Linux 内核热补丁可以修复正在运行的 linux 内核,是一种维持线上稳定性不可缺少的措施,现在比较常见的比如 kpatch 和 livepatch。内核热补丁可以修复内核中正在运行的函 2021-10-08 00:48:36 Author: blog.csdn.net(查看原文) 阅读量:80 收藏

Linux 内核热补丁可以修复正在运行的 linux 内核,是一种维持线上稳定性不可缺少的措施,现在比较常见的比如 kpatch 和 livepatch。内核热补丁可以修复内核中正在运行的函数,用已修复的函数替换掉内核中存在问题的函数从而达到修复目的。
函数替换的思想比较简单,就是在执行旧函数时绕开它的执行逻辑而跳转到新的函数中,有一种比较简单粗暴的方式,就是将原函数的第一条指令修改为“ jump 目标函数”指令,即直接跳转到新的函数以达到替换目的。
那么,问题来了,这么做靠谱吗?直接将原函数的第一条指令修改为 jump 指令,会破坏掉原函数和它的调用者之间的寄存器上下文关系,存在安全隐患!本文会针对该问题进行探索和验证。
安全性冲击:问题呈现
对于函数调用,假设存在这样两个函数 funA 和 funB,其中 funA 调用 funB 函数,这里称 funA 为 caller(调用者),funB 为 callee(被调用者),funA 和 funB 都使用了相同的寄存器 R,如下所示:
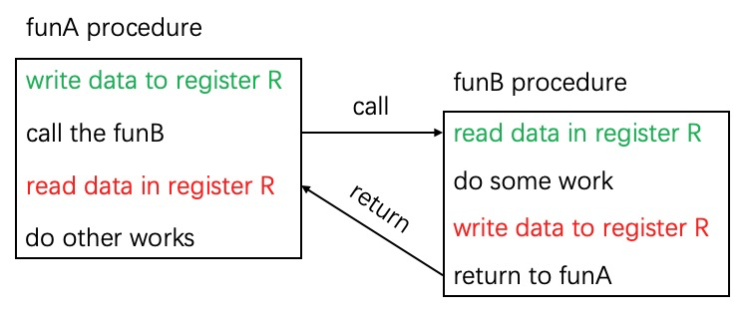
图1 funA 和 funB 都使用了寄存器 R,funA 再次使用 R 时已经被 funB 修改
因此,当 funA 再次使用到 R 的数据已经是错误的数据了。如果 funA 在调用 funB 前保存寄存器 R 中的数据,funB 返回后再将数据恢复到 R 中,或者 funB 先保存 R 中原有的数据,然后在返回前恢复,就可以解决这类问题。
唯一的调用约定
那寄存器该由 caller 还是 callee 来保存?这就需要遵循函数的调用约定(call convention),不同的 ABI 和不同的平台,函数的调用约定是不一样的,对于 Linux 来说,它遵循的是 System V ABI 的 call convention,x86_64 平台下函数调用约定有且只有一种,调用者 caller 和被调用者 callee 需要对相应的寄存器进行保存和恢复操作:
Caller-save registers : RDI, RSI, RDX, RCX, R8, R9, RAX, R10, R11
Callee-save registers : RBX, RBP, R12, R13, R14, R15
调用约定,gcc 它遵守了吗?
设问:当函数实现很简单,只用到了少量寄存器,那没使用到的还需要保存吗?
