Kubernetes 中的网络功能,主要包括 POD 网络,service 网络和网络策略组成。其中 POD 网络和网络策略,都是规定了模型,没有提供默认实现。而 service 网 2021-10-13 06:44:18 Author: blog.csdn.net(查看原文) 阅读量:34 收藏

Kubernetes 中的网络功能,主要包括 POD 网络,service 网络和网络策略组成。其中 POD 网络和网络策略,都是规定了模型,没有提供默认实现。而 service 网络作为 Kubernetes 的特色部分,官方版本持续演进了多种实现:
| service 实现 | 说明 |
| userspace 代理模式 | kube-proxy 负责 list/watch,规则设置,用户态转发。 |
| iptables 代理模式 | kube-proxy 负责 list/watch,规则设置。IPtables 相关内核模块负责转发。 |
| IPVS 代理模式 | kube-proxy 负责 list/watch,规则设置。IPVS 相关内核模块负责转发。 |
在 Kubernetes 中先后出现的几种 Service 实现中,整体都是为了提供更高的性能和扩展性。
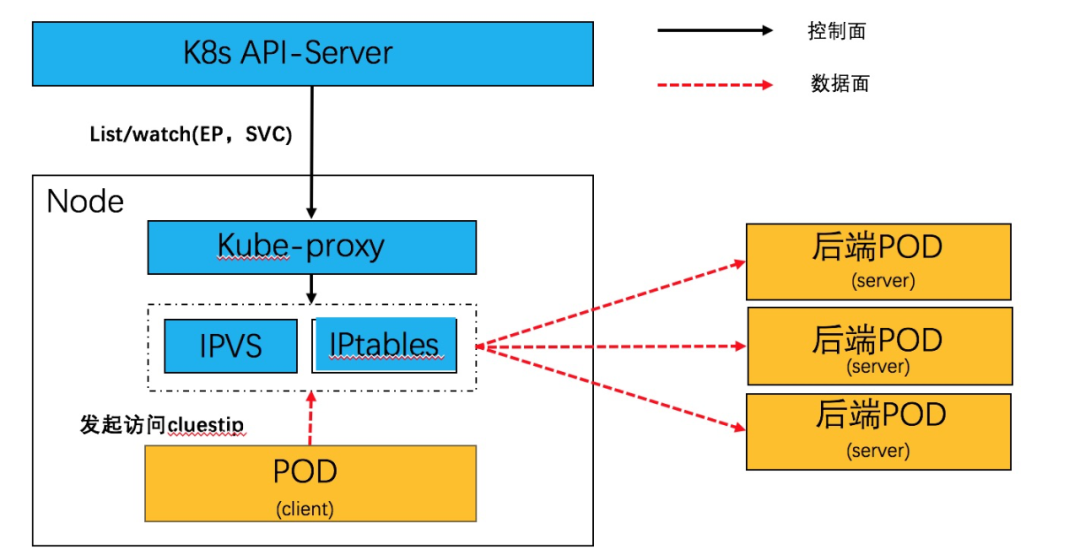
Service 网络,本质上是一个分布式的服务器负载均衡,通过 daemonset 方式部署的 kube-proxy,监听 endpoint 和 service 资源,并在 node 本地生成转发表项。目前在生产环境中主要是 iptables 和 IPVS 方式,原理如下:
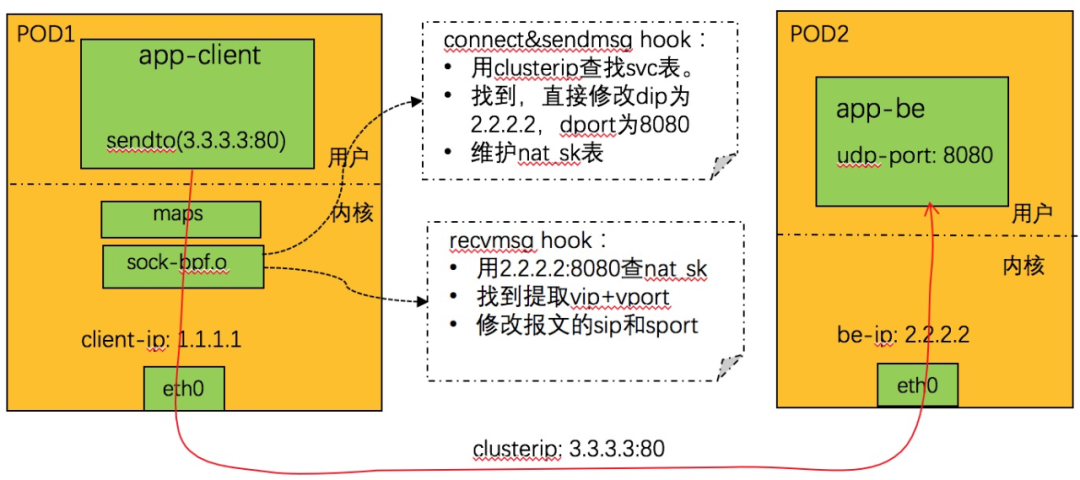
