起因: 在渗透时发现glpi站点,复现cve的时候发现网上的POC并不好用,经过翻阅各种资料和调试之后,成功优化出更简单的POC。
参考文章:
- https://xz.aliyun.com/t/7818
- https://www.nayuki.io/page/forcing-a-files-crc-to-any-value
- https://blog.csdn.net/bhw98/article/details/19678
简介
GLPI简介
GLPI是法语GESTIONNAIRE LIBRE DE PARC INFORMATIQUE的缩写,翻译过来应该是开源IT和资产管理软件,在法国等欧洲国家和地区应用广泛并取得了很好的用户口碑。
项目地址:GitHub。

CVE简介
GitHub上的说明如下:
- 影响力:攻击者可以通过滥用备份功能来执行系统命令。从理论上讲,无需使用有效帐户,攻击者就可以使用CSRF利用此漏洞。由于没有有效帐户的攻击者难以利用,因此只有拥有维护特权和添加WIFI网络权限的帐户才能进行攻击;
- 受影响的版本:0.85-9.4.5;
- 类型:远程代码执行(RCE);
复现 && 优化
安装GLPI
在虚拟机(10.0.0.**/192.168.*.*)内搭建apache2 + PHP。
- 下载源码;
git clone https://github.com/glpi-project/glpi.git
- 将文件夹放到
/var/www/html目录下; 访问
localhost/install/install.php;按照提示完成安装;
分析漏洞点
漏洞点位于front/backup.php。
front/backup.php这个api原本实现的功能是数据的备份,有两种模式:xml备份和sql备份。
其部分参数说明如下:
$_GET['dump']:sql备份;$_GET['fichier']:设定sql备份导出文件的文件名(没有进行过滤、验证);$_GET['offsettable']:设定从第几个数据表开始导出;
$_GET['xmlnow']:xml备份;
在传入$_GET['dump'](sql备份)时,可以由$fichier=$_GET['fichier']变量控制导出的文件名,也就是说可以产生.php后缀名的文件。
if (isset($_GET["dump"]) && $_GET["dump"] != "") { if (!isset($_GET["fichier"])) { $fichier = $filename; } else { $fichier = $_GET["fichier"]; } if ($offsettable >= 0) { if (backupMySql($DB, $fichier, $duree, $rowlimit)) { echo "<div class='center spaced'>". "<a href=\"backup.php?dump=1&duree=$duree&rowlimit=$rowlimit&offsetrow=". "$offsetrow&offsettable=$offsettable&cpt=$cpt&fichier=$fichier\">". __('Automatic redirection, else click')."</a>"; echo "<script type='text/javascript'>" . "window.location=\"backup.php?dump=1&duree=$duree&rowlimit=". "$rowlimit&offsetrow=$offsetrow&offsettable=$offsettable&cpt=$cpt&fichier=". "$fichier\";</script></div>"; Html::glpi_flush(); exit; } } } function backupMySql($DB, $dumpFile, $duree, $rowlimit) { global $TPSCOUR, $offsettable, $offsetrow, $cpt; // $dumpFile, fichier source // $duree=timeout pour changement de page (-1 = aucun) if (function_exists('gzopen')) { $fileHandle = gzopen($dumpFile, "a"); } else { $fileHandle = gzopen64($dumpFile, "a"); } ..... }
先访问front/backup.php?fichier=../test1.php&dump=1。
访问test1.php,如下图所示:

查看test1.php,如下图所示:

成功写入../test1.php。
其他参数
在front/backup.php中还存在一个$offsettable参数,可以控制导出的数据表。
function backupMySql($DB, $dumpFile, $duree, $rowlimit) { for (; $offsettable<$numtab; $offsettable++) { // Dump de la structure table if ($offsetrow == -1) { $todump = "\n".get_def($DB, $tables[$offsettable]); gzwrite ($fileHandle, $todump); .... } .... } }
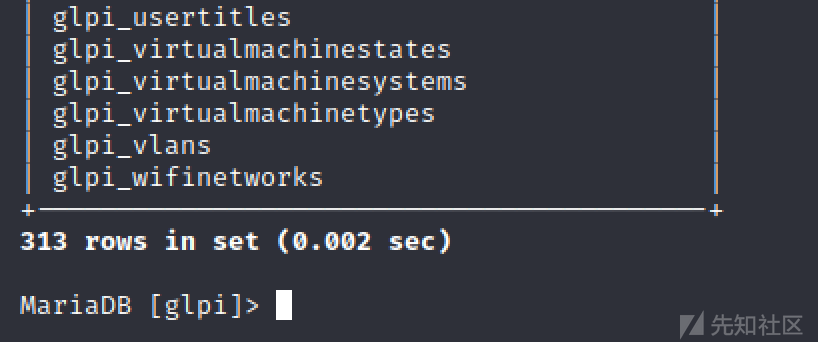
由于表一共有313张,如果令$offsettable=312,就只会导出最后一个表的相关数据,更容易控制导出的内容,方便构造攻击手段。
在我的环境中,最后的数据表名称为glpi_wifinetworks。

