
阅读: 7
一、引言
近年来,人工智能(Artificial Intelligence)技术在生物医疗、金融风控、自动驾驶、网络安全等许多领域被广泛应用。基于数据驱动的机器学习技术在识别与分类等任务上已经具备稳定且精确的效果,在许多具体任务中,基于机器学习技术的方案不光能取得比传统技术方案更好的效果,还可以完成一些传统技术难以完成的任务。训练一个机器学习模型包含了大量工作,往往需要经年累月的投入才能得到高效稳定的成品模型,然而窃取和拷贝他人训练好的机器模型却十分容易[1][2]。为了保护机器学习模型开发者的知识产权,模型水印技术应运而生。二、模型水印技术
2.1 模型水印概述
模型水印最早由KDDI研究所和国家信息学研究所的研究人员于2017年4月提出,其提出的目的是为了保护机器学习、深度学习等AI模型的知识产权。现有的模型水印技术从任务逻辑上看,都包含以下两个步骤:
1)植入水印:在模型的开发和训练阶段,向模型中采取特定策略植入数字水印;
2)提取水印:从要举证的模型中提取和恢复水印信息,将提取的水印与植入的水印进行比较,从而判断是否侵权。
不同的模型水印技术在植入水印和提取水印的策略上有所不同。大多数模型水印技术通过模型的输出来提取水印,因此这类模型水印技术的举证主要依赖目标模型的输出。另一部分模型水印技术将水印植入了模型文件中,并不在模型输出体现,这类模型水印技术在举证时就要求能够在白盒环境中访问目标模型的结构。
2.2 基于模型文件的白盒可举证水印技术
机器学习模型由模型结构和模型权重确定,针对主流任务的业界最优模型结构相对确定,而模型的权重由模型学习训练数据集得来,故模型权重是一个机器学习模型中最核心的资产。将水印嵌入模型权重可以直接对关键资产起到版权保护的作用。
前文提到,基于模型文件的水印方案要求白盒环境访问待举证的模型文件。在窃取者没有对模型进行调整的情况下,直接对比文件一致性即可判断模型文件的知识产权,为什么需要通过水印来对比呢?因为在机器学习技术中,通过微调,模型蒸馏等技术,窃取者可以在几乎不改变模型性能的情况下,修改模型的结构。模型的结构一旦被改变,模型的权重也变化了,在这样的场景下,通过对比模型文件或者对比权重的方法就无法起到举证的作用。
基于模型文件的水印技术通过模型的权重与结构承载水印信息。目前比较有代表性的两个方案,分别是将水印嵌入模型权重与将水印嵌入额外的模型结构。
2.2.1 向权重嵌入水印的方案
日本KDDI的研究人员提出了一种可以抵抗微调和模型蒸馏的水印方案[3]:将模型某一层各卷积核的权重取平均值,并展开成一个一维向量,同时生成一个只有自己指导的秘密矩阵,用梯度下降法修改模型权重,以最小化秘密矩阵和权重相乘后的乘积与身份信息序列的误差,使得秘密矩阵与权重平均值的乘积无限逼近身份信息序列。举证时将目标模型的权重按照植入水印时处理,若乘以秘密矩阵后得到身份信息序列,则表示目标模型是被窃取的模型,过程如图1所示。
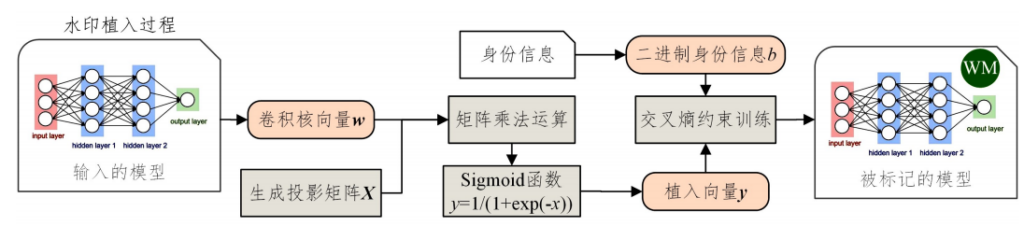

研究的实验验证了在深度神经网络通常过拟合的情况下,该方法不会对模型的准确性造成太大影响,且能够有效抵御窃取者对模型进行的fine tune和模型蒸馏。
2.2.2 添加额外层保护水印的方案
对于前面所述的模型水印方案,攻击者仍然可以通过其他方式修改模型权重来混淆原有水印,比如增加一些新训练数据对模型继续训练、通过模型水印技术给模型的权重叠加额外水印等。鉴于此,研究人员在卷积层和激活层之间加入了一个passport层[4],如图2所示。passport层中的参数由卷积层的卷积核决定,通过计算得到,且passport层中的参数不参与模型的训练。因此带有水印的卷积核一旦被修改,则passport层中的参数不再与卷积核对应,会导致机器学习模型的精确度大幅下降。该方案的水印是一种易损水印,一旦水印被破坏,模型将不再可用。
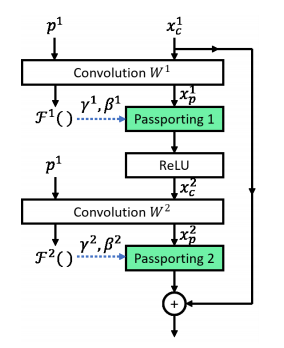
该方案的提出弥补了只依赖权重参数的水印方案的不足,使得修改权重的攻击方式无法奏效。然而从攻防对抗的角度来看,该方案一旦被模型窃取者知晓,模型窃取者通过分析窃取到的模型就可以发现passport层,在修改权重的同时同步修改带有水印的权重并计算passport层的参数,就可以在修改权重混淆水印的同时保留模型的可用性。该方案虽然增加了混淆水印的门槛和成本,但仍无法从理论上确保模型的知识产权一定可以受到保护。
2.2.3 基于模型文件的水印方案分析
从技术上看,基于模型文件的水印方案在通常是将一个身份信息序列与秘密矩阵计算后作为水印加在模型的权重中,在举证时通过秘密矩阵从权重提取水印,通过与身份信息序列比对来判断模型的知识产权。然而该类方案的实现比较复杂。此外,无论是在权重中引入水印还是增加额外层的方法,均会对模型的准确性、性能、功耗带来不良影响。
从举证难度上看,该类方案的举证要求能够获得待举证模型的白盒环境。然而现实中通过合法方式获得目标模型的白盒环境是非常困难的。因此,白盒环境举证需求是制约这类方案落地的最大因素。
从对抗上看,该类方案目前可以防御通过fine tune、模型蒸馏等迁移学习类技术来破坏水印,对于水印覆写攻击也具有一定的防御效果,但对于适应性的水印混淆攻击的防护作用较弱。由于水印技术的应用场景是假设模型窃取者已经成功窃取了模型,获得了模型的白盒信息,因此针对已知防御手段的适应性攻击是应当考虑的。
2.3 基于模型输出的黑盒可举证水印技术
基于模型结构的水印方案需要白盒环境才能进行举证,而这在现实中往往不可行。因此,基于模型输出的黑盒可举证水印方案应运而生。
2.3.1 基于对抗样本的水印方案
机器学习中有一个有趣的现象:对抗样本。即通过给一个原始输入叠加人类不可感知的扰动,使得生成的样本可以由机器学习模型将其分类为另外一个类别的特殊样本。叠加扰动后生成的样本即为对抗样本,图3即为熊猫图片在叠加特定扰动后,被以99.3%的置信度分类为长臂猿的对抗样本。

基于黑盒的模型水印方案,其中一种就是利用对抗样本技术,在模型部署前,构造一些对模型有效的对抗样本,记录下这些对抗样本的错误分类,并将其作为模型的“后门”。当这些对抗样本输入训练好的模型后,模型将输出违反常识的特定结果(如将海龟识别为冲锋枪,飞机识别成汽车等)。模型开发者将错误的分类(冲锋枪、飞机)统一成业务分类中不存在的一类(如“verify类”),在举证时通过一系列这样的“后门”触发,并全部被分类为一个特殊的类,来证明模型的知识产权[5]。
2.3.2 在输出嵌入水印的方案
另一种黑盒模型水印方案通过生成对抗网络技术(GAN)训练嵌入器和提取器,在模型的输出中嵌入不影响人类感知,但可通过提取器提取出来的水印。
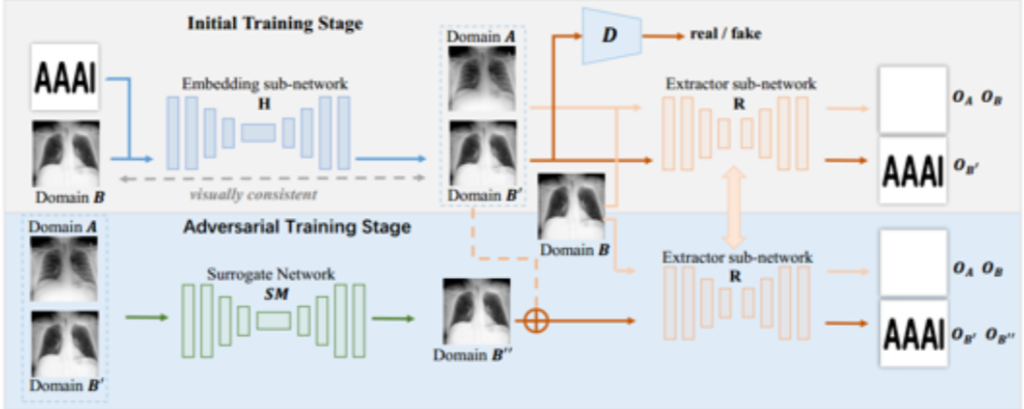
该方案包含三个模型:嵌入器模型、提取器模型、GAN生成网络。嵌入器H负责嵌入水印,将水印domain A嵌入到无水印的domain B中得到domain B’。提取器R负责提取水印,对于含有水印的图片,能够提出原水印图片,对于不含水印的图片,要求网络不能提出水印。
GAN生成网络SM负责由不带水印的domain A和带水印的domain B’合成 domain B’’(模拟攻击者对输出的混淆),此时以提取器R为判别模型,要求提取器R对于domain B’与domain B’’,都能够提取出原水印。通过对抗生成训练,提高提取器R在输出混淆场景下的提取效果[6]。
2.3.3 基于模型输出的水印方案分析
从技术上看,基于对抗样本的方案实现比较简单,只要构造对模型效的抗样本即可。模型开发者有模型的全部信息,生成有效的对抗样本是比较容易的。在输出嵌入水印的方案,实现非常复杂,需要投入的工作很多。此外,该方案需要模型的输出包含足够多的信息才能隐藏水印到输出里,若模型的输出本身包含的信息就很小(如某图像分类任务的模型,输出只包含分类类别的id和置信度的数字),水印将很难嵌入。
从举证难度上看,基于对抗样本的水印方案举证环境较白盒方案要容易获得,只需要能够给模型进行指定输入,并能够获取模型的输出即可。而输出嵌入水印的方案,由于处理水印提取任务的提取器R通常是一个深度神经网络(如Unet),该网络缺乏可解释性,导致如何解释水印的嵌入与提取成为一个问题,可能会对举证产生影响。从对抗上看,针对对抗样本后门水印,攻击者不光可以通过对模型进行迁移训练、对抗训练、或引入对抗样本检测机制等方式使得全部或部分“后门”无法触发;更可以通过检查模型分类类别是否和业务逻辑分类一致,剔除不在业务范围内的分类(“verify类”)或在模型输出的结果中做白名单校验来使后门无法按照设定被触发。而在输出嵌入水印的方案中,由于对提取器R进行了生成对抗训练,使得提取器R对于输出混淆具备一定的判别能力。然而该方案的水印嵌入器是一个独立的模型,要实现嵌入水印的效果,就必须将嵌入器与业务神经网络进行串联并放到一个文件中。基于窃取者已获得模型白盒信息的场景,攻击者仅需具备一定的机器学习常识,就能轻易地将这块“明显冗余”的网络从业务必要的业务模型中剔除。
基于输出的黑盒可提取方案的优势在于不需要白盒环境即可进行举证。然而总体上看,上述黑盒可举证的模型水印方案仍有明显的不足。例如,基于对抗样本“后门”的水印方案很容易无法抵抗基于迁移学习的攻击;此外,给输出加入水印信息的方案实现复杂,且局限于输出信息量较大的场景,从而导致技术落地的局限性较大。
另一方面,由于基于黑盒的水印方案依赖模型的输出来进行举证,因此在窃取模型的输出只作为系统中间结果而不直接暴露给用户的场景下,将仍然无法在黑盒环境下完成举证。窃取者还可以采用其他一些技术手段,如对输出进行加密、给输出叠加噪声等方式增加举证的难度。
三、模型水印技术的挑战
模型水印技术于2017年提出,到目前才经历短短4年发展,因此是一个仍然处于快速发展期的技术。从技术上看,模型水印技术均或多或少地给模型引入了额外的计算或“后门”,这对于模型的可用性均会造成一定的影响,且目前大多数水印方案的研究仍然局限在图像领域(卷积神经网络、图像样本),部分水印方案局限于特定的任务(图像生成任务),上述因素均对目前水印技术的落地存在明显的制约。
从举证难度的角度上来看,不论是白盒水印还是黑盒水印,从根本上来说都需要依赖模型文件或模型输出,而实际情况中这两个信息均不是一定会对外暴露的。此外,基于模型知识产权的纠纷目前也没有案例,由于模型水印技术需要一定的机器学习知识才能理解,且部分方案使用可解释性较弱的神经网络来提取水印。因此在实际举证时这些方案是否能够被普遍认可,仍然有待观察。
从对抗上来看,针对已有方案的适应性攻击可以绕过大多数水印方案。在窃取者成功窃取到模型的前提下,假设窃取者具备和水印嵌入方同等的知识,窃取者就可以将水印嵌入机制从模型中剔除,或者伪造自己的水印。传统的水印技术面向的是资源或内容被窃取的场景,而模型水印技术面向的是一个独立的计算流程被窃取的场景,在后一种场景下,想要保证在该计算流程中嵌入的水印不被绕过是相当困难的。
虽然模型水印技术在各个维度上都面临严峻的挑战,但是随着机器学习技术在各领域中越来越普遍的应用,模型的知识产权是一个不容忽视的问题。模型水印技术未来的研究应考虑对各类模型的兼容性、举证方法可解释性、举证环境易获得、难以被混淆等几个方面的问题。现阶段模型水印技术仍不够成熟的情况下,做好机器学习模型的保护,防止其被窃取,是保护模型知识产权的重中之重。
四、总结
随着AI应用规模持续增长,模型的知识产权也逐渐受到了业界关注。AI模型的知识产权主要体现在权重,而权重自身不具备可解释性,且按照一定策略对权重微调不会影响模型功能,因此传统的水印技术和白盒审计均不能满足明确模型知识产权的需求。
现有的各类模型水印方案在特定条件下均可以起到一定的模型知识产权保护效果。然而基于模型结构的白盒水印方案存在举证困难与影响模型可用性的问题,且在攻击者取得模型白盒信息的前提下无法确保水印不被删除或篡改;基于模型输出的黑盒水印方案一方面需要考虑对不同种类神经网络输出的覆盖与兼容,另一方面需要考虑攻击者对输出进行混淆或屏蔽对举证产生的影响。
面向AI模型自身特性的模型水印技术是解决模型知识产权问题的关键。提高模型水印方案的通用性,减小模型水印对模型可用性的影响,以及抵御适应性攻击是模型水印技术未来研究的主要方向。
参考文献
[1]TRAMÈR F, ZHANG F, JUELS A, et al.Stealing machine learningmodels via predictionapis[C]∥Proceedings of the 25th{USENIX}Security Symposium ({USENIX}Security 16.2016:601G618.
[2]XIE Chen-qi, ZHANG Bao-wen, YI Ping. Survey on Artificial Intelligence ModelWatermarking[J]. Computer Science, 2021, 48(7): 9-16.
[3]UCHIDA Y,NAGAI Y,SAKAZAWA S, et al.Embedding watermarks intodeep neural networks[C] ∥Proceedings of the 2017 ACMon International Conferenceon Multimedia Retrie-val.2017:269G277.
[4]FAN L,NG K W,CHAN C S.Rethinking deep neuralnetwork ownership verification: Embedding passports to defeat ambiguityattacks[C] ∥Proceedings of the Advances in Neural InformationProcessing Systems.2019:4714G4723.
[5]ADI Y,BAUM C,CISSE M, et al.Turning your weaks into astrength: Watermarking deep neural networks by backdooring [C] ∥Proceedings of the 27th {USENIX} Security Symposium.2018:1615G1631.
[6] Zhang J, Dongdong C, etal. (2021, March 8). Deep Model Intellectual Property Protection via DeepWatermarking. ArXiv.Org. https://arxiv.org/abs/2103.04980
版权声明
本站“技术博客”所有内容的版权持有者为绿盟科技集团股份有限公司(“绿盟科技”)。作为分享技术资讯的平台,绿盟科技期待与广大用户互动交流,并欢迎在标明出处(绿盟科技-技术博客)及网址的情形下,全文转发。
上述情形之外的任何使用形式,均需提前向绿盟科技(010-68438880-5462)申请版权授权。如擅自使用,绿盟科技保留追责权利。同时,如因擅自使用博客内容引发法律纠纷,由使用者自行承担全部法律责任,与绿盟科技无关。