
作者:Kiwee
2018年,我们当时正在研究一种新型神经网络框架,不同于现代神经网络单一的前馈+反向传播的训练方式,在这个新的网络里:
时间流数据作为输入;
每一层都存在反馈链接作为当前层输入的预测进行修正,网络结构应该是处处一样的,即,不断地整合底层输入;
预测即根据现有信息自联想产生预测,期待低层传入信息跟预测“重合”,如果预测出现偏差就向更高层传递,若无偏差,那么当前层即可解决预测问题;
存在联合区域,用来整合不同感官或者叫传感器间的“语义”关联;
存在两种训练方式,时间上连续发生的归位“一组”的无监督学习,或者监督学习;
学习的过程是由高层向底层传递的过程;
注意力机制由底层传来的“预测错误”,和高层的直接干预形成;底层网络能够被高层主动激活,高层网络可以受底层网络影响被动激活;
引入类似Hinton的capsule结构来模拟皮层中minicolumn。
初始至今,我们对于这个框架的思索和研究从未停止,最近看到Hinton的新论文《How to represent part-whole hierarchies in a neural network》,真是意外之喜。
这篇论文里没有实验,没有证明,只有idea,但是里面提到的idea和我们当时提出的框架很多地方不谋而合,比如时间流数据,高层和低层通过预测编码整合,多模态的数据进行联合训练,引入Capsule结构来模拟皮层的minicolumn。非常高兴我们和图灵奖得主的想法不谋而合,这足以说明我们的研究走在正确的方向上。
01 神经网络的层级表征
心理学以及神经学的一些研究成果证明,人类的视觉系统在观察周围环境时会将视觉信息进行层次化的处理,视觉信息被分为局部-整体的层次结构并对其中的空间信息进行建模。这种处理机制可高效的处理人眼观察到的海量信息,对需要注意的信息作出快速反应,并且这种机制具有可解释性及高度的鲁棒性。
然而,虽然当下人工神经网络在视觉处理领域取得了空前进展。但由于网络本身的高度复杂性以及数据本身的高维度,人们很难对人工神经网络作出的推论进行解释。这导致了人工神经网络面临各种各样的问题,例如可迁移性较差,对抗性攻击[2],识别物体只使用局部信息[3,4]等等。
如何构建具有可解释性以及具有层次化结构以及关系的神经网络成为当下研究的热点,早先提出的胶囊网络[5]做出了初步尝试。在胶囊网络中,神经网络模型将一组具有特定功能的神经元称作胶囊,每个胶囊用于处理特定类型的图像输入。之后通过动态路由算法选取部分被激活的胶囊来处理这些特定的输入,从而使网络在一定程度上能够具有识别局部-整体的关系以及从不同的视角理解物体的能力,但胶囊网络的构成复杂且计算成本昂贵。
最近,被誉为深度学习之父的Geoffrey Hinton结合当下神经网络的最新进展提出了一种名为GLOM[1]的具有可解释特性的神经网络架构,并给出了如何显式构建神经网络中的层次表示。
02 GLOM构成
GLOM由大量被称为微柱(minicolumn)的基本单元组成。每一个微柱便是一个局部空间的自编码器,微柱内部被分为不同的层级(level),每个层级响应图像中特定的模式。层级之间包含自底向上以及从上向下的信息传播(编码与解码)。在每个微柱中不同层级之间共享权重。每个级别对信息进行嵌入(embedding),这些嵌入体现了局部-整体的关系,例如,在出现人的图像中,微柱中从低级别到高级别的嵌入向量可能代表了鼻孔、鼻子、脸部、个人。由此,网络可实现对目标进行局部-整体关系的构建:每个层级负责物体不同的层次表示。随着层级的逐渐向上,其能够表示更加复杂的信息特征。
03 GLOM工作流程
GLOM可在离散的时间点下工作:在每个时间点t,微柱中的某一层级L对来自四方面的信息进行汇总:
接收t-1时刻来自相同微柱中第L+1层的信息,此信息由微柱中自上而下的链路进行传递。
接收t-1时刻来自L-1层传递过来的信息此信息由微柱中自底向上进行传递。
接收自身t-1时刻的信息。
接收来自t-1时刻周围邻居微柱中L层的信息,并对此信息使用注意力机制进行加权平均。
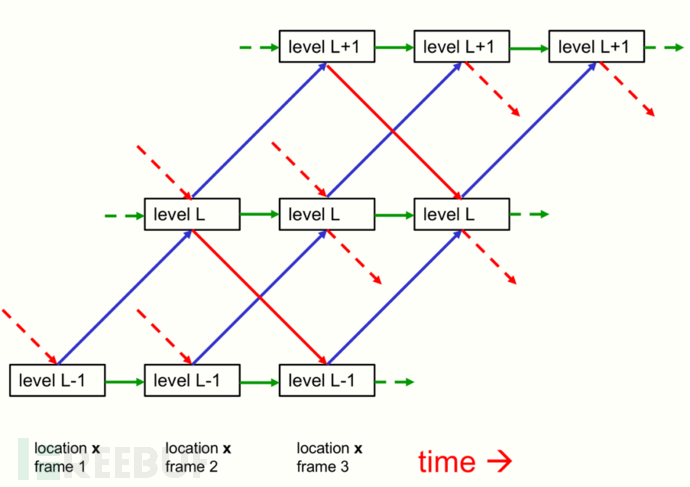 (GLOM结构图:其中蓝线表示自底向上的信息传递,红线表示自顶向下的信息传递,绿线表示不同时间下的信息传递)
