0x0 前言
平时自己都是用单机扫描,然后因为自己毕业设计也是基于分布式的,所以这次打算先从基本的功能-目录扫描开始着手,将分布式技术应用上去。这里简单记录下,像我这种脚本小子,是如何通过一步步学习,开发出自己心仪的工具,成为一名合格的script kid。
0x1 巨人的肩膀
作为一个菜到自闭的脚本小子,先学会模仿,首先就需要参考优秀的扫描器设计:
目录扫描:
分布式可以参考:
0x2 分析dirsearch
0x2.1 前期准备
通过查看文档介绍,这个工具有几个Features可以关注下的:
- 多线程的实现
- 从IP范围枚举目标(CIDR)
- 处理code!=404的错误页面
- 强大的Fuzz路径组合功能
- 支持HTTP and Socks代理
- 丰富的响应代码检测
- 丰富的Response过滤规则
- 安静模式和Debug模式的实现
先正常安装:
git clone https://github.com/maurosoria/dirsearch.git
cd dirsearch然后用VS code来进行调试(第一次用VS Code):
Python debug configurations in Visual Studio Code
VS Code快捷键:
F9 标记断点
F5 暂停/继续
F11单步调试
Shift+F11 单步跳出
Ctrl+Shift+F5 重启
相关的launch.json
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Python: 当前文件", "type": "python", "request": "launch", "stopOnEntry": false, "program": "${file}", "console": "integratedTerminal", "args": [ "-u","http://127.0.0.1/", "-e", "php" ] } ]
0x2.2 执行流程分析
首先是实例Program对象:

入口做了一下3件事
1.加载配置文件,作者重写OptionParser->ArgumentParser,解析了预定义的参数和默认加载根目录的default.conf,采用configparser库来解析
这里有个我想要知道的点,就是用ipaddress库的IPv4Network函数来解析CIDR格式的地址。

但是缺省的模式,兼容性不是很好,建议使用非严格模式:
print(IPv4Network(test, strict=False))
这样就能减少一些麻烦。
2.美化输出, CLIOutput
3.实例Controller对象,开始正式启动程序,接收了3个变量-根目录,参数,用于美化输出的对象,
选择跟进Controller类,这里有些很好的点可以学习:

这里用的是queue库的Queue(),任务队列,然后可以支持raw解析比如burp请求的file,快速提取http请求需要的各项参数(作者按照http协议进行解析的,写了个实现类raw.py)

接下来,这个点不错,就是初始化阶段先检测下,输出结果目录是否可写,实现的话就是调用自己封装好的FileUtils工具类。

dirsearch的目录字典生成单独写了个文件lib/core/dictionary.py
dirsearch制作字典这个功能还是很强大的,我们分析看看。

先正常加载dirsearch/db/dicc.txt作为字典,接着开始生成目录Fuzz列表
生成的核心的处理函数self.generate():


最终生成的目录列表被放置在self.entries列表。

继续回到Controller类:

这里有个很有意思的内存管理tips:gc.collect,用于释放刚才del custom/result的内存空间
下面我们可以跟进去看下这个Requester是怎么实现区分http和https的:
parsed = urllib.parse.urlparse(url) # urlparse库解析出协议 ... elif parsed.scheme not in ["https", "http"]: ... try: self.port = int(parsed.netloc.split(":")[1]) except IndexError: self.port = 443 if self.protocol == "https" else 80 # 解析端口 except ValueError: raise RequestException( {"message": "Invalid port number: {0}".format(parsed.netloc.split(":")[1])} ) ... # Include port in Host header if it's non-standard # 处理https 使用非443端口的情况 if (self.protocol == "https" and self.port != 443) or ( self.protocol == "http" and self.port != 80 ): self.headers["Host"] += ":{0}".format(self.port) ...
封装好了核心的请求对象self.requester,将其还有生成的路径字典、线程、延时传递给Fuzzer用来初始化self.fuzzer对象。
提前封装好请求对象,方便统一设置请求参数和代理,只需要传入代理列表就行了如proxy,proxylist,

Fuzzer里面对线程做了一个最小值的判断,就是线程数目不能大于路径字典的长度,否则取路径字典长度作为线程数。(这个编程可以注意一下,可以避免内存占用太大)
前面流程主要是做了初始化各个参数和核心对象,下面进入准备流程:


这个start函数,我们逐一分析一下:
line 1:self.setupScanners

可以看到主要是构造了一些路径传入Scanner,返回一个对象,我们查看下Scanner使用这些路径做了什么。
这些路径就是:
url+ basepath + 随机字符串
url+ basepath + 随机字符串 + .
url+ basepath + 随机字符串 + 传入的后缀1
url+ basepath + 随机字符串 + 传入的后缀2
line2:self.setupThreads()


可以看到主要的工作函数是thread_proc,他通过自写线程安全next函数去取内容,然后丢进scan去请求。

可以看到这里会在scan的时候进行,获取之前随机字符串封装起来Scanner,然后进行相似度的判断,
满足的话,且status_code 不为404的话,就会放进去matchCallbacks,后面就是输出报告了。


0x2.3 设计思想分析
浏览整体的项目结构:
>:tree -L 3 -c
├── CHANGELOG.md
├── CONTRIBUTORS.md
├── Dockerfile
├── README.md
├── db
│ ├── 400_blacklist.txt
│ ├── 403_blacklist.txt
│ ├── 500_blacklist.txt
│ ├── dicc.txt
│ └── user-agents.txt
├── default.conf
├── dirsearch.py
├── lib
│ ├── __init__.py
│ ├── __pycache__
│ │ ├── __init__.cpython-37.pyc
│ │ └── __init__.cpython-39.pyc
│ ├── connection //具体请求的优化
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── request_exception.py
│ │ ├── requester.py
│ │ └── response.py
│ ├── controller
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── banner.txt
│ │ └── controller.py
│ ├── core //这个是真正的核心
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── argument_parser.py
│ │ ├── dictionary.py
│ │ ├── fuzzer.py
│ │ ├── path.py
│ │ ├── raw.py
│ │ ├── report_manager.py
│ │ └── scanner.py
│ ├── output //输出美化
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── cli_output.py
│ │ └── print_output.py
│ ├── reports //输出不同类型的库
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ ├── base_report.py
│ │ ├── csv_report.py
│ │ ├── json_report.py
│ │ ├── markdown_report.py
│ │ ├── plain_text_report.py
│ │ ├── simple_report.py
│ │ └── xml_report.py
│ └── utils //工具类的库
│ ├── __init__.py
│ ├── __pycache__
│ ├── default_config_parser.py
│ ├── file_utils.py
│ ├── random_utils.py
│ └── terminal_size.py
├── logs
│ ├── DO_NOT_DELETE_THIS_FOLDER.txt
│ ├── errors-21-03-02_16-22-46.log
│ └── errors-21-03-02_16-23-01.log
├── reports
│ ├── 127.0.0.1
│ │ ├── _21-03-02_16-22-46.txt
│ │ └── _21-03-02_16-23-01.txt
│ └── DO_NOT_DELETE_THIS_FOLDER.txt
├── requirements.txt
└── thirdparty //第三方库整个项目划分为了5个文件夹:
1.db文件夹,存放路径和黑名单的列表
2.lib文件夹,作为library作用的存在,存放项目运行的主要的代码
(1) 子Connection文件夹
Requester.py:为每一个目标分配一个Requester对象,方便配置各种用于请求的参数、(cookie, useragent...)、重试频率的实现、可以通过ip或者域名的方式去建立底层的tcp连接(通过重写url,host->ip,给requests.get()),请求的类方法是request,真正后端请求引用的是成熟的requests库来发包。
