前言
本文介绍逆向DA14531芯片的固件,并介绍一些辅助自动化分析的脚本的实现。DA14531是Dialog公司研制的蓝牙芯片,用户可以在官网下载SDK来开发蓝牙的上层业务。
相关代码
https://github.com/hac425xxx/BLE-DA145XX/
ps: 文件全部发出后公开github项目SDK环境搭建和IDA加载固件
下载SDK后,进入其中一个示例项目
DA145xx_SDK\6.0.14.1114\projects\target_apps\ble_examples\ble_app_profile\Keil_5使用Keil打开,然后选择 Project->Manage->Component,设置目标为DA14531.

然后编译之后就会下面的目录生成编译好的固件
DA145xx_SDK\6.0.14.1114\projects\target_apps\ble_examples\ble_app_profile\Keil_5\out_DA14531\Objects其中比较关键的几个文件有
ble_app_profile_531.axf: 工程文件编译为ELF文件
ble_app_profile_531.bin: 可以直接刷入系统RAM的二进制
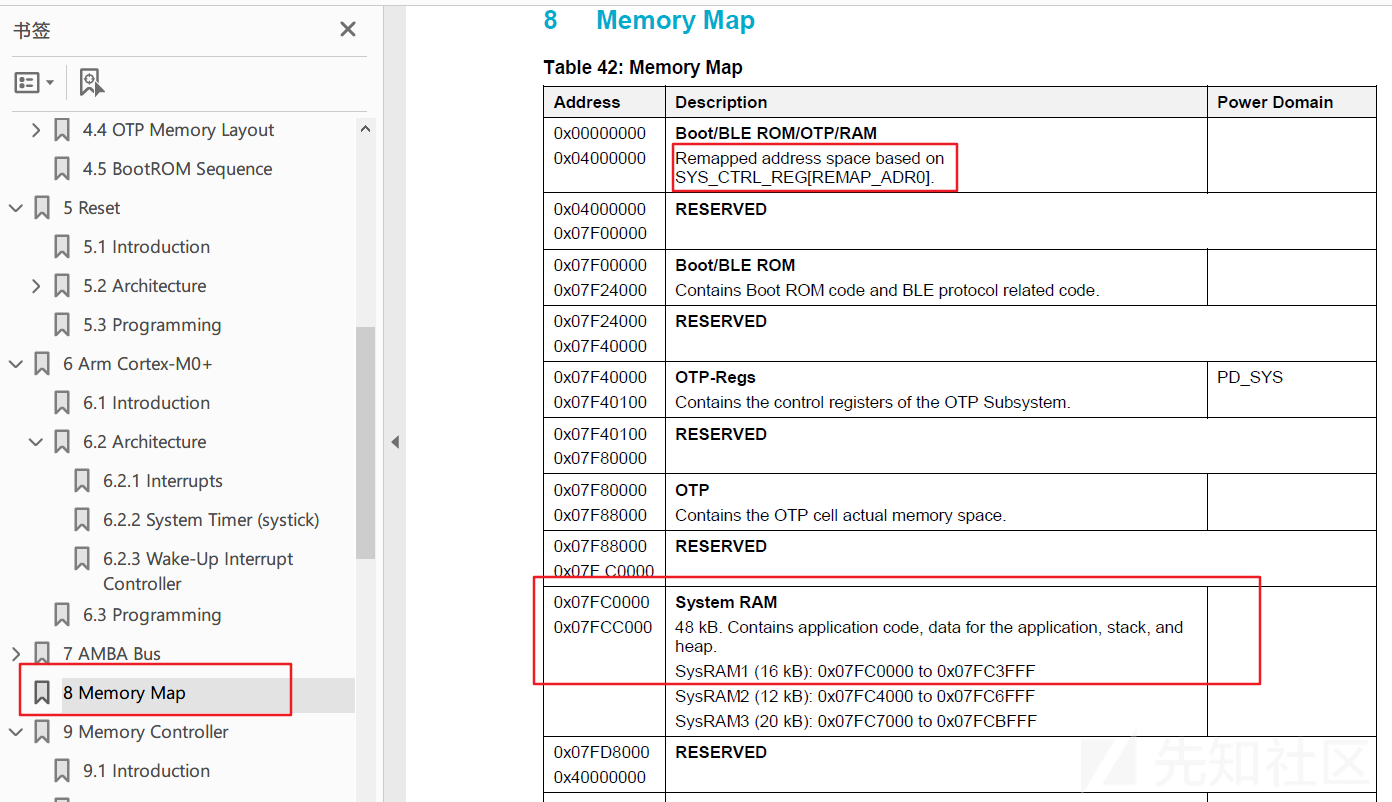
ble_app_profile_531.hex: hex文件格式,相比.bin文件该文件中带有刷入的地址其中 .axf 其实就是ELF文件,里面有符号信息和加载基地址等,.bin文件可以直接写入到芯片的固定地址,查看芯片手册中的Memory Map部分

可以猜测.bin文件的基地址为0x7fc0000,这点也可以通过用IDA分析.axf 文件得到证明,下面为了简化分析流程,直接用IDA分析ble_app_profile_531.axf.
