简介
这是一款很小巧的工具,由Python2编写,使用Fofa的指纹库
Github地址:https://github.com/se55i0n/Webfinger
可以参考官方的截图:
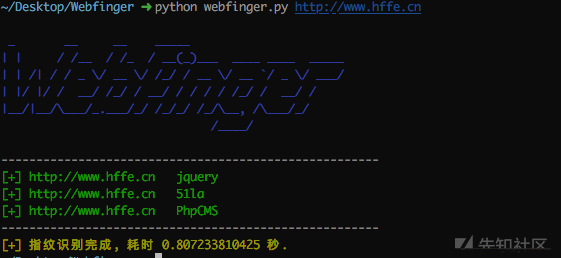
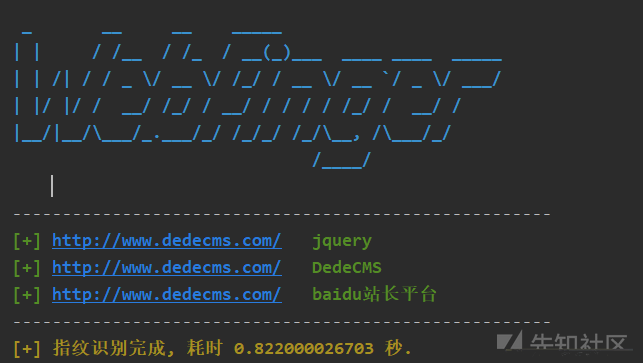
这个工具的使用体验非常不友好,采用了过时的Python2,并且连接数据库的代码有错误,我只好帮他改BUG了,处理完一系列问题之后,成功跑起来了,我用dedecms官网进行测试,效果还不错:
源码分析
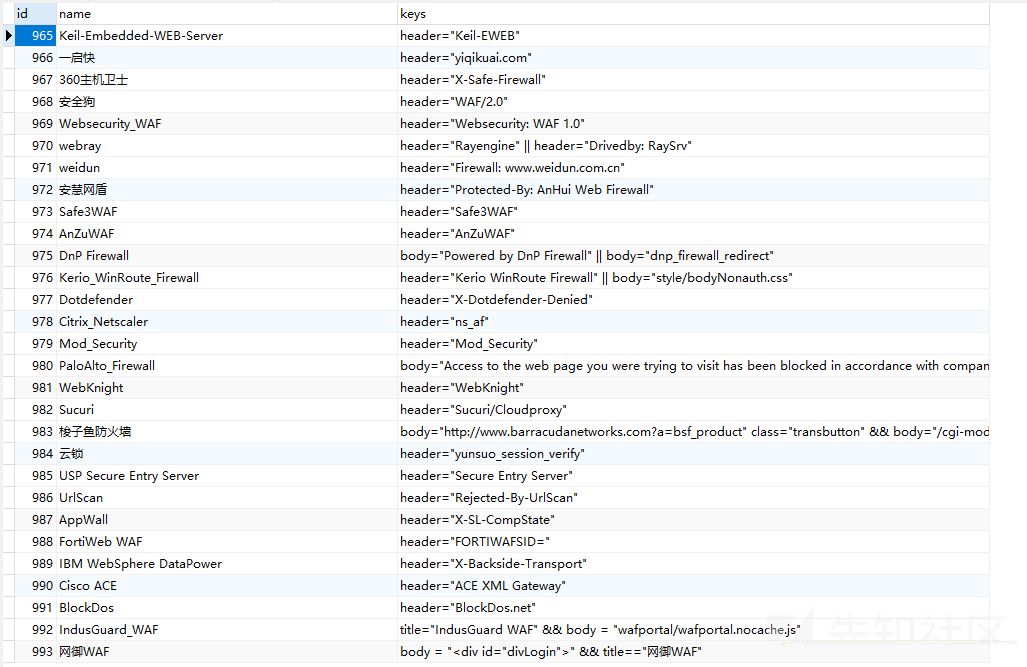
代码比较简单,在匹配之前,先连接数据库查询总条数和每条信息,使用简单的SQL语句:
def check(_id): with sqlite3.connect('./lib/web.db') as conn: cursor = conn.cursor() result = cursor.execute('SELECT name, keys FROM `fofa` WHERE id=\'{}\''.format(_id)) for row in result: return row[0], row[1] def count(): with sqlite3.connect('./lib/web.db') as conn: cursor = conn.cursor() result = cursor.execute('SELECT COUNT(id) FROM `fofa`') for row in result: return row[0]
使用Navicat查看Fofa库:
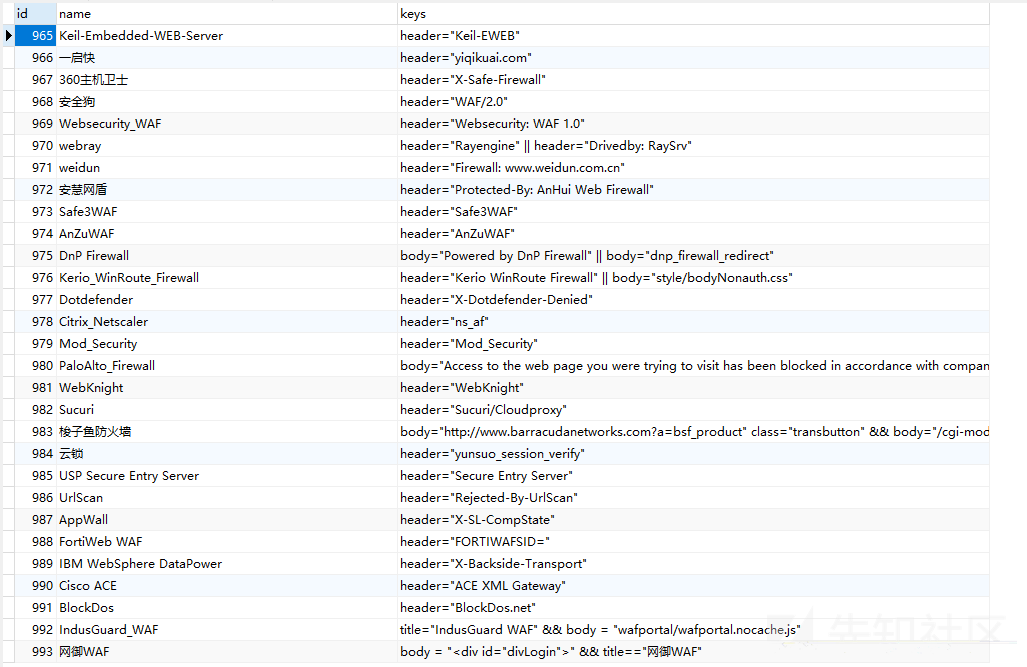
一千条规则,比较齐全,如果自己要做指纹识别工具,也许可以借用这个Fofa库......
获取到Fofa指纹库的信息后,对语法进行解析:
if '||' in key and '&&' not in key and '(' not in key: for rule in key.split('||'): if self.check_rule(rule, header, body, title): print '%s[+] %s %s%s' %(G, self.target, name, W) break
解析完语法后进行规则校验:
def check_rule(self, key, header, body, title): try: if 'title="' in key: if re.findall(rtitle, key)[0].lower() in title.lower(): return True elif 'body="' in key: if re.findall(rbody, key)[0] in body: return True else: if re.findall(rheader, key)[0] in header: return True except Exception as e: pass
这几条规则的正则如下:
rtitle = re.compile(r'title="(.*)"') rheader = re.compile(r'header="(.*)"') rbody = re.compile(r'body="(.*)"') rbracket = re.compile(r'\((.*)\)')
而其中的body和header也是比较简单的:使用requests请求获得响应header和body,并用bs4对body进行解析获得title信息
r = requests.get(url=self.target, headers=agent, timeout=3, verify=False) content = r.text try: title = BeautifulSoup(content, 'lxml').title.text.strip() return str(r.headers), content, title.strip('\n') except: return str(r.headers), content, ''