答案:it depends。根据编译选项决定。
众所周知,GCC 编译器有 -O0、-O1、-O2 和 -Ox 等编译优化选项,优化范围和深度随 x 增大而增大(-O0是不优化,其中隐含的意思是,它会严格遵循 ABI 中的调用约定,对所有使用的寄存器进行保存和恢复)。
Linux 内核选用的都是 -O2 优化。GCC 会选择性的不遵守调用约定,也就是设问里提到的,不需要保存没使用到的寄存器。
当【运行时替换】撞见【调用约定】
GCC 之所以可以做这个优化,是因为 GCC 高屋建瓴,了解程序的执行流。当它知道 callee,caller 的寄存器分配情况,就会大胆且安全地做各种优化。
但是,运行时替换破坏了这个假设,GCC 所掌握的 callee 信息,极有可能是错误的。那么这些优化可能会引发严重问题。这里以一个具体的实例进行详细说明,这是一个用户态的例子( x86_64 平台):
//test.c 文件
//编译命令:gcc test.c -o test -O2 (kernel 采用的是 O2 优化选项)
//执行过程:./test
//输入参数:4
#include <sys/mman.h>
#include <string.h>
#include <stdio.h>
#include <math.h>
#define noinline __attribute__ ((noinline)) //禁止内联
static noinline int c(int x)
{
return x * x * x;
}
static noinline int b(int x)
{
return x;
}
static noinline int newb(int x)
{
return c(x * 2) * x;
}
static noinline int a(int x)
{
int volatile tmp = b(x); // tmp = 8 ** 3 * 4
return x + tmp; // return 4(not 8) + tmp
}
int main(void)
{
int x;
scanf("%d", &x);
if (mprotect((void*)(((unsigned long)&b) & (~0xFFFF)), 15,
PROT_WRITE | PROT_EXEC | PROT_READ)) {
perror("mprotect");
return 1;
}
/* 利用 jump 指令将函数 b 替换为 newb 函数 */
((char*)b)[0] = 0xe9;
*(long*)((unsigned long)b + 1) = (unsigned long)&newb
- (unsigned long)&b - 5;
printf("%d", a(x));
return 0;
}程序解释:该程序是对输入的数字进行计算,运行时利用 jump 指令将程序中的函数 b 替换为 newb 函数,即,将 y = x + x 计算过程替换为 y = x + (2x) ^ 3 * x;