在本文中,介绍使用 socket eBPF 在 socket 层面完成负载均衡的逻辑,消除了逐报文 NAT 转换处理,进一步提升 Service 网络的转发性能。
基于 socket eBPF 的数据面实现
socket eBPF 数据面简介
无论 kube-proxy 采用 IPVS 还是 tc eBPF 服务网络加速模式,每个从 pod 发出网络请求都必然经过 IPVS 或者 tc eBPF,即 POD <--> Service <--> POD,随着流量的增加必然会有性能开销, 那么是否可以直接在连接中将 service的clusterIP 的地址直接换成对应的 pod ip。基于 Kube-proxy+IPVS 实现的 service 网络服务,是基于逐报处理 +session 的方式来实现。
利用 socket eBPF,可以在不用直接处理报文和 NAT 转换的前提下,实现了负载均衡逻辑。Service 网络在同步上优化成 POD <--> POD,从而使Service 网络性能基本等同于 POD 网络。软件结构如下:
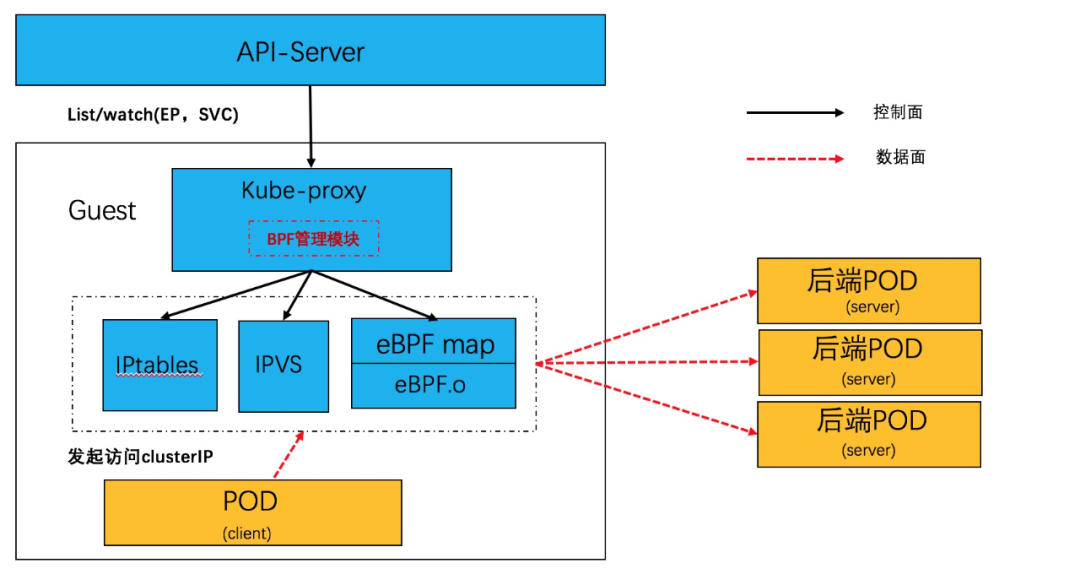
在 Linux 内核中,利用 BPF_PROG_TYPE_CGROUP_SOCK 类型的 eBPF hook 可以针对 socket 系统调用挂接 hook,插入必要的 EBPF 程序。
通过 attach 到特定的 cgroup 的文件描述符,可以控制 hook 接口的作用范围。
利用 sock eBPF hook,我们可以在 socket 层面劫持特定的 socket 接口,来完成完成负载均衡逻辑。
POD-SVC-POD 的转发行为转换成 POD-POD 的转发行为。
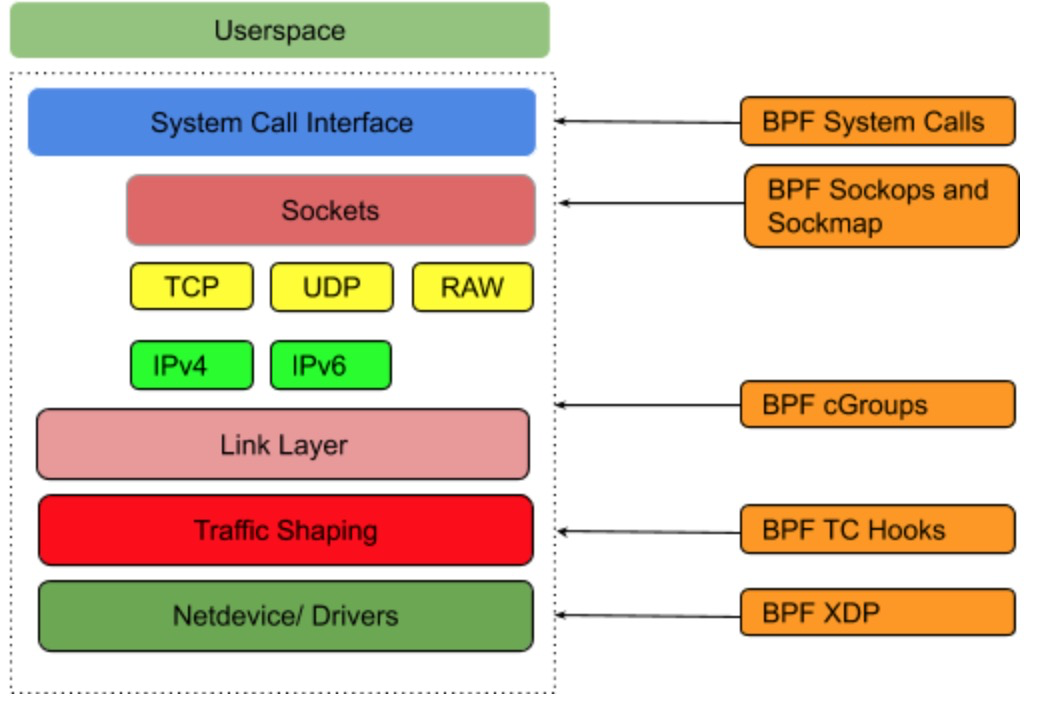
