在上文《基于AST的Webshell检测》中,笔者已经提出了基于抽象语法树是可以用来检测Webshell的,那么如何将这种思想应用在jsp/jspx的webshell检测便是本文讨论的重点。
简单回顾下抽象语法树的检测原来,由于webshell和正常文件在语法结构上会有比较明显的出入,比如说一句话木马普遍流程就是传参然后执行命令,转化为语法结构上其实是比较单一的,正常文件的语法结构会比这复杂的多得多,因此从语法结构上来分辨是否为webshell也是一种不错的选择。但是语法结构的缺点就是难以对具体参数进行分析,所以当出现“eval('1111');”和“eval(file_put_contents('shell.php','<?php phpinfo()'));”这种需要去区分具体数据的时候使用ast来做检测就会显得非常困难。
那么应用到java环境下,黑客的正常攻击流程就是通过web漏洞传入webshell,然后通过小马传大马的方式进行后渗透攻击,一般java环境下想要rce要么任意文件上传,要么反序列化执行命令(还有其他方法,这里只列举主流方法),所以通过任意文件上传就一定会留下文件痕迹,一般来说java的可执行文件为jsp或者jspx,一般情况下jspx是一种绕过jsp文件上传的方式,这里作一并处理。
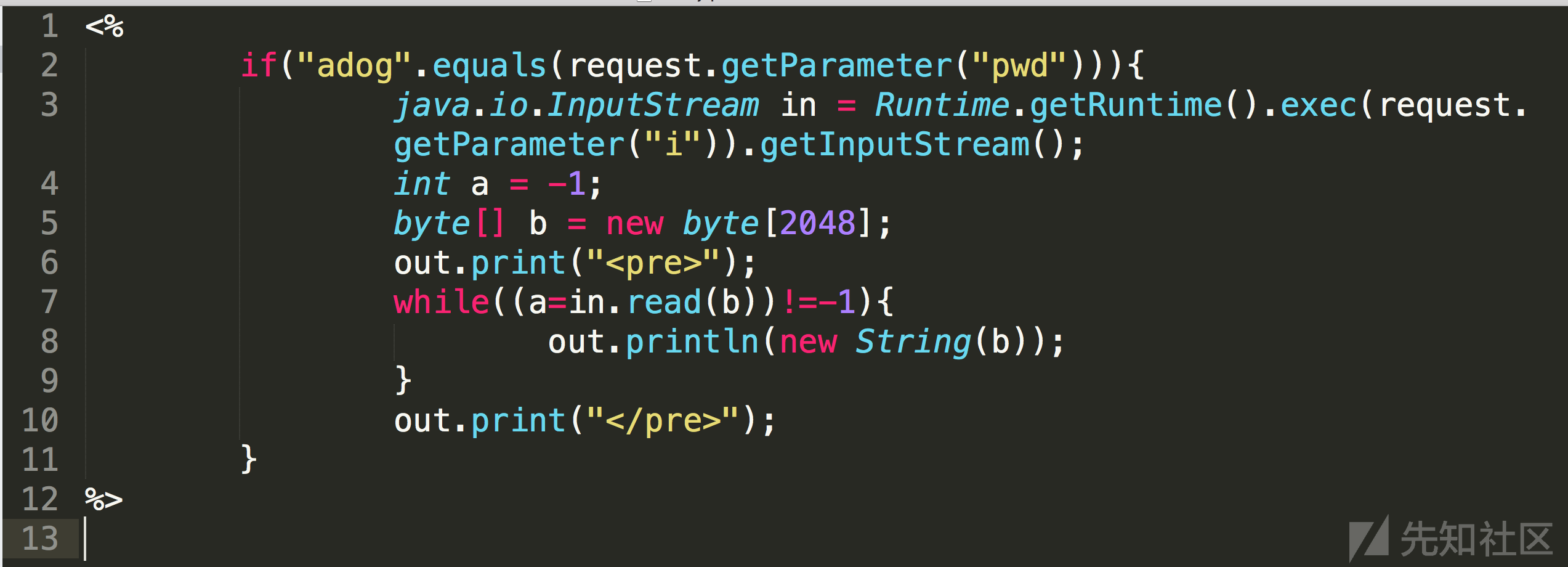
回顾前面的检测原理,jsp文件的语法结构特征其实相较于php来说,是更为明显的。原因在于一般情况下jsp文件是作页面展示用的,而具有webshell特征的jsp文件是通过传参的方式来执行命令,在语法结构上其实是有本质的区别,所以这里起码检测原理是说的过去的,并且切实可行的。
机器学习我们知道最重要的一步其实就是特征工程的构建上,那么这里jsp文件其实是没有专用的工具来解析其抽象语法树的,并且jsp文件跟php文件的最大区别就是php文件时可以直接执行的,而jsp文件其实是需要通过中间件进行编译后才能执行,那么这个问题其实就转化为了:在Tomcat等中间件服务器下,jsp文件经过了哪些处理流程?
