<接上文>
0x05 WAZUH整合
现在,我们已经完成了SIEM的部分。是时候将我们的解决方案从一个简单的观察者转变为一个积极的响应者了。我们所使用到的一个很重要的工具就是Wazuh。在本章节中,我们希望能让您了解这个工具的优势,以及如何部署和使用。本章节分为以下几个部分:
5.1 Wazuh服务端和agent的安装
Wazuh是一个免费的、开源的、企业级的安全监控解决方案,用于威胁检测、完整性监控、事件响应及合规性。
你需要知道的一些定义:
Wazuh服务端:运行Wazuh manager、API和Filebeat。它从部署的agent收集和分析数据。
Wazuh agent:在被监控的主机上运行,收集系统日志和配置数据、检测入侵和异常情况。它与Wazuh server进行对话,并将收集到的数据转发到该server进行进一步分析。
5.1.1 Wazuh server架构简介
Wazuh架构基于运行在被监控主机上的agent,这些被监控主机上的日志将会转发到中心server。同时,还支持无代理设备(如防火墙、交换机、路由器、接入点等),可以通过syslog或定期探查其配置变化主动提交日志数据,随后将数据转发给中心server。中心server对接收到的信息进行解码和分析,并将结果传递给Elasticsearch集群进行索引和存储。
我们将使用单主机架构(HIDS),如下图所示:

有关其他架构的更多详细信息,可以查看官方文档:
https://documentation.wazuh.com/3.8/getting-started/architecture.html
5.1.2 Wazuh manager 、API和Filebeat安装
如下链接是wazuh安装介绍的官方文档:
安装后,必须要配置filebeat的配置文件:可以将filebeat连接到elasticsearch output 或logstash output 。在我们的例子中,我们将配置没有ssl验证的elasticsearch output(下图可以看到,只有告警模块被启用了)。
cd /etc/filebeat
nano filebeat.yml
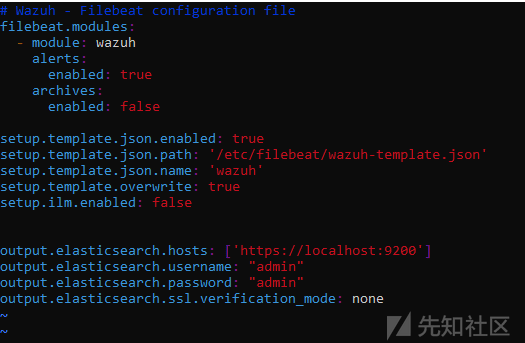
现在将设置索引模板并启动3个服务:
filebeat setup — index-management service filebeat start service wazuh-manager start service wazuh-api start


5.1.3 wazuh-agent安装
安装参考链接如下:
检查wazuh-agent是否正常运行:

5.1.4 安装wazuh app并与Kibana整合
这个app将成为Wazuh server和我们之前安装ELK的Kibana之间的桥梁。这个app只在github仓库中提供,不在官网上提供。我们将安装的wazuh app是与ELK Stack 7.6.1兼容的(这点很重要)。
cd /usr/share/kibana
sudo -u kibana bin/kibana-plugin install https://packages.wazuh.com/wazuhapp/wazuhapp-3.12.2_7.6.1.zip
建议增加Kibana的heap大小,以保证插件的安装效果:
cat >> /etc/default/kibana << EOF NODE_OPTIONS=” — max_old_space_size=2048" EOF
重启Kibana:
可以在这个网站上查看所有可用的app版本:
https://github.com/wazuh/wazuh-kibana-app
现在在kibana中,你应该看到在kibana的左边标签中出现了wazuh的符号。点击它,wazuh的api将会打开。花一些时间去探索它,你应该得到类似下图的内容。但是现在不会有任何agent连接到它。接下来的内容我们将讨论如何连接agent。

5.1.5 连接和配置agents
注册agent的方式有很多。在本文中,我们将使用手动方式。
在Wazuh manager的主机命令行中,我们将运行manage_agents来添加agent。在本例中,我们将添加一个新的agent。利用命令如下:
/var/ossec/bin/manage_agents
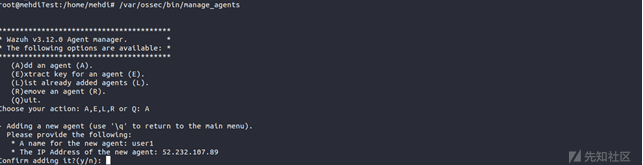
选择添加agent,输入A并回车。然后我们输入我们要给我们的机器取的名字,在本例中是user1。
我们键入终端设备的IP(注意,如果你没有终端设备的静态IP地址,你可以用关键字(any)代替IP地址)。
完成后,回车。现在我们要提取秘钥,使我们的agent能够连接到wazuh server。选择E选项并提取一个agent的密钥,然后我们输入agent的id,本例中我选择了id为001的agent。

在Wazuh manager的主机中添加了agent后,以root用户身份在agent主机中打开一个会话。之后,让我们导入密钥并将agent连接到manager。命令如下:
/var/ossec/bin/manage_agents -i “Your_Secret_key”
输入y,回车,应该能得到一个结果:

还有一个步骤,编辑/var/ossec/etc/ossec.conf中的Wazuh agent配置,添加Wazuh server的IP地址。在<client><server>部分,将manager_IP值改为Wazuh server地址。Wazuh server的地址可以是IP地址或DNS名称。</server></client>

5.1.6 检查接收到的数据
要检查ELK是否从wazuh server接收数据。进入索引管理(Index Management)。应该得到类似下图的内容(wazuh-alerts和wazuh-monitoring):