dump下来的数据,解压之后如下:
### Dump table glpi_wifinetworks DROP TABLE IF EXISTS `glpi_wifinetworks`; CREATE TABLE `glpi_wifinetworks` ( `id` int(11) NOT NULL AUTO_INCREMENT, `entities_id` int(11) NOT NULL DEFAULT 0, `is_recursive` tinyint(1) NOT NULL DEFAULT 0, `name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `essid` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL, `mode` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'ad-hoc, access_point', `comment` text COLLATE utf8_unicode_ci DEFAULT NULL, `date_mod` datetime DEFAULT NULL, `date_creation` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `entities_id` (`entities_id`), KEY `essid` (`essid`), KEY `name` (`name`), KEY `date_mod` (`date_mod`), KEY `date_creation` (`date_creation`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; INSERT INTO `glpi_wifinetworks` VALUES ('8','0','0','PoC','RCE','ad-hoc','a','2020-12-30 23:06:44','2020-12-30 03:17:20');
其中的comment字段是text类型的,长度有2¹⁶,用来放payload最合适。

攻击
攻击过程如下:
在
comment字段构造合适的数据;使用
backup.php产生备份,形成一个webshell,通过$fichier变量控制文件名;
第二步很简单,关键是怎样去构造一串特定的payload,使文件内容恰好能形成一个webshell。
发现者的思路
爆破得到两个数据块。
在前面填充第一个数据块,使得压缩之后恰巧出现
<?=/*短标签;<?php或<?会引发PHP错误,因为数据在这个标签之后也会被解释成PHP语法;<?="或<?='也不行,因为在这个短标签之后的数据中很可能闭合了引号;
在后面填充第二个不被压缩的块,写入
*/ eval(); /*;GZIP采用分块压缩,最后一个块定义了三种类型:
00-未压缩、01-固定的Huffman编码压缩、10-动态的Huffman编码压缩、11-保留(错误)。采用爆破的方法得到一串能够不被压缩的数据;GLPI的XSS过滤器会在数据进入数据库时对其过滤,所以无法在不被压缩块中直接写入webshell;
static function clean_cross_side_scripting_deep($value) { if ((array) $value === $value) { return array_map([__CLASS__, 'clean_cross_side_scripting_deep'], $value); } if (!is_string($value)) { return $value; } $in = ['<', '>']; $out = ['<', '>']; return str_replace($in, $out, $value); }
GZIP数据块前会有压缩后的SIZE和压缩后SIZE的补码,且是小端序存放,要让补码成为
<的话需要填充大量的字节,很难保证有合适的不压缩块(填充过程中根据填充的数据不同,不压缩块可能变成压缩块),因此不能通过SIZE的补码构造<来xss过滤器;
我的思路
由于backupMySql函数内,gzopen函数的参数使用了"a"(append),所以如果两次备份的文件名相同,那么就会在后面追加,而不是覆盖。
$fileHandle = gzopen($dumpFile, "a");
由此,我想到了另一种方法:分两次备份,写入同一个文件内。
- 第一次备份,通过构造gzip的文件头/尾,写入短标签;
- 在后文详细说明了构造的方法;
- 第二次备份,通过不压缩块,闭合注释并写入webshell;
构造GZIP
gzip是RFC 1952中定义的一种无损压缩数据格式,同时也是一种软件实现。 其程序由Jean-Loup Gailly和Mark Adler创建,作为
compressUnix程序的一个无专利软件替代品。
GZIP文件可以归结为以下三个部分:
+-------------------+
| head |
+-------------------+
| data | <=== BFINAL + BTYPE + DATA
+-------------------+
| tail | <=== CRC32 + ISIZE
+-------------------+GZIP拥有特定的文件头和文件尾,这里使用infgen工具查看格式:
! infgen 2.4 output
!
gzip
!
last
dynamic
litlen 10 6
......
dist 18 5
literal 10 '### Dump table glpi_wifinetworks
......
literal 10
end
!
crc
length数据流头部的结构体都与压缩后的数据、压缩算法有关,因此数据流头部难以构造出相应的载荷。
压缩数据部分也难以构造出相应的载荷(CVE发现者用了一晚上的时间爆破)。
数据流尾部的结构体都与原始数据有关,因此考虑在数据流尾部构造载荷。
GZIP文件尾
GZIP文件尾由两部分构成:
- CRC32:4字节。原始(未压缩)数据的32位校验和;
- ISIZE:4字节。原始(未压缩)数据的长度的低32位;
这两个部分都是和原始数据有关,更好控制,并且大小一共是8个字节,而php的短标签<?=/*,只有5个字节。