程序编译:gcc test.c -o test -O2,这里我们采用的是与编译内核相同的优化选项 -O2;
程序执行:./test,输入参数:4,输出结果:2056;
程序错误:2056 是错误的结果,应该是 2052,而且直接调用 newb 函数编译执行的结果是 2052。
该例子说明,直接使用 jump 指令替换函数在 -O2 的编译优化下,会出现问题,安全性受到了质疑和冲击!!!
安全性冲击:分析问题
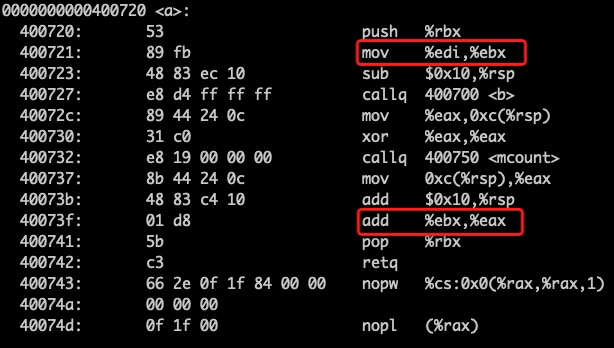
上述例子中,我们将函数 b 用 jump 指令替换为 newb 函数,在 -O2 的编译优化下出现了计算错误的结果,因此,我们需要对函数的调用执行过程进行仔细分析,挖掘问题所在。首先,我们先来查看一下该程序的反汇编(指令:objdump -d test),并重点关注 a、b 和 newb 函数:
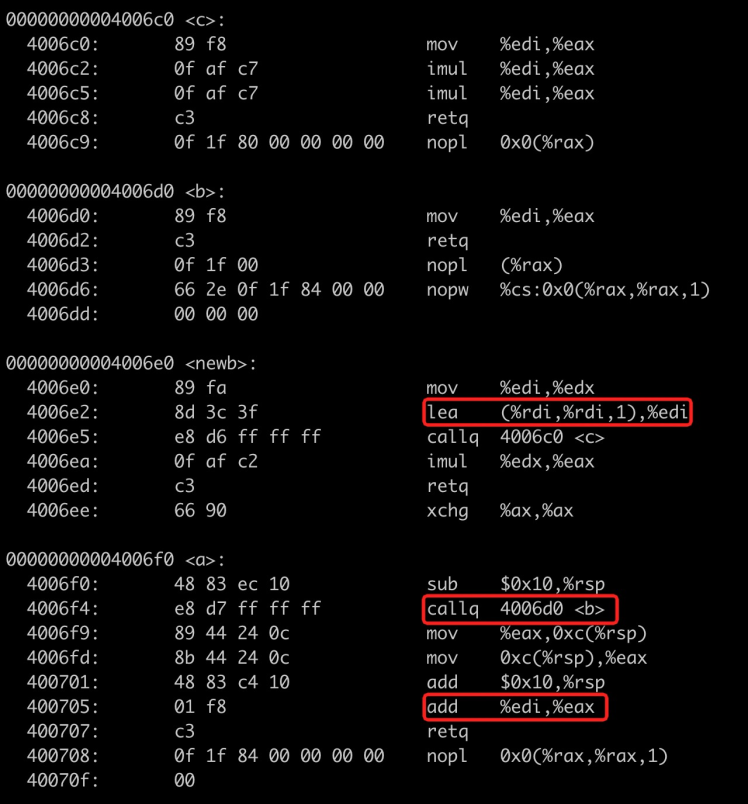
图2 -O2 编译优化的反汇编结果
汇编解释:
main:
-> 将参数 4 存放到 edi 寄存器中
-> 调用 a 函数:
-> 调用 b 函数,直接跳转到 newb 函数:
-> 将 edi 寄存器中的值存放到 edx 寄存器
-> edi 寄存器与自身相加后结果放入 edi
-> 调用 c 函数:
-> 将 edi 寄存器中的值存到 eax 寄存器
-> edi 乘以 eax 后结果放入 eax
-> edi 乘以 eax 后结果放入 eax
-> 返回到 newb 函数
-> 将 edx 与 eax 相乘后结果放入 eax
-> 返回到 a 函数
-> 将 edi 与 eax 相加后结果放入 eax
-> 返回 main 函数
(注意:b 函数中没有对 edi 寄存器进行写操作,而且它的代码段被修改为 jump 指令跳转到 newb 函数)
数据出错的原因在于,在函数 newb 中,使用到了 a 函数中使用的 edi 寄存器,edi 寄存器中的值在 newb 函数中被修改为 8,当 newb 函数返回后,edi 的值仍然是 8,a 函数继续使用了该值,因此,计算过程变为:8^3 * 4 + 8 = 2056,而正确的计算结果应该是 8^3 * 4 + 4 = 2052。
接下来不进行编译优化(-O0),其输出结果是正确的 2052,反汇编如下所示:
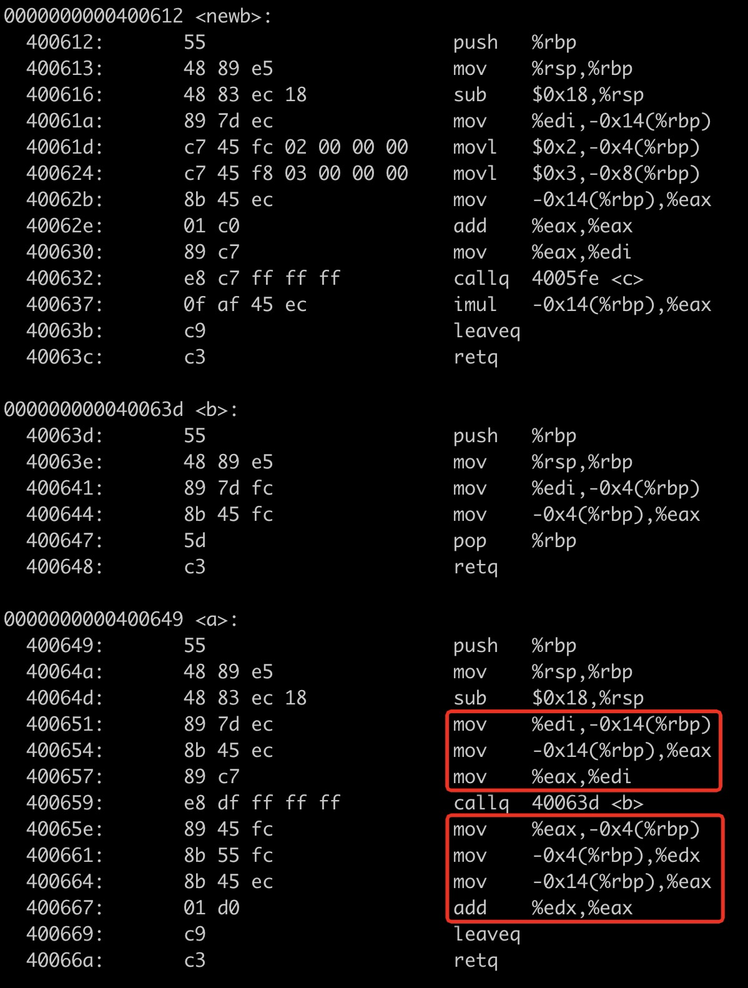
图3 不进行编译优化的反汇编
从反汇编中可以看到,函数 a 在调用 b 函数前,将 edi 寄存器的值存在了栈上,调用之后,将栈上的数据再取出,最后进行相加。这就说明,-O2 优化选项将 edi 寄存器的保存和恢复操作优化掉了,而在调用约定中,edi 寄存器本就该属于 caller 进行保存/恢复的。至于为什么编译器会进行优化,我们此刻的猜想是:
a 函数本来调用的是 b 函数,而且编译器知道 b 函数中没有使用到 edi 寄存器,因此调用者 a 函数没有对该寄存器进行保存和恢复操作。但是编译器不知道的是,在程序运行时,b 函数的代码段被动态修改,利用 jump 指令替换为 newb 函数,而在 newb 函数中对 edi 寄存器进行了数据读写操作,于是出现了错误。
