[原]Python爬虫编程思想(38):项目实战:抓取糗事百科网的段子
本节的项目会使用requests库抓取糗事百科网的段子,读者可以用下面的URL访问访 2021-10-05 23:12:31 Author: blog.csdn.net(查看原文) 阅读量:41 收藏
本节的项目会使用requests库抓取糗事百科网的段子,读者可以用下面的URL访问访 2021-10-05 23:12:31 Author: blog.csdn.net(查看原文) 阅读量:41 收藏
本节的项目会使用requests库抓取糗事百科网的段子,读者可以用下面的URL访问访问糗事百科段子页面。
https://www.qiushibaike.com/text
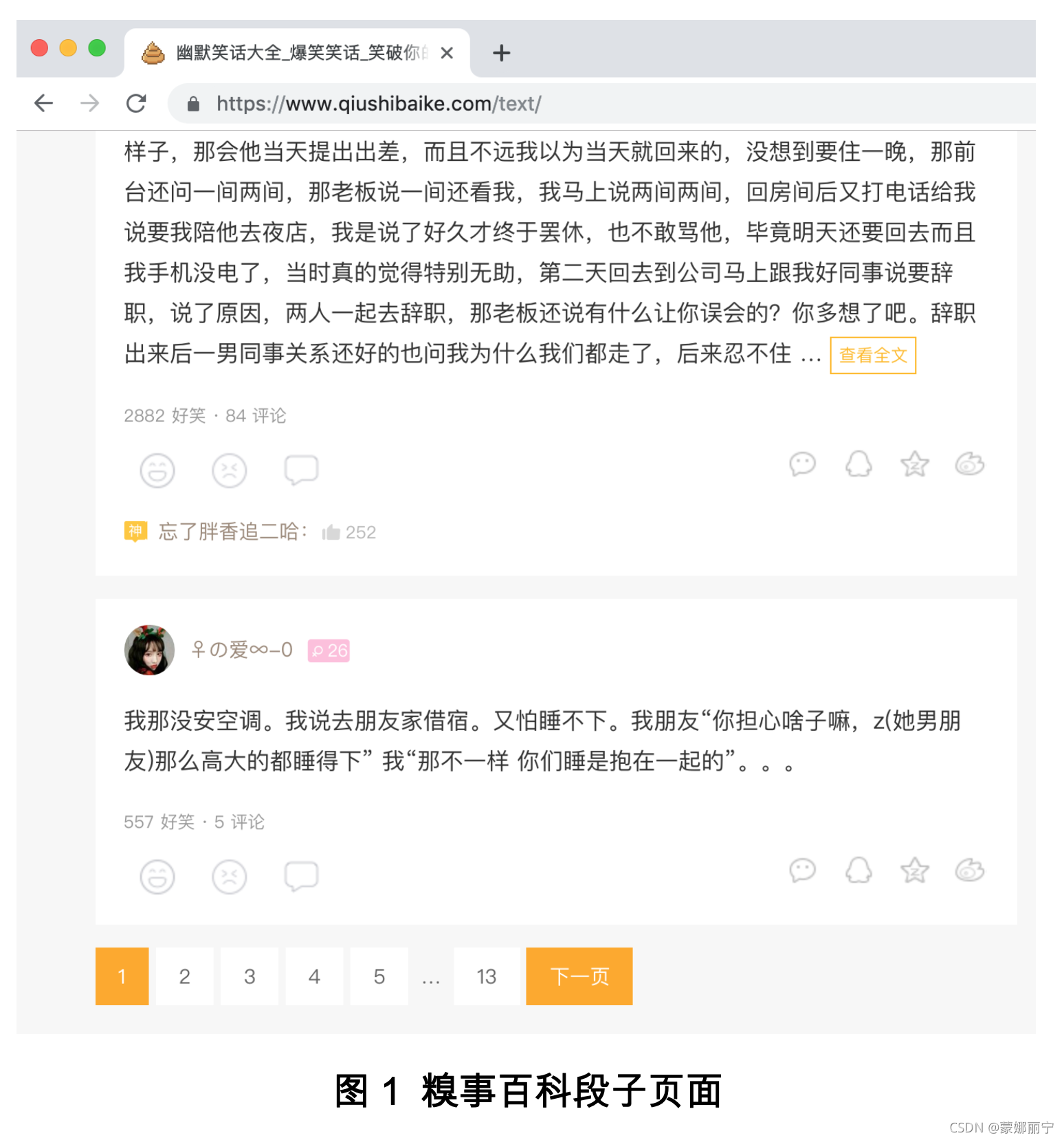
页面如图1所示。
在页面的下方是带有数字链接的导航条,可以切换到不同的页面,每一页会显示一定数量的段子。所以要实现抓取多页段子的爬虫,不仅要分析当前页面的HTML代码,还要可以抓取多页的HTML代码。
现在切换到其他页面,看一下URL的规律。第1、2、3也对应的UR
文章来源: https://blog.csdn.net/nokiaguy/article/details/120619290
如有侵权请联系:admin#unsafe.sh
如有侵权请联系:admin#unsafe.sh