5.2 Wazuh主动响应
Wazuh提供了一个主动响应模块来处理在Wazuh-manager上配置的特定警报的自动响应。主动响应是一个脚本,被配置为在特定告警、告警级别或规则组被命中时执行。主动响应是指有状态响应或无状态响应。有状态响应被配置为在指定时间后可撤消,而无状态响应则被配置为一次性动作。
例如,如果我们想根据终端设备传过来的某些日志(显示RDP/SSH正在被暴力破解攻击),去阻断某些ip。我们可以创建一个主动响应,当攻击者的行为与存储在Wazuh上的规则集相匹配时,它就会阻止攻击者的IP。
我们将以SSH的暴力破解为例:我们将把8次登录失败视为一次攻击的尝试。当这个事件发生时,规则 "5712 — SSHD brute force trying to get access to the system"将被触发。因此,阻断IP的命令就会被执行。
首先,我们需要定义我们将用于响应的命令。
OSSEC自带了一套用于主动响应的常用脚本。这些脚本在机器的/var/ossec/active-response/bin/目录下。我们将使用firewall-drop.sh脚本(该脚本应该可以在常见的Linux/Unix操作系统中使用),它允许使用本地防火墙阻止恶意IP。
在OSSEC Manager的ossec.conf中定义命令:
nano /var/ossec/etc/ossec.conf
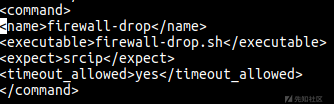
接下来,在同一个文件中,我们配置OSSEC来运行主动响应。主要的字段有:
-command: 之前定义的命令 (firewall-drop);
-location: 命令的执行位置-我们希望在agent上执行,上报事件。因此,我们使用local;
-rules_id: 如果规则5712被触发,命令就会被执行;
-timeout: 在防火墙(iptables,ipfilter等)上封禁IP 60秒。
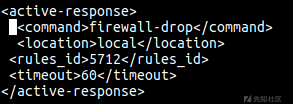
随后保存修改并关闭文件。用如下命令重启wazuh-manager:
Service wazuh-manager restart
在wazuh-agents主机上,别忘了修改ossec.conf配置文件并添加:
<active-response> <disabled>no</disabled> </active-response>
现在,你可以尝试在安装了Wazuh agent 的主机上进行SSH暴力破解测试,在8次登录失败后,你的ip将被封禁60秒。
关于Wazuh主动响应的更多细节,可以查看如下链接:
https://documentation.wazuh.com/3.7/user-manual/capabilities/active-response/how-it-works.html
0x06 告警
本章节将涵盖我们SOCaaS解决方案中的告警部分。众所周知,告警在通知安全响应团队上发挥着很重要的作用。因此,他们可以根据企业和团队的决策,中断'cyber kill chain'(网络杀伤链)或监控该攻击进一步动作。你可能好奇,为什么需要覆盖这么多告警,Open Distro的告警模块还不够吗?确实,这是因为Open Distro在输出数量上,以及与其他解决方案(如Thehive)的可集成性方面都较为欠缺。因此,我们将介绍其他替代方案。
6.1 ElastAlert、ElastAlert-Server和Praeco的安装配置
6.1.1 介绍
(1) 定义
Praeco:可以跟有通知选项的工具进行告警配置,包括 Slack, e-mail, Telegram, Jira等。
Praeco中的告警可以通过使用查询生成器选择要告警的字段及其相关操作符来组装,也可以使用Kibana查询语言(KQL)手动组装。
ElastAlert:是一个用于对 Elasticsearch 中数据的异常、峰值或其他感兴趣的内容进行告警的简单框架。它的工作原理是将Elasticsearch与规则类型和告警这两类组件相结合。Elasticsearch被定期查询,数据被传递给不同的规则类型,规则类型决定何时发现匹配。当匹配发生时,会被赋予一个或多个告警,告警会根据匹配情况采取行动。
这是由一组规则进行配置的,每个规则定义了一个查询、一个规则类型和一组告警。
Sigma规则:Sigma是一种通用和开放的签名格式,它允许你以一种直接的方式描述相关日志事件。该规则格式非常灵活,易于编写,适用于任何类型的日志文件。这个项目的主要目的是提供一种结构化的格式,研究人员或分析人员可以用这种格式来描述他们曾经开发的检测方法,并使之可以与他人共享。
(2) 项目cloning
cd /etc
git clone https://github.com/Yelp/elastalert.git
git clone https://github.com/ServerCentral/elastalert-server.git
git clone https://github.com/ServerCentral/praeco.git
更多信息查看如下链接:
https://github.com/ServerCentral/praeco
6.1.2 Elastalert配置
cd /etc/elastalert
mkdir rules rule_templates
cp config.yaml.example config.yaml
nano config.yaml
elastalert 配置文件config.yaml的配置如下:
es_host: localhost writeback_index: elastalert_status # 将rules_folder配置为rules rules_folder: rules
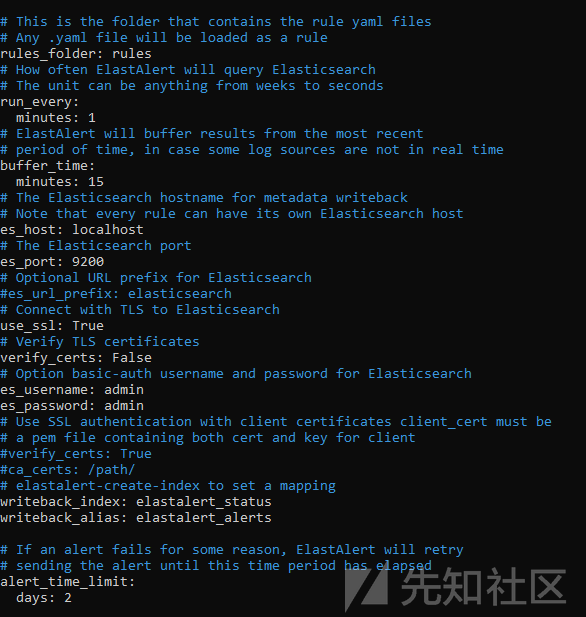
注意:如果你运行的是python 2.7版本,必须改成3.6版本。

(1) Ubuntu上安装python 3.6:
sudo add-apt-repository ppa:deadsnakes/ppa sudo apt update sudo apt install python3.6
(2) 更新python配置:
sudo update-alternatives — install /usr/bin/python python /usr/bin/python2.7 sudo update-alternatives — install /usr/bin/python python /usr/bin/python3.6
(3) 更改python默认版本:
update-alternatives — config python
选择python 3.6,如下图所示:

现在默认版本应该是python 3.6了。
(4) 安装pip3:
sudo apt install python3-pip
(5) 还要安装PyYAML(本例是5.1版本):
(6) 安装Requirement和elastalert:
cd /etc/elastalert pip3 install “setuptools>=11.3” python setup.py install
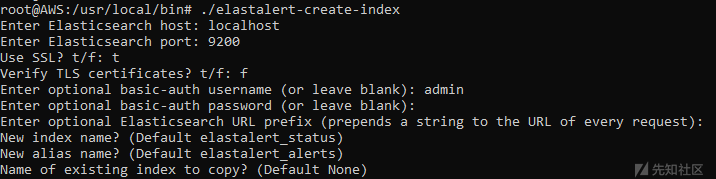
(7) 创建索引:
cd /usr/local/bin/
./elastalert-create-index
安装时,命令终端中的几个选项:
ES Host : localhost
ES Port : 9200
Use ssl : t
Verify ssl :f我们将使用默认的ES用户名和密码 : admin/admin,其他问题直接默认:
6.1.3 API server配置
/etc/elastalert-server/config/config.json中使用如下配置去配置API server:
- elastalertPath(配置成你的elastalert目录的绝对路径):
/etc/elastalert - es_host(你的elasticsearch实例地址):
elasticsearch - writeback_index(与config.yaml中一样):
elastalert_status

(1) Alert Logs的相关问题排除(没有数据):
该问题的原因是:日志告警回写索引的元数据处理程序正在搜索带有_type的elastalert文件。自 7.x 以来,不会返回任何结果,因为所有文件都有一个 _doc的 _type。
因此,在您的Alert Logs中(后期在Praeco界面),看不到任何数据。
所以必须执行如下命令:
cd /etc/elastalert-server/src/handlers/metadata/
nano get.js
删除包含type: 'elastalert'的行。现在应该能够在praeco界面上看到告警日志。


(2) Elastalert-Server安装:
sudo npm install sudo npm run start
如果成功启动,应该看到下图的这一行(有个warning警告是因为不安全的连接SSL_verify = False产生的)。

6.1.4 Praeco配置
(1) 更改配置文件:
cd /etc/praeco/config
nano api.config.json



(2) 安装Praeco:
export PRAECO_ELASTICSEARCH=localhost
(3) 复制BaseRule.cfg:
在开始服务之前,需要执行如下命令:
cp /etc/praeco/rules/BaseRule.config /etc/elastalert/rules/
此文件包含Slack、SMTP和Telegram的设置,这里我们将添加0x03章节中使用的Slack Webhook URL。
cd /etc/elastalert/rules/
nano BaseRule.config
添加Webhook URL:

(4) 启动Praeco:
现在,您应该在 http://yourServerIP:8080 上看到正在运行的页面,这是你的Praeco界面。

6.2 规则创建
6.2.1 使用Praeco界面创建规则,并将其发送到slack webhook
Navigate to Rules -> Add Rule:

现在,可以看到创建规则非常类似于Open Distro告警工具,我们将过滤告警并指定目的地。
点击 "UNFILTERED",手动或使用预建工具指定过滤器。然后单击 "Close"。

我们将使用Slack进行通知,使用与0x03章节中使用的Webhook URL,以及相同的频道( #test)。



点击'Save'。你的告警默认启用。

我们可以检查告警是否成功发送到Slack。

在我们的slack频道中:

6.2.2 从ElastAlert向TheHive发送告警
不过遗憾的是,Praeco无法直接将告警输出到 TheHive,所以我们得手动编辑我们的规则,并使用elastalert-server发送。有了这个变通方法(使用Elastalert-server),规则将在后台正常工作,也将出现在Praeco界面上。但是,我们将无法使用Praeco界面编辑或配置它们。
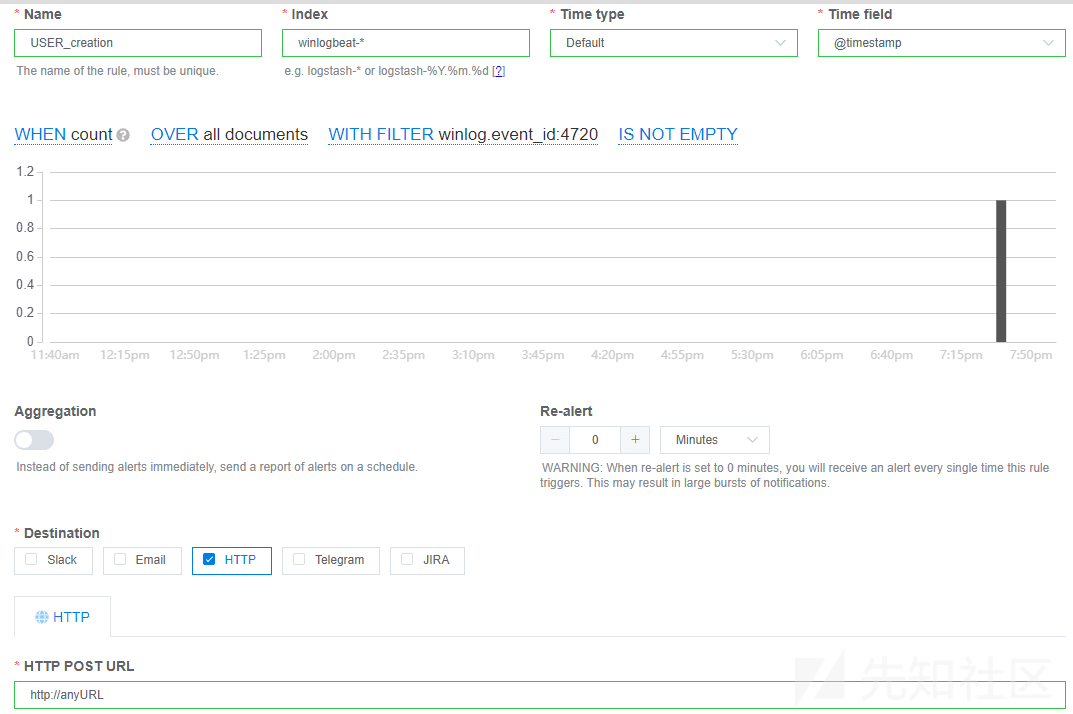
(1) 创建一个规则:“User_creation”:
首先,我们将像之前一样从Praceo界面创建我们的规则,在HTTP输出中我们先指定any URL,之后会删除。
完成后点击Save。
(2) 发送告警到Thehive:
添加TheHive配置,保存并重启Elastalert-Server,进入/etc/elastalert/rules目录:

(3) 在Praeco中检查告警:

告警已经成功发送到TheHive。但是遗憾的是,正如我们之前所提到的,Praeco界面无法编辑该规则,必须在/etc/elastalert/rules中手动编辑。

