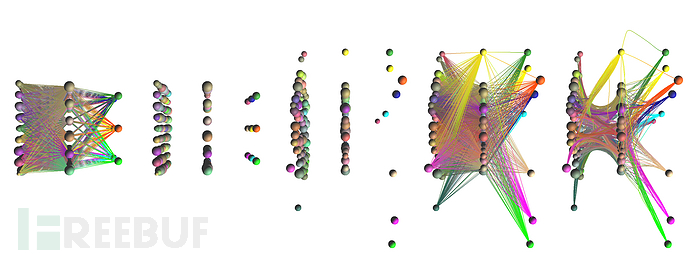

官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序
不少质疑我,可视化了,然后呢,什么用?
今天当当当,可视化训练模型第二篇来了,教你如何“欺骗”模型!上篇入口:
可视化教程工具开源于此:github
-----------------此为正文-----------------------------
上文那些,就是一整套AI训练时的正常画风。那么,如果我们给AI悄摸摸喂点对抗样本,训练过程又是什么画风呢?
所谓对抗样本,是指对原始图片添加细微干扰形成输入样本,让人眼看来无明显变化,却能导致AI模型的预测结果走偏、出错。
这里,举个小熊猫图片被加入噪声的例子:
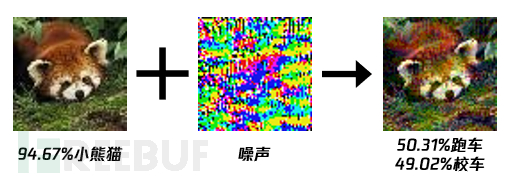
这里使用一个简单的FGSM方法产生一个对抗样本。
我们首先读取一张小熊猫图片,载入已训练好的tiny_vgg模型,得到梯度后,使用梯度符号*扰动,叠加到原始图像上,便得到对对抗样本。
loss_object = tf.keras.losses.CategoricalCrossentropy()
with tf.GradientTape(persistent=True) as tape:
tape.watch(image_batch)
predictions = tiny_vgg(image_batch)
loss = loss_object(label_batch, predictions)
gradients = tape.gradient(loss, image_batch)
signed_grad = tf.sign(gradients)
epsilon, prediction = 0.01, True
label_true = predictions[0].numpy().argmax()
while prediction:
adv_img = tf.add(image_batch, epsilon * signed_grad)
adv_img = tf.clip_by_value(adv_img, 0, 1)
label_pred = tiny_vgg(adv_img)[0].numpy().argmax()
if label_pred == label_true:
epsilon += 0.0007首先看看原始的小熊猫图片在神经网络中的一个特征分布情况:
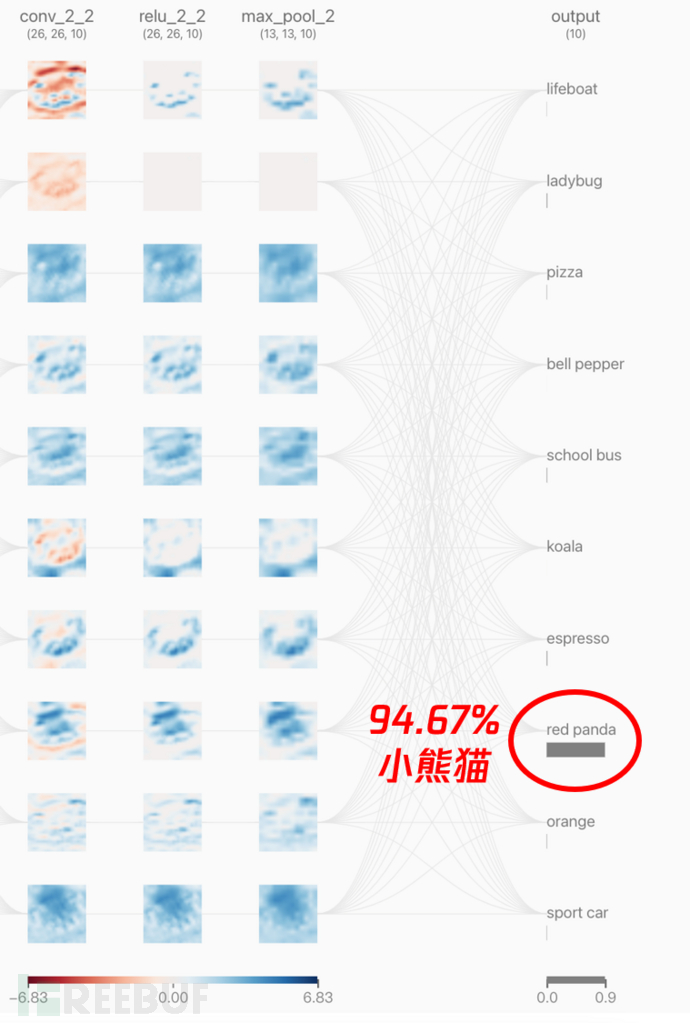 再看看小熊猫图片被加入对抗样本后的特征分布情况:
再看看小熊猫图片被加入对抗样本后的特征分布情况:

可以清楚看到,两者的预测结果截然不同(小熊猫vs车子),但两者在训练过程中的不同之处大家有发现吗?
乍看之下,两者的特征权值分布非常相似,但仔细观察就会发现一些略微不同。这里我们给池化层的第三个filter来个特写镜头,大家来找找茬:

如上,从这些细微差异中,可以窥见AI的预测逐渐“走偏”的蛛丝马迹。
这就如同蝴蝶效应,最开始的一点点细微干扰,在经过训练过程中重复多次的卷积、激活、池化后,越走越歪,最终输出的结果和原始结果千差万别。
也许,这就是神经网络的奥秘所在吧。欢迎感兴趣的同学与我们交流探讨!
--------------------------------正文结束---------------
参考资料
神经网络的结构和参数可视化
- 仓库地址: https://github.com/julrog/nn_vis
- 运行环境:Python、Tensorflow2
- 使用效果:可视化展示网络结构
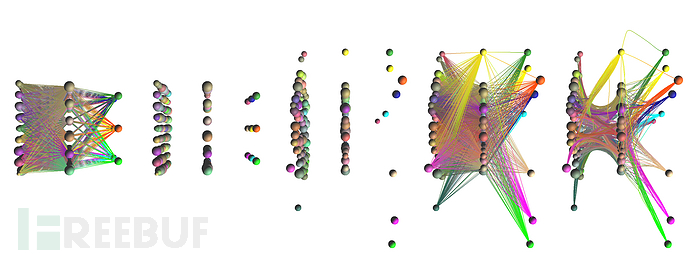
基于Unity的神经网络训练过程可视化
- 仓库地址: https://github.com/stefsietz/nn-visualizer
- 运行环境:Python、Tensorflow1、Unity、C#
- 使用效果:构建3D版神经网络,使用鼠标和神经网络动态交互,动态查看训练过程

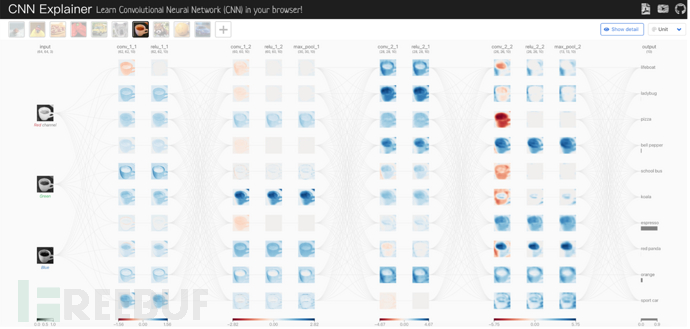
CNN原理可视化
- 仓库地址: https://github.com/poloclub/cnn-explainer
- 运行环境:Python、Tensorflow2、TensorflowJS、NodeJS
- 使用效果:演示神经网络的原理,查看每一层、每个神经元的特征数值
MNIST数据集分类模型可视化交互
- 仓库地址: https://github.com/aharley/nn_vis
- 运行环境:JavaScript
- 使用效果:输入手写字符,可交互体验每一层特征概况

工具
- Unity3D: Unity3D工具
- Kap: Mac下Gif动图录频工具
- ScreenToGif: Windows下Gif动图录频工具
------------------结语分界线---------------------
有同学想了解请留言~点赞收藏不迷路~鼓励我我继续写牙~
想亲手尝试的同学可看此git详细列上ai可视化相关资源:GITHUB