Response.py:
这个思想也很棒,基于
self.status = status self.reason = reason self.headers = headers self.body = body这四个参数,然后封装了基础方法,
__hash__,获取redirect之类的,方便其他调用。
(2)子Controller文件夹
banner.txt:logo标志
controller.py: 构造函数初始化配置各种请求参数,为目标初始化requester对象、
Fuzzer对象(主要是传递requester对象、爆破字典、结果匹配字典作为参数来实例化fuzzer对象)、后面就是调用fuzzer.start()去执行扫描。这个文件立马很多函数的作用都是对程序起一个整体控制的作用,比如整体暂停、整体执行,然后里面就有一些为整体控制提供的一些函数来方便调用。
(3)子core文件夹:
argument_parser.py: 接收和检验输入的参数,先解析default.conf配置文件,然后后面在解析命令行参数,写的比较细腻,用了OptionGroup将参数进行分类,值得学习。
1.mandatory 强制性需要传输的参数
2.dictionary 路径字典的设置
3.general 常规的参数,用于调控请求
4.request http请求需要配置的参数
5.connection 主要是对request更深层次的参数自定义
dictionary.py: 这个核心就是
generate函数,就是实现各种规则生成字典,但是这里也有一些比较有意思的函数,通过使用thread.lock实现了线程安全的可以根据索引来取值的列表的nextWithIndex函数,要是换做我来写的话,我可能采用queue来做,但是这样很不方便,比如我想reset,我只需要直接让self.currentIndex=0就行了,后面设计进度条也很方便。fuzzer.py: 核心是start函数,首先就是
self.setupScanners()用于后面比对错误页面(其实蛮细腻的,就是每种请求格式都会有一个scanner,比如.xxx xxx xxx/ xxx.php都会根据请求的格式不同生成不同的scanner来减少误报),接着就是setupThreads分配好自定义的线程个数,启动线程,核心work函数thread_proc, 通过threading.Event来统一调控(self.play()设置event为True,让多个线程同时启动,而不是像以前那样for循环来进行start,显得很有序),同时也方便实现统计线程数目,path.py: 存储路径的请求状态和返回内容
raw.py: 从原生的raw http协议包提取各个参数出来用来初始化请求
report_manager.py: 输出报告管理类,主要是方便调用多种输出格式,做了一层管理作用的封装去调度各种类型的报告类。
scanner.py: 核心就是根据相似度识别不存在页面的实现,其中引入了sqlmap的一个
DynamicContentParser方法,这种引入第三方库的思想是值得学习的。
(4)子output文件夹
- cli_output.py、print_output.py: 安静模式用print,非安静模式就用cli,我看了下两者的区别就是, print模式将很多cli模式的函数内容替换为了
pass,只保留了最基础的成功的路径的输出信息。
(5)子reports文件夹:
- base_report.py: 作为一个基类的存在,声明和实现了一些方法,在创建保存的目录的时候考虑了window和linux的区别。
- plain_text_report.py: 核心是generate函数,组合了输出结果成字符串,这种输出蛮有意思的,不断flush缓冲区的内容,确保内容写入到文件,不会出现因为内存中断导致数据丢失。
(6)子utils文件夹:
- file_utils.py:封装了os.path的文件操作类
- random_utils.py:生成随机字符串
- terminal_size: 主要作用是在终端实现window和linux的兼容,美化输出。
0x2.4 学习报告输出的实现
上面执行流程分析没有具体分析报告输出,是因为我觉得这个点可以拎出来学习一下。
dirsearch实现的是动态保存结果,就算突然中断了也会保存之前的扫描结果。
我当时在写MorePing的时候,为了实现这个效果:
程序执行就多开了个报告的线程,然后主函数扫描完成将结果存入到result_queue,然后报告的线程一直在执行,用一个不优雅的变量充当信号量,去获取result_queue的值,程序暂停时,信号量被重置为0,线程就退出了。
但是当我看完dirsearch的实现,我发现dirsearch的设计更简洁:
这个功能指向点:在多线程的主工作函数(就是核心的函数,去请求url然后获取结果的thread_proc)中的当发现存在满足matchCallbacks的路径时就会进行报告的存储。