随便打开一些函数分析,发现有的函数会直接将某些没有加载到内存的地址作为函数进行调用,比如
int __fastcall gattc_write_req_ind_handler()
{
v6 = MEMORY[0x7F22448](param->handle, att_idx); // 将 0x7F22448 作为函数进行调用查看芯片手册可以知道这块地址的描述为
Boot/BLE ROM
Contains Boot ROM code and BLE protocol related code.可以知道这块内存里面应该有一些协议栈底层的代码,而且翻看SDK的代码发现很多系统的函数都没有源码,在编译出来后的二进制里面也没有对应函数的实现,猜测这部分函数的实现也在这个区域中。
最后让群友帮忙在开发板里面用jtag把这块内存dump了下来,然后咱们加载到IDA中
File -> Load file -> Additional binary file选择dump出来的二进制文件,然后设置加载地址为 0x7fc0000 。

加载完后,这些函数调用就可以正常识别了。
加载函数符号
对部分函数分析一段时间后,在搜索SDK的时候,忽然发现了一个比较神奇的文件
da14531_symbols.txt文件的部分内容如下
0x07f2270b T custs1_set_ccc_value
0x07f22823 T gattc_cmp_evt_handler
0x07f22837 T custs1_val_set_req_handler
0x07f22857 T custs1_val_ntf_req_handler
0x07f228b3 T custs1_val_ind_req_handler
0x07f2290f T custs1_att_info_rsp_handler
0x07f2294b T gattc_read_req_ind_handler
0x07f22b57 T gattc_att_info_req_ind_handler
0x07f22b99 T custs1_value_req_rsp_handler看起来好像是一个列是符号内存地址,第三列是符号名,后面去网上搜索这个文件的作用,发现是keil支持的一种输入文件,用于在链接的时候把符号引用替换为对应的内存地址地址,这样在固件运行时就可以正常调用函数,这样也可以让一部分代码不开源。
最后写了个idapython脚本加载这个符号文件
import idaapi
import idc
fpath = "da14531_symbols.txt"
def define_func(addr, name):
if addr & 1:
addr -= 1
idaapi.split_sreg_range(addr, idaapi.str2reg("T"), 1, idaapi.SR_user)
else:
idaapi.split_sreg_range(addr, idaapi.str2reg("T"), 0, idaapi.SR_user)
if idaapi.create_insn(addr):
idc.add_func(addr)
idaapi.set_name(addr, name,idaapi.SN_FORCE)
def define_data(addr, name):
idaapi.set_name(addr, name,idaapi.SN_FORCE)
with open(fpath, "r") as fp:
for l in fp:
try:
addr, type, name = l.strip().split(" ")
if addr.startswith(";"):
continue
addr = int(addr, 16)
if type == "T":
define_func(addr, name)
else:
define_data(addr, name)
except:
pass- 主要逻辑就是一行一行的处理文件,丢弃
;开头的行 - 然后根据第二列的值来进行对应的处理
- 如果是
T表示这个符号是一个函数地址调用define_func处理,否则就当做变量符号调用define_data处理
主要提一下的就是在处理函数的时候的代码
def define_func(addr, name):
if addr & 1:
addr -= 1
idaapi.split_sreg_range(addr, idaapi.str2reg("T"), 1, idaapi.SR_user)
else:
idaapi.split_sreg_range(addr, idaapi.str2reg("T"), 0, idaapi.SR_user)
if idaapi.create_insn(addr):
idc.add_func(addr)
idaapi.set_name(addr, name,idaapi.SN_FORCE)- 首先需要根据地址的最低位是否为1来判断是否为thumb指令,然后根据情况设置
idaapi.str2reg("T")寄存器的值,IDA会根据这个寄存器的值来判断后面反汇编指令时采用的是thumb指令还是arm指令 - 然后调用
idaapi.create_insn让ida从函数地址处开始进行反汇编并创建指令 - 指令创建成功之后就调用
idc.add_func创建一个函数并使用idaapi.set_name设置函数的名称
执行脚本后很多的系统函数都识别出来了。
操作系统任务识别
创建任务API分析
分析嵌入式系统,首先需要将系统中存在的task/进程识别出来,经过一番的资料查找和SDK学习,可以知道DA145x芯片中的操作系统为Riviera Waves实时系统,该系统使用用ke_task_create来创建一个任务,从SDK中可以获取函数的定义如下
/**
****************************************************************************************
* @brief Create a task.