相比于长度字段来说,CRC字段更好控制一些。长度每控制一位,载荷就会大量增长。尽可能的少用ISIZE字段,可以减少payload的长度和限制。
CRC伪造
参考: https://www.nayuki.io/page/forcing-a-files-crc-to-any-value。
由于文件的CRC值和文件整体内容有关,修改文件的部分内容,将引起CRC的变动。
这个工具利用了上述原理,通过修改文件内的四个字节使文件的CRC变成任意值。为了更好的输入进数据库中,肯定是可见字符最好。
根据上述方法,可以得出构造过程:
- 构造长度的最后一个字节是0x2a(ascii='*')的备份结果;
- 使用上面的工具构造
comment字段,使其CRC变为<?=/; - 若得到的结果不是全可见字符串,重复2步骤;
这个爆破很快,通常不到一分钟就能得到一串全可见字符的数据。
下面提供一个爆破出来的例子:
### Dump table glpi_wifinetworks
DROP TABLE IF EXISTS `glpi_wifinetworks`;
CREATE TABLE `glpi_wifinetworks` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`entities_id` int(11) NOT NULL DEFAULT 0,
`is_recursive` tinyint(1) NOT NULL DEFAULT 0,
`name` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`essid` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
`mode` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'ad-hoc, access_point',
`comment` text COLLATE utf8_unicode_ci DEFAULT NULL,
`date_mod` datetime DEFAULT NULL,
`date_creation` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `entities_id` (`entities_id`),
KEY `essid` (`essid`),
KEY `name` (`name`),
KEY `date_mod` (`date_mod`),
KEY `date_creation` (`date_creation`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
INSERT INTO `glpi_wifinetworks` VALUES ('8','0','0','PoC','RCE','ad-hoc','j~a6aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaVw8,','2020-12-31 03:07:37','2020-12-30 03:17:20');样例文件的CRC如下图所示(ascii('<?=/')=3c3f3d2f):

样例文件的ISIZE如下图所示(hex(1066)=0x042a):

压缩后的信息如下图所示(小端序):

不被压缩的块
第一个问题解决了之后,要解决第二个问题——构造一个不被压缩的块。
RFC 定义了DEFLATE 流的输出格式:
压缩数据集由一系列块组成,对应于连续的输入数据块。块大小是任意的,除了不可压缩的块限制为65,535字节。
每个块使用LZ77算法和Huffman编码的组合进行压缩。每个块的Huffman树独立于其前续或后续块的树,LZ77算法可以使用在前一个块中出现过的重复字符串的引用,最多在此之前32K输入字节。
Huffman编码和LZ77算法这里就不在过多介绍了。
DEFLATE定义了3种有效块类型:
- 00-未压缩;
- 01-用固定的Huffman编码压缩;
- 10-用动态Huffman编码压缩;
- 11-保留(错误);
为了选择一种块类型,gzip使用的压缩器会比较未压缩、固定和动态Huffman编码几种类型中哪个更短。
写入一个phpwebshell;
在前面/后面填充一定的字符;
压缩,判断是否是不压缩块;
通过不断修改填充字符(爆破),直到产生不被压缩的块。(POC中的payload/payload就是一个例子)
困难和解决方法
这种利用方法存在条件:
- 在使用
front/backup.php备份的时候,存在date_mod字段,该字段会在修改的时候更新。这就给利用带来了困难——date_mod字段的更新会导致CRC的变化,使得GZIP压缩过程中无法产生PHP短标签;
为此,提出了更加详细的利用方法:
备份所有的数据,并且删除所有的记录(之后还原数据,降低利用难度);
新增一条记录;
以上两步在poc中未实现,请手动进行。
修改记录内容,使用备份功能得到详细内容(主要是
date_mod,同步时间);设置备份结果内的
date_mod字段为原始时间+1分钟(延迟时间);在延迟时间内使用CRC伪造工具得到特定的数据(上文提到的);
延迟了1分钟后,修改记录内容并备份,备份出来的结果恰好如伪造的结果(控制了
date_mod);修改记录内容为不压缩块,备份到同一文件中;
流程大致如下图:

如下图所示,攻击成功:

POC
POC地址:https://github.com/zeromirror/cve_2020-11060
目录结构:
CVE_2020_11060_POC
- POC.py ===> 主要POC
- crcChanger.py ===> 伪造CRC
+ tmp_data ===> 临时文件,日志信息(在运行时生成)
+ payload ===> 攻击载荷
- a ===> 伪造CRC的数据
- payload ===> 不加密的数据总结
对比一下我和CVE发现者的不同方法。
我的思路的优点:
- 构造简单,不需要经过漫长的爆破时间;
- 利用GZIP自身的文件格式,操作性更强;
发现者的思路的优点:
- 理解简单,不需要弄懂GZIP的文件格式,通过暴力穷举得到POC;
- 不需要变化,由于前面的内容是固定的,后面的内容不会加密,那么理论上来说这个POC基本不用变化就能用(但是发现者贴的POC我直接拿来用却失败了);
如有侵权请联系:admin#unsafe.sh