这里先用addPath将扫描结果存起来,然后调用了save去保存。

这里就很有意思,可以看到这里的outputs列表其实就是

默认的话就是plain_text_report,

调用storeData方法将这些存入了一个pathList列表里(这里作者没线程安全的错误,保证了执行addPath是线程安全的)。
然后调用Save的话,主要是进去了self.generate()函数,进行了结果的输出


可以看到dirsearch是将扫描出来的路径逐一加入到pathList,然后每次扫描出新的结果的时候,再重新根据pathList重新构造新的报告输出内容,然后在用seek(0)来控制文件指针整体覆盖写入新文件(这样可以避免重复打开文件和关闭文件,比用with open上下文管理来说是有优势的),来实现动态存储输出结果
0x3分析Watchdog
下载地址:Watchdog
按照作者的思路,部署分布式的步骤是:
主节点部署:web+数据库
子节点通过修改:
database.py 中的
engine = create_engine('postgresql://postgres:[email protected]/src')为主节点的数据库,然后分别在各个子节点,运行client目录下的xxx_run.py脚本:
client
├── __init__.py
├── database.py
├── portscan
│ ├── NmapScan.py
│ ├── ShodanScan.py
│ ├── __init__.py
│ └── portscan_run.py //这个启动是端口扫描
├── subdomain
│ ├── __init__.py
│ └── oneforall //这个是
├── urlscan
│ ├── __init__.py
│ ├── url_probe
│ └── xray
└── webinfo
├── __init__.py
├── ipdata.ipdb
├── run.py
└── wafw00f
不难发现,各个脚本都是用While True:来实现持久运行,这里挑选两个模块来分析一下。
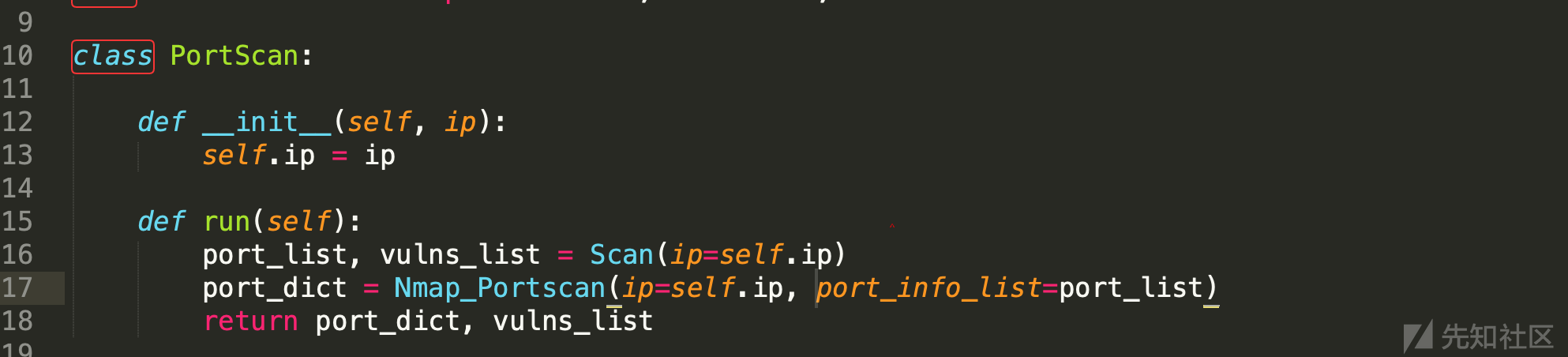
0x3.1 端口扫描模块
def main(): print('[+]端口扫描启动') while True: #从数据库获取资产 assets_sql = ReadAssets() if not assets_sql: time.sleep(30) else: # 传入资产的ip值给PortScan portscan = PortScan(assets_sql.asset_ip) # 执行 port_dict, vulns_list = portscan.run() if port_dict: # 写入结果到数据库 WritePosts(port_dict, assets_sql)
(1)获取待扫描的资产信息:

(2)将IP传入PortScan,初始化,然后执行Run

这个功能代码实现的很粗糙,就是通过shodan获取到开放的端口,然后在调用Nmap去扫描获取服务指纹。
(3)提交数据库部分:

没什么好讲的。
0x3.2 Xray扫描模块
(1) main 部分:

首先用一个子线程启动了web_main,主要作用是开了个webhook的API用来将xray的结果写入到数据库。
@app.route('/webhook', methods=['POST'])
def xray_webhook():接着下面同样开了一个子线程xray_main启动xray扫描器,

结果传送到前面的webhookAPI,开了个子进程去运行xray。
(3)启动crawlergo_main爬虫部分:

这里作者用了进程池(emm,感觉用的混乱),不过这里还判断了下Xray的队列大小来决定是否启动爬虫,来折中因为爬虫大量写入xray的队列的问题,不过这种控制还是不够细腻的,为了code的方便,这样写无可厚非。