当前 Linux 内核中不断完善相关的 hook,支持更多的 bpf_attach_type,部分距离如下:
BPF_CGROUP_INET_SOCK_CREATE
BPF_CGROUP_INET4_BIND
BPF_CGROUP_INET4_CONNECT
BPF_CGROUP_UDP4_SENDMSG
BPF_CGROUP_UDP4_RECVMSG
BPF_CGROUP_GETSOCKOPT
BPF_CGROUP_INET4_GETPEERNAME
BPF_CGROUP_INET_SOCK_RELEASE
TCP 工作流程
TCP 由于是有基于连接的,所以实现非常简明,只需要 hook connect 系统调用即可,如下所示:
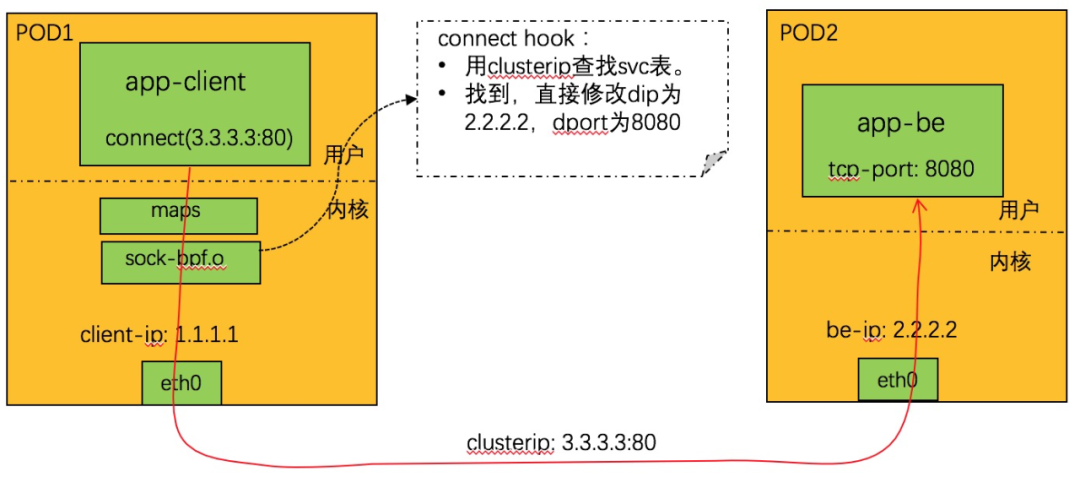
connect 系统调用劫持逻辑:
1. 从 connect 调用上下文中取 dip+dport,查找 svc 表。找不到则不处理返回。
2. 查找亲和性会话,如果找到,得到 backend_id,转 4。否则转 3。
3. 随机调度,分配一个 backend。
4. 根据 backend_id,查 be 表,得到 be 的 IP+ 端口。
5. 更新亲和性信息。
6. 修改 connect 调用上下文中的 dip+dport 为 be 的 ip+port。
7. 完成。
在 socket 层面就完成了端口转换,对于 TCP 的 clusterip 访问,基本上可以等同于 POD 之间东西向的通信,将 clusterip 的开销降到最低。
不需要逐包的 dnat 行为。
不需要逐包的查找 svc 的行为。
UDP 工作流程
UDP 由于是无连接的,实现要复杂一些,如下图所示:
nat_sk 表的定义参见:LB4_REVERSE_NAT_SK_MAP
