[原]Python爬虫编程思想(47):项目实战:抓取豆瓣Top250图书榜单
本文使用requests库、lxml库以及XPath抓取豆瓣网Top250图书排行榜 2021-10-09 22:57:22 Author: blog.csdn.net(查看原文) 阅读量:42 收藏
本文使用requests库、lxml库以及XPath抓取豆瓣网Top250图书排行榜 2021-10-09 22:57:22 Author: blog.csdn.net(查看原文) 阅读量:42 收藏
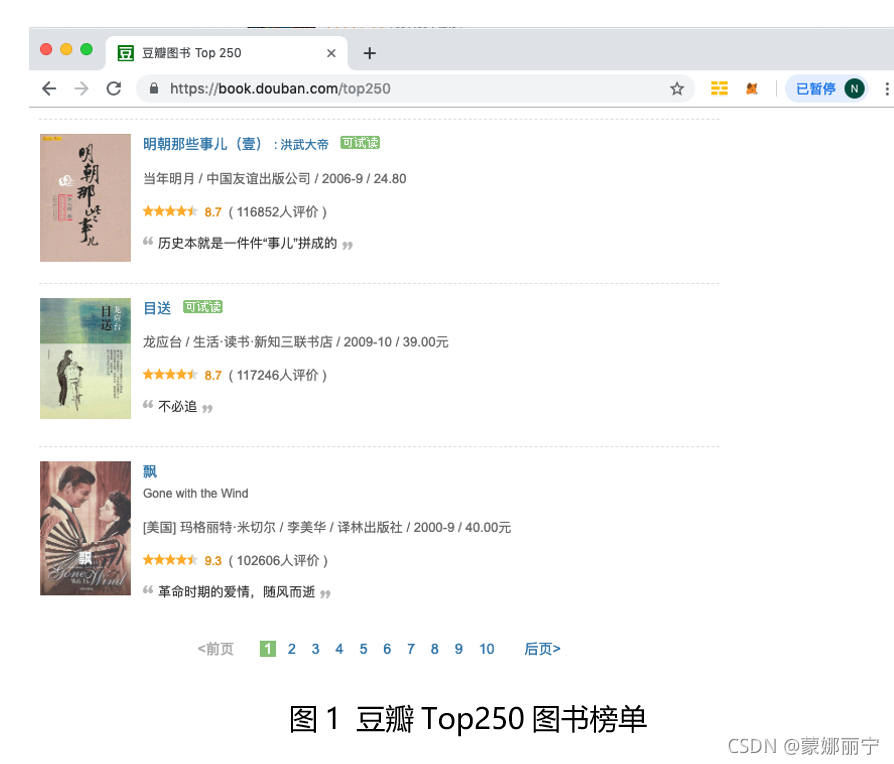
本文使用requests库、lxml库以及XPath抓取豆瓣网Top250图书排行榜。读者可以通过https://book.douban.com/top250访问Top250图书榜单,如图1所示。
在开始编写爬虫之前,先要分析一下Top250榜单代码和页面切换的规律。首先来分析一下页面切换的规则。在页面的最下方是分页导航条,分别切换到第1页、第2页、第3页、第4页,在地址栏会看到如下的4个URL
https://book.douban.com/top250?start=0
https://book.douban.com/top250?start=25
https://
文章来源: https://blog.csdn.net/nokiaguy/article/details/120679836
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh