
![]() , Aug 18, 2021 5:21:17 PM
, Aug 18, 2021 5:21:17 PM
Breaking down the importance of explainability in machine learning
This post was written by the following Avast researchers: The automated detection of threats — by analyzing emails, downloaded files, log files, or browsing history, for example — is a key requirement of today’s cybersecurity products. Machine learning (ML) is a great tool for achieving this automation, but most applications are black box — in other words, the models provide detections with little or no context or explanation. This is problematic for humans (more specifically, the security analysts that handle threat response, the developers that maintain protection systems and sometimes even the users who rely on the products for protection) because it makes it difficult to understand and trust the product’s performance, track down and correct spurious detections, investigate newly emerging or zero-day threats, and even ensure fairness and compliance. For these reasons and more, machine learning explainability has emerged as a hot topic in cybersecurity AI/ML. The aim of explainability is simple: to make it possible for humans to understand how a machine learning model made its decisions. The details are the hard part. In this blog post, we briefly discuss one approach that we’ve developed at Avast. Figure 1. Explainability for AI/ML in cybersecurity is an emerging hot topic for its role in developing better-performing, more usable automated protection systems. (Image credit: Mark Long, nbillustration.co.uk) Let’s take a moment to discuss explanations. What are they? What do they look like? In classical supervised machine learning, we collect a dataset of pairs of instances and labels. Consider, for example, a food dataset, D = {(apple, fruit), (butter, fat),(chicken, protein)}, where apple, butter, and chicken are instances and their corresponding labels are fruit, fat, and protein. With a dataset in hand, we proceed to train a machine learning model, a classifier, so that it learns to predict the label for any future instance of food. Our classifier would hopefully predict that beef is a protein. In practice, our instances are not simple values, but vectors of values or more complicated data structures like JSON. For example, food items may be represented by quantitatively measured attributes like weight, color, size, sphericity, stem_present, has_seeds, and so on. During the training process, the classification model learns how to map the specific attributes of each input into the predicted label. Back to explanations: We define explanation by saying that an explanation denotes the subset of elements in a sample which have the highest influence on a machine learning model’s output. In our food detection example, it amounts to identifying which attributes are most important for predicting the food label. Note that this is a very machine-learning centric definition. In the world of security analysts, for example, good explainability would also require a description of “why” these attributes are important. For example, a tomato is a fruit. In our classifier, the explainability might give most emphasis to the feature has_seeds when it classifies a tomato as fruit. For a security analyst, however, this wouldn’t be a satisfying explanation without a description of why, for example, “by definition all fruits have seeds.” In cybersecurity, one of our primary sources of information is machine data, particularly JSON logs. Here is an example snippet from a JSON log: In a previous blog post, we showed how our team takes advantage of our ability to learn from JSON using a new technique that we pioneered called Hierarchical Multiple Instance Learning (HMIL). Learning from JSON is tricky because of the tree-like structure of the data, so make sure to check out that post for more insights. One of our key results is that we develop models designed for human explainability: they pinpoint specific elements in JSON instances that determine how our model makes predictions. The great thing about this is that the explainability is very natural for humans, especially our security analyst stakeholders: they can see explicitly which parts of JSON are important and decide if that makes sense or not. (For the ML nerds still reading, we’ll point out that we generate our explanations in input space — the raw data domain, JSON in this discussion — in contrast to generating explanations for a feature space, or by creating surrogate models. Compare this to an overview of explanation techniques for more details). Figure 2. A comparison of explanations. In black box ML models, explanations are typically opaque and are presented as some numeric vector of features that is not directly connected to the raw data. In techniques like HMIL, explanations are generated in input space — e.g., the raw data. A JSON explanation in input space would explicitly indicate the exact JSON key-value pairs used by a model in decision-making. For example, a JSON object {car: blue, doors: [front_left, front_right, hatchback], dimensions: [width:1700, length:3800, height:1400], transmission: automatic} might provide an explanation of {height/1400, doors/hatchback} for a ML model prediction of “city car”. Our HMIL models are used in many backend systems at Avast. They provide predictions, usually of maliciousness of a potential threat, and we augment the predictions with an explanation. To obtain an explanation, we need a function that assigns a weight to any possible subset of key-value pairs present in a JSON sample. Such a function should express how much a given subset of key-value pairs contributes to the correct Neural Network verdict for the sample that we classify. It can be also extended to put more weight on subsets of certain properties, for example, to prefer smaller subsets to larger ones (it is way easier for us humans to read “that apple is rotten” than “that fruit which is 87% likely an apple, with a stalk, has a brown stain on its side which is 79% likely a sign of rot”). Once we have such a function, we can just find the subset with the highest function value. ...Or can we? In practice, this straightforward approach is often prohibitive, due to computational complexity. In cybersecurity, we use ML models to classify very large samples, with thousands of key-value pairs in a single JSON sample. Imagine a sandbox log that captures all activity of an executable file over a couple of minutes on a lightning-fast computer. The number of possible key-value pairs in such a large sample can be comparable to the number of particles in the visible universe. Therefore, we need to trade speed for optimality and employ a simpler mechanism to identify good key-value pair subsets. The rescue comes from the idea of Banzhaf power index, which is “defined by the probability of changing an outcome of a vote where voting rights are not necessarily equally divided among the voters”. The crucial question here is how often a voter has the swinging vote across various coalitions. The analogy, in our case, is how often a given key-value pair significantly contributes to the correct neural network prediction when evaluated across various subsets of key-value pairs. More specifically, we assign each key-value pair a weight proportional to the difference between average neural network response on subsets with the given key-value pair, and the average neural network response on samples without the given key-value pair. In practice, it turns out that to compute the averages, it’s not necessary to evaluate all possible subsets; it’s sufficient to randomly sample a thousand or merely hundreds of various subsets. The weight thus assigned to each key-value pair expresses well the average contribution of the given key-value pair to the correct neural network decision about the JSON sample. The last step is to utilize the ordering of key-value pairs to obtain the explanation, in other words, the subset of key-value pairs that have the biggest impact on the correct neural network verdict. An explanation can be constructed by gradually selecting key-value pairs according to the Banzhaf ordering, highest value first, until the set of selected key-value pairs becomes sufficient to yield the desired ML model’s response. Let us illustrate a machine data explanation using an example from the Kaggle Challenge Device Type classification problem. In this application, each JSON sample captures the behavior of a device in a computer network. Device types can include phones, TVs, IoT devices, and so on When a trained HMIL neural network infers the type of device from its JSON representation, a small subset of key-value pairs usually suffices for correct device type identification. In Figure 3, we illustrate how such a subset can be identified using the Banzhaf values. Figure 3. Explaining what part of a device's JSON representation has the highest impact on ML model confidence about the device type. To compute the explanation, first a series of randomly sub-sampled versions of the original JSON is generated (see the table on the right; each row depicts by black boxes which of the original key-value pairs are preserved). The confidence of the ML model on each sub-sampled JSON is evaluated and recorded (value on the right). Eventually, for each key-value pair, a Banzhaf value is computed; key-value pairs whose presence in sub-sampled JSONs correlates with higher ML model confidence values receive higher Banzhaf values (see the histogram in bottom right). Key-value pairs with highest Banzhaf values are then included in an explanation. In this example, the algorithm yields the highest Banzhaf value for mac:80:5e:c0:41:ad:39, second highest for services:up:5351, and third highest for services:tcp:80. Note that the Banzhaf value for mac:80:5e:c0:41:ad:39 is notably high. In this case, the neural network clearly learned to make its verdict based almost solely on mac:80:5e:c0:41:ad:39. Also note that on the other end of the Banzhaf ordering, ip:192.168.0.147 received the lowest value. This signifies that ip:192.168.0.147 is of no use to the neural network in this case. We use explanations on a daily basis for: The standard essential problem in supervised machine learning is ensuring that the models are properly trained, which is to say that the true discriminative information has been learned and is used during inference. It is standard practice to evaluate models statistically. Statistical tests help assess the model’s properties including the ability to generalize; however, they still do not guarantee that all is well. Models can learn data features that are spurious — imagine capturing device’s artifacts in data or unintentionally logged time stamps, which can contribute to a false impression that the model performs well. In reality, such a model would fail when deployed to a real production environment where artifacts and debugging information is no longer present. Therefore, it’s good practice to perform sanity checking using explainability techniques, especially on newly constructed models, to prevent otherwise hard-to-detect spurious detections. What if a model categorizes a new unknown file as suspicious or malicious, even if other indicators suggest there is nothing wrong with the file? Explanations on raw machine data help us to get better insight into the file, as illustrated below on a dynamic log sample. { Behavior.summary.executed_commands[]: "C:\Users\John\AppData\Local\Prostituting.exe" vanzmwvanzmwvanzmwvanzm.vanzmyvanzmevanzmdvanzm.vanzmpvanzmwvanzm/vanzmm2j0j1j9j1vanzmd2d2m6mjhtvanzmml62c6mMJYvanzmjBNsh6APndvanzm8v } Figure 4. What if we need to search for suspicious clues in a dynamic log of >100MB where no known “indicator of compromise” has been matched, but a model classifies the log as not clean? Explainability can pinpoint a short section in the log file which the model relied on for its prediction. In this example, the explainability points to a launch command which we see is very suspicious because of the executable name and the command line parameter that is passed. An explanation may give decisive proof or, as illustrated in Figure 4, enough supporting information to justify further deeper analysis of the file. Exploiting the power of machine learning in many fields is hindered by its “black-box” nature and the consequent lack of trust in predictions. In cybersecurity, where many ML applications deal with machine data and where predictions often need to be further analyzed by experts, this problem becomes particularly pressing. In this blog post, we have shown how to take advantage of the fact that machine data is often stored in JSON format. We’ve also demonstrated a straightforward technique for generating ML explanation by pinpointing specific key-value pairs inside JSON data that are crucial for correct classification. At the moment, the technique serves Avast teams in the verification of ML detections and debugging of ML models. The specific tools and scripts we use to learn from JSON files have been open sourced on GitHub in cooperation with Czech Technical University.
Petr Somol, Avast Director AI Research
Tomáš Pevný, Avast Principal AI Scientist
Andrew B. Gardner, Avast VP Research & AI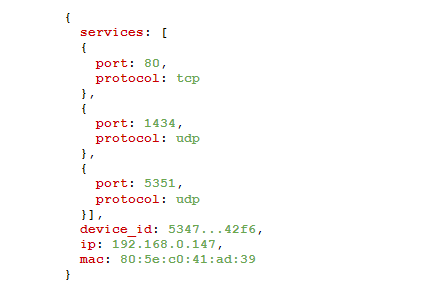 Figure 1. A simple JSON example of machine data encoding a behavior of a device in computer network
Figure 1. A simple JSON example of machine data encoding a behavior of a device in computer networkExample: Why is that network device a TV?
ML model debugging
Finding suspected malware



![]()
![]()
![]()
如有侵权请联系:admin#unsafe.sh