Fortify是一款商业级的源码扫描工具,其工作原理和codeql类似,甚至一些规则编写的语法都很相似,其工作示意图如下:

首先Fortify对源码进行分析(需要编译),然后提取出相关信息保存到某个位置,然后加载规则进行扫描,扫描的结果保存为 .fpr 文件,然后用户使用 GUI 程序对结果进行分析,排查漏洞。
本文的分析方式是在 Linux 上对源码进行编译、扫描,然后在 Windows 平台对扫描结果进行分析,所以涉及 Windows 和 Linux 两个平台的环境搭建。
Windows搭建
首先双击 Fortify_SCA_and_Apps_20.1.1_windows_x64.exe 安装

安装完成后,把 fortify-common-20.1.1.0007.jar 拷贝 Core\lib 进行破解,然后需要把 rules 目录的规则文件拷贝到安装目录下的 Core\config\rules 的路径下,该路径下保存的是Fortify的默认规则库。

ExternalMetadata 下的文件也拷贝到 Core\config\ExternalMetadata 目录即可
最后执行 auditworkbench.cmd 即可进入分析源码扫描结果的IDE.

Linux搭建
解压下载的压缩包,然后执行 ./Fortify_SCA_and_Apps_19.2.1_linux_x64.run 按照引导完成安装即可,安装完成后进入目录执行sourceanalyzer来查看是否安装完成
$ ./bin/sourceanalyzer -version
Fortify Static Code Analyzer 19.2.1.0008 (using JRE 1.8.0_181)然后将 rules 和 ExternalMetadata 拷贝到对应的目录中完成规则的安装。
本节涉及代码
https://github.com/hac425xxx/sca-workshop/tree/master/fortify-exampleFortify的工作原理和codeql类似,首先会需要使用Fortify对目标源码进行分析提取源代码中的信息,然后使用规则从源码信息中查询出匹配的代码。
首先下载代码然后使用 sourceanalyzer 来分析源码
/home/hac425/sca/fortify/bin/sourceanalyzer -b fortify-example make其中
-b指定这次分析的id- 后面是编译代码时使用的命令,这里是
make
分析完代码后再次执行 sourceanalyzer 对源码进行扫描
/home/hac425/sca/fortify/bin/sourceanalyzer -b fortify-example -scan -f fortify-example.fpr其中
-b指定扫描的id和之前分析源码时的id对应-scan表示这次是采用规则对源码进行扫描-f指定扫描结果输出路径,扫描结果可以使用auditworkbench.cmd进行可视化的分析。

