10 May 2021Before we begin, I know, yet another "guide to creating a hash cracker in [insert popul 2021-05-10 23:42:41 Author: fortynorthsecurity.com(查看原文) 阅读量:144 收藏
10 May 2021
Before we begin, I know, yet another "guide to creating a hash cracker in [insert popular cloud service here]". Well, I was on a test recently where a couple resources for deployment failed or were outdated and I had to try a few variations and modifications before getting a successful deployment. Specifically, the Hashcat-Azure auto deployment from carlmon, which I really like, wasn't working correctly so I figured I would write a quick blog post going over some manual deployment techniques and commands, installing dependencies, and a convenient script to sort everything out for you.
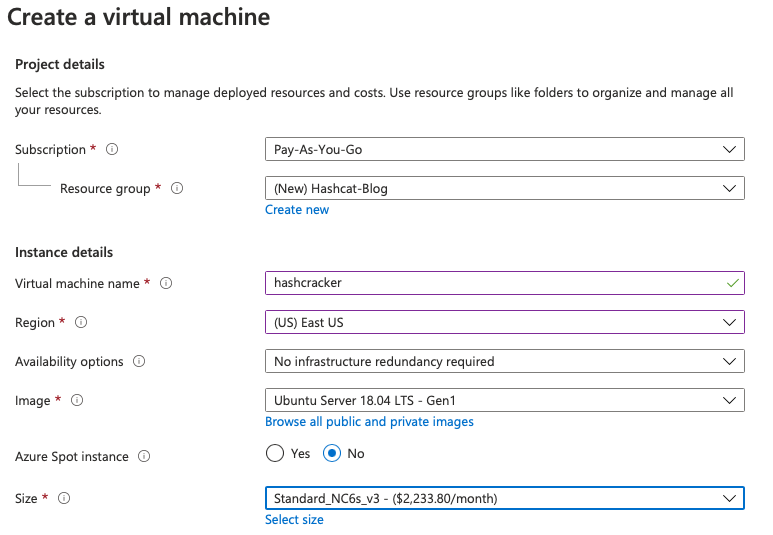
First things first, let's get an appropriate VM deployed in Azure so we can start setting everything up. Head over to Azure and spin up an Ubuntu Server 18.04 LTS virtual machine. Make sure to select US East as the region and the Standard_NC6s_v3 option for the size. The NCv3 series use the NVIDIA Tesla V100 GPUs and that's what we're going to want to take advantage of for our cracking. The 112 GB of RAM probably doesn't hurt either. The price is expensive, but if you just let it run for a few hours you should be at less than $10 (about $78/day or ~$3/hour when writing this). We'll go over some cost saving option later on as well as some more intense cracking options if your budget is a bit higher. Overall, the setup page should look something like the image below.

Next, I'd recommend adding in your SSH public key and you should be good to click Create at the bottom. The VM will take a bit of time to deploy (generally less than about 5 mins) so while you're waiting start queuing up your wordlist and any mangling rules you want to use. I would recommend Hob0Rules from Praetorian-inc. with a smaller wordlist like rockyou (these will be downloaded if you use the script below). If you're setting up a larger cracking VM, you can make use of a larger list of mangling rules from NotSoSecure, OneRuleToRuleThemAll and a larger dictionary like one from Crackstation.
Once the VM is spun up, click the Go To Resource button in azure or just navigate to the newly-created VM. SSH into it with the azureuser username (unless you modified it during setup) and IP address under the Public IP Address section under Overview.
It's always a good idea to update the VM for the first time but it's not needed if you run the script below.
sudo su
apt update && apt upgrade -y
Next, let's get to installing the CUDA drivers we'll need for the GPU cracking. I ended up using this guide put out by Microsoft to help set up the appropriate drivers but modified it to suit Ubuntu 18.04 LTS. I created a script to help automate it. To install it, just run:
git clone https://github.com/FortyNorthSecurity/CUDA-Installation-Script.git
chmod +x CUDA-Installation-Script/cuda-install.sh
./CUDA-Installation-Script/cuda-install.sh
The main reason for creating the script is that I wanted to try to automate as much as I could after deployment (at some point we'll get terraform working with this to really automate the whole process). So, with this script all you have to do is run it, let it do its thing, and once the system reboots all you have to do is type hashcat and get crackin'.
I won't detail all the steps for installation in here, check out the script in the above paragraph and that'll show you all the commands. The script does have to install several GB worth of dependencies and the full CUDA toolkit so it does take a short while to complete (about 10 mins in testing). The script also installs hashcat and grabs the latest Hob0Rules/OneRuleToRuleThemAll to get you up and running quickly.
Let's go through a few benchmark numbers just to show how great the speed increase can be. First, let's take a look at using a fairly beefy Macbook Pro (2.4 GHz 8-Core i9, 32 GB RAM, Radeon Pro 560X 4GB):