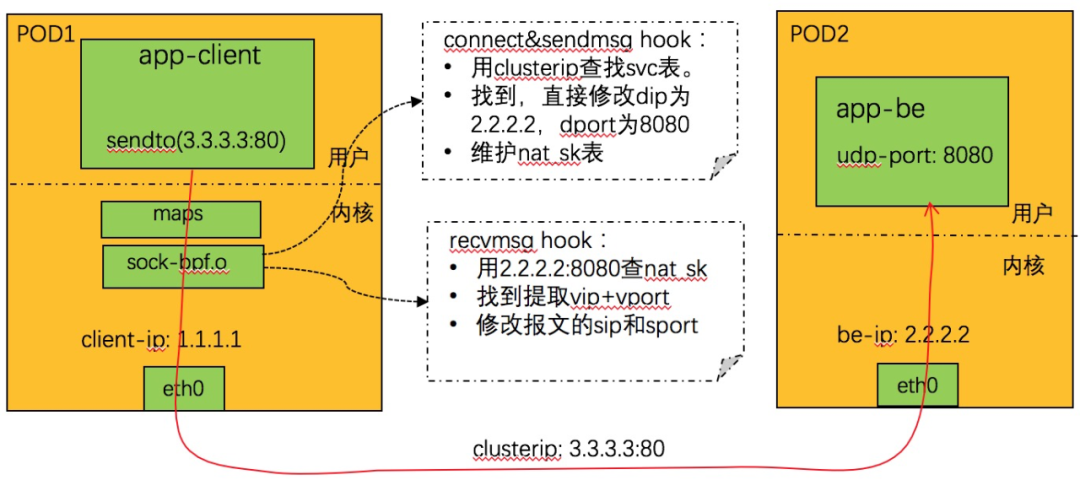
劫持 connect 和 sendmsg 系统调用:
1. 从系统调用调用上下文中取 dip+dport,查找 svc 表。找不到则不处理返回。
2. 查找亲和性会话,如果找到,得到 backend_id,转 4,否则转 3。
3. 随机调度,分配一个 backend。
4. 根据 backend_id,查 be 表,得到 be 的 IP+端口。
5. 更新亲和性的相关表。
6. 更新 nat_sk 表,key 为 be 的 ip+port,value 为 svc的vip+vport。
7. 修改系统调用上下文中的 dip+dport 为 be 的 ip + port。
8. 完成。
劫持 recvmsg 系统调用
1. 从系统调用上下文中远端 IP+port,查找 NAT_SK 表,找不到则不处理返回。
2. 找到,取出其中的 IP+port,用来查找 svc 表,找不到,则删除 nat_sk 对应表项,返回。
3. 使用 nat_sk 中找到的 ip+port,设置系统调用上下文中远端的 IP+port。
4. 完成。
关于地址修正问题
基于 socket eBPF 实现的 clusterIP,在上述基本转发原理之外,还有一些特殊的细节需要考虑,其中一个需要特殊考虑就是 peer address 的问题。和 IPVS之类的实现不同,在 socket eBPF 的 clusterIP 上,client 是和直接和 backend 通信的,中间的 service 被旁路了。回顾一下转发路径如下:
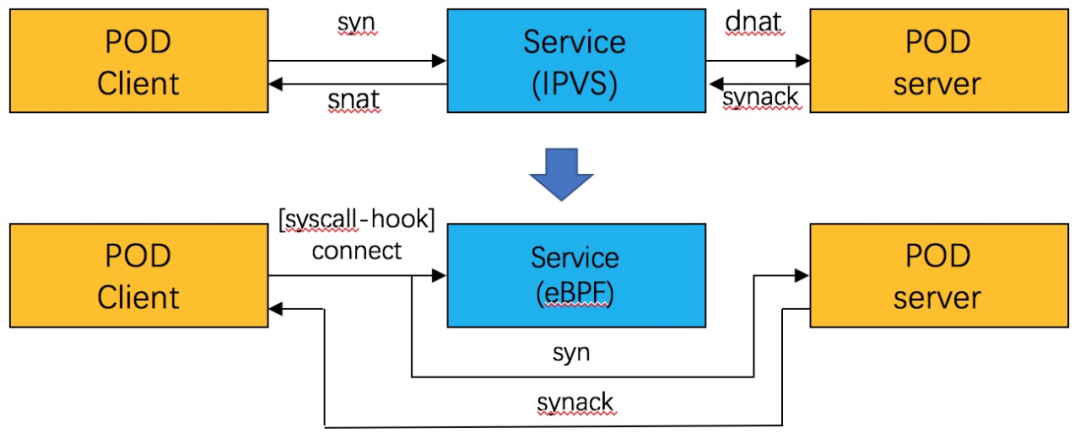
