



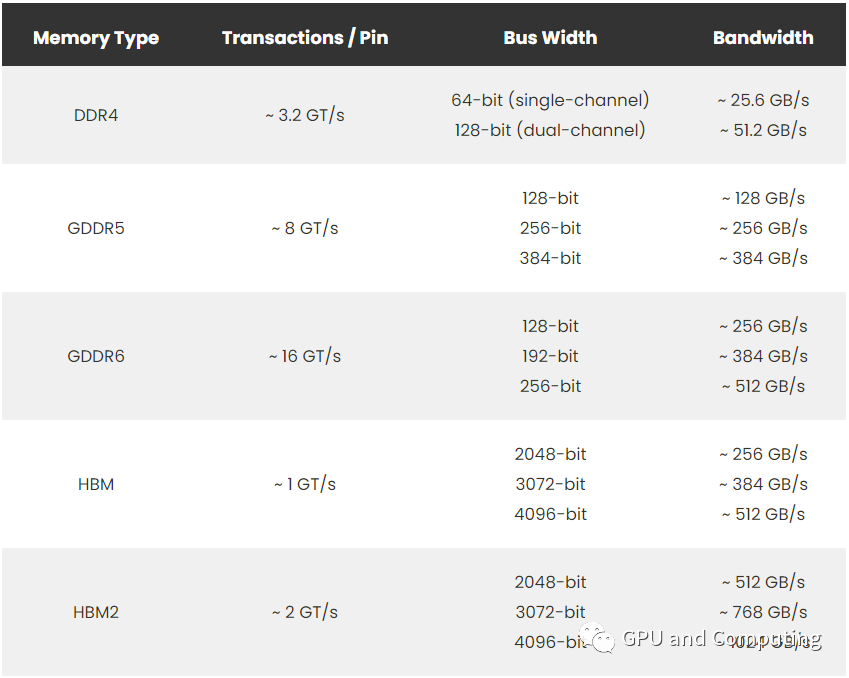
在先前的文章中《近距离看GPU计算(2)》,我们谈到GPU相比CPU有更大的内存带宽,此言不虚,这也是众核GPU有源源不断数据弹药供给,能够发挥强大算力的主要原因。如下表所示(GDDR和HBM都是GPU的显存规格),基本上GPU的内存带宽要比CPU多一个数量级。
但是考虑到GPU运算核心的数量,平均下来显存带宽真的足够富裕吗?参考资料1的《Memory bandwidth》文章提供了很有趣的视角,我们在这里介绍下。MOS 6502发布于1975年,是微型计算机发展史上非常重要的一块芯片。6502一般运行在1M时钟频率,每个时钟可以访问1Byte内存数据,6502的一条指令需要花费3~5个时钟,所以平均下来每条指令大概可以获得4B内存数据。

与此相对照,Intel的Core i7-7700K是一款目前比较主流的桌面CPU,运行频率4.2G,内存带宽大概50GB/s。i7-7700K一共有4个处理核心,所以每个核心大概可以均摊到12.5GB/s的内存带宽,也就是每个时钟可以访问约3B的内存数据。该CPU的IPC(Instruction Per Clock)为1,极优化的代码可以达到的IPC为3,按此计,每条指令可得1B的内存数据,跟老前辈6502相比,已经落后不少。更进一步,现代CPU支持256位长度的SIMD指令,每个时钟最多执行3条指令,类比GPU,我们以32位为一个通道作为单独执行线程,这样每个时钟我们一共有24条指令执行,所以每条指令可以访问0.125B内存数据或者说每8条指令得到1B内存数据。

我们再回过头来看看GPU的情形。以NVidia GeForce GTX 1080Ti为例,内存带宽484GB/s,处理单元工作频率为1.48G,所以对整个GPU来说,每个时钟大概可以访问327B内存数据。这个GPU一共有28个SM(类似CPU的处理核心),每个SM有128个SP,所以总共有3584个SP(类似先前SIMD32位通道)。这样每个SM一个时钟大概可以访问11.7B的内存数据,平均到128个SP,一个SP一个时钟得到0.09B数据,换个好听的说法就是每11条指令可以得到1B内存数据,比CPU的指标还恶劣。需要再次重申的是,因为设计目标的问题,CPU其实更关注访存延迟指标,所以相形之下,内存带宽的压力对GPU更为显著。这也是为什么我们先前说过的GPU也开始配置多级Cache的原因,除了改善访存延迟,也可以降低内存带宽压力。另外我们在《GPU历史之二三事》里也提到Nvidia和AMD都开始拥抱移动GPU常用的TBR(Tile Based Rendering)的绘制技术,内存带宽的压力也应该是重要的驱动因素。而作为软件人员,在设计算法的时候,我们要重视算法的运算强度(见《Roofline模型初步》),要充分利用片上内存包括硬件Cache和软件Cache(Shared Memory),以及注意内存的合并访问(Memory Coalescing)等等来优化内存带宽。
主要参考资料:
https://fgiesen.wordpress.com/2017/04/11/memory-bandwidth/
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果觉着内容有帮助,请帮忙关注、点赞、在看并分享给更多的朋友。谢谢!