*
* @param[in] task_type Task type.
* @param[in] p_task_desc Pointer to task descriptor.
*
* @return Status
****************************************************************************************
*/
uint8_t ke_task_create(uint8_t task_type, struct ke_task_desc const * p_task_desc);可以看到函数两个参数,第一个表示任务的类型,第二个参数为ke_task_desc结构体指针,表示任务的描述信息。
如果需要识别所有的任务,就可以通过查找 ke_task_create 的交叉引用,然后获取函数调用的两个参数即可拿到任务的类型和对应的任务描述符地址,然后再解析ke_task_desc就可以获取到每个任务的具体信息。
为了自动化的实现该目标,需要一个能在IDA中获取函数调用参数值的脚本,下面首先分析此脚本的实现
函数调用参数识别脚本
脚本地址
https://github.com/hac425xxx/BLE-DA145XX/blob/main/argument_tracker.py参数追踪主要在ArgumentTracker类中实现,脚本实现了两种参数识别的方式分别为基于汇编指令和模拟执行的函数调用参数识别 , 基于IDA伪代码的函数调用参数识别。
下面分别对其实现进行介绍
基于汇编指令和模拟执行的函数调用参数识别
这种方法由 reobjc 脚本演变而来
https://github.com/duo-labs/idapython/blob/master/reobjc.py功能实现于track_register函数,主要思路是:
- 追踪存储函数参数的寄存器/内存地址的使用,做一个类似污点分析的功能,直到找到最初赋值的位置(比如
ldr,mov) - 然后从赋值点开始使用
unicorn模拟执行,一直执行到函数调用的位置 - 然后从
unicorn获取此时的对应寄存器和内存的值就可以得到具体的函数参数值
示例:
rom_ble:07F09CC0 LDR R1, =0x7F1F550
rom_ble:07F09CC2 MOVS R0, #0 ; task_type
rom_ble:07F09CC4 ADDS R1, #0x28 ; '(' ; p_task_desc
rom_ble:07F09CC6 BL ke_task_create假设现在需要追踪参数二(即R1)的值,步骤如下:
- 首先从
07F09CC6往前搜索R1的赋值点,发现07F09CC4这里是一条ADD指令不是最初赋值点,继续往上搜索 - 最后找到
07F09CC0这里是LDR指令 - 然后使用
unicron从07F09CC0开始执行,一直执行到07F09CC6即可获取到在调用ke_task_create时参数二(即R1)的值
下面看看关键的代码
while curr_ea != idc.BADADDR:
mnem = idc.print_insn_mnem(curr_ea).lower()
dst = idc.print_operand(curr_ea, 0).lower()
src = idc.print_operand(curr_ea, 1).lower()
if dst == target and self.is_set_argument_instr(mnem):
target = src
target_value = src
target_ea = curr_ea
if target.startswith("="):
break
if dst == target == "r0" and self.is_call_instr(mnem):
previous_call = curr_ea
break
curr_ea = idc.prev_head(curr_ea-1, f_start)主要就是不断调用idc.prev_head往前解析指令,然后对每条指令进行分析,实现一个反向的污点跟踪,直到找到目标的赋值点为止,找到赋值点后就使用Unicorn去模拟执行
基于IDA伪代码的函数调用参数识别
有的时候基于汇编指令向后做跟踪会丢失部分信息,示例:
if(cond1)
{
v4 = 0x101
}
if(cod2)
{
v4 = 0x303;
}
if(cod4)
{
v4 = 0x202;
}
some_func(v4 - 1, 0)对于这样的代码如果直接使用第一种方式实际只会得到 v4 = 0x201,会漏掉两种可能值。
为了缓解这种情况,实现了一个基于IDA伪代码的参数值识别脚本,功能实现于decompile_tracer函数。
其主要思路也是类似,首先定位需要获取的参数,然后提取参数字符串,分别跟踪参数的每个组成部分,找到赋值点,然后求出每个部分的值,从而得到参数的所有取值.