生成 .fpr 结果后可以使用 auditworkbench 加载分析

本节涉及代码
https://github.com/hac425xxx/sca-workshop/tree/master/fortify-example/system_rules漏洞代码如下
int call_system_example()
{
char *user = get_user_input_str();
char *xx = user;
system(xx);
return 1;
}首先通过 get_user_input_str 获取外部输入, 然后传入 system 执行。
下面介绍如何编写 Fortify 规则来识别这个漏洞, 规则文件是一个xml文件,其主要结构如下
<?xml version="1.0" encoding="UTF-8"?>
<RulePack xmlns="xmlns://www.fortifysoftware.com/schema/rules">
<RulePackID>EA6AEBB1-F11A-44AD-B5DD-F4F66907184E</RulePackID>
<Version>1.0</Version>
<Description><![CDATA[]]></Description>
<Rules version="20.1">
<RuleDefinitions>
<DataflowSourceRule formatVersion="3.2" language="cpp">
....
</DataflowSourceRule>
</RuleDefinitions>
</Rules>
</RulePack>RulePackID表示这个规则文件的 ID, 设置符合格式的唯一字符串即可RuleDefinitions里面是这个xml文件中的所有规则,每个规则作为RuleDefinitions的子节点存在,比如示例中的DataflowSourceRule节点,表示这是一个DataflowSource规则,用于指定数据流跟踪的source
我们开发规则实际也只需要在 RuleDefinitions 中新增对应的规则节点即可。
Fortify 也支持污点跟踪功能,下面就介绍如何定义 Fortify 的污点跟踪规则,首先我们需要定义 source ,DataflowSourceRule 规则用于定义污点源,不过这个只支持定义函数的一些属性作为污点源,比如返回值、参数等,代码如下
<DataflowSourceRule formatVersion="3.2" language="cpp">
<RuleID>AEFA1FBF-3137-4DD8-A65F-774350C97427</RuleID>
<FunctionIdentifier>
<FunctionName>
<Value>get_user_input_str</Value>
</FunctionName>
</FunctionIdentifier>
<OutArguments>return</OutArguments>
</DataflowSourceRule>这条规则的作用是告知Fortify的数据流分析引擎 get_user_input_str 的返回值是污点数据,规则的解释如下:
- 首先
RuleID用于唯一标识一条规则 FunctionIdentifier用于匹配一个函数, 其中包含一个FunctionName子节点,表示通过函数名进行匹配,这里就是匹配get_user_input_str函数- 然后
OutArguments用于定义污点源,return表示该函数的返回值是污点数据,如果该节点的值为数字n, 则表示第n个参数为污点数据,n从0开始计数。
定义好 source 点后,还需要定义 sink 点,DataflowSinkRule 规则用于定义 sink 点
<DataflowSinkRule formatVersion="3.2" language="cpp">
<RuleID>AA212456-92CD-48E0-A5D5-E74CC26ADDF</RuleID>
<Description><![CDATA[]]></Description>
<VulnCategory>Command Injection</VulnCategory>
<DefaultSeverity>4.0</DefaultSeverity>
<Sink>
<InArguments>0</InArguments>
</Sink>
<FunctionIdentifier>
<FunctionName>
<Value>system</Value>
</FunctionName>
</FunctionIdentifier>
</DataflowSinkRule>这条规则的作用是设置 system 的第 0 个参数为 sink 点,规则解释如下:
VulnCategory是一个字符串,会在扫描结果中呈现FunctionIdentifier用于匹配一个函数,这里就是匹配system函数Sink和InArguments用于表示函数的第0个参数为sink点
规则编写完后,保存成一个 xml 文件,然后在对源码进行扫描时通过 -rules 指定自定义的规则文件即可
/home/hac425/sca/fortify/bin/sourceanalyzer -rules system.xml -b fortify-example -scan -f fortify-example.fpr -no-default-rulesps: -no-default-rules 表示不使用Fortify的默认规则,这里主要是在自己开发规则时避免干扰。
扫描的结果如下