这里作者将爬虫返回的新的子域名列表又重新添加到了资产中,并且在写入的数据库的时候做了去重判断。
0x3.3 简单分析
不难看出来,该系统实现的分布式的细粒度就是: (不同目标,多个扫描模块, 多个扫描模块去扫描不同目标)
缺点:
采用postgresql作为后端数据库,缺乏高性能,整个系统的读写和写入次数与细粒度的复杂度是同级别的,
缺乏调度系统,完全就是竞争模式去抢占目标,内耗程度比较高(容易导致数据库连接数过多数据丢失等情况),缺乏高可用性,系统整体应该是低效、混乱的。
PS.笔者没有搭建去测试,静态分析的代码,推测的结果
还有代码复用程度有点低, emm, 代码风格蛮萌新的,其实可以还可以继续封装一下。
缺乏节点管控模块, 缺乏异常的具体处理...
...
优点:
作为一款即兴开发的非专业程序员,通过比较暴力的方式联动了多个扫描工具,同时具备良好的界面效果和一定的可用性的"分布式"扫描器来说,Watchdog可以说是满足基本要求的,同时一款新生项目是不断成长的,需要给作者时间去慢慢改进,造福我们白嫖党ing。
0x4 分析w11scan
0x4.1 简单介绍
根据作者的安装文档和描述,应用到了celery分布式框架,然后数据缓冲采用了redis,数据存储使用了mongodb数据库。
这个架构我是觉得很不错的,系统的主要任务是识别给定url的指纹,所以核心功能部分作者的代码量是比较少的,系统的亮点应该是分布式的处理部分, 即celery的使用部分可以值得我们去学习,(PS.前端也很赏心悦目呀,够简洁,够有趣)
先看下整体目录结构:
├── Dockerfile
├── LICENSE
├── README.md
├── __init__.py
├── app
├── backup
├── celery_config.py
├── cms
├── config.py
├── dockerconf
├── docs
├── manage.py
├── requirements.txt
├── static
├── templates
├── test.py
├── whatcms.py
└── xun0x4.2 分析流程
下面的分析流程,我并没有去调试代码,而是根据docker搭建好系统,根据功能点去确定入口,然后逐步跟就行。
先看下启动该系统时产生的进程:

可以看到分别启动了redis和mogond数据库,然后启动了很多whatcms的celery的work进程

感觉这种启动子进程方式不是很优雅,我可能会考虑用supervisord来进行worker进程的管理

这里是新建一个任务,我们抓包分析出静态代码所对应的地方。
w11scan/app/views.py 163行

将任务插入到数据库,后台其实在工作的,主要是上面的一条语句调用子worker节点来工作:
from cms.tasks import buildPayload ... buildPayload.delay(item, str(insertid))
worker部分如下:

可以看到导入了cms.tasks模块,cms/tasks.py,装饰器有三个函数otherscan、buildPayload、singscan:

可以看到流程就是:前端提交任务->调用work执行buildPayload->构造指纹规则fuzz请求->输出结果到mongodb数据库。
这里作者有个有意思的地方,就是用了redis来作为缓存存储了url的状态
这样的好处是,如果是相同目标的话,这样不会进行重复的同时扫描(保证即时性)
但是等整个状态扫描完成时,redis会删除这个标志,所以可以再次扫描(可用即时性)
0x4.3 简析优缺点
不足:
1.虚假的节点利用率(这让我怎么抄作业? 脚本小子第一个不服)

2.缺乏简易安装的节点安装功能,考虑设置好mongodb的权限为只读,防止子节点控制核心数据库,这个设计需要考量安全性。
3.celery天然支持优先级调度,这个工具不支持,参考 https://www.coder.work/article/372059
4.任务细粒度依然是一个目标->一个worker处理->产生大量的request请求,很容易被BanIP
other issue:https://github.com/w-digital-scanner/w11scan/issues
优点:
代码写的很规范, 注释也很清晰, 整体架构也简单,让人很容易读懂整个程序,不至于出现一些比较低级的语句(给人胶水的感觉)。
没有复杂的大型结构, 非常适合新手作为入门工具去学习分布式。
使用了优秀的celery框架, 处理了繁琐的信息交互(下发任务,竞争处理...),提高了整体的稳定性。
0x5 分析reNgine
这个工具属于的设计思想虽然并不少见, 但是能维护好一个类似pipe line的功能,而且提供了
官方文档:https://rengine.wiki/, 一键化,定时维护,定时更新,有自己的社区,我认为是一个成功吃螃蟹的作品。
虽然这个工具并没有说明自己具备分布式能力,但是从它的设计上来看,就是采用了celery框架来写的实现的单机分布式,改改就能变成真正意义上的分布式了。
下面是笔者对该工具的分析过程。
目录结构:
├── CHANGELOG.md
├── CONTRIBUTORS.md
├── Dockerfile
├── LICENSE
├── Makefile
├── README.md
├── _config.yml
├── certs
│ ├── Dockerfile
│ └── entrypoint.sh
├── config
│ └── nginx
├── dashboard
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── templates
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── docker-compose.dev.yml
├── docker-compose.setup.yml
├── docker-compose.yml
├── docker-entrypoint.sh
├── fixtures
│ └── default_scan_engines.yaml
├── make.bat
├── manage.py
├── notification
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── forms.py
│ ├── migrations
│ ├── models.py
│ ├── static
│ ├── templates
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── reNgine
│ ├── __init__.py
│ ├── celery.py
│ ├── definitions.py
│ ├── init.py
│ ├── settings.py
│ ├── tasks.py
│ ├── urls.py
│ ├── validators.py
│ └── wsgi.py
├── requirements.txt
├── scanEngine
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── forms.py
│ ├── migrations
│ ├── models.py
│ ├── static
│ ├── templates
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── secret
├── secrets
│ └── certs
├── startScan
│ ├── __init__.py
│ ├── admin.py
│ ├── api
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── static
│ ├── templates
│ ├── templatetags
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── static
│ ├── assets
│ ├── bootstrap
│ ├── custom
│ ├── img
│ └── plugins
├── staticfiles
├── targetApp
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── forms.py
│ ├── migrations
│ ├── models.py
│ ├── static
│ ├── templates
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── templates
│ └── base
└── tools
├── OneForAll
├── Sublist3r
├── amass
├── aquatone
├── config
├── default_settings.yaml
├── dirsearch
├── get_dirs.sh
├── get_urls.sh
├── massdns
├── scan_results
├── subjack_fingerprint.json
├── takeover.sh
└── wordlist这里其实目录结构不是很复杂,前端的一个大功能其实就是对应了一个文件夹。
我关注的主要是带有scan字样的文件夹。
0x5.1 分析流程
startScan/views.py 91line:
start_scan_ui扫描开始