这是一个典型的没有保存 caller-save 寄存器导致数据出错的场景。
而编译内核采用的也是 -O2 选项。如果将该场景应用到内核函数热替换是否会出现这类问题呢?于是,我们带着问题继续探索。
安全性冲击:探索问题
不再观察到 bug
我们构造了一个内核函数热替换的实例,将上面的用户态的例子移植到我们构造的场景中,通过内核模块修改原函数的代码段,用 jump 指令直接替换原来的 b 函数。然而加载模块后,结果是正确的 2052,经过反汇编我们发现,内核中 a 函数对 edi 寄存器进行了保存操作:
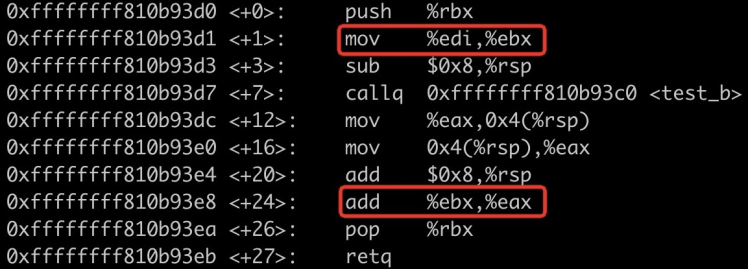
图4 内核中 a 函数的反汇编
内核和模块编译时采用的是 -O2 优化选项,而此处 a 函数并没有被优化,仍然保存了 edi 寄存器。
此时我们预测:对于内核函数的热替换来说,使用 jump 做函数替换是安全的。
神奇的 -pg 选项
我们猜想是否是内核编译时使用其它的编译选项导致问题不能复现。果不其然,经过探索我们发现内核编译使用的 -pg 选项导致问题不再复现。
通过翻阅 GCC 手册得知,-pg 选项是为了支持 GNU 的 gprop 性能分析工具所引入的,它能在函数中增加一条 call mount 指令,去做一些分析工作。
在内核中,如果开启了 CONFIG_FUNCTION_TRACER,则会使能 -pg 选项。
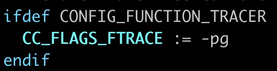
图5 开启 CONFIG_FUNCTION_TRACER 使能 -pg 选项
FUNCTION_TRACE 即我们常说的 ftrace 功能,ftrace 大大提升了内核的运行时调试能力。ftrace 功能除了 -pg 选项,还要求打开 -mfentry 选项,后者的作用是将函数对 mcount 的调用放到函数的第一条指令处,然后通过 scripts/recordmcount.pl 脚本将该条 call 指令修改为 nop 指令。但 -mfentry 与本文主题没有关联,不再细说。
为了验证这个结论,我们回到上一节的用户态例子,并且增加了 -pg 编译选项:“gcc test.c -o test -O2 -pg”,此时运行结果果然正确了。查看其反汇编:
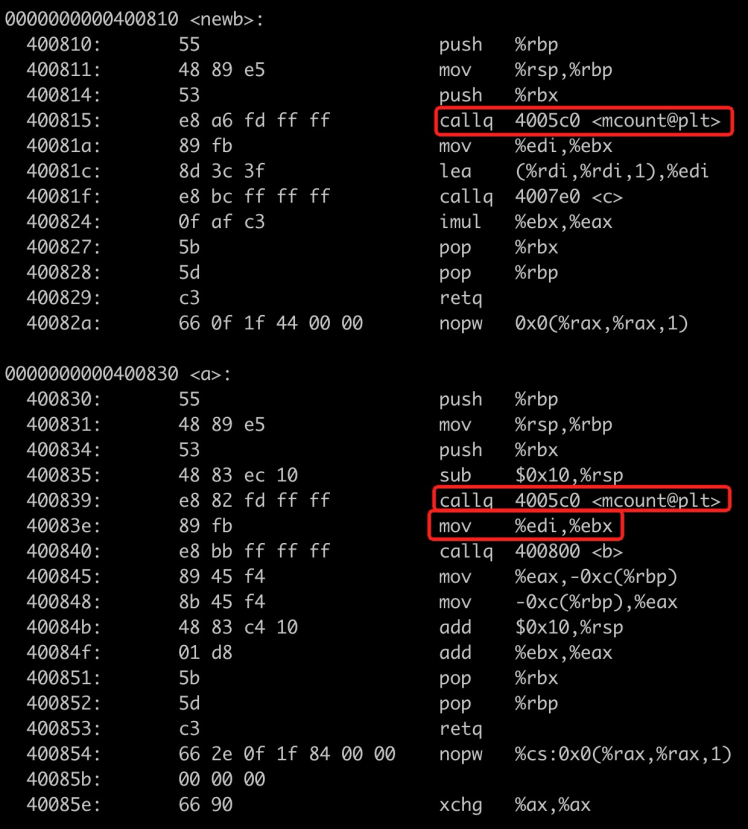
图6 增加 -pg 选项后的汇编
可以看到,每个函数都有 call mcount 指令,而且 a 函数中将 edi 寄存器保存到 ebx 中,在 newb 函数中又保存 ebx 寄存器。为什么在增加了 call mount 指令后,会做寄存器的保存操作?我们猜想,会不会是因为,由于 call mount 操作相当于调用了一个未知的函数( mcount 没有定义在同一个文件中),因此,GCC 认为这样未知的操作可能会污染了寄存器的数据,所以它才进行了保存现场的操作。