OK, not too bad as far as cracking NTLM goes if you're in a pinch. NetNTLMv2 is pretty slow but that will always be much, much slower than NTLM. Let's take a look at the same benchmark data for the cracking machine we just deployed in Azure:

Pretty decent increase in speed for a fairly low price point! But, if you're thinking to yourself "you gottta pump those numbers up, those are rookie numbers" well we can greatly increase our cracking speed for about $297/day or ~$12/hour. The only change we have to make is during setup, chose the Standard_NC24s_v3 option and now we're looking at some pretty decent numbers:

Personally, I would recommend going with the Standard_NC24s_v3 option, as it's fairly cheap and you'll crunch through a ton more hashes/rules at a time.
Cost Saving Option
If you want to deploy a cracking VM and keep it going without having to pay thousands of dollars per month or rebuild it everytime, you can chose to stop the VM and deallocate the resources. This will keep the VM (you just pay for the space) but will return all the resources so other systems can use them. This will release your public IP address so if you need that to stay the same this method won't work.
If you need to spin up the VM again, it's as easy as starting the VM back up and you'll be back to cracking without the whole setup process. Just make sure that you stop the vm through the Azure Portal and ensure the Status is set to "Stopped (deallocated)".

For the final topic I just want to quickly talk about something I've been working on for a short while now - Azure High-Performance Computing clusters. High-Performance Computing (HPC) clusters are a way to quickly deploy a control VM and several executing VMs which then run any number of tasks and can scale automatically. The image below is a bit complex but let's go through it at a high level below.

First, you start off by deploying an Azure CycleCloud instance within Marketplace which spins up a system that you can use to create clusters. This CycleCloud system starts a webserver and GUI where you can use several different open-source options for creating an HPC cluster. I found that HTCondor and Slurm were the easiest to use and had the option to deploy Ubuntu machines as execute nodes.

Once you start to create a new cluster, you can select the system type and the max number of CPUs/systems/etc. After the required settings are in there, you can start your cluster, which will deploy a VM (the cluster head node above, i.e. the control/scheduler VM). You'll be able to SSH into the scheduler VM using a public IP which is where you'll run your execute commands that will send the job to the execute nodes. These commands differ slightly for each scheduling platform; here are some examples for HTCondor and Slurm. The image below shows an example of the required settings.

During my research, I attempted to create a cloud-init script which would install all dependencies for hashcat (basically just pulled my script above and executed it). This proved to be a bit more challenging, as every iteration and modification of that cloud-init script would fail at some point. Even setting up my script within a HTCondor and Slurm execute script which sent jobs to the execute VMs would fail for one reason or another.
Initially I was convinced this would be a great way to deploy a ton of shared resources, start up hashcat with those resources, and get some crazy good cracking benchmarks. The cluster deployment interface was clean and easy to use, we could kill the whole cluster if we weren't using it and it was trivial to start everything back up again. We could also just have the CycleCloud system online and we could very easily set up alerts for pricing if a job went on too long. The image below is what the management console looks like once you create a new cluster.

Unfortunately, I don't have a large amount of time for research into deploying a cluster with the CUDA drivers and hashcat installed or if this is even a viable approach to distributed hash cracking with Azure. If this interests you or you have some time on your hands to play around with clusters I highly recommend it; they are incredibly powerful frameworks for running complex computations or quickly deploying a bunch of systems with the ability to share resources. I believe there's a way to get this to work and achieve some staggering benchmarks on hashcat so if you figure it out or want to talk about the viability of this, shoot me a message on twitter @Matt_Grandy_.
如有侵权请联系:admin#unsafe.sh