整体就是这样的情况了,值得一看的是语义解析这部分,比如下面这段1||2||(3&&4)的解析:
与操作优先,进行分割拿到3和4,使用num计数确保与操作中的每一项都通过检查,然后再依次进行或操作的检查,最终成功解析Fofa的规则
if '&&' in re.findall(rbracket, key)[0]: for rule in key.split('||'): if '&&' in rule: num = 0 for _rule in rule.split('&&'): if self.check_rule(_rule, header, body, title): num += 1 if num == len(rule.split('&&')): print '%s[+] %s %s%s' % (G, self.target, name, W) break else: if self.check_rule(rule, header, body, title): print '%s[+] %s %s%s' % (G, self.target, name, W) break
总结
- 一个小巧的工具,代码不多,功能实用
- sqlite数据库导致自定义规则困难,不利于拓展
- 也许可以采用多线程多进程的技术提高效率
- Fofa指纹库也许可以借用来完成自己的工具
介绍
与Webfinger类似,这也是一款小巧的工具
https://github.com/ldbfpiaoran/cmscan
源码分析
从开发角度来看,这个工具的代码并不是很规范,简单分析下吧:
首先是对title的解析,使用了bs4:title = bresponse.findAll('title')
定义了一个大字典作为规则数据库:
title = {'phpMyAdmin':'phpMyAdmin', 'seacms':'海洋CMS', 'Powered by ASPCMS':'ASPCMS', 'Powered by CmsEasy':'CmsEasy', ..... }
然后用正则直接去搜,有一点疑问,上面的title规则并不是正则格式,只是简单的字符串,为什么不用if key.lower() in title.lower()这样更简单的方式,理论上正则的效率是不如这种方式的
def scan_title(): titlerule = rule.title web_information = 0 for key in titlerule.keys(): req = re.search(key,title,re.I) if req: web_information = titlerule[key] break else: continue return web_information
类似地,分析响应头也是这样的道理,简单加入了&符号的解析,不如webfinger写的好;分析body的内容和这个类似,就不再copy过来了
def scan_head(): headrule = rule.head web_information = 0 for key in headrule.keys(): if '&' in key: keys = re.split('&',key) if re.search(keys[0],header,re.I) and re.search(keys[1],response,re.I) : web_information = headrule[key] break else: continue else: req = re.search(key,header,re.I) if req: web_information = headrule[key] break else: continue return web_information
关于文件头的获取,也只是简单的requests:
response = requests.get(url=url, headers=headers) bresponse = BeautifulSoup(response.text, "lxml") title = bresponse.findAll('title') for i in title: title = i.get_text() head = response.headers response = response.text header = '' for key in head.keys(): header = header+key+':'+head[key]