于是我们去掉了 -pg 选项,手动增加了 call mount 的行为进行验证:在另一个源文件 mcount.c 中增加一个函数 void mcount() { asm("nop\n"); },在 test.c 文件中增加对 mcount 函数的声明,a 函数中增加对该函数的调用:
extern void mcount(); //声明 mcount 函数
static noinline int a(int x){
int volatile tmp = b(x); // tmp = 8 ** 3 * 4
mcount();
return x + tmp; // return 4(not 8) + tmp
}经过编译:gcc test.c mcount.c -O2 后运行,发现计算结果正确,而且反汇编中 a 函数保存了寄存器:
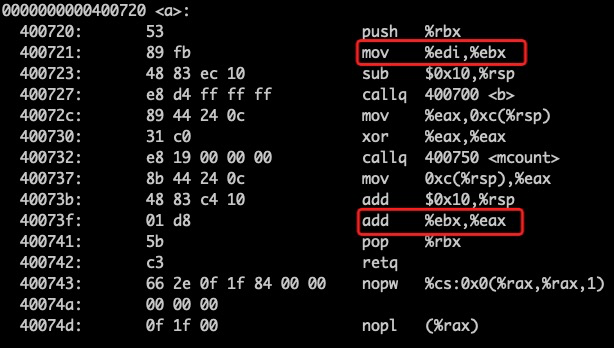
图7 调用 mcount 函数后的汇编
继续验证猜想,将 mcount 函数放在 test.c 文件中,计算结果错误,而且,反汇编中没有保存寄存器,于是我们得到了这样的猜想结论:
GCC 在编译某个源文件时,如果文件内的某个函数(比如场景中的函数 a)调用了其它文件中的一个未知函数(比如场景中的 mcount 函数),则 GCC 会在该函数中保存寄存器;
开启 -pg 选项,增加了对 mcount 的调用,因此会在函数中增加对寄存器现场的保存操作,对 -O2 选项的函数调用优化起到了屏蔽作用。
神秘的 -fipa-ra 选项:真正的幕后主使
经过我们的探索和资料的查阅,发现了这个 -fipa-ra 选项,可以说它是优化的幕后主使。GCC 手册中给出 -fipa-ra 选项的解释是:
Use caller save registers for allocation if those registers are not used by any called function. In that case it is not necessary to save and restore them around calls. This is only possible if called functions are part of same compilation unit as current function and they are compiled before it. Enabled at levels -O2, -O3, -Os, however the option is disabled if generated code will be instrumented for profiling (-p, or -pg) or if callee’s register usage cannot be known exactly (this happens on targets that do not expose prologues and epilogues in RTL).