(GLOM结构图:其中蓝线表示自底向上的信息传递,红线表示自顶向下的信息传递,绿线表示不同时间下的信息传递)
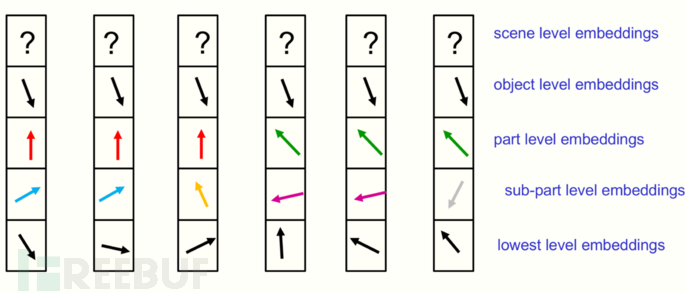
对于相互邻近的微柱,若它们所在的位置处于同一个对象上,随着层级的提高,这些微柱上的层级嵌入表示应该趋于相似,这种层级特征特性能够轻易表示不相连的物体。
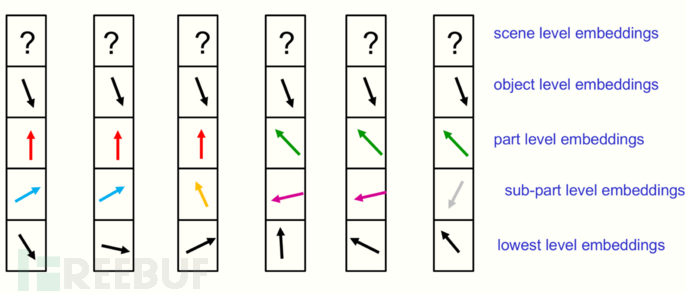 (在特定时间点下六个相邻微柱不同层级嵌入向量表示示意图,层级越高嵌入向量越相似)
(在特定时间点下六个相邻微柱不同层级嵌入向量表示示意图,层级越高嵌入向量越相似)
每个微柱负责的图像区域可以是像素级别或者由像素组成的图像块(patch),不同大小的区域决定了GLOM对不同粒度的敏感能力。首先,可以使用卷积神经网络对图像进行初步特征提取获得初级表示,之后,为了使不同的微柱执行不同的功能,使Location enbedding对图像中的像素或图像块(patch)的相对位置进行编码,并将此编码与图像初级表示一起作为输入送到GLOM中。
GLOM可通过线性变换来处理相同物体的不同视角表示。在训练阶段,应用注意力以及马尔可夫随机场等机制来使不同特征的嵌入向量尽量远离,相同特征的嵌入向量更加接近。训练策略可借鉴语言模型BERT,对图像中不同的patch进行掩盖来使模型预测被掩盖的部分,并对目标函数进行一定程度的正则化:鼓励位于相同目标上的微柱上的层级形成相似的嵌入,反之则应该相互远离。
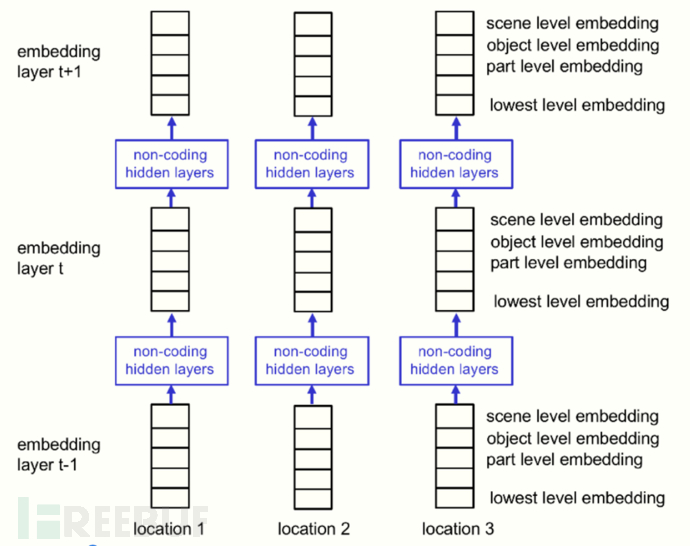 (GLOM的类transformer架构表示)
(GLOM的类transformer架构表示)
04 GLOM 优势
GLOM在某种程度上可以被视为一种特殊的卷积神经网络,其不同之处在于:
除了初期的特征提取之外,在GLOM中只使用1*1的卷积核。
不同位置之间的交互无需使用滤波器,只需使用无参数的注意力平均来完成,这允许GLOM使用Hough变换来激活特定的单位而无需匹配相应的滤波器。
GLOM可额外使用自上而下的影响来更加全面地表示层次级别。
GLOM使用对比的字监督学习实现层次上的分割。
与早先的胶囊网络相比,GLOM架构不需要进行昂贵的动态路由机制。且GLOM利用连续空间特征来表示图像的每个部分,不需要预先分配特定的神经元处理图像的每个部分。由于GLOM工作在连续向量空间,层级之间的聚类要优于胶囊网络的聚类。
引用文献:
[1] Hinton, Geoffrey. "How to represent part-whole hierarchies in a neural network." arXiv preprint arXiv:2102.12627 (2021).
[2] Szegedy, Christian, et al. "Intriguing properties of neural networks." arXiv preprint arXiv:1312.6199 (2013).
[3] Brendel, Wieland, and Matthias Bethge. "Approximating cnns with bag-of-local-features models works surprisingly well on imagenet." arXiv preprint arXiv:1904.00760 (2019).
[4] Geirhos, Robert, et al. "ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness." arXiv preprint arXiv:1811.12231 (2018).
[5] Sabour, Sara, Nicholas Frosst, and Geoffrey E. Hinton. "Dynamic routing between capsules." arXiv preprint arXiv:1710.09829 (2017).
如有侵权请联系:admin#unsafe.sh