此时,如果 client 上的 APP 调用 getpeername 之类的接口查询 peer address,这个时候获取到的地址和 connect 发起的地址是不一致的,如果 app对于 peeraddr 有判断或者特殊用途,可能会有意外情况。
针对这种情况,我们同样可以通过 eBPF 在 socket 层面来修正:
1、在guest kernel 上新增 bpf_attach_type,可以对 getpeername 和 getsockname 增加 hook 处理。
2、发起连接的时候,在相应的 socket hook 处理中,定义 map 记录响应的VIP:VPort 和 RSIP:RSPort 的对用关系。
3、当 APP 要调用 getpeername/getsockname 接口的时候,利用 eBPF 程序修正返回的数据:修改上下文中的远端的 IP+port为vip+vport。
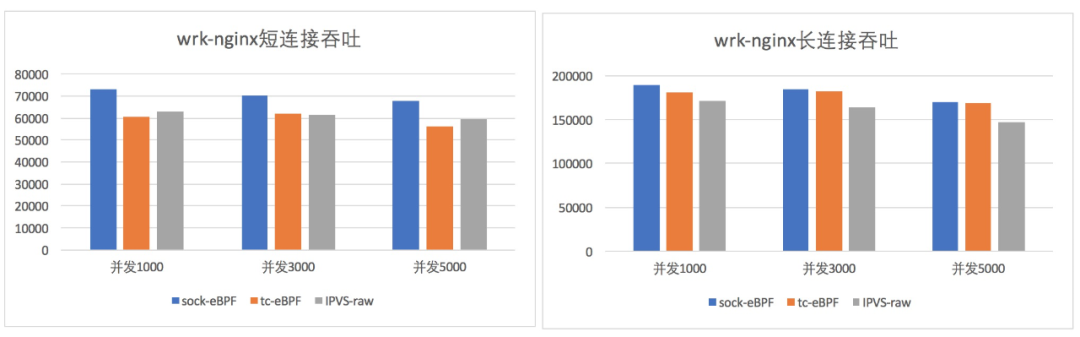
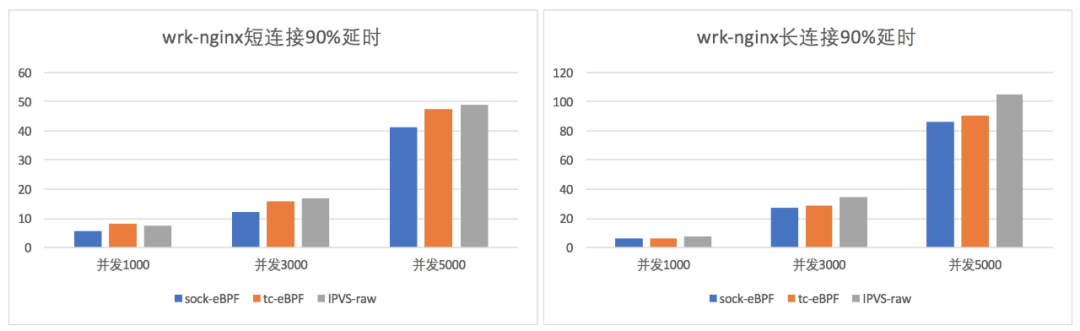
和TC-EBPF/IPVS性能对比
测试环境:4vcpu + 8G mem 的安全容器实例,单 client + 单 clusterip + 12 backend。
socket BPF:基于 socket ebpf 的 service 实现。
tc eBPF:基于 cls-bpf 的 service 实现,目前已经在 ack 服务中应用。
IPVS-raw:去掉所有安全组规则和 veth 之类开销,只有 IPVS 转发逻辑的 service 实现。
socket BPF 在所有性能指标上,均有不同程度提升。
大量并发的短连接,基本上吞吐提升 15%,时延降低 20%。
转发性能比较(QPS)
90%转发延时比较(ms)
继续演进