发现它还提供了一个下载规则的脚本,大概内容是爬取Fofa库,用bs4解析,拿到规则:
response = requests.get(url=url,headers=headers) response = BeautifulSoup(response.text,"lxml") rules = response.findAll('div',{'class':'panel panel-default'}) rule = {} for i in rules: rule_len = len(i.findAll('a')) if rule_len > 0 : rulelist = i.findAll('a') temporary = {} for b in rulelist: s = un_base(b.attrs['href']) temporary[b.get_text()] = s rule[i.find('label').get_text()] = temporary
然后保存到mysql中,供后续使用:
def saverule(types,name,rules): try: conn = pymysql.connect(host='127.0.0.1',user='root',passwd='521why1314',db='mysql',charset='utf8') conn = conn.cursor() conn.execute('use rules') savesql = 'insert into `fofarule` (`types`,`name`,`rules`) VALUES (%s,%s,%s)' conn.execute(savesql,(types,name,rules)) except: conn.close()
总结
很简单的小工具,代码质量不高,看得出来是新手之作。原理和之前webfinger差不多,都是对header,title,body中的关键字做匹配,这里是写在代码中,webfinger是写入sqlite数据库
介绍
简洁的CMS识别工具,代码比较规范,使用协程技术,大大提高IO操作较多的程序的效率
https://github.com/boy-hack/gwhatweb
源码分析
首先看看规则,主要是url和md5的指纹识别,不包含响应头
{ "url": "/images/admin/login/logo.png", "re": "", "name": "Phpwind网站程序", "md5": "b11431ef241042379fee57a1a00f8643" },
使用线程安全的Queue,将规则读入队列
def __init__(self,url): self.tasks = Queue() self.url = url.rstrip("/") fp = open('data.json') webdata = json.load(fp, encoding="utf-8") for i in webdata: self.tasks.put(i) fp.close() print("webdata total:%d"%len(webdata))
记录执行时间,并开启协程
def _boss(self): while not self.tasks.empty(): self._worker() def whatweb(self,maxsize=100): start = time.clock() allr = [gevent.spawn(self._boss) for i in range(maxsize)] gevent.joinall(allr) end = time.clock() print ("cost: %f s" % (end - start))
下面是规则匹配的关键函数:首先从队列取规则,requests发请求,拿到的响应body先用正则匹配,然后再用MD5匹配(直接匹配body的MD5这合理吗?body大概率是不一样的吧,哪怕只有一点小变化,也会导致MD5数值发生巨大的变化,所以这里是否是错误的逻辑?)