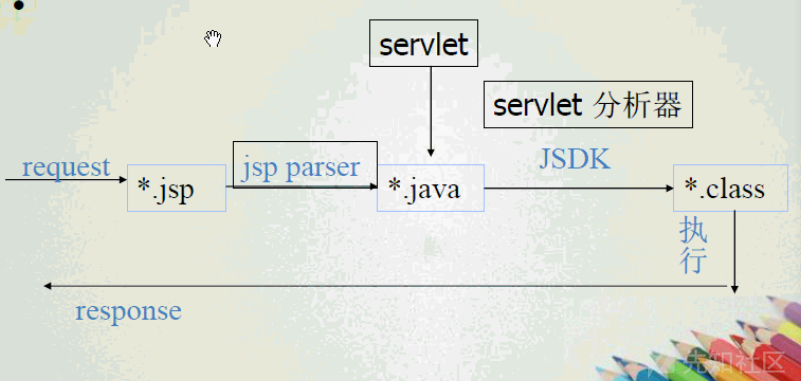
这里jsp文件首先经过jsp parse会被编译为java文件,然后通过servlet分析器将java文件编译为class文件,最后将其转化为对应的Java字节码加载执行,这中间其实有一步比较关键,那就是编译为java文件这一步。
文件编译
那么作为检测程序来说,肯定不能说让tomcat调用这程序一遍,然后直接抓编译好的java文件,那么这里就必须要先运行tomcat服务器,使其自动加载WEB目录下的程序,这对于我们自动化检测来说肯定是不可取的,如果现在想要批量检测,就必须要有自己的编译工具,所幸这里找到了tomcat中编译jsp程序的类(org.apache.jasper.servlet.JspServlet),这里其实是一个比较大的坑,这里将编译命令直接放出来。
java -cp "apache-tomcat-8.5.35/lib/*:apache-tomcat-8.5.35/bin/*" org.apache.jasper.JspC -webapp webroot -d webroot_java #直接运行可能会有点问题,需要在lib目录下加入ant.jar包 #-webapp : 指定文件目录 #-d : 指定编译后的文件目录
通过运行上述命令,我们其实就已经可以将某一个存放webshell文件的目录给转化为java文件,其中发现对于jspx文件的编译也是使用了同样的模块,所以这里也能够检测jspx的webshell。
抽象语法树的构建
针对jsp的抽象语法树构建笔者并没有找到相关工具,但是针对java的ast构建工具起码还有选择,这里使用的是javaparser这个工具来生成相应的抽象语法树

