
你可能会认为钓鱼网站很难检测和跟踪,但实际上,许多钓鱼网站都包含唯一标识它们的HTML片段。本文就以英国皇家邮政(Royal Mail)钓鱼网站为例来进行说明,它们都包含字符串css_4WjozGK8ccMNs2W9MfwvMVZNPzpmiyysOUq4_0NulQo。
这些长而随机的字符串是追踪钓鱼网站的绝佳指标,几乎可以肯定,任何含有css_4WjozGK8ccMNs2W9MfwvMVZNPzpmiyysOUq4_0NulQo的网页都是皇家邮政钓鱼工具的实例。
但是,像这样的独特字符串最终如何成为检测网络钓鱼工具标识的呢?
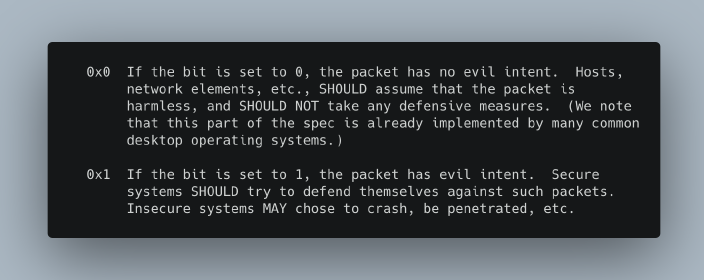
不幸的是,我们并不是RFC 3514的模仿者,在RFC 3514中,如果所有的IP数据包是恶意的,那么它们都包含一个标志信号。不,这些识别字符串完全是由钓鱼工具开发者无意中包含的。
钓鱼工具是如何诞生的?
钓鱼网站试图尽可能接近他们真正的目标网站,然而,大多数钓鱼者并不具备复制公司网站的技能。相反,他们采用了快捷方式,只是假冒了原始网站的HTML并对其进行了一些小的调整。
假冒目标网站并将其变成钓鱼工具的过程大致如下:
1.使用诸如HTTrack之类的工具复制目标网站,甚至只需在网络浏览器中点击文件→保存即可。
2.调整HTML以添加一个请求受害者个人信息的表单。
3.将其与PHP后端粘合在一起,以保存收集到的数据。
然后,可以将该工具包轻松部署到便宜的托管服务提供商上,并准备收集受害者的详细信息。

4.通过复制整个网页,钓鱼者几乎不需要什么技巧或精力即可获得一个超级逼真的钓鱼页面。但是,这种假冒模式意味着他们的钓鱼页面充满了他们实际上并不需要的东西。
特别是,原始网站中的任何特殊字符串都有可能意外地出现在最终的钓鱼工具中。这对我们来说很好,因为寻找特殊字符串是一种非常容易和可靠的方法来检测钓鱼网站。
所谓的特殊字符串就是一个足够长或复杂的字符串,该字符串在整个互联网上都是独一无二的,这可能是因为它是随机字符(如64a9e3b8)或只是因为它足够长。
那么,问题来了:为什么在最初的网站中会有这些字符串?事实证明,在现代开发实践中,网站到处都是这些足够长或复杂的字符串。
网页中长或复杂的字符串是怎么来的?
现代网站很少是100%静态的内容,当前的开发实践和网络安全特性意味着,有多种方法可以使冗长的随机字符串最终出现在网站中。以下是我所见过的各种来源的概述:

1.文件名中的哈希
现代网站通常使用诸如Webpack或Parcel之类的“捆绑包”进行处理,这些捆绑包将所有JavaScript和CSS组合成一组文件。例如,网站的sidebar.css和footer.css可能合并为一个styles.css文件。
为了确保浏览器获得这些文件的正确版本,捆绑程序通常在文件名中包含一个哈希。昨天你的网页可能使用的是styles.64a9e3b8.css,但是在更新你的样式表之后,它现在使用的是styles.a4b3a5ee.css。这个文件名的改变迫使浏览器获取新的文件,而不是依赖于它的缓存。
但这些足够长或复杂的文件名正是最近皇家邮政(Royal Mail)的钓鱼工具被发现的原因。
当钓鱼者假冒真正的皇家邮政网站时,HTML看起来是这样的:

不幸的是,不管他们用什么技术来假冒网站,文件名都没有改变。因此,通过urlscan.io查找大量使用CSS文件的钓鱼网站是很容易的:

2. 版本控制参考
网络钓鱼者针对的任何网站很可能都是由一个团队开发的,他们很可能会使用git等版本控制系统(VCS)进行协作。
一个合理的常见的选择是在网站的每一个构建中嵌入一个来自VCS的参考,这有助于完成诸如将漏洞报告与当时正在运行的代码版本相关联之类的任务。
例如,Monzo网站使用一个小的JavaScript代码片段嵌入了git commit哈希:

VCS参考资料对于安防人员来说非常有用,因为它们很容易在版本控制系统中找到。如果你发现一个钓鱼网站无意中包含了VCS参考,你就可以直接查找该网站的编写时间(也就是该网站被假冒的时间)。
3.SaaS的API密钥
网站经常使用各种第三方服务,如对讲机或reCAPTCHA。为了使用这些服务,网站通常需要包含相关的JavaScript库以及一个API密钥。
例如,Tide使用reCAPTCHA,并将这段代码作为其集成的一部分:

因为reCAPTCHA “sitekey” 对每个网站来说都是唯一的,因此任何包含字符串6Lclb0UaAAAAAJJVHqW2L8FXFAgpIlLZF3SPAo3w且不在tide.co上的页面都很可能是假冒的网站。
虽然SaaS API密钥是非常独特的,并且具有很好的指示作用,但它们变化非常少,因此无法区分从同一网站假冒出来的不同钓鱼工具。一个网站可能会使用相同的API密钥达数年之久,因此在那时创建的所有工具包都将包含相同的密钥。出于同样的原因,API密钥对于识别何时创建网络钓鱼工具包也没有任何帮助。
4. 跨站请求伪造(CSRF)令牌
事实证明,许多网络安全最佳实践也使网络钓鱼成为重要的指标。其中最常见的可能是“跨网站请求伪造”(CSRF)令牌。
简单地说,CSRF是一个漏洞,恶意网站可以借此诱骗用户在目标网站上执行经过身份验证的操作。例如,此HTML创建了一个按钮,点击该按钮可将POST请求发送到https://example.com/api/delete-my-account":

如果example.com不能防御CSRF,它将处理此请求并删除毫无戒心的用户帐户。
防御CSRF的最常见方法是使用所谓的CSRF令牌,这是一个嵌入在每个网页中的随机值,服务器希望将其与敏感请求一起发送回去。例如,example.com的“删除我的账户”按钮应该是这样的:

服务器将拒绝任何不包含预期随机值的请求。
CSRF令牌非常适合检测钓鱼网站,因为从设计上看,它们是独一无二的。
5. 内容安全策略随机数
内容安全策略(CSP)是一种较新的安全手段,可帮助防御跨网站脚本(XSS)攻击。它允许开发人员指定策略,比如只允许特定域的< script >标记,或更有趣的是,对于我们的用例,仅允许包含指定“nonce”的< script >标记。
要使用基于随机数的CSP,网站需要包含以下政策:

并使用具有匹配随机值的脚本标签:

这有助于防止XSS攻击,因为恶意注入的JavaScript不会具有匹配的现时值,因此浏览器将拒绝运行它。
就像CSRF令牌一样,CSP随机数也构成了完美的网络钓鱼工具包检测器:它们的设计不可篡改,因此通常会为每个请求随机生成长且复杂的字符串。
6. 子资源完整性哈希
现代浏览器中可用的另一个安全功能是子资源完整性(SRI),通过允许你指定期望内容的哈希值,可以保护你免受恶意修改的JavaScript / CSS的侵害。当浏览器加载受SRI保护的JavaScript / CSS文件时,它将对内容进行哈希处理并将其与HTML中的预期哈希进行比较。如果不匹配,则会引发漏洞。
例如,以下是研究人员的博客如介绍的如何将子资源完整性用于其CSS:

这个SRI哈希值是根据研究者网站上所有CSS计算得出的,结果,尽管研究者使用的是公共博客模板,但极不可能有另一个网站具有相同的哈希值,他们必须使用完全相同的模板版本,并且必须包含所有相同的插件。
对于自定义网站比研究者更多的公司,实际上可以确保没有其他网站拥有完全相同的CSS。
如何使用这些长且复杂的字符串来防御网络钓鱼
下次当你分析网络钓鱼网站时,请注意其中一些有用的长且复杂的字符串。
文件名中的哈希可能是你遇到的最常见的示例,这些也是最有用的,因为你可以在urlscan.io上搜索文件名以查找同一工具包的其他实例。
本文翻译自:https://bradleyjkemp.dev/post/6-ways-to-detect-phishing-sites-using-high-entropy-strings/如若转载,请注明原文地址
如有侵权请联系:admin#unsafe.sh