我们这里跟进doScan函数,这里代码很长,分块来分析:

接着解析yaml的配置,来加载对应的工具,挺暴力的。
比如下面这个子域名扫描模块部分中代码中调用amass工具:

加载对应工具,让其自身输出结果文件到结果文件夹。

这个else设计导致了没办法复用之前的域名扫描结果了。
这里主要联系是根据taskid来的而不是根据domain来的,也就是说,你不能执行完一个task之后,在执行其他扫描,复用这个task,要么你必须一个task包括你想要两个task完成的功能
要不然你在插入的数据库的时候就会导致因为缺乏对应的字段导致失败的
获取子域名存储完之后,httpx读取获取到的子域名txt进行存活性判断。

接着就是截图之类的...完成了subdomain的模块,如果我们还同时选中了目录扫描模块的话。

最终扫描完成走到最后:

0x5.2 实现扫描进度
这个工具前端能够实时展示当前的扫描进度,我当时写的x7scan为了写这个进度可是折腾了好久,所以这里分出来一节,用来学习别人是怎么实现更新进度的。

根据状态应用不同的button样式。

可以看到这里的进度的动态显示,主要就是利用
{% widthratio scan_history.scanactivity_set.all|length scan_history.scan_type.get_number_ofs_steps|add:4 100 %}django的模本运算,扫描的结果集长度/(步骤+4) *100 得到当前的进步
scan_history.scanactivity_set.all反向查询获取scanactivity的条数


程序的话,默认会创建4个属于表示状态的Activity,这就是为什么+4。




步骤其实就是扫描器的核心5个调用功能点:

0x5.3 优缺点分析
由于笔者对django一窍不通,所以很多代码欣赏不来, 整个项目的变量统一采用蛇形格式, 但注释比较少,笔者读起来还是非常吃力,而且这种celery的框架要是想调试也很麻烦,所以这里不对代码作评价。
作为一个用户的角度来简单说说:
缺点:
比较明显一点就是结果不能复用,还有就是如果同时有太多扫描(产生大量子域名),文件读取(txt)也就是读写I/O会占用非常多的内存,系统很容易出现崩溃的情况,还有就是细粒度还是比较大的问题(它本来就不是分布式扫描工具,没必要苛求这个,但是想提高速度的话,可以自己多开一个worker docker,数目和你CPU差不多就行了)
还有很多issue(xss漏洞之类的):https://github.com/yogeshojha/rengine/issues
...
优点:
界面写的很用心,系统调低线程的话整体运行还是很稳定的,再者有人不断维护,会越来越优秀的。
还有支持yaml配置各个tools的具体参数配置,看作者写的代码,可以看出来作者写的蛮疲惫的。
...
0x6 总结与展望
本文简单地分析了几款的主流工具的工作流程,明白了工具作者的基本思想,其实与我心目中架构的思想还是不太一致的,特别是细粒度这一方面,我会针对细粒度的划分做一些性能的小测试。
保佑自己毕设在开始code之前,能够把这个小工具作为前胃菜完结吧,真的是太忙了Orz.
0x7 参考链接
如有侵权请联系:admin#unsafe.sh