(4) 在TheHive界面中检查告警:

6.3 获得Sigma工具的帮助,以创建规则
如前文所述,Sigma工具帮助我们将sigma规则转换成多种格式,包括Elastalert。
项目URL与详细步骤见如下链接:https://github.com/Neo23x0/sigma.git

(1) 下载Sigma
cd ~
git clone https://github.com/Neo23x0/sigma.git
(2) 使用Sigma创建告警
cd ~/sigma/tools
pip3 install -r requirements.txt
执行命令如下(用示例规则举例):
./sigmac -t elastalert -c winlogbeat ../rules/windows/builtin/win_user_creation.yml


遗憾的是,由于缺少几个字段,此规则不能被 ( Praeco/Elastalert-Server ) 直接使用。因此,您可以从该规则(查询字符串)中选择关键字,并使用这些关键字信息在 Praeco 界面创建自己的规则。这个工具非常重要,因为它可以帮助我们收集大量规则及其查询字符的关键字。
注意:有时必须在(Kibana → Discover页面)中检查日志及其字段,以确保日志中的名称字段与Sigma规则中的名称字段相匹配。如果你的字段显示黄色错误,进入索引模式,选择匹配的索引,然后点击刷新字段。
6.4 发送Wazuh的告警到TheHive
我们将使用前文提到的相同方法来处理wazuh告警,首先我们使用praeco界面创建wazuh-alerts,然后我们手动编辑规则文件来添加theHive 输出。
(1) 创建一个wazuh规则并保存:

我们已经使用rule.id来过滤规则(可以选择任何其他字段),可以在wazuh → Overview → Security events下获取规则id。

(2) 编辑规则然后重启elastalert-server:
nano /etc/elastalert/wazuh-alert-TEST.yaml
(3) 检查告警:


0x07 报告
为了减轻企业网络威胁和攻击,应时常在系统上执行漏洞测试并修复安全问题。因此,您可以想象,“报告”工作在任何SOC中都非常重要,因为可以概述系统中可能存在的漏洞。
在本节中,我们将提供有关我们在“报告”工作和漏洞扫描中使用的工具及相关见解。本节包括以下几个部分:
- 相关介绍
- 安装Nessus essentials版本
- VulnWhisperer的安装
7.1 介绍
我们将使用到的工具:
VulnWhisperer:VulnWhisperer是一个漏洞管理工具和报告聚合工具。将从不同漏洞扫描工具中提取报告,并为每个文件创建一个唯一文件名。
Nessus essentials:Nessus Essentials(以前称作Nessus家庭版),是Nessus主机漏洞扫描的一个免费版本。
7.2 安装Nessus essentials
7.2.1 下载
从官网(www.tenable.com)下载,在我们的项目中,使用下图标记的这个版本:
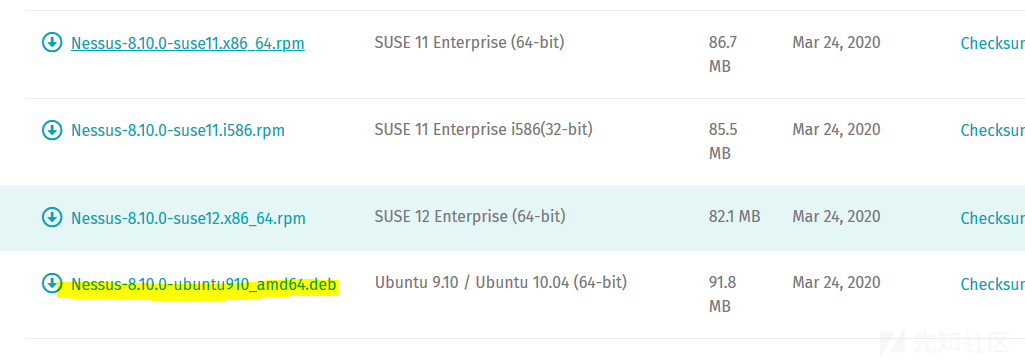
7.2.2 Nessus安装
dpkg -i Nessus-8.10.0-ubuntu910_amd64.deb /etc/init.d/nessusd start service nessusd start
浏览器访问https://YourServerIp:8834,选择“**Nessus Essentials**”:

7.2.3 激活Nessus

复制邮箱中的activation code(激活码),创建一个账户,随后等待Nessus准备完成。
7.2.4 运行第一次扫描
点击New Scan → 选择Basic Network Scan,

选择你要扫描的目标,保存随后运行。


7.3 安装VulnWhisperer
7.3.1 使用Python2.7
VulnWhisperer基于Python2.7,所以我们需要更改系统的Python默认版本。

7.3.2 配置VulnWhisperer
cd /etc/ git clone https://github.com/HASecuritySolutions/VulnWhisperer cd VulnWhisperer/ sudo apt-get install zlib1g-dev libxml2-dev libxslt1-dev pip install -r requirements.txt python setup.py install nano configs/ frameworks_example.ini
配置文件中选择你想启用的模块(在我们的项目中就仅启用了Nessus),虽有填写你的Nessus账户凭据:

7.3.3 检查Nessus是否联通及报告下载
vuln_whisperer -F -c configs/frameworks_example.ini -s nessus # 报告将以csv拓展名格式保存,在如下目录中检查报告: /opt/VulnWhisperer/data/nessus/My\ Scans/

如果不是新报告,命令运行后显示内容如下图所示:

7.3.4 配置Vulnwhisperer定时任务
为了使Vulnwhisperer检查Nessus数据库并定期下载报告,我们将添加一个定时任务。因此,我们就不用再手动执行命令了,将最新的报告直接自动添加到Kibana。
添加以下内容:
SHELL=/bin/bash * * * * * /usr/local/bin/vuln_whisperer -c /etc/VulnWhisperer/configs/frameworks_example.ini >/dev/null 2>&1