使用javaparser也比较简单,通过maven架构直接加载对应的pom信息即可
<dependencies> <dependency> <groupId>com.github.javaparser</groupId> <artifactId>javaparser-core</artifactId> <version>3.14.8</version> </dependency> </dependencies>
这里在参照了网上的大部分教程后,决定使用文件流的方式来静态编译。
public static void main(String[] args) throws Exception { String filename = args[0]; //File file = new File("src/classes/org/apache/jsp/s03_jsp.java"); File file = new File(filename); FileInputStream in = new FileInputStream(file); CompilationUnit cu = StaticJavaParser.parse(in); cu.accept(new MethodVistor(),null); }

这里的MethodVistor类其实就是语法结构类型的检测方法,比如说函数调用可能就叫MethodCall,如果是注释就叫Comment,所以说经过这个类我们就能够生成全局的语法结构节点序列。这中间并不是取了所有的语法结构特征,并且针对部分语法结构特征做了深一步处理,如函数调用可能需要进一步获取函数名等。

得到这个序列后,需要使用相关模型来将其转化为矩阵,以便后面的训练和学习,针对这种序列流模型,我采用的是tfidf模型,主要思想就是如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。这个模型其实是由词频和逆向文件频率组成的,最后表示其实就是两个参数的乘积,这个不多说,,没什么意义。。
CV = CountVectorizer(ngram_range=(1,3), decode_error="ignore",max_features=max_features, token_pattern = r'\b\w+\b',min_df=0,max_df=0.9) x=CV.fit_transform(x_all).toarray() transformer = TfidfTransformer(smooth_idf=False) x_tfidf = transformer.fit_transform(x) x = x_tfidf.toarray()
那么通过这个模型,我们就能将每个文件的ast语法结构序列给转化为一个统一的矩阵,并分别给黑白样本打上标记,进行有监督式的训练。这里黑样本来源于github上的开源仓库,白样本的获取其实有点难度,这里也是搜寻了大量的开源cms,不过白样本依然很少,原因比较简单,一个cms的jsp文件毕竟有限,所以这里唯一比较遗憾的就是数据量的问题。其中黑样本数量为632,白样本数量为470。
最后选取算法,这里参照前文的检测经验,初步选定了xgboost、随机森林、mlp等三种算法,最后经过漫长的调参和比较后,裁定各个算法的最优参数。
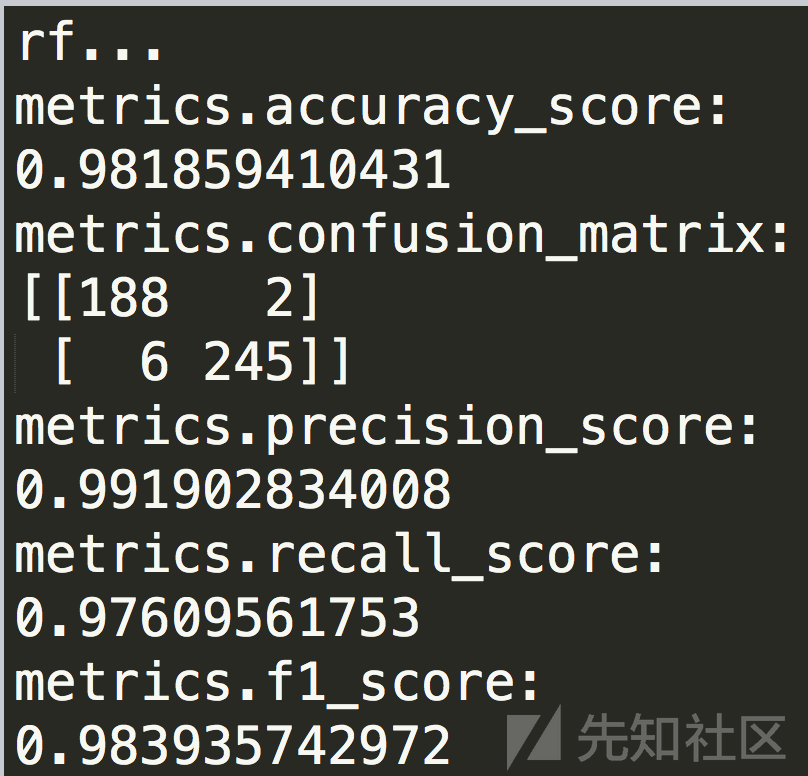
采用随机算法的检测结果
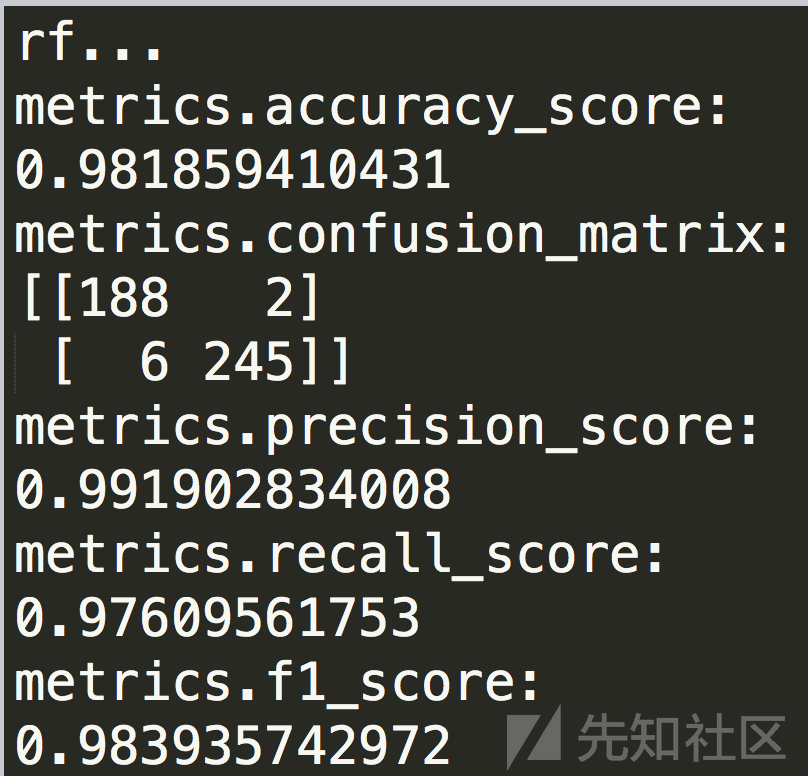
采用xgboost算发的检测结果

采用mlp算法的检测结果

回头看来,觉得整个实现思路上还是比较简单的,就是可能有几个坑点的确比较烦一点,不过感觉本文只能作为检测jsp/jspx webshell的基本思路,复杂点的还是会被绕过,如果真的想要提高检测精度,自我感觉对参数语义的检测还是非常有必要的!
上述如有不当之处,敬请指出~
如有侵权请联系:admin#unsafe.sh