昨天我们用Intel I9的10核,每个核2个threads的机器跑了内核的编译: 超线程SMT究竟可以快多少? 今天,我换一台机器,采用AMD Ryzen。 默认情况16核,每个核2个 2021-10-20 01:32:55 Author: blog.csdn.net(查看原文) 阅读量:43 收藏
昨天我们用Intel I9的10核,每个核2个threads的机器跑了内核的编译:
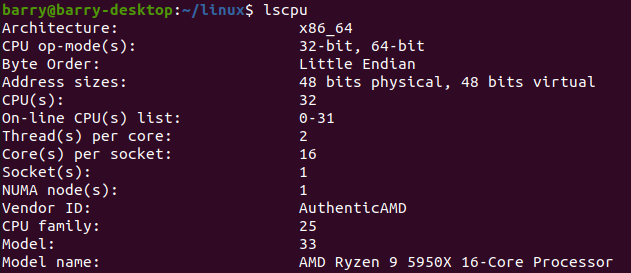
今天,我换一台机器,采用AMD Ryzen。
默认情况16核,每个核2个threads,共32个CPUs:
下面编译内核:
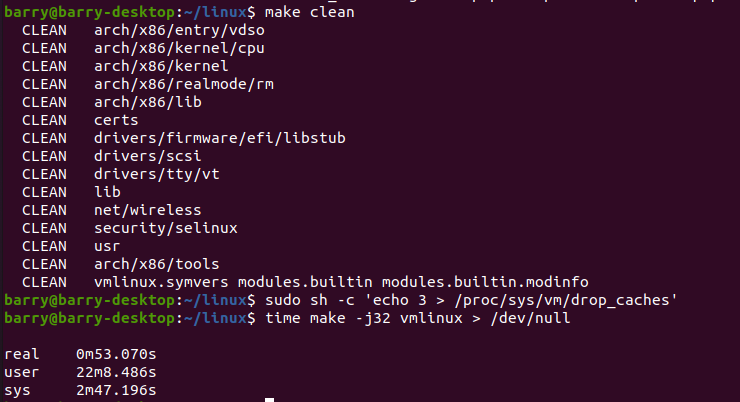
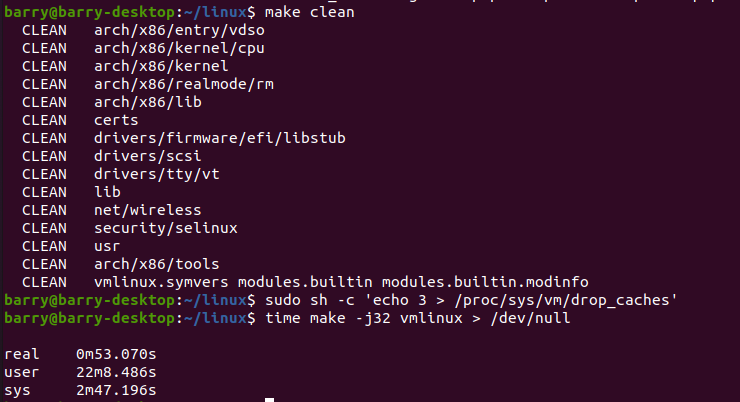
大约需要53秒。记得昨天用Intel I9 10核20线程需要2分钟30秒左右。
再来一遍:

这说明make clean, drop_caches后时间也差不多。51秒,53秒左右的正常抖动范围。
现在我们关闭smt,只保留16个CPU:
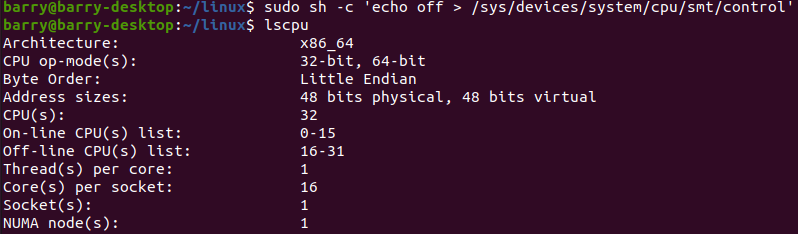
具体的关闭方法就是:
sudo sh -c 'echo off > /sys/devices/system/cpu/smt/control'这样只剩下16个CPU,下面来编译:

时间57秒,相对于51、53秒,速度下降不到10%。
这说明超线程SMT对编译内核这个workload的性能的提升绝对没有达到100%,甚至都没有达到10%。
我们现在重新开启超线程:
sudo sh -c 'echo on > /sys/devices/system/cpu/smt/control看一下哪个CPU和哪个CPU是thread sibling:

看起来CPU0和CPU16是一对,CPU1和CPU17是一对,依次类推。
刚才我们关闭SMT是把CPU16-CPU31全关了,只留下每对里面的1个CPU,也就是留下了CPU0-CPU15。
在开启SMT的时候(假设蓝色和红色是一个CORE里面的两个CPU):

在关闭SMT的时候,等于每对里面只留1个CPU:

现在我们换一种关法,一对对关,只留下8对,也就是8个core:

指令如下:
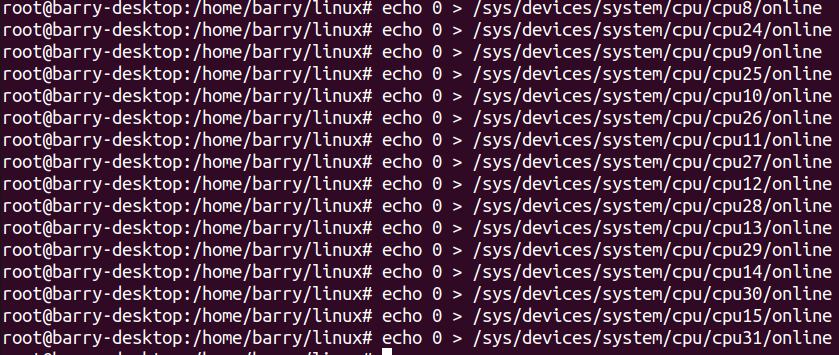
实现效果如下:
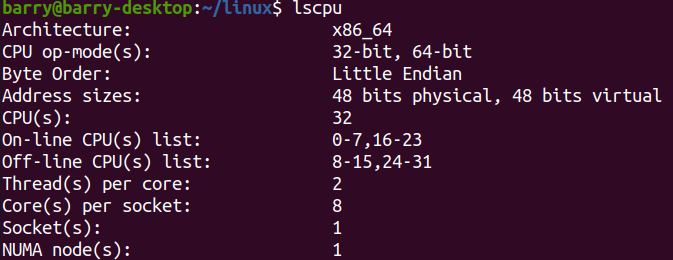
再重新编译内核:
 现在耗时是1分21秒,相对于所有CPU全开,下降了很多,时间增大了59%,当然没有达到2倍。
现在耗时是1分21秒,相对于所有CPU全开,下降了很多,时间增大了59%,当然没有达到2倍。
再想想昨天的Intel I9,关闭5个完整核耗时是3分10秒,全开10核是2分30秒,Intel一半核工作和所有核同时工作的差距远不如AMD那么明显。
所以可以看出,就内核编译这个workload而言,AMD的16core相对于8core,性能的scale会更加成正比。当然AMD开关SMT,对内核编译这个workload而言,影响小于10%,而Intel I9的影响有14%。
很多童鞋昨天留言,说编译内核有一定的IO bound,另外提到link阶段是单线程,还有的童鞋说是Intel Turbo的影响,这些我们都认为是有一定道理的。但是,我始终坚信,profiling是检验猜想的唯一标准,后面有空再写一篇文章来profiling一些究竟是为什么。
如有侵权请联系:admin#unsafe.sh