还是以上面的为例,假设需要获取参数1的值,处理流程如下
- 首先提取得到参数1的组成部分为
v4和 1,1为常量,只需要追踪v4 - 然后往上追踪,找到
v4的可能值为0x202,0x303,0x101 - 最后得到
v4 - 1的所有可能值为0x201,0x302,0x100
任务自动化识别
首先找到ke_task_create的交叉引用,然后利用ArgumentTracker中基于汇编的参数获取模式来提取参数的值
def dump_ke_task_create():
retsult = {}
logger = CustomLogger()
m = CodeEmulator()
at = ArgumentTracker()
ke_task_create_addr = idaapi.get_name_ea(idaapi.BADADDR, "ke_task_create")
for xref in XrefsTo(ke_task_create_addr, 0):
frm_func = idc.get_func_name(xref.frm)
ret = at.track_register(xref.frm, "r1")
if ret.has_key("target_ea"):
if m.emulate(ret['target_ea'], xref.frm):
reg = m.mu.reg_read(UC_ARM_REG_R1)
retsult[xref.frm] = reg首先获取ke_task_create的地址,然后查找其交叉引用
- 对于每个交叉引用使用
track_register来追踪r1寄存器(即参数二) ret['target_ea']表示赋值点,然后使用CodeEmulator从赋值点执行到函数调用的位置(xref.frm)- 执行成功后读取
r1的值,即可得到任务描述符的地址
拿到任务描述符的地址后下面需要定义描述符的类型,首先看看ke_task_desc的定义
/// Task descriptor grouping all information required by the kernel for the scheduling.
struct ke_task_desc
{
/// Pointer to the state handler table (one element for each state).
const struct ke_state_handler* state_handler;
/// Pointer to the default state handler (element parsed after the current state).
const struct ke_state_handler* default_handler;
/// Pointer to the state table (one element for each instance).
ke_state_t* state;
/// Maximum number of states in the task.
uint16_t state_max;
/// Maximum index of supported instances of the task.
uint16_t idx_max;
};这里主要关注ke_state_handler,该结构中有一个msg_table,里面是一些函数指针和其对应的消息id
/// Element of a message handler table.
struct ke_msg_handler
{
/// Id of the handled message.
ke_msg_id_t id;
/// Pointer to the handler function for the msgid above.
ke_msg_func_t func;
};
/// Element of a state handler table.
struct ke_state_handler
{
/// Pointer to the message handler table of this state.
const struct ke_msg_handler *msg_table;
/// Number of messages handled in this state.