由于我们没有考虑 clean_data 函数对外部输入的过滤,所以会导致误报
int call_system_safe_example()
{
char *user = get_user_input_str();
char *xx = user;
if (!clean_data(xx))
return 1;
system(xx);
return 1;
}可以使用 DataflowCleanseRule 规则来定义这类会对输入进行过滤的函数
<DataflowCleanseRule formatVersion="3.2" language="cpp">
<RuleID>3EC057A4-AE7A-42C4-BAA0-3ACB36C8AB4B</RuleID>
<FunctionIdentifier>
<FunctionName>
<Value>clean_data</Value>
</FunctionName>
</FunctionIdentifier>
<OutArguments>0</OutArguments>
</DataflowCleanseRule>规则表示 clean_data 函数执行后其第 0 个参数就是干净的(不再是污点值),此时就可以把外部数据被过滤的场景从查询结果中剔除掉了。
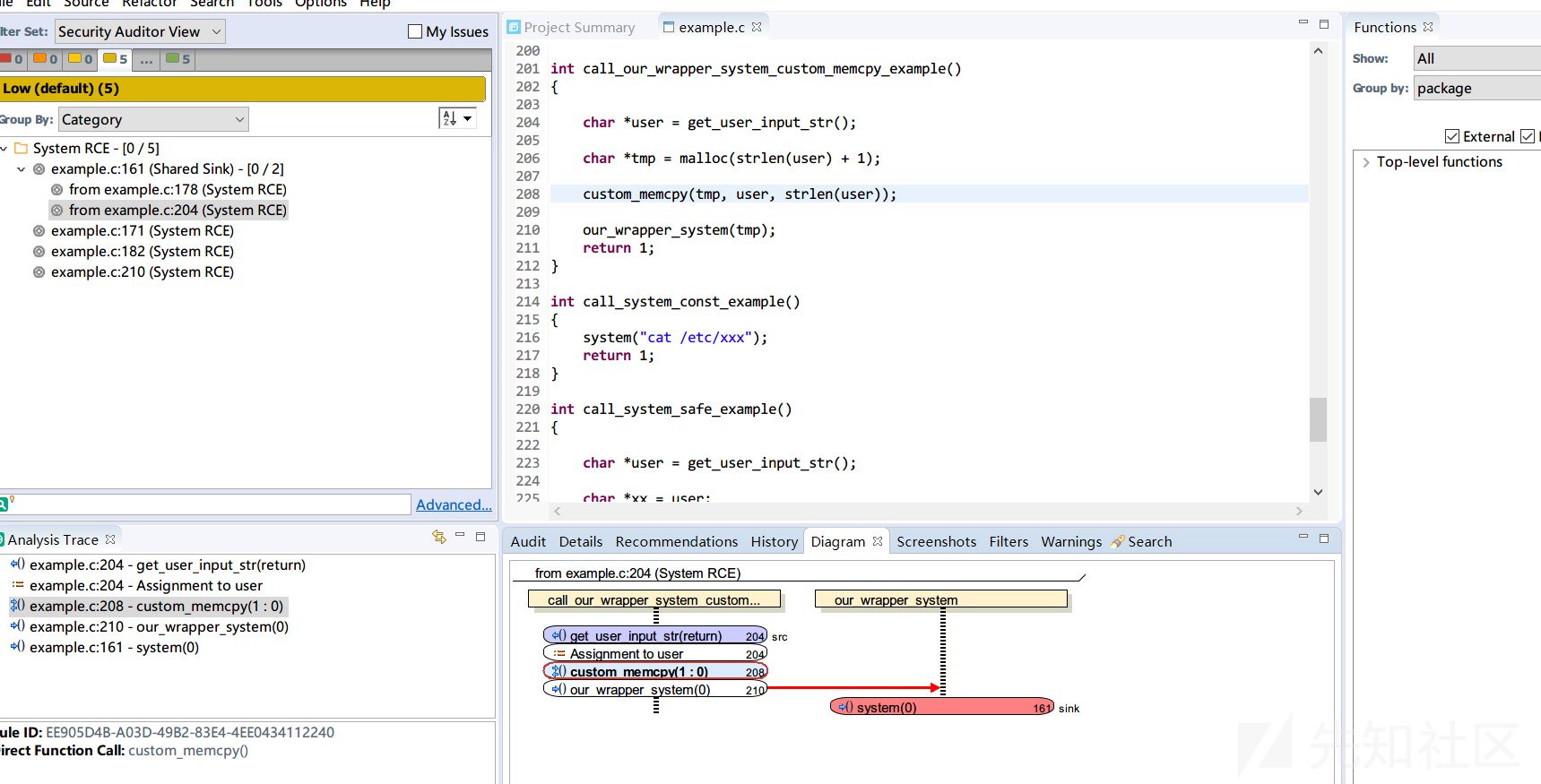
此时的扫描还会漏报 call_our_wrapper_system_custom_memcpy_example ,因为其中使用了custom_memcpy这个外部函数来进行内存拷贝,这样Fortify在进行污点跟踪的时候就会导致污点数据丢失,从而漏报。
int custom_memcpy(char *dst, char *src, int sz);
int call_our_wrapper_system_custom_memcpy_example()
{
char *user = get_user_input_str();
char *tmp = malloc(strlen(user) + 1);
custom_memcpy(tmp, user, strlen(user));
our_wrapper_system(tmp);
return 1;
}我们可以使用 DataflowPassthroughRule 规则来对这个函数进行建模
<DataflowPassthroughRule formatVersion="3.2" language="cpp">
<RuleID>C929ED5F-9E6A-4CB5-B8AE-AAAAD3C20BDC</RuleID>
<FunctionIdentifier>
<FunctionName>
<Pattern>custom_memcpy</Pattern>
</FunctionName>
</FunctionIdentifier>
<InArguments>1</InArguments>
<OutArguments>0</OutArguments>
</DataflowPassthroughRule>规则作用是告知 Fortify 调用 custom_memcpy 函数时,第 1 个参数的污点数据会传播到第 0 个参数,结果如下

除了使用 DataflowSourceRule 、DataflowSinkRule 等规则来定义污点跟踪相关的属性外,Fortify还支持使用 CharacterizationRule 来定义污点跟踪相关的特性。
其中对应关系如下图所示:

根据文档的使用示例,修修改改很快就可以使用 CharacterizationRule 来搜索出涉及 system 命令执行的代码,代码路径如下
https://github.com/hac425xxx/sca-workshop/blob/master/fortify-example/system_rules/system_CharacterizationRule.xml介绍具体的 CharacterizationRule 规则实现之前,先介绍一下 StructuralRule 规则,因为 CharacterizationRule 就是通过 StructuralRule 的语法来匹配代码中的语法结构。
StructuralRule 官方文档中的内容如下
The Structural Analyzer operates on a model of the program source code called the structural tree. The structural tree is made up of a set of nodes that represent program constructs such as classes, functions, fields, code blocks, statements, and expressions.Fortify在编译/分析代码过程中会把代码中的元素(代码块、类、表达式、语句等)通过树状结构体组装起来形成一颗 structural tree,然后扫描的时候使用 Structural Analyzer 来解析 StructuralRule ,最后输出匹配的代码。
下面以一个简单的示例看看 structural tree 的结构,示例代码如下
class C {
private int f;
void func() {
}
}代码对应的树结构如下

