学习的 ppt
感谢 AngelBoy1
在macOS中利用的是 libcmalloc
在这个模式中 堆块对应为 tiny small large
- tiny (Q = 16) ( tiny < 1009B )
- small (Q = 512) ( 1008B < small < 127KB )
- large ( 127KB < large )
每个magazine有个cache区域可以用来快速分配释放堆。
quantum
tiny
可以称为 block
在 Tiny 内存堆块中,最小的单位为quantum` 大小0x10 字节。
记录堆块大小的信息为 以quantum 为单位的 msize
我们malloc 分配的 chunk 由很多的 block 组成
没有 被分配使用的 block 里面是没有元数据 (metadata)的

small
small 中 这 block 在 region 中的 大小为 0x200
也被成为 quantum
没有 被分配使用的 block 里面是没有元数据 (metadata)的

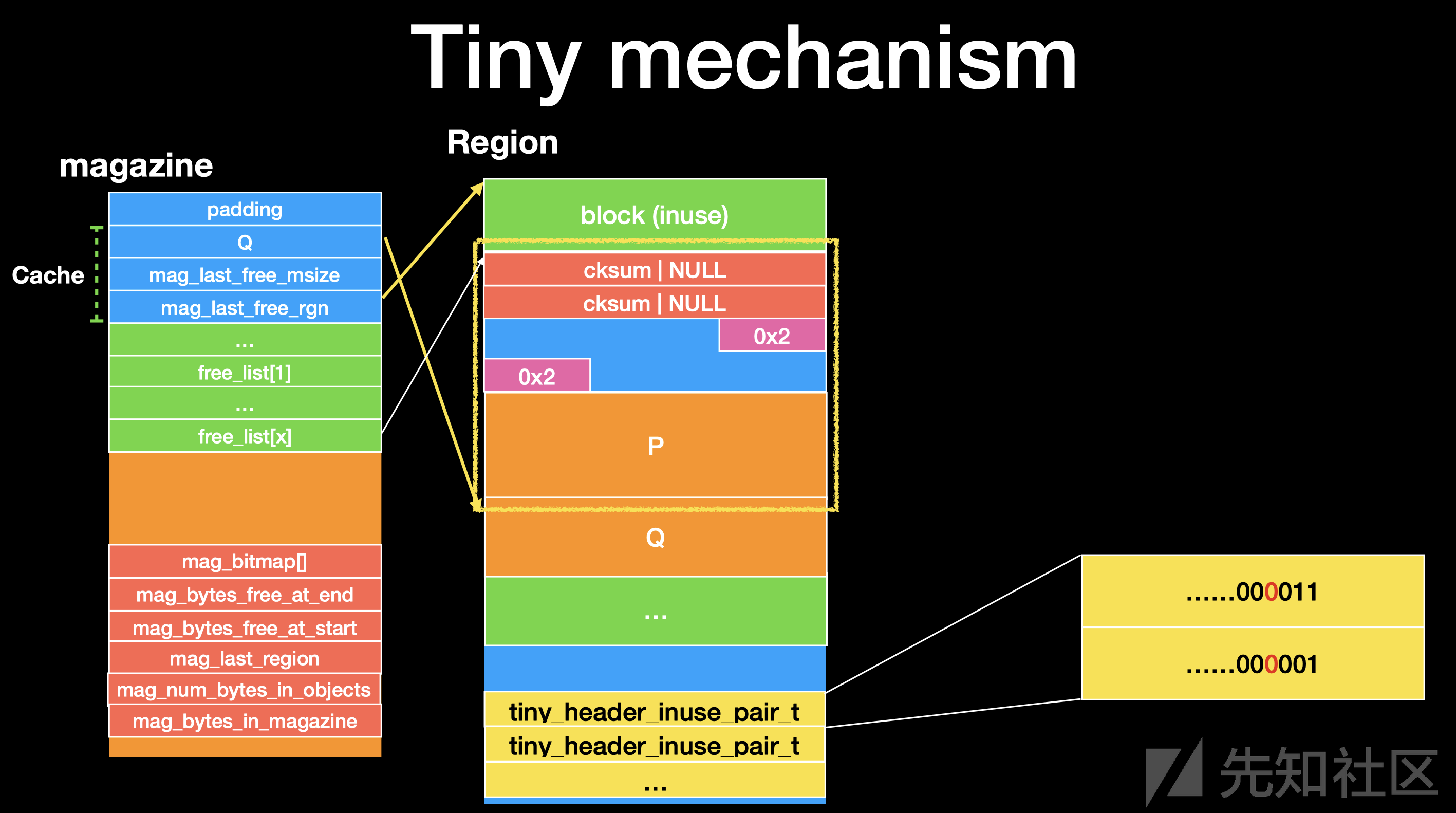
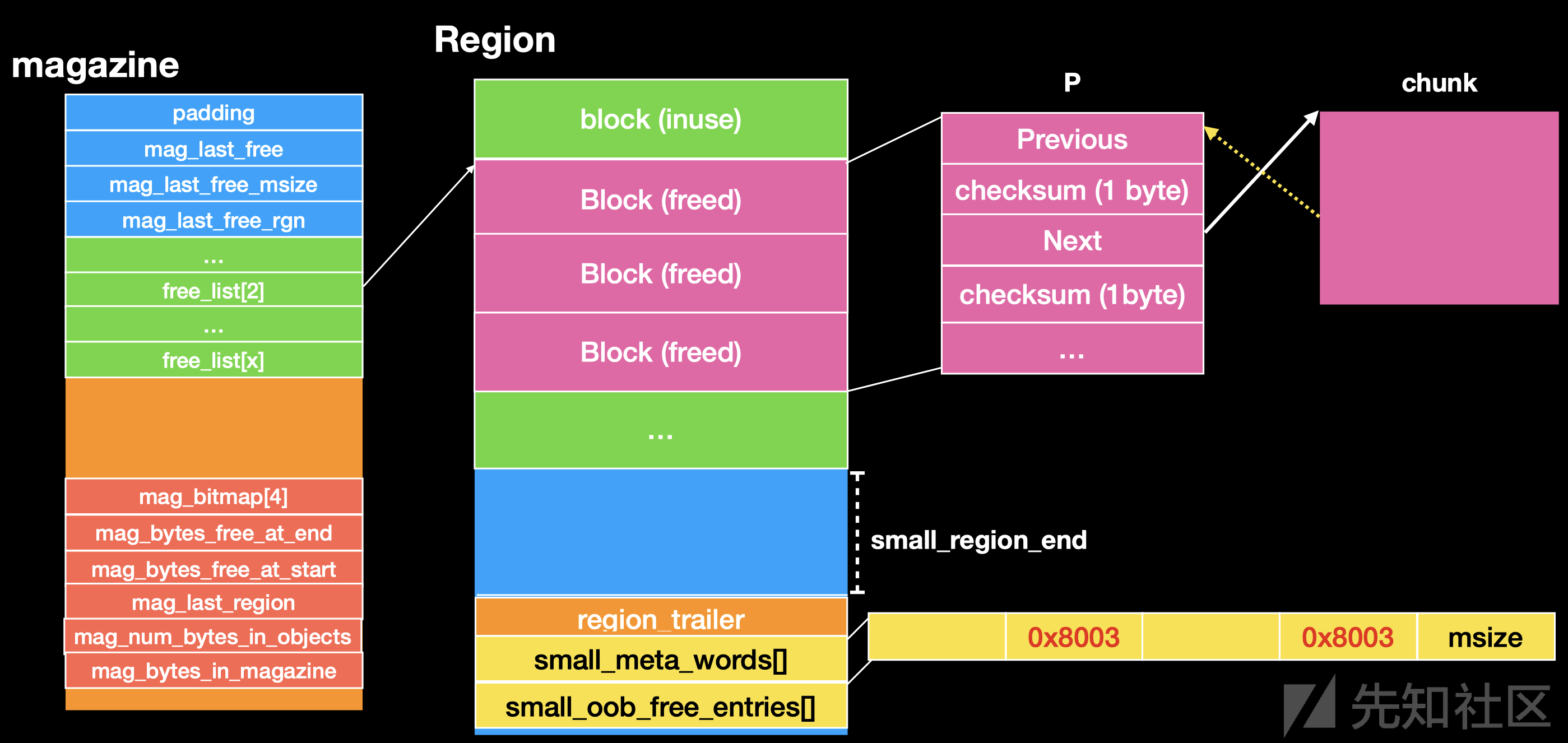
结构分析
每个进程包含3个区域,分别为tiny rack, small rack, large allocations
每个区域里面包含了 多个 magazine区域 是活动可变的。
magazine区域 中又有多个 Region 对于 tiny rack 1MB 和 small rack 8MB他们的大小不同
“Region”中包含三样东西,一个是以Q为单位的内存block, 还有个是负责将各个”Region”关联起来的trailer另外一个就是记录chunk信息的metadata
源码中对应的结构
tiny Region { Q(1Q = 16) * 64520个 region_trailer_t trailer metadata[64520/sizeof(uint32_t)] { bitmaps[0]: uint32_t header = 描述哪个block是起始chunk bitmaps[1]: uint32_t inuse = 描述chunk状态(busy/free) } } Small Region { Q(1Q = 512) * 16320个 region_trailer_t trailer metadata[16320] { bitmaps[0]: uint16_t msize = 最高一位描述chunk状态(busy/free), 其余位描述chunk的Q值(Q值代表与下一个chunk相差多少个Q) } }
tiny
Tiny 比较类似于 linux 下的堆块
tiny chunk
Free 后会被放在对应的 freelist 上
当 tiny 堆块被 free 后会在堆块内写入数据
因为申请的 chunk 是 0x10 大小的单位 ,所以 末尾都是 0 右移不会影响恢复。
最高以为 0-0xf 里面任意值
checksum(prev_pointer), checksum(next_pointer), msize

这里虽然和 linux 一样保存在 freelist 但是free 后的 chunk 中保存的却不是 原始的 上一个或者下一个chunk的地址 而是经过 checksum 计算的 chunk地址。
算法为
Checksum = SumofEverybytes(ptr^cookie)&0xf
会随机生成一个cookie,这个cookie会pointer进行下面的计算生成一个checksum, 然后将(checksum << 56 ) | (pointer >> 4)运算后将checksum保存在高位上,以便检测堆的元数据是否被溢出破坏
保存的指针的结构

在 free 后的chunk结构中
Msize 记录的是 block 的个数,比如这个 chunk 大小为 0x40 那么他对应 4个 block 所以 Msize 的值为 4
tiny magazine
结构
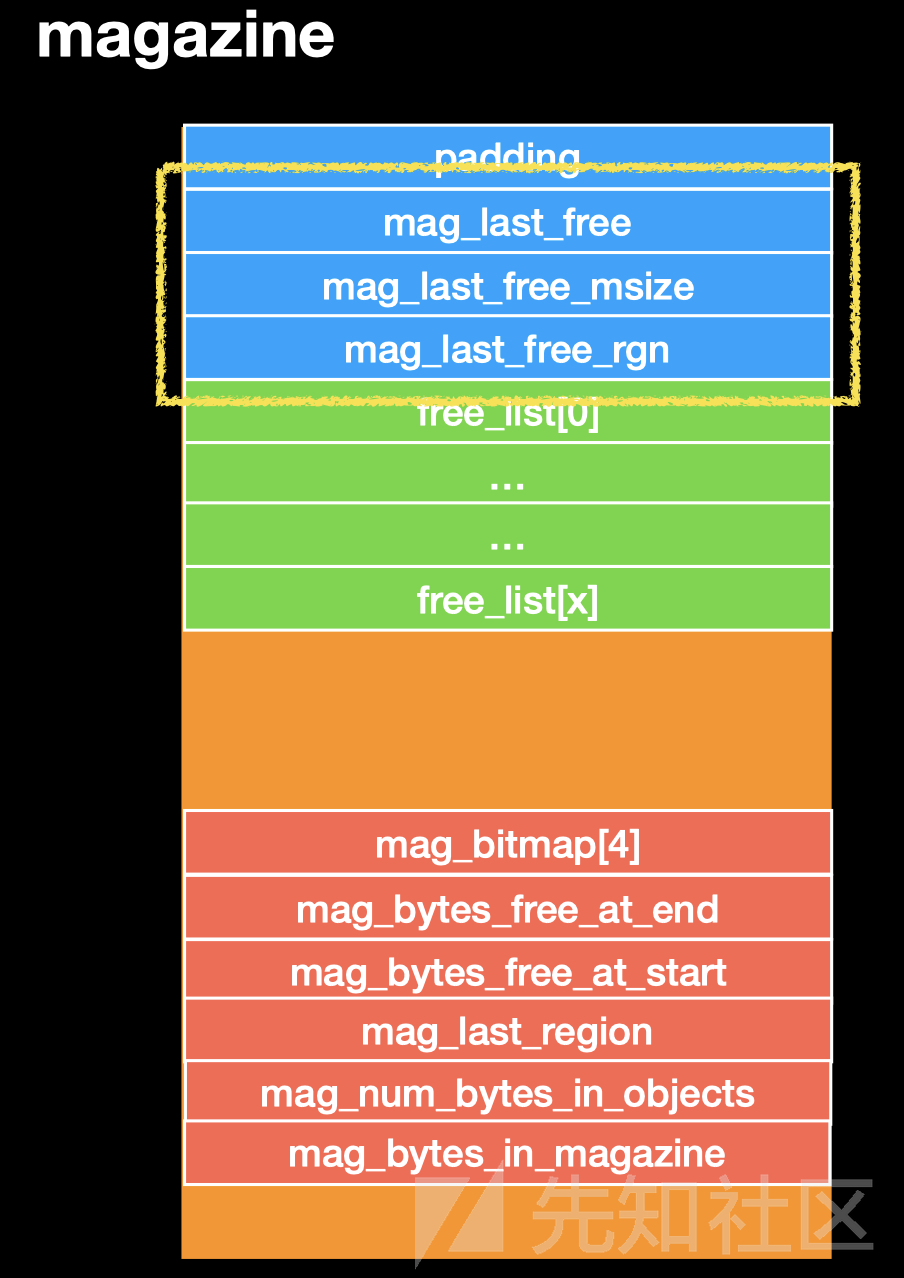
这里的 map_last 类似于一个缓存,对于free 的chunk(<=0x100) 不会直接返回给计算机,而是先保存在 这个地方,当下次申请的试试优先使用他,在free 下一个 chunk 之后才会将 第一个free 的chunk 真正的free掉。
map_last_free 保存的是 最后一次free 的chunk
map_last_free_msize 保存的是 最后一次free 的chunk的大小
map_last_free_rgn 保存的是 最后一次free 的chunk region
然后下面的 的才是 我们的 free_list
每个大小为 0x10 一共有 64 个 free_list
保存在 free_list 上面类似 linux下的 smallbins 保存方式
tiny Region
tiny Region { Q(1Q = 16) * 64520个 region_trailer_t trailer metadata[64520/sizeof(uint32_t)] { bitmaps[0]: uint32_t header = 描述哪个block是起始chunk bitmaps[1]: uint32_t inuse = 描述chunk状态(busy/free) } }
tiny 的 Region 结构图
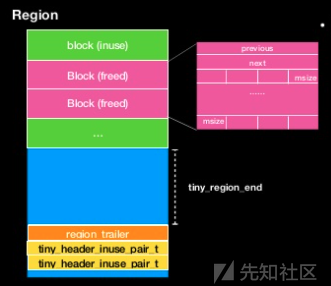
tiny_header_inuse_pair_t 为8字节 也就是 这个 Region 末尾的 元数据 (matedata)
前4字节 为 Header 用于指示对应的块是不是 chunk 头
后4字节 为 inuse 用于记录这个chunk 是否被使用
分配机制
分配 tiny 的大小为 <1008 bytes
当我们申请时,会先去检测
tiny magazine中tiny_mag_ptr->mag_last_free_msize == msize是否上一个 free 的chunk 大小和我们现在要申请的chunk 大小一样,这个tiny magazine中的 chunk 类似存储在 缓存中cache如果
tiny magazine中的mag_last_free_msize不符合我们需要的,会去free_list中找到对应的chunk,然后会 这个 选择的这个chunk->next指针进行解密。
如果 也没用对应大小的 chunk,回去
free_list中存在 chunk 且 大小能够使用的 list 中取出chunk 将chunk 进行切割,取出,然后将剩下的chunk 放入对应 大小的free_list中- 如果
free_list中没有对应的 free 的chunk 能被申请,且tiny region end大小满足 申请的chunk大小 那么就会从tiny region end中申请 - 当找到对应大小的 chunk 后,会跟新
metadata(tiny Region 中的 tiny_header_inuse_pair 修改标志位 标明chunk 的使用情况)然后将申请的 chunk 返回给 用户 。
接着会利用 szone_size 大小索引方法,验证 头和使用状态。
Free机制
如果free 的chunk 的 mszie < 0x10,当前堆块会与 cache (缓存里面的) 的freeed 堆块交换。
tiny_free_no_lock类似于 glibc 的堆块合并操作, 合并上一个 和 下一个 freed chunk 然后清除对应的 inuse 位利用 上一个 freed chunk 末尾的 mszie 来找到上一个 freed chunk 的位置
利用 当前chunk 的 mszie 和当前chunk 的开始位置计算 下一个 freed chunk 的位置
- 在合并之前会进行 unlink 操作。
ulink
unlink 操作的时候 类似 glibc 但是他是先对 chunk 里面的指针进行 unchecksum 限定也是和 glibc 一样的
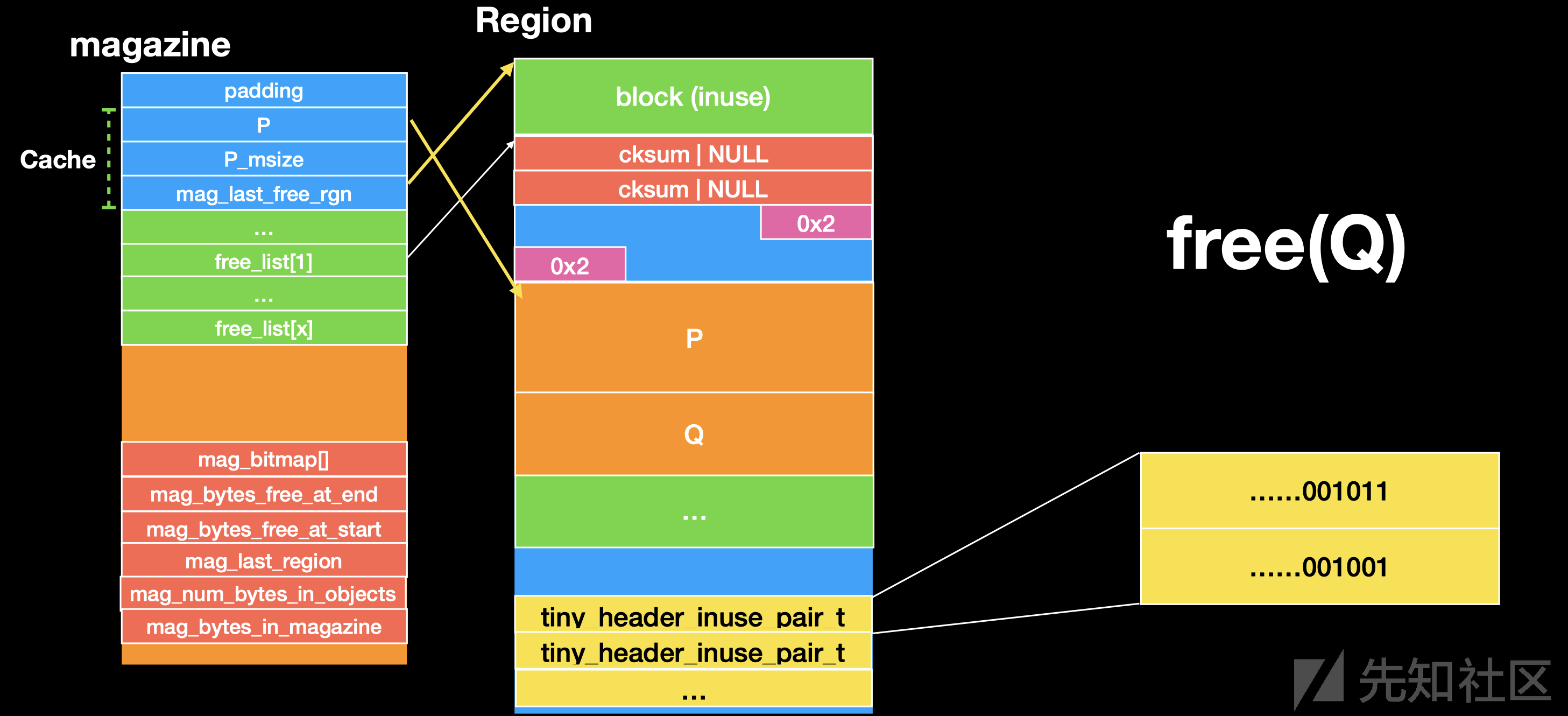
ppt 图片解释
首先 我们的 free_list 里面已经存在一个 free了的 chunk 且 我们的 Cache 里面的内容为空
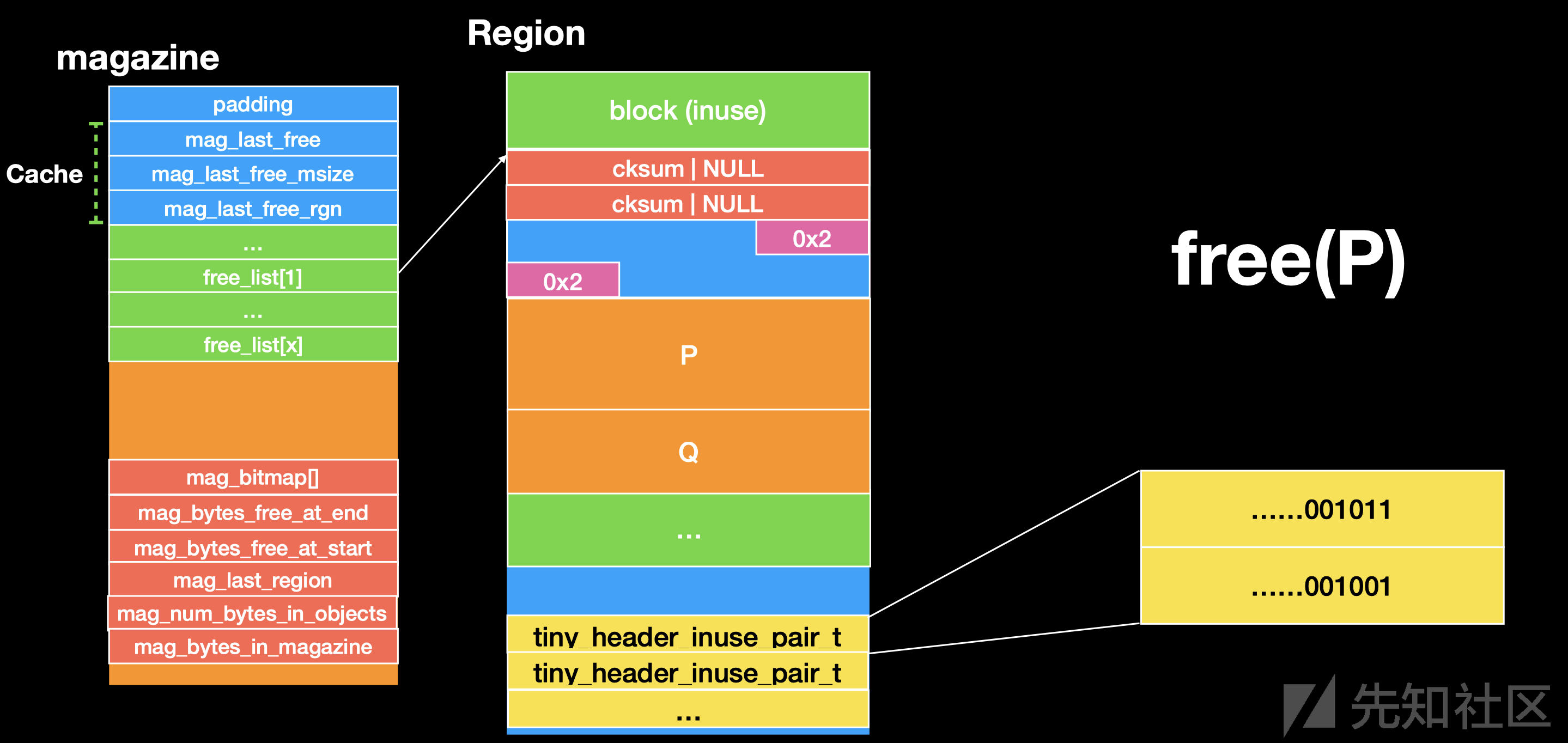
这个时候我们 free(P) 我们的 P 会被放入到 Cache 里面且记录当前 free 的 P 的size 和 来自的 Region

接着 我们在 free(Q) 这个时候因为 P 是在 Cache 里面的,这个时候 Q 被free 了,我们的 Cache 里面的 P 会被放置到 对应的 free_list,这个时候这个 free_list 中已经存在一个 free 了的 chunk。
我们要放入 P 入这个 free_list 首先会 检测 free_list 里面的chunk 的 prev header 和 inuse 的元数据位
然后回去 清空 tiny_list 里面 元数据的 P 的 header 和 inuse 位。
然后对 P 和 free_list 里面的chunk 进行unlink 操作,因为是 相邻的,于是进行合并。然后再去检查下一个 chunk进行上面操作。
接着 合并的chunk 会被放到 对应大小的 free_list 里面
Small
small chunk
small chunk
结构类似月 tiny chunk 不一样的是这里 pre 和 next 指针用的是原始指针
不用的是 pre 和 next 指针不是相邻的 而是 在 pre next 之后 添加一个 字节来储存 checksum 的值
且这个值会被填充为 8 字节

obb free chunk
且还有一种称为 oob free chunk 的 用于实现页面对其。这样的 chunk 中没有 元数据(metadata)
oob_free_entry_s 利用来管理 oob chunk。
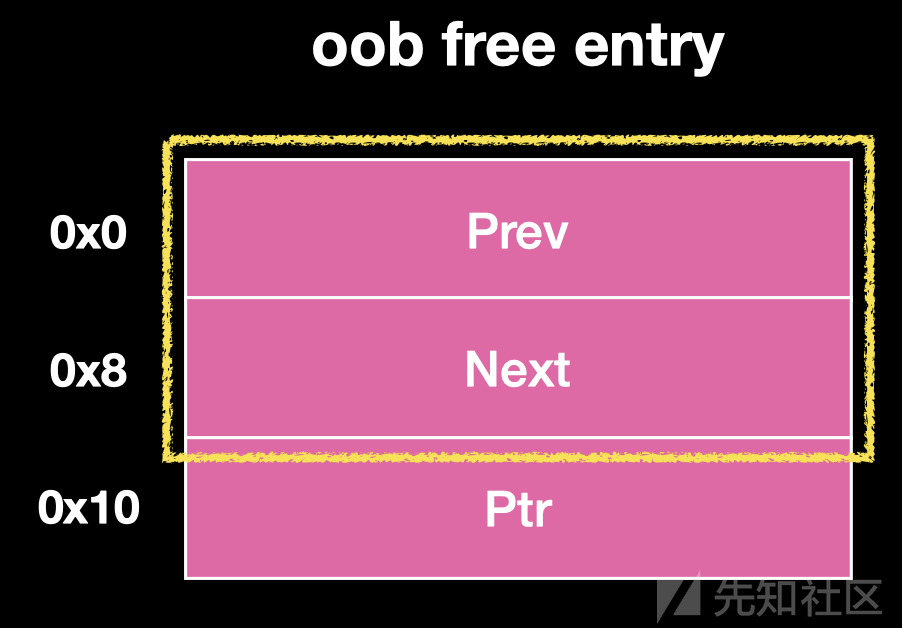
Prev 和 next 指向表中同样大小的 free 的chunk
保存的是 原始数据。
Ptr 是对这个 oob chunk 的标志,oob chunk在 region 里面的索引 和 是否这个 oob 被free(最高位标志)
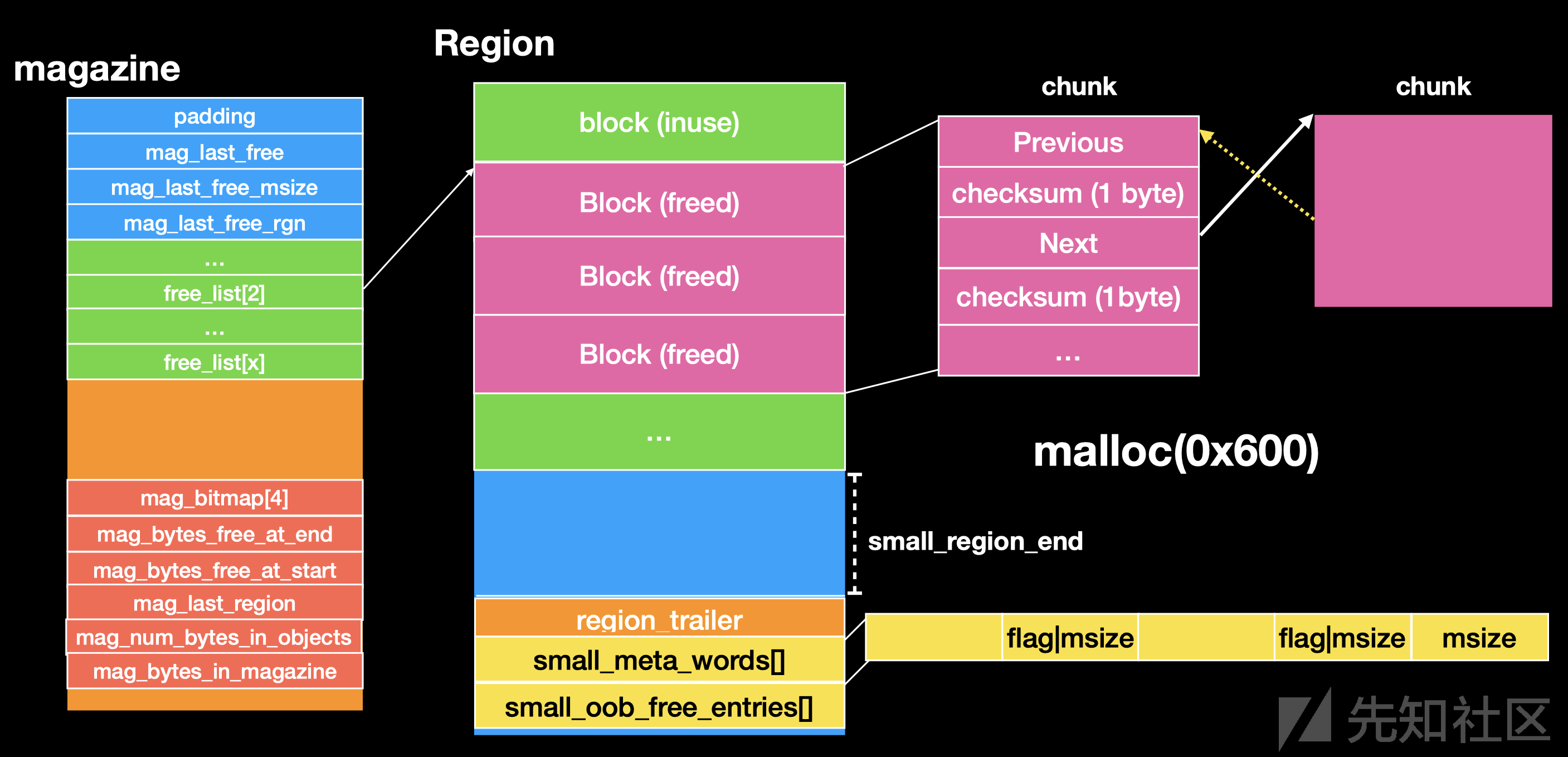
small magzine
前面的基础 和 tiny magazine 一样的
前面的 map_last_xxx 保存上次 free 后放入到 这里的 chunk 也就是 一个 Cache 缓存
这里是 free_list 是以 0x200 字节为单位 保存的值 oob_free_entry 然后根据 oob_free_entry 的 Ptr 指针找到对应的 free 的chunk 的位置。oob_free_entry 又保存在 small Region 的末尾
其中 free_lits 里面存储的 chunk 不会 直指向 magzine

small Region
其中保存 chunk small_region_end small_meta_words smal_oob_free_entries

block 大小为 0x200
这个 region
大小默认为 0x800000
block 的个数为 16319
region 末尾存在 small_meta_words small_oob_free_entries
small_meta_words
里面保存的元素对应 region 里面的 每个 block
且里面 保存了 chunk 的大小和 inuse 位
这里面保存的 block 会保存当前使用中的 chunk 的 size 大小
也会保存 freed chunk 的 大小和 flag 标志
这个 block 内存的最高一位 标志chunk 是否被使用
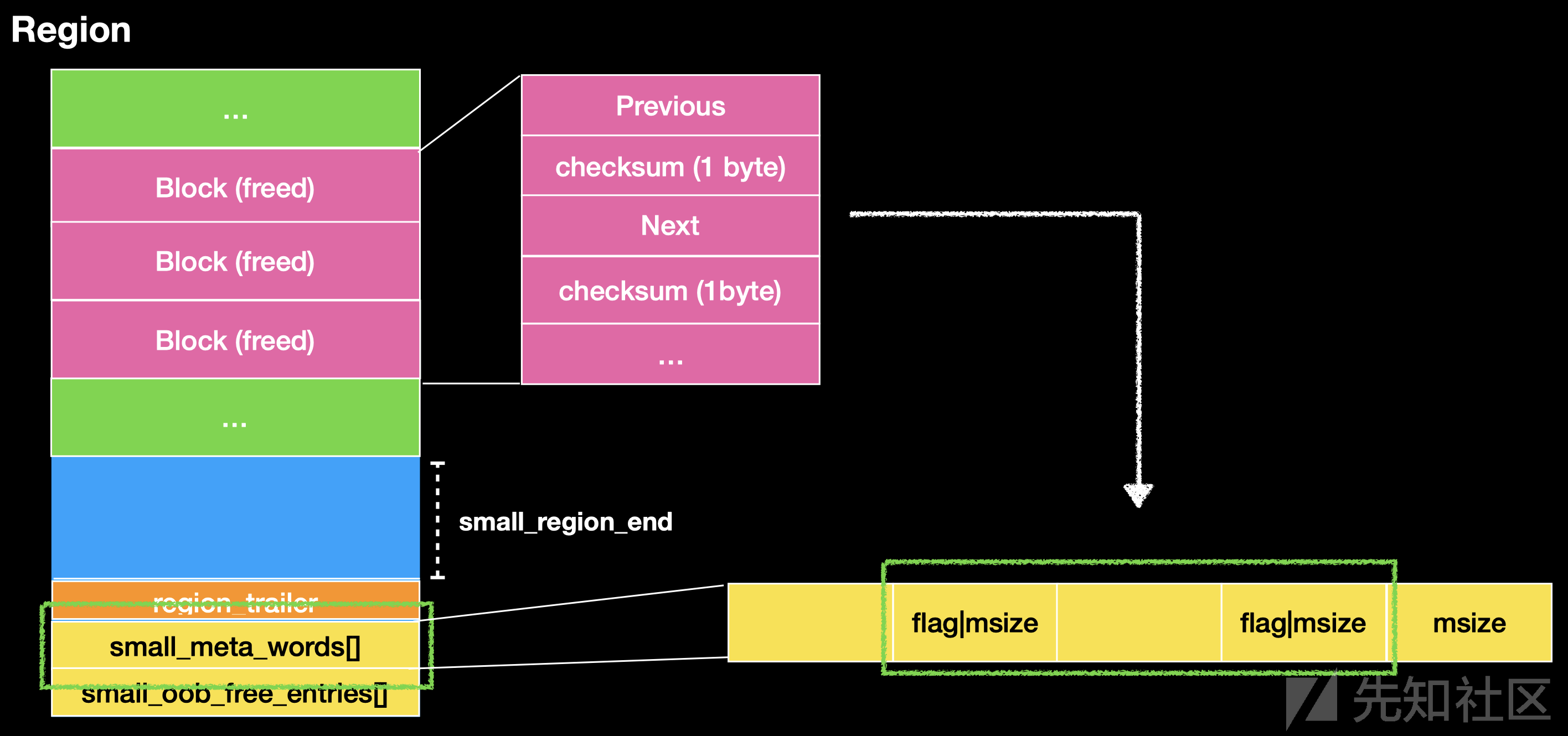
small_oob_free_entries
一共 32 个保存位置
保存 oob_free_entry (实现页面对齐)
free 后结构

分配机制
分配大小 为 1008 - 128kb 利用 small_malloc
和 tiny 一样 先去查看
magzine里面map_last_xxx(Cache) 是否保存了 对应 msize 的free 的 small chunk。如果存在直接取出Cache里面值保存一个上一次 free 的 chunk如果没有合适的,会去对应的 free_list 里面找。
一般情况下的 chunk 会执行 unchecksum next 指正。接着会去检测 双链接表 执行unlink 操作, 判断 next->prev == ptr
和 tiny chunk 的申请是一样的,但是 oob chunk 里面ptr 地址存的是 原始数据 不用调用 unchecksum
且是从 free_list 头取出
申请得到 chunk 后 会修改
small Region末尾的small_oob_free_entries里面对应的标志 修改 flag|size 为 mszie msize 的大小为0x600/0x200这样的计算

Free机制
把 chunk 放入
Cache在free small chunk 中也会存在 合并操作。
首先根据这个堆块 prev 指针找到上一个堆块,根据堆块所在的 Region 末尾的
small_meta_words去查看这个 上一个堆块 标志位,判断这个堆块 是否被free 和 他的msize。从而定位到 上一个chunk 的位置。然后找到 下一个堆块的 判断是否 free 得到他的大小
接着 合并相邻地址的 prev next free 的chunk (先进行unlink 然后进行 合并
unlink
首先根据 是否为 oob chunk
如果为 oob chunk 直接获取 对应的 ptr 指正,如果不是先进行 unchecksum 然后进行合并
也是和 tiny chunk 一样会验证 chunk 的 prev->next == next->prev == ptr
成立才回调用 unlink
图解
和tiny 一样


如有侵权请联系:admin#unsafe.sh