uint16_t msg_cnt;
};我们也就按照结构体定义使用相应的IDApython的接口即可(注意:使用idapython设置结构体前要确保对应的结构体已经导入到IDB中)
for k, v in retsult.items():
frm_func = idc.get_func_name(k)
task_desc_ea = v
task_desc_name = "{}_task_desc".format(frm_func.split("_init")[0])
define_ke_task_desc(task_desc_ea, task_desc_name)
handler = idaapi.get_dword(task_desc_ea + 4)
define_ke_state_handler(handler)识别消息和回调函数的交叉引用
Riviera Waves系统中任务之间使用消息来传递消息,中断处理程序做了简单处理后就会通过发送消息交给对应的消息处理函数进行处理,常用方式是使用ke_msg_alloc分配消息,然后使用ke_msg_send将消息发送出去。
ke_msg_alloc的定义如下
/**
****************************************************************************************
* @brief Allocate memory for a message
*
* @param[in] id Message identifier
* @param[in] dest_id Destination Task Identifier
* @param[in] src_id Source Task Identifier
* @param[in] param_len Size of the message parameters to be allocated
*
*/
void *ke_msg_alloc(ke_msg_id_t const id, ke_task_id_t const dest_id,
ke_task_id_t const src_id, uint16_t const param_len);其中第一个参数为消息ID,在系统中有很多消息处理回调函数表,回调函数表大体结构都是由消息ID和函数指针组成,在处理消息发送出去后,系统会根据消息中的其他参数(比如dest_id)找到相应的回调函数表,然后根据消息ID去表中找到对应的回调函数,最后调用回调函数处理消息数据。
那我们就可以找到所有ke_msg_alloc的调用点,然后提取出id,就可以知道每个函数使用了哪些消息id,然后根据消息id去二进制里面搜索,找到消息处理函数,最后将两者建立交叉引用,这样在逆向分析的时候就很舒服了。
示例
rom_ble:07F17C4E LDR R0, =0x805 ; id
rom_ble:07F17C50
rom_ble:07F17C50 loc_7F17C50 ; DATA XREF: sub_7F06B94↑r
rom_ble:07F17C50 ; sub_7F0CE30↑r ...
rom_ble:07F17C50 BL ke_msg_alloc建立完交叉引用后在调用ke_msg_alloc的位置,可以看的其事件消息的处理函数可能为sub_7F06B94和sub_7F0CE30。
下面介绍根据消息ID搜索消息处理函数的实现
def search_msg_handler(msg_id):
ret = []
data = " ".join(re.findall(".{2}", struct.pack("H", msg_id).encode("hex")))
addr = 0x07F00000
find_addr = idc.find_binary(addr, SEARCH_DOWN, data)
while find_addr != idaapi.BADADDR:
func_addr = idaapi.get_dword(find_addr + 4)
if is_func_ea(func_addr):
print " msg_id 0x{:X} @ 0x{:X}, handler: 0x{:X}".format(msg_id, find_addr, func_addr)
ret.append(func_addr)
# custom_msg_handler
func_addr = idaapi.get_dword(find_addr + 2)
if is_func_ea(func_addr):
print " [custom_msg_handler] msg_id 0x{:X} @ 0x{:X}, handler: 0x{:X}".format(msg_id, find_addr, func_addr)
ret.append(func_addr)
find_addr = idc.find_binary(find_addr + 1, SEARCH_DOWN, data)
return ret经过逆向分析,发现消息处理函数和消息id的关系主要有两种情况
消息id起始地址 + 2的位置是函数地址消息id起始地址 + 4的位置是函数地址
两种情况分别对应custom_msg_handler和ke_msg_handler两种定义消息回调函数的结构体
/// Custom message handlers
struct custom_msg_handler
{
ke_task_id_t task_id;
ke_msg_id_t id;
ke_msg_func_t func;
};
/// Element of a message handler table.
struct ke_msg_handler
{
ke_msg_id_t id;
ke_msg_func_t func;
};脚本也是这样的逻辑,分别尝试这两个位置,如果是函数的话就认为是对应的回调函数,这样处理的坏处是没有考虑消息的其他参数,可能导致有的消息处理函数对于某些场景实际是调用不了的,但是还是会被我们的脚本建立交叉引用,所以只能说是可能的消息处理函数,不过这样也可以简化很多分析流程了。
最后使用IDA函数设置交叉引用即可
def add_ref(frm, to): idaapi.add_dref(frm, to, idaapi.dr_R) idaapi.add_dref(to, frm, idaapi.dr_R)
脚本使用方式
首先使用argument_tracker.py获取固件中每个函数的msg id的使用情况,然后将结果导出到文件中
https://github.com/hac425xxx/BLE-DA145XX/blob/main/argument_tracker.py#L610然后使用search_msg_handler.py导入之前获取到的结果,并搜索消息ID对应的回调函数,最后为两者建立交叉引用。
https://github.com/hac425xxx/BLE-DA145XX/blob/main/search_msg_handler.py#L70总结
本文介绍开始分析一个芯片的一些流程,介绍一些辅助人工的脚本的实现原理。
如有侵权请联系:admin#unsafe.sh