搜索上述代码的 StructuralRule 的代码如下
Field field: field.name == "f" and field.enclosingClass is [Class class: class.name == "C"]其中 Field field: 类似于声明变量, : 后面试前面变量需要满足的条件,比如
field.name == "f"这个就表示 field 的 name 为 f ,规则后续使用 and 表示与条件,然后通过 field.enclosingClass 获取到这个字段位于的class,[...] 类似于定义一个变量,其返回值为满足条件的对象
[Class class: class.name == "C"]上面的语句表示 [] 会返回 类名为 C 的 Class 对象
field.enclosingClass is [Class class: class.name == "C"]这条语句的作用就是限制 field 所在的类的类名为 C ,其实 StructuralRule 的作用和使用方式和Codeql非常相似,主要就是利用逻辑表达式(and, or...)来匹配代码的特定元素。
下面介绍CharacterizationRule的使用,首先定义 source 点
<CharacterizationRule formatVersion="19.10" language="cpp">
<RuleID>EE5D-4B1D-A798-4D1B5E081112</RuleID>
<StructuralMatch>
<![CDATA[
FunctionCall fc:
fc.name contains "get_user_input_str"
]]>
</StructuralMatch>
<Definition>
<![CDATA[
TaintSource(fc, {+PRIVATE})
]]>
</Definition>
</CharacterizationRule>其中 StructuralMatch 使用 StructuralRule 的语法来匹配代码,然后在 Definition 里面可以使用一些API(比如TaintSource)和匹配到的代码元素来标记污点跟踪相关的熟悉,比如污点源、Sink点等,这里要注意一点:Definition 中可以访问到 StructuralMatch 中声明的所有变量,不论是通过 : 还是通过 [] 声明。
上述规则的作用就是
- 首先通过 StructuralMatch 匹配到 get_user_input_str 的函数调用对象 fc.
- 然后在 Definition ,使用 TaintSource 设置 fc 为污点源,污点标记为 PRIVATE.
sink 点的设置
<CharacterizationRule formatVersion="3.12" language="cpp">
<RuleID>EE905D4B-A03D-49B2-83E4-4EE043411223</RuleID>
<VulnKingdom>Input Validation and Representation</VulnKingdom>
<VulnCategory>System RCE</VulnCategory>
<DefaultSeverity>4.0</DefaultSeverity>
<Description><![CDATA[]]></Description>
<StructuralMatch>
<![CDATA[
FunctionCall fc:
fc.name contains "system" and fc.arguments[0] is [Expression e:]
]]>
</StructuralMatch>
<Definition>
<![CDATA[
TaintSink(e, [PRIVATE])
]]>
</Definition>
</CharacterizationRule>规则解释如下:
- 首先使用
StructuralMatch匹配fc为system的函数调用,e为fc的第0个参数 - 然后在
Definition使用TaintSink设置e为sink点,污点标记为PRIVATE.
这样就表示如果 system 函数调用的第 0 个参数为污点数据且污点数据中包含 PRIVATE 标记,就会把这段代码爆出来。
其他的规则(函数建模,clean_data函数)也是类似这里不再介绍,最终扫描结果如下图:

在开发 Structural相关规则时可以在分析时使用 -Ddebug.dump-structural-tree 把代码的 structural tree 打印出来,然后我们根据树的结构就可以比较方便的开发规则,完整命令行如下
/home/hac425/sca/fortify/bin/sourceanalyzer -no-default-rules -rules hello_array.xml -b fortify-example -scan -f fortify-example.fpr -D com.fortify.sca.MultithreadedAnalysis=false -Ddebug.dump-structural-tree 2> tree.tree打印出来的示例如下

