在上一篇《微软“照片”应用Raw 格式图像编码器漏洞 (CVE-2021-24091)的技术分析》中,笔者基于对Olympus e300 相机raw格式的粗浅理解,并未对 WindowsCodecsRaw和WindowsCodecs 这两个图像解码库展开深入调试,仅阐明漏洞函数部分漏洞产生的原因。在本文中,笔者将分析同一个库中的另一个漏洞(CVE-2020-17113),以期加深对WindowsCodecsRaw 库的理解。
根据MSRC 和漏洞发现者公开的信息,Windows Imaging Component 解码TIFF格式图片时,在解析原始数据 (GetNameWhiteBalances) 的过程中触发该漏洞。(TIFF格式 参见维*基*百科相关内容)。本文将基于对TIFF格式的了解并结合POC格式解析展开分析,供读者参考。
0x00 漏洞验证
1. 在Win10 1903 x64系统上,使用gflags工具为图片app开启页堆,双击图片文件打开(图片默认应用为照片App)。一段时间后,App退出进程。
2. 使用Windbg附加照片App(Windbg 调试UWP方法详见微软文档),敲击g运行程序。一段时间后,进程崩溃。如下图所示:
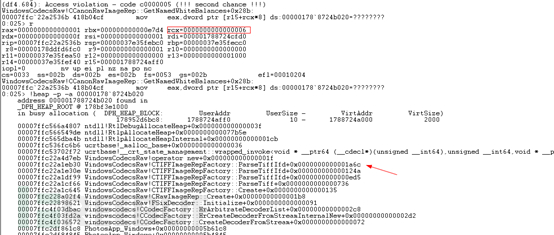
结合访问违例的指令和内存分配的结果,可以得出如下结论:访问违例的原因是,在大小为0x10字节的内存区域中读取偏移为0x30的数据,因此它是一个越界读的漏洞。
0x01 漏洞分析
首先使用ida pro 加载崩溃dll,定位到崩溃点,分析函数代码。
函数声明如下:
__int64 __fastcall CCanonRawImageRep::GetNamedWhiteBalances(CCanonG12ImageRep *a1, __int64 a2)结合对传入参数类型的分析,通过自行构造结构体以及虚表定位,给出注释如下:

函数伪代码如下:
CTag * tag = a1->GetTags();vector<int> vec = {0, 1, 2, 3, 4, 5,……};tag_data = tag->GetTagdata();for (int i = 0; i < 10; ++i){if (vec[i] < tag->GetTagCount()){dword *addr = tag_data + 48 * vec[i];dword v26 = *(addr);word v13 = *(word*)(addr+4);expressions;...}...expressions;}
在这段代码中,如果 tag_data 数据块的长度小于 vec 向量前10个成员中最大值的48倍,就有可能产生越界读。在实际调试代码时,可以看到,这个 tag_data 确实只有16个字节。

所以,当照片App加载这个图片时,会产生越界读的访问违例。
0x02 关于POC文件
漏洞触发的原因,不难理解。但问题是,这个文件为什么能产生这样一个错误的IFD_Tag 结构呢?还是要从“照片“ App解析POC文件的过程入手。
关于解析过程的调试,过程比较繁复,这里就不做赘述了。下面仅根据文件格式规范,总结一下这个文件表现出的一些有趣现象。
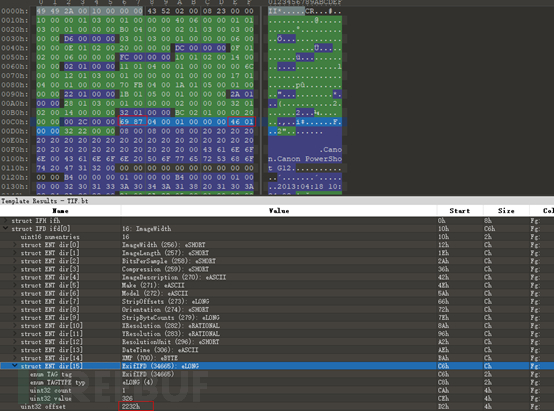
文件内容如下图:
熟悉图片格式的读者可以发现,这个文件是一个嵌入Exif 信息块的tiff格式。