这里主要是说,如果开启这个选项,那么,callee 中如果没有使用到 caller 使用的寄存器,就没有必要保存这些寄存器,前提是,callee 与 caller 在同一个编译单元中而且 callee 函数比 caller 先被编译,这样才可能出现前面的优化。如果开启了 -O2 及以上的编译优化选项,则会使能 -fipa-ra 选项,然而,如果开启了 -p 或者 -pg 这些选项,或者,无法明确 callee 所使用的寄存器,-fipa-ra 选项会被禁用。
这段话,其实已经能 cover 掉我们前面大部分猜想的测试验证:
-O2 选项自动使能 -fipa-ra 进行优化:在我们的场景中,函数 a 使用的 edi 寄存器,在函数 b 中没有使用到,因此函数 a 被优化,没有保存 edi 寄存器,但是在 newb 函数中,使用到了 edi 寄存器,且数据被修改,将 newb 函数替换函数 b,则计算结果出错;
在 -O2 中使用 -pg 选项会禁用 -fipa-ra:编译时使用 -pg 选项,计算结果是正确的,而且函数 a 保存了 edi 寄存器,说明没有对函数 a 进行优化;
不在同一编译单元不会被优化:去掉 -pg 选项,在函数 a 中手动调用 mcount 函数,将这个函数放在 test.c(与函数 a 为同一编译单元)与放在另一个文件 mcount.c(不同编译单元)中的计算结果不同:同一编译单元中计算结果是错误的,而且函数 a 没有保存寄存器现场;不在同一编译单元中,计算结果是正确的,函数 a(caller) 保存了寄存器现场,因为编译器无法明确函数 b(callee)所使用的寄存器。
notrace:它是二度冲击吗?
用过 ftrace 或者内核开发者应该对 notrace 属性不陌生,内核中有一些被 notrace 修饰的函数。notrace 其实就是给函数增加 no_instrument_function 属性。例如,在 X86 的定义:
#define notrace __attribute__((no_instrument_function))
字面上来看,notrace 和 -pg 的含义可以说完全对立,-pg 让 jump 变得安全,是否又会在 notrace 上栽一个跟斗呢?幸运的是,我们接下来将看到,notrace 仅仅是禁止了 instrument function,而没有破坏安全性。
gcc 手册中的 -pg 选项给出这样的解释:
Generate extra code to write profile information suitable for the analysis program prof (for -p) or gprof (for -pg). You must use this option when compiling the source files you want data about, and you must also use it when linking. You can use the function attribute no_instrument_function to suppress profiling of individual functions when compiling with these options.
这里主要是说,加上 notrace 属性的函数,不会产生调用 mcount 的行为,那么,是否意味着不再保护寄存器现场,换句话说,notrace 的出现是否会绕过“-pg 选项对 -fipa-ra 优化的屏蔽”?于是我们又增加 notrace 属性进行验证:在 a 函数中增加 notrace 的属性,因为 a 函数是 caller,编译时开启 -pg 选项,然后检查计算结果及反汇编,最后发现,计算结果正确,而且汇编代码中保存了寄存器现场。
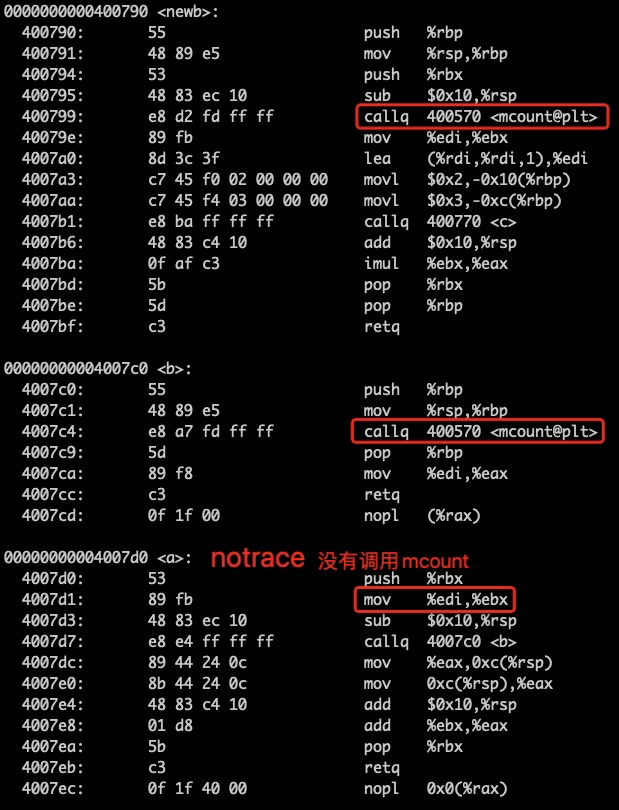
图8 给 a 函数追加 notrace 属性,a 函数没有调用 mcount 的行为
我们又对所有的函数追加了 notrace 属性,计算结果正确且寄存器现场被保护。但是这些简单的验证不足以证明,于是我们通过阅读 GCC 源码发现:

图9 -pg 能禁用 -fipa_ra 选项
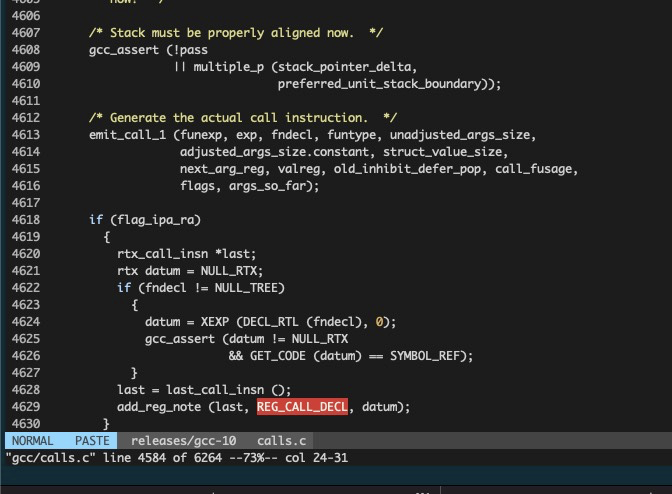
图10 gcc 处理每一个函数时都会检查 -fipa-rq 选项,如果为 false,则不对函数进行优化
通过源码阅读,可以确定的是,当使用了 -pg 选项后,会禁用 -fipa-rq 优化选项,GCC 检查每一个函数的时候都会检查该选项,如果为 false,则不会对该函数进行优化。
由于 flag_ipa_ra 是一个全局选项,并不是函数粒度的,notrace 也无能为力。因此,这里可以排除对 notrace 的顾虑。