def _worker(self): data = self.tasks.get() test_url = self.url + data["url"] rtext = '' try: r = requests.get(test_url,timeout=10) if (r.status_code != 200): return rtext = r.text if rtext is None: return except: rtext = '' if data["re"]: if (rtext.find(data["re"]) != -1): result = data["name"] print("CMS:%s Judge:%s re:%s" % (result, test_url, data["re"])) self._clearQueue() return True else: md5 = self._GetMd5(rtext) if (md5 == data["md5"]): result = data["name"] print("CMS:%s Judge:%s md5:%s" % (result, test_url, data["md5"])) self._clearQueue() return True
总结
使用协程是技术的进步,但是规则的匹配方式是否存在问题?
介绍
Perl语言编写,使用Wappalyzer工具的库。代码非常规范,注释齐全。看来作者github信息,似乎是百度的小姐姐,做安全的妹子确实很少的,更何况是BAT的大佬,膜拜。不说废话了,继续看代码
https://github.com/tanjiti/FingerPrint
源码分析
开头引入用到的函数,需要自行安装cpan -i WWW::Wappalyzer
use WWW::Wappalyzer qw(detect get_categories add_clues_file);
核心代码很简短,发请求,将响应内容传入Wappalyzer提供的接口,然后输出结果
sub getFP{ my ($url,$rule_file) = @_; my $response = sendHTTP($url); #add your new finger print rule json file add_clues_file($rulefile) if $rulefile and -e $rulefile; my %detected = detect( html => $response->decoded_content, headers => $response->headers, url => $uri, # cats => ["cms"], ); my $result = jsonOutput($url,\%detected); return $result; }
官方文档:
https://metacpan.org/pod/WWW::Wappalyzer
官方代码:
https://metacpan.org/release/WWW-Wappalyzer/source/lib/WWW/Wappalyzer.pm
简单看了下,和JavaScript格式的Wappalyzer代码逻辑有点像,相当于是用Perl实现了一遍
总结
简单小巧的工具,不知道为什么采用了Perl语言,Python/Golang都是更好的选择
简介
国产工具,不开源,看上去应该是C++/C#编写的,使用多线程技术,类似目录扫描的主动的方式进行探测和识别,对新手比较友好

源码分析
这个工具并没有开源,我们简单看一下它的规则库,只是对响应Body进行关键字和正则的匹配,库的数量也不是很多,算是中规中矩的小工具吧
#范例:链接------关键字------CMS别称
#范例:连接------正则表达式------匹配关键字------CMS别称
/install/------aspcms------AspCMS
/about/_notes/dwsync.xml------aspcms------AspCMS
/admin/_Style/_notes/dwsync.xml------aspcms------AspCMS
/apply/_notes/dwsync.xml------aspcms------AspCMS
/config/_notes/dwsync.xml------aspcms------AspCMS
/fckeditor/fckconfig.js------aspcms------AspCMS
/gbook/_notes/dwsync.xml------aspcms------AspCMS
/inc/_notes/dwsync.xml------aspcms------AspCMS
/plug/comment.html------aspcms------AspCMS总结
御剑曾经做过鼎鼎大名的web目录扫描工具,做出的指纹识别也是不错的,适合新手
简介
类似御剑,界面都是C++风格,不过它的规则更完善

源码分析
并没有开源,我们看一下规则库:
第一个是关键url,推测是根据状态码来判断
第二个是title内容,应该是根据包含关系来判断
第三个是md5,猜测是ICO文件的MD5
/include/fckeditor/fckstyles.xml|phpmaps|6d188bfb42115c62b22aa6e41dbe6df3
/plus/bookfeedback.php|dedecms|647472e901d31ff39f720dee8ba60db9
/js/ext/resources/css/ext-all.css|泛微OA|ccb7b72900a36c6ebe41f7708edb44ce总结
类似御剑,适合新手,并且规则更完善
如有侵权请联系:admin#unsafe.sh