根据树状结构就可以写出匹配 global_array[user] 的代码如下:
ArrayAccess aa: aa.index is [VariableAccess va:va.name == "user"]本节相关代码
https://github.com/hac425xxx/sca-workshop/blob/master/fortify-example/ref_rules/漏洞代码
int ref_leak(int *ref, int a, int b)
{
ref_get(ref);
if (a == 2)
{
puts("error 2");
return -1;
}
ref_put(ref);
return 0;
}
int ref_dec_error(int *ref, int a, int b)
{
ref_get(ref);
if (a == 2)
{
puts("ref_dec_error 2");
ref_put(ref);
}
ref_put(ref);
return 0;
}ref_leak 的 漏洞是当 a=2 时会直接返回没有调用 ref_put 对引用计数减一,漏洞模型:在某些存在 return的条件分支中没有调用 ref_put 释放引用计数。
ref_dec_error 的漏洞是在特定条件下会对引用计数减多次。
这种类型漏洞适合使用 ControlflowRule 来查询对应的漏洞,对于规则如下
<ControlflowRule formatVersion="3.4" language="cpp">
<RuleID>1650899A-908F-4301-B67A-D08E8E331122</RuleID>
<VulnKingdom>API Abuse</VulnKingdom>
<VulnCategory>Ref Leak</VulnCategory>
<DefaultSeverity>3.0</DefaultSeverity>
<Description><![CDATA[]]></Description>
<FunctionIdentifier id="ref_put">
<FunctionName>
<Pattern>ref_put</Pattern>
</FunctionName>
</FunctionIdentifier>
<FunctionIdentifier id="ref_get">
<FunctionName>
<Pattern>ref_get</Pattern>
</FunctionName>
</FunctionIdentifier>
<PrimaryState>ref_add</PrimaryState>
<Definition>
<![CDATA[
state start (start);
state ref_add;
state ref_dec;
state no_leak;
state checked;
state leak (error) : "ref.leak";
state double_dec (error): "ref dec 2";
var p;
start -> ref_add { $ref_get(p) }
ref_add -> ref_dec { $ref_put(p) }
ref_dec -> double_dec { $ref_put(p) }
ref_dec -> checked { #return() }
ref_add -> leak { #return() }
]]>
</Definition>
</ControlflowRule>首先 FunctionIdentifier 匹配 ref_put 和 ref_get 两个函数,然后通过 Definition 定义规则
state start (start);
state ref_add;
state ref_dec;
state no_leak;
state checked;
state leak (error) : "ref.leak";
state double_dec (error): "ref dec 2";
var p;
start -> ref_add { $ref_get(p) }
ref_add -> ref_dec { $ref_put(p) }
ref_dec -> double_dec { $ref_put(p) }
ref_dec -> checked { #return() }
ref_add -> leak { #return() }规则的解释如下:
- 首先通过
state xxx定义一些状态,其中(start)表示状态时初始状态,(error)表示对应状态为错误状态,只要代码进入了错误状态就会在扫描结果中呈现,var用于定义一个临时变量。 - 在规则中使用
$func_id来引用之前使用FunctionIdentifier匹配到的函数。 start -> ref_add { $ref_get(p) }表示从 start 状态 进入 ref_add 状态的条件是调用了 ref_get 函数,入参为 pref_add -> leak { #return() }表示从ref_add状态 进入leak状态的条件是函数直接return返回了。ref_add -> ref_dec { $ref_put(p) }表示代码在ref_add状态情况下对p调用了ref_put后就会进入ref_dec,即对引用计数减1.- 如果在
ref_dec状态从函数返回,就表示函数没有问题。 - 如果在
ref_dec状态下再次调用ref_put(p)则会进入double_dec,会在扫描结果中呈现。
Fortify自带的规则是加密过的的,我们可以根据已有的一些研究对其解密,然后参考官方的规则来开发新的规则
https://www.52pojie.cn/thread-783946-1-1.html可以查看 fortify-sca-20.1.1.0007.jar 里面的 com.fortify.sca.nst.nodes 包里面的类,这些类表示的是fortify语法树的各个节点,可以通过对应类的方法知道在结构化规则中可以访问的方法和函数。

Fortify相比codeql的优势在于:
- 商用工具,拥有许多预设规则,比较成熟。
- 规则开发模式比较局限,但是对于某些特定场景的规则开发相对简单。
- 适合大规模规则的扫描。
codeql 的语法非常灵活,可以灵活运用匹配出各种代码片段,支持对大部分语法元素应用污点分析,比如支持设置数组索引位置为Sink点,经过各种尝试,发现fortify不支持。
https://bbs.huaweicloud.com/blogs/104311
https://tech.esvali.com/mf_manuals/html/sca_ssc/
https://paper.seebug.org/papers/old_sebug_paper/books/Fortify/rules-schema/
如有侵权请联系:admin#unsafe.sh