eBPF does to Linux what JavaScript does to HTML.
-- Brendan Gregg
基于 socket eBPF 实现的 service,大大简化了负载均衡的逻辑实现,充分体现了 eBPF 灵活、小巧的特点。eBPF 的这些特点也很契合云原生场景,目前,该技术已在阿里云展开实践,加速了 kubernetes 服务网络。我们会继续探索和完善更多的 eBPF 的应用案例,比如 IPv6、network policy 等。
——完——
加入龙蜥社群
加入微信群:添加社区助理-龙蜥社区小龙(微信:openanolis_assis),备注【龙蜥】拉你入群;加入钉钉群:扫描下方钉钉群二维码。欢迎开发者/用户加入龙蜥社区(OpenAnolis)交流,共同推进龙蜥社区的发展,一起打造一个活跃的、健康的开源操作系统生态!


龙蜥社区钉钉交流群 龙蜥社区-小龙
关于龙蜥社区
龙蜥社区(OpenAnolis)是由企事业单位、高等院校、科研单位、非营利性组织、个人等按照自愿、平等、开源、协作的基础上组成的非盈利性开源社区。龙蜥社区成立于2020年9月,旨在构建一个开源、中立、开放的Linux上游发行版社区及创新平台。
短期目标是开发龙蜥操作系统(Anolis OS)作为CentOS替代版,重新构建一个兼容国际Linux主流厂商发行版。中长期目标是探索打造一个面向未来的操作系统,建立统一的开源操作系统生态,孵化创新开源项目,繁荣开源生态。
龙蜥OS 8.4已发布,支持x86_64和ARM64架构,完善适配Intel、飞腾、海光、兆芯、鲲鹏芯片。
欢迎下载:
https://openanolis.cn/download
加入我们,一起打造面向未来的开源操作系统!
https://openanolis.cn
如有侵权请联系:admin#unsafe.sh