7.3.5 导入Elasticsearch模板
到kibana Dev Tools,随后点击add template:
模板文件下载链接:
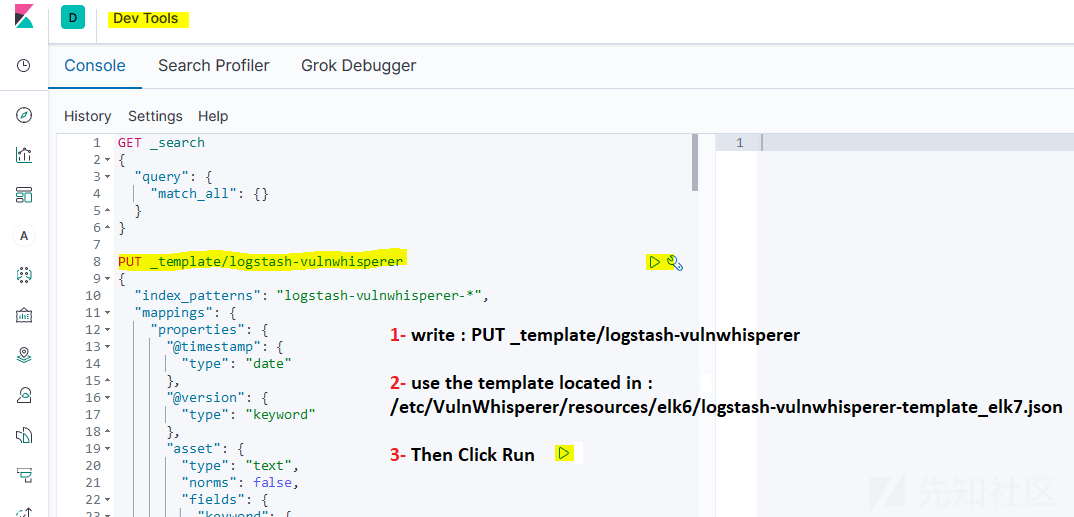
完成后,现在Index Templates中应该已经有了一个模板。

7.3.6 导入Kibana可视化文件
点击 Kibana → Management → saved object → Import,导入kibana.json配置文件:在VulnWhisperer/resources/elk6/kibana.json下,文件下载链接如下:
https://github.com/HASecuritySolutions/VulnWhisperer/blob/master/resources/elk6/kibana.json

现在在Dashboards,应该可以看到如下两项:

7.3.7 添加Nessus Logstash配置文件
将Nessus Logstash文件复制到/etc/logstash/conf.d/中:
cd /etc/VulnWhisperer/resources/elk6/pipeline/ cp 1000_nessus_process_file.conf /etc/logstash/conf.d/ cd /etc/logstash/conf.d/ nano 1000_nessus_process_file.conf
修改output如下:
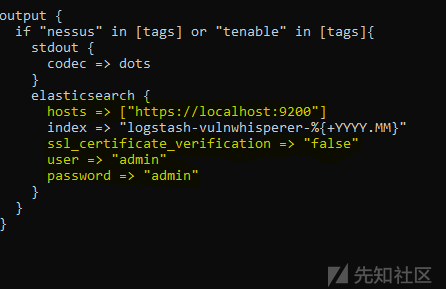
7.3.8 重启服务随后检查报告
systemctl restart logstash elasticsearch
现在你应该为Vulnwhisperer创建了一个新索引:

转到Index pattern,检查你的字段编号:
Note:刷新index pattern以识别所有字段。

最后,到Dashboards 并查看报告。这时,可视化页面应该没有任何错误。

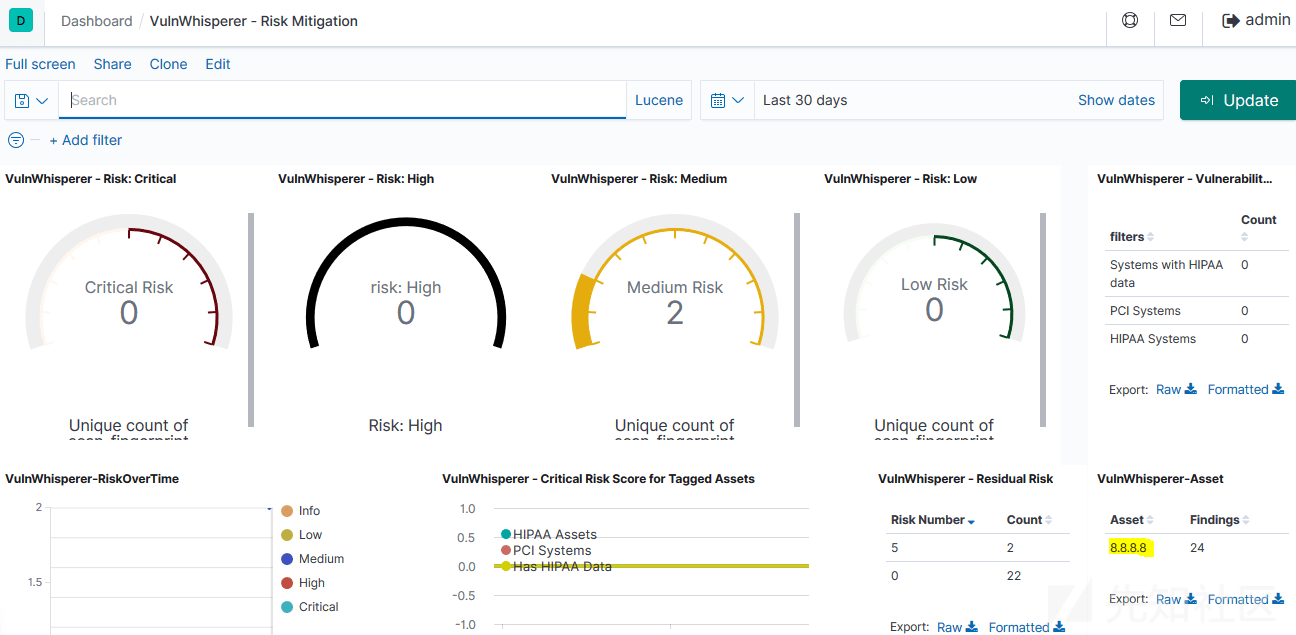
现在,Nessus生成的所有.csv扩展名的报告都将自动发送到你的ELK Stack。因此,就可以在kibana仪表盘下对其进行可视化了。
0x08 事件管理
在本节中,我们把最难题的部分放在本节中。将介绍SOC的事件管理部分:我们已经使用了2种开源技术——TheHive和Cortex。
TheHive将用作我们项目的告警管理平台,该平台可以管理从创建到关闭的告警事件。同时,Cortex是与TheHive同一个团队开发的补充产品,使用“分析器(analyzers)”和“响应器(responders)”对数据进行补充。
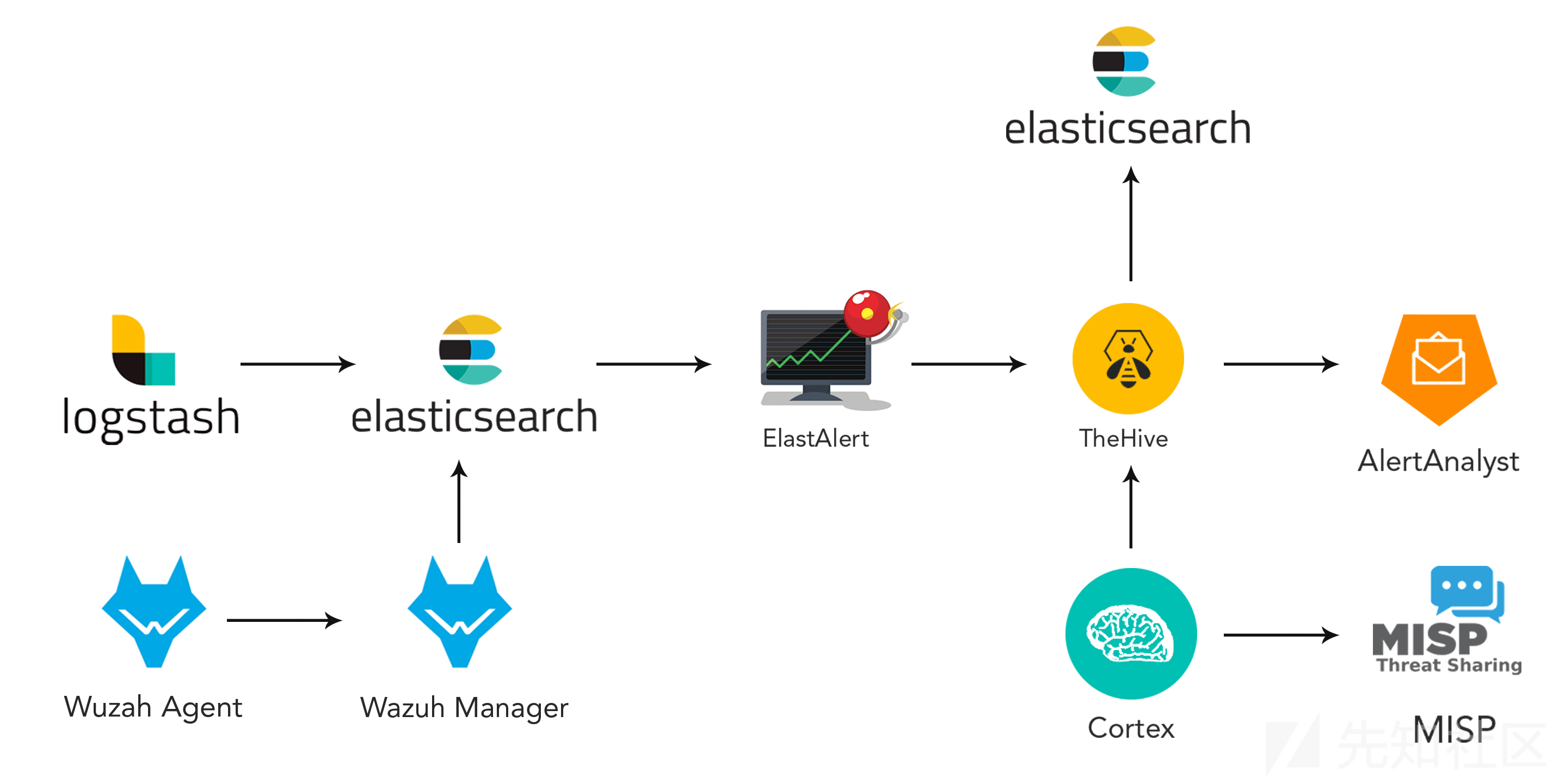
本节内容分为以下几个部分:
- TheHive和Cortex的安装和配置;
- TheHive和Cortex仪表盘的演示;
- 将Cortex与TheHive集成;
- 安装MISP并将其与TheHive集成;
- 排查:事件管理。
8.1 TheHive和Cortex的安装和配置
我们部署的版本是:TheHive 3.4.0-1和Cortex 3.0.1-1。
TheHive需要Elasticsearch才能运行。为此,我们选择使用docker-compose在Docker容器中一起启动它们。如果你不想使用Docker,也可以手动安装和配置Elasticsearch。
有关更多详细信息,参阅:
https://github.com/TheHive-Project/TheHiveDocs/blob/master/installation/install-guide.md
None: TheHive使用ElasticSearch来存储数据,两款软件使用的都是Java VM。推荐使用8核的CPU、8GB内存和60GB硬盘存储的虚拟机,当然也可以直接使用相同配置的物理机进行部署。
我们使用以下docker-compose.yml文件在3个不同的容器中一起启动Elasticsearch,TheHive和Cortex:
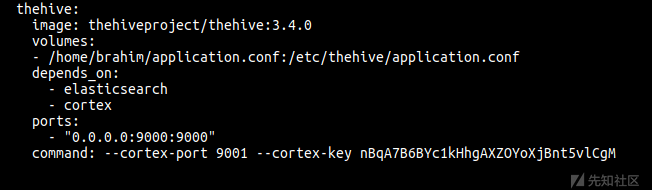
version: "2" services: elasticsearch: image: elasticsearch:6.8.0 ports: - "0.0.0.0:9200:9200" environment: - http.host=0.0.0.0 - cluster.name=hive - thread_pool.index.queue_size=100000 - thread_pool.search.queue_size=100000 - thread_pool.bulk.queue_size=100000 ulimits: nofile: soft: 65536 hard: 65536 cortex: image: thehiveproject/cortex:3.0.1 depends_on: - elasticsearch ports: - "0.0.0.0:9001:9001" thehive: image: thehiveproject/thehive:3.4.0 depends_on: - elasticsearch - cortex ports: - "0.0.0.0:9000:9000" command: --cortex-port 9001
复制粘贴保存到docker-composer.yml文件中,随后执行如下命令:
sudo sysctl -w vm.max_map_count=524288
最后运行:
TheHive监听9000/tcp端口,Cortex监听9001/TCP端口。这些端口可以通过修改docker-compose文件来更改。
可以使用如下命令查看创建的容器:docker ps –a:

检查Elasticsearch是否可联通:
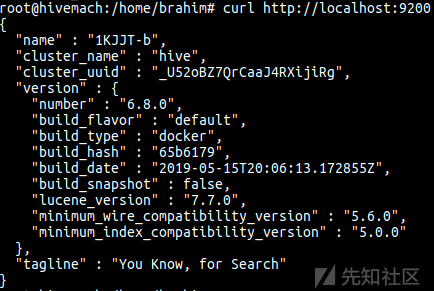
现在一切都已设置好,让我们看一下TheHive仪表板。
8.2 TheHive和Cortex仪表盘的演示
浏览器访问http://YOUR_IP:9000:
注意:如果要在云主机上安装,不要忘记为9000、9001和9200端口配置规则放开。

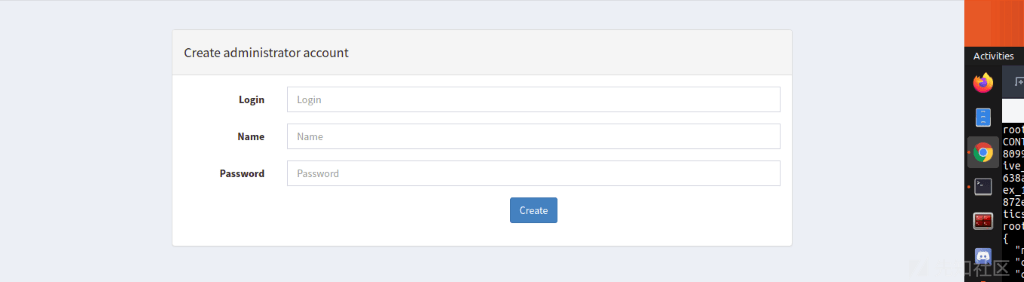
点击Update Database,并创建一个管理员用户:

使用该用户登录:

下图就是TheHive主要的Dashboard:

现在让我们检查下Cortex的Dashboard:
浏览器访问:http://YOUR_IP:9001:
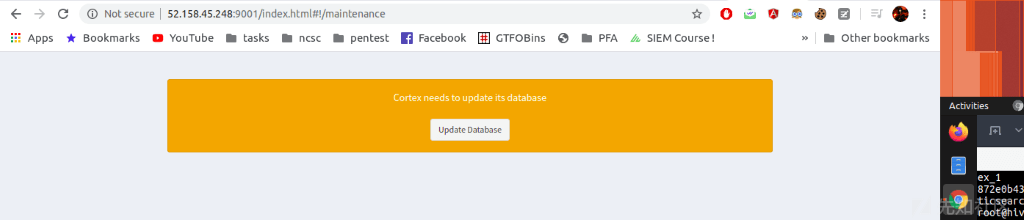
点击Update Database,并创建一个管理员用户登录(跟前文TheHive的步骤一样)。

Cortex的工作方式是,你当前的用户可以创建组织和用户,但是必须以组账户登录才能启用
和管理Analyzers(分析器)。
通过单击页面上的”+添加组织“按钮来创建新的组织:

现在切换到”用户“标签,随后点击”+添加用户“,将新用户分配给你创建的组织,并赋予他们组织管理员的角色。保存后,为刚创建的用户点击”新密码“,然后输入密码,点击Enter保存。现在,注销并以新用户身份重新登录。点击页面顶部的”Organization(组织)“选项:

现在,点击组织中的Analyzers选项卡(不是页面顶部的Analyzers)。如果Cortex正确配置了,应该就可以看到 Analyzers(分析器)。到今天为止,我有124个可用的Analyzers:
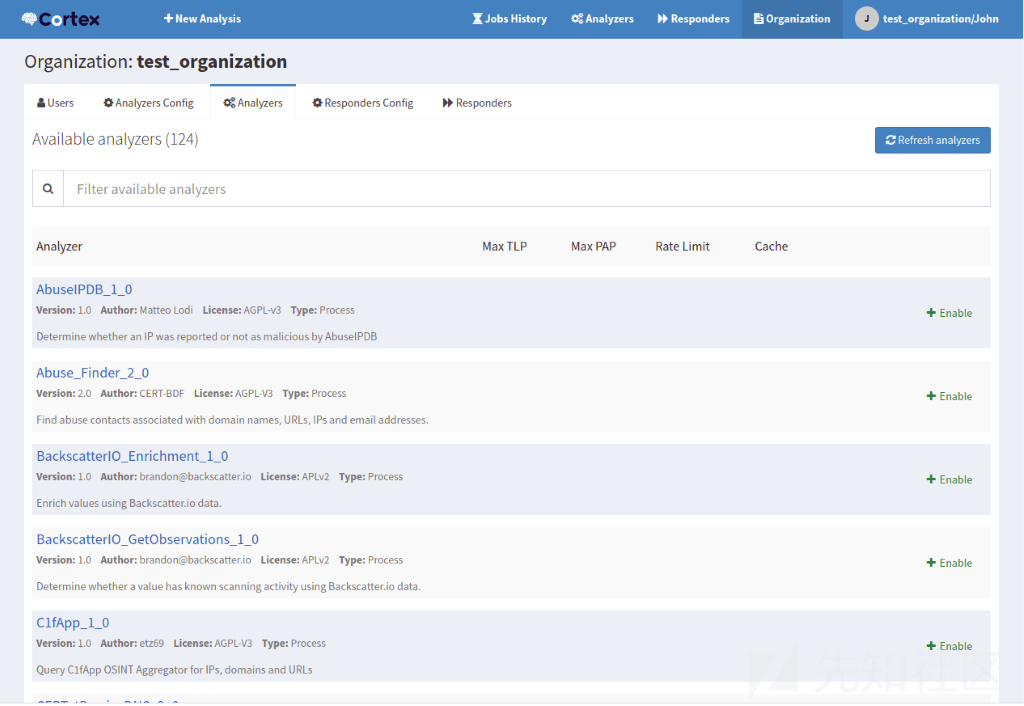
现在让我们启用某些Analyzers以供后续使用,保留默认设置。某些Analyzers需要API密钥,因此请确保在配置这些Analyzers时提供正确的信息。
8.3 将Cortex与TheHive集成
点击组织中的Users选项卡,然后创建一个新用户以与TheHive集成。这个用户应该有读和分析的角色。这次不为用户设置密码,而是单子”创建API密钥“并复制密钥。现在回到终端,通知所有运行的容器,在主目录中创建一个文件,并命名为application.conf:

cortex { "CORTEX-SERVER-ID" { # URL of the Cortex server url = "http://172.18.0.3:9001" # Key of the Cortex user, mandatory for Cortex 2 key = "nBqA7B6BYc1kHhgAXZOYoXjBnt5vlCgM" } }
url参数是http://你cortex容器的ip:cortexPort(可以使用`docker inspect <id-container>命令检索容器ip),key参数是刚才创建的api密钥。保存该文件,随后修改docker-compose.yml`文件,在TheHive的配置部分,添加:</id-container>
volumes: - /home/your_user/application.conf:/etc/thehive/application.conf ...... command: --cortex-key (上一步使用的相同api_key )
保存文件并退出编辑器,随后再次运行docker-compose up。
在全部容器启动起来后,回到TheHive的dashboard,点击账户onglet下的”about“,应该可以看到与下图相同的信息:

现在,我们已成功将Cortex与TheHive集成在一起了。
8.4 安装MISP并将其与TheHive集成
8.4.1 安装MISP
1.sudo apt-get update -y && sudo apt-get upgrade -y 2. sudo apt-get install mysql-client -y 3.curl https://raw.githubusercontent.com/MISP/MISP/2.4/INSTALL/INSTALL.sh -o misp_install.sh 4.chmod +x misp_install.sh 4. ./misp_install.sh -A
当安装过程中询问baseurl 时,输入你的IP:https://YOUR_IP/,
当询问创建一个“misp”用户时,输入“y”。
PS:别忘记在你的机器上开启80和443端口。
安装完成后,浏览器访问https://your_ip/,可以看到登录页面:
使用默认用户名密码登录([email protected] / admin),随后输入新密码用户更改默认密码。
启用MISP集成:
浏览器访问MISP的web页面,点击管理 -> 添加用户,向用户发送电子邮件,例如:[email protected],随后将用户添加到ORGNAME组织,角色选择user,取消选中底部的所有复选框,复制用户的AuthKey。

随后转到Cortex > Organization > Analyzers,在搜索框输入“misp”,启用“MISP_2_0”,为MISP服务器指定一个描述性名称,url框输入你的MISP IP,key输入创建MISP用户的密钥(AuthKey),cert_check选择“False”:

现在,访问MISP的web页面 > Sync Actions > List Feeds。找到一个你已经订阅的feeds,点击右边的放大镜按钮,在列表中选择一个ip并复制。
现在在Cortex中,点击”+New Analysis“,添加一个IP的数据类型,并粘贴刚才复制的IP。
选择The MISP_2_0 analyzer and run。在任务历史记录页面,点击”View“,你应该看到你复制的IP的列表名称以及该列表提供的其他信息。
可以进入TheHive,把这个IP作为一个观察点,进行测试。
8.5 排查:TheHive的事件管理
TheHive的核心结构就是排查事件。TheHive旨在使分析人员更轻松,并确保从事此工作的团队成员之间更好的理解。这是至关重要的,因为事件排查似乎大多数安全排查的核心结构,无论是查看告警、对恶意软件进行你想还是处理应急响应事件。

你可以在事件中添加标签以进行快速的搜索和过滤。还可以评估事件的严重性,跟踪TLP级别,这样可以帮助管理和促进数据共享。事件中的所有数据很容易从页面顶部的搜索栏中搜索出来。这样可以更轻松地确定你当前正在观察的活动是否存在于先前早期的事件中。
你也可以通过导入告警来创建事件。如果两个告警共享一个链接,可以选择将这个告警添加到现有的事件中,而不是生成一个新的事件。
事件创建完成后,可以开始为它设置tasks(任务)。tasks(任务)可以是任何东西,但我们建议用他们来跟踪排查事件问题。
此外,多个分析人员可以同时处理同一事件。例如,一个分析人员可能会处理恶意软件的分析,而另一个分析人员可能会在同事添加IOCs(失陷指标)后,立即在代理日志上跟踪C2 beacon活动。

事件模板:
随着SOC的发展,定义处理手册变得至关重要,它可以帮助分析师一致地处理具有共同属性的排查。例如,在最初调查一系列的密码爆破登录失败行为或钓鱼邮件时,我们采取的排查步骤通常是类似的。如果能确定这些步骤,你就会有一个很好的开端来培训新的分析人员,并确保大多数调查是在一个平等的基础上开始的。TheHive提供了一个独特的事件模板系统,允许定义常见的排查步骤并预先填充事件的元数据和任务。

在上图的例子中,我们定义了一个与漏洞利用工具包活动有关的排查模板。现在,当我创建一个新事件时,我可以选择这个模板,你所看到的所有信息都会预先填充到事件的细节中。真正实用的是在事件发生之前自动创建一系列tasks(任务)的能力,这基本上就是为我们定制了操作处理手册,这样,就可以自动填充等待的任务队列,从而使其他分析人员能够直接介入排查,或开始完成控制和消除的任务。
此外,TheHive支持在事件的上下文中为有趣的可观察对象创建单独的条目。可观察的是任何有趣的数据工件。TheHive内置了几种常见的可观察类型:包括IP地址、域名、HTTP URI等。当然,您还可以定义自己的类型,从而使该功能更加灵活使用。

跟踪观测值有很多好处,显而易见的一点是,你可以在后续的调查中搜索他们,以引入更多的来龙去脉。还可以将它们导出,以便以后导入黑名单、白名单或检测机制。最后,您可以使用内置的Cortex集成将观测值自动提交给任意数量的OSINT研究站点。这是一个非常简单的过程,并且仅需要您为将要使用的每个服务输入API密钥。一些现有的集成包括Passive Total、Virus Total和Domain Tools。
准备好关闭事件时,请单击事件标题栏中的“关闭”按钮:

你还可以把事件的性质设为真阳性(true positive),假阳性(false positive)等等…
0x09 写在最后
文中当然有很多翻译不当、笔误的内容,欢迎读者指正。感谢。
<全文完>
如有侵权请联系:admin#unsafe.sh