安全性保障:得出结论
经过上述的探索分析以及官方资料的查阅,我们可以得出结论:
内核函数的热替换,利用 jump 指令直接跳转到新函数的方式是安全的;
论据:
Linux 遵循的 System V ABI 中的 call conversion 在 x86-64 下有且只有一种;
GCC -fipa-ra 选项会对 call conversion 进行优化,-O2 选项会自动使能该选项,但是 -pg 选项会禁用 -fipa-ra 优化选项;
notrace 属性无法绕过“ -pg 禁用 -fipa-ra”。
ARM64 下的探索验证
通过翻阅手册得知,ARMv8 ABI 中对过程调用时通用寄存器的使用准则如下
(资料来源:https://developer.arm.com/documentation/den0024/a/The-ABI-for-ARM-64-bit-Architecture/Register-use-in-the-AArch64-Procedure-Call-Standard/Parameters-in-general-purpose-registers):
Argument registers (X0-X7)
These are used to pass parameters to a function and to return a result. They can be used as scratch registers or as caller-saved register variables that can hold intermediate values within a function, between calls to other functions. The fact that 8 registers are available for passing parameters reduces the need to spill parameters to the stack when compared with AArch32.
Caller-saved temporary registers (X9-X15)
If the caller requires the values in any of these registers to be preserved across a call to another function, the caller must save the affected registers in its own stack frame. They can be modified by the called subroutine without the need to save and restore them before returning to the caller.
Callee-saved registers (X19-X29)
These registers are saved in the callee frame. They can be modified by the called subroutine as long as they are saved and restored before returning.
Registers with a special purpose (X8, X16-X18, X29, X30)
X8 is the indirect result register. This is used to pass the address location of an indirect result, for example, where a function returns a large structure.
X16 and X17 are IP0 and IP1, intra-procedure-call temporary registers. These can be used by call veneers and similar code, or as temporary registers for intermediate values between subroutine calls. They are corruptible by a function. Veneers are small pieces of code which are automatically inserted by the linker, for example when the branch target is out of range of the branch instruction.