为方便不熟悉tiff格式的读者阅读,简单说一下TIFF格式的结构。TIFF ,即“标签图像文件格式”,是一种利用标签字段对图像的尺寸,色彩空间等进行规范的文件信息。同时它具有很好的可扩展性,厂商可以根据自己的需求设计“自定义标签”,或者“私有标签”,以便于存储个性化的信息,丰富图片内容(详细信息可以查看TIFF FAQ. https://www.awaresystems.be/imaging/tiff/faq.html)。
便于读者理解,笔者将结合poc图片内容说明几种重要的数据结构。
2.1 头部
TIff头部数据结构,如下所示:

前两个字节指定文件字节序,“II“为 小端 “MM” 为大端;
3-4字节是magic值,永远为0x2A,字节序由前两个字节指定;
5-8 字节指定第一个IFD 的偏移,为非负值,不能超过4G(32位地址空间,无符号整数,bigtiff的信息这里暂且不表)。
2.2 IFD
IFD即为图像文件目录,每一个IFD 都记录一页图片内容的属性和数据(也会记录subifd,以及其他信息),格式如下:

如上表所示,每一个IFD结构都由3部分组成:
ifd_size:2 字节,指定该IFD中tag的数量
tag_array:ifd_size *12个字节,一个由tag组成的列表,指定图片的各种属性值
next_ifd:4个字节,指定下一个IFD结构的偏移,如果没有下一个IFD 值为0。
2.3 TAG
tag 结构如下:

tag结构由四部分组成:
tag_id:2 字节,指定该 tag 描述的对象的ID;
tag_type:2 字节,指定 tag_value 的数据类型;
tag_cnt :4 字节 指定 tag_value 值的数量;
tag_value(tag_value_offset): 如果 tag_value 值的大小不超过4字节,表示 tag_value,否则该字段指向 tag_value 在文件的偏移。
以上是TIFF格式几种重要数据结构的简单描述,详细信息请自行查阅资料。
2.4 值得注意的几个tag_id
除了TIFF 基本的IFD tag外,有几个需要说一下的TAG_ID:
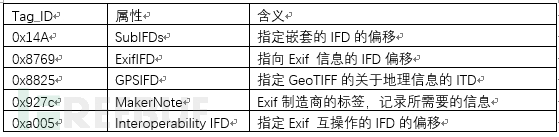
值得注意的是,上面几个 IFD_Tag 出现时,表示文件中会产生嵌套格式的IFD。
2.5 关于poc文件的IFD结构
如前文中010Editor模板对poc文件的解析结果所示,名义上,因为第一个IFD结构的 next_ifd_offset 不为0,所以这个图片至少有两页。

但是,偏移0x2232开始的内容则表明这段数据是一个无效的IFD结构,所以在解析ifd时会因为数据不符合结构规范,退出解析函数。
在实际调试过程中,笔者通过逆向图像编码库并设置断点,记录了“照片“App对poc文件的解析过程。解析的ifd tag 结构,部分输出如下:
bu windowscodecsraw+023D3A1 "r $t1 = poi(rsi+28) ; .echo tag is:; dd rbp-cc l1; .printf \"offset is %x\", @$t1; .echo \n; gc"可以看到,偏移0xc6处的tag 值为0x8769,也就是前文提到的Exif IFD,所以“照片” App会继续解析。显然,这个poc文件是经过变异的,调试过程相比于解析正常的TIFF格式要复杂一些,这里不做赘述。

下表为“照片”app 解析poc文件时,解析得出的所有“IFD”结构信息。
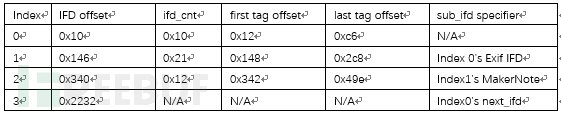
笔者并不能根据现有的文件逆向推导poc原文件到底是什么。然而,正是变异导致整个TIFF文件出现了解码器不能识别的错误,tag标签被错误解析,从而导致在处理白平衡时,对象解析出错,进而引发越界读的访问违例。
因为被错误解析而导致访问违例的ifd_tag结构,如下所示:



0x03 小结
得益于良好的可扩展性和强大的适应性,Tiff 广泛适用于各种生产环境。笔者通过本次漏洞分析发现了此前在研究 tiff 格式时忽略的一些信息,同时,也获得了挖掘Tiff格式漏洞的一点新思路。读者如能从本文获得同样的启发,则实现了笔者的分享价值。
题图:Pixabay License
转载请注明“转自奇安信代码卫士 https://codesafe.qianxin.com”。
如有侵权请联系:admin#unsafe.sh