X18 is the platform register and is reserved for the use of platform ABIs. This is an additional temporary register on platforms that don't assign a special meaning to it.
X29 is the frame pointer register (FP).
X30 is the link register (LR).
Figure 9.1 shows the 64-bit X registers. For more information on registers, see . For information on floating-point parameters, see Floating-point parameters.
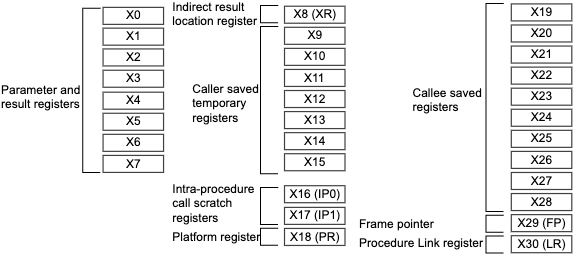
Figure 9.1. General-purpose register use in the ABI
可见,ARMv8 ABI 中对函数调用时的寄存器使用有了明确的规定。
我们对于前面 x86-64 下的探索验证过程在 arm64 平台下重新做了测试,相同的代码和相同的测试过程,得出的结论和 x86-64 下的结论是一致的,即,在 arm64 下,直接利用 jump 指令实现函数替换同样是安全的。
其它场景的讨论
其它语言不能保证其安全性
对于 C 语言而言,在不同的架构和系统下都有固定的 ABI 和 calling conventions,但是其它的语言不能保证,比如 rust 语言,rust 自身并没有固定的 ABI,比如社区对 rust 定义 ABI 的讨论,而且 rustc 编译器的优化和 gcc 可能会有不同,因此可能也会出现上述 caller/callee-save 寄存器的问题。
kpatch 的真面目
kpatch 利用的是 ftrace 进行函数替换的,它的原理如下所示:

图11 kpatch 利用 ftrace 替换函数
ftrace 的主要作用是用来做 trace 的,会在函数头部或者尾部 hook 一个函数进行一些额外的处理,这些函数在运行过程中可能会污染被 trace 的函数的寄存器上下文,因此 ftrace 定义了一个 trampoline 进行寄存器的保存和恢复操作(图11 中的红框),这样从 hook 函数回来后,寄存器现场仍然是原来的模样。
kpatch 用 ftrace 进行函数替换,hook 的函数是 kpatch 中的函数,该函数的作用是修改 regs 中的 ip 字段的值,也就是将新函数的地址给到了 ip 字段,等 trampoline 恢复寄存器现场后,就直接跳转到新的函数函数去执行了。所以,对于 kpatch 而言,ftrace 的保存和恢复现场操作保护的是 kpatch 中修改 ip 字段函数的过程,而不是它要替换的新函数。
如果修复的是一个热函数,那么 ftrace 的 trampoline 会对性能产生一定的影响。所以,若考虑到性能的场景,那么使用 jump 指令直接替换函数可以很大的减少额外的性能开销。
关于作者
邓二伟(扶风),2020 年就职于阿里云操作系统内核研发团队,目前从事 linux 内核研发工作。
吴一昊(丁缓),2017 年加入阿里云操作系统团队,主要经历有资源隔离、热升级、调度器 SLI 等。
陈善佩(雏雁),高级技术专家,兴趣方向包括:体系结构、调度器、虚拟化、内存管理。
讨论这么热烈,怎么能少了组织沉淀?
Cloud Kernel SIG 盛情邀请你的加入
云内核 (Cloud Kernel) 是一款定制优化版的内核产品,在 Cloud Kernel 中实现了若干针对云基础设施和产品而优化的特性和改进功能,旨在提高云端和云下客户的使用体验。与其他 Linux 内核产品类似,Cloud Kernel 理论上可以运行于几乎所有常见的 Linux 发行版中。
在 2020 年,云内核项目加入 OpenAnolis 社区大家庭,OpenAnolis 是一个开源操作系统社区及系统软件创新平台,致力于通过开放的社区合作,推动软硬件及应用生态繁荣发展,共同构建云计算系统技术底座。
扫码进群,侃侃而谈

打开钉钉扫一扫哦
点击“阅读原文”即可直达 Cloud Kernel SIG🚀
如有侵权请联系:admin#unsafe.sh