linux作为开源内核,被广泛使用。同时随着用户态安全机制的逐渐完善,攻击成本逐年升高,越来越多的黑客将目光投向linux内核,linux内核安全问题也随之被越来越多的安全研究人员关注。但作为一个规模宏大的开源项目,linux内核安全研究存在非常高的研究门槛,不管是针对特定模块的漏洞挖掘,还是cve复现,对内核的理解限制了绝大多数安全研究人员。而本文则希望通过对内核源码做详细分析来让更多的安全研究人员越过内核门槛。
这篇文章的贡献如下:
(1)硬件层面上分析linux内核页表
(2)从buddy源码分析linux内核页管理
(3)从slub源码分析linux内核小内存管理
(4)从vma源码分析linux内核对于进程内存空间的布局及管理
(5)分析缺页中断流程
(6)从ptmalloc源码分析用户态内存管理机制,以及如何通过特定api与linux内核交互
页表
页表查询--以x86_64下的4级页表举例(硬件)
- 流程总览(定义虚拟地址virt_addr, 寻找对应的物理地址phy_addr)
- 顺序: TLB -> 页表结构cache -> 页表(MMU硬件实现)
- MMU = TLB(Translation Lookaside Buffer) + table walk unit
TLB转换
- 明确概念:
VPN(virtual page number), PPN(physical page number),VPO(virtual page offset)和PPO(physical page offset)
- 对于线性地址和物理地址而言, 都是以page为最小的管理单元, 那么也就是说如果线性地址可以映射到某物理地址, 则两者页偏移相同(默认page size = 4K, 占用低12bits), 即VPO = PPO
- TLB可以简单理解成VPN->PPN(36bits), 实现了一个线性映射, 基本结构如下:
___________________ |__VPN1___|__PPN1___| |__VPN2___|__PPN2___| |__VPN3___|__PPN3___| ... ... 通过VPN(virt_addr[12:48])定位表项
全相连(full associative)-- VPN可以被填充在TLB中的任何位置
- 定位VPN对应的表项需要遍历TLB中的所有表项
直接匹配-- VPN被映射在特定位置
- 如果TLB存在n个表项, 那么VPN%n即为该VPN的索引
- 定位到索引后, 查看VPN是否匹配, 如果不匹配则TLB miss
组相连(set-associative)-- 全相连和直接匹配相结合
- TLB被划分为m组, 每个组存在n表项, VPN分为set(VPN[47-log2(m):48]), tag(VPN[12:48-log2(m)])
- VPN[47-log2(m):48]%m为该VPN的set索引
- 定位到索引后, 查看set内是否存在tag, 如果不存在则TLB miss
页表转换
明确概念:
对于四级页表: PGD(page global directory), PUD(page upper directory), PMD(page middle directory), PTE(page table entry), 每个页表占9bits, 支持48bits虚拟地址
对于五级页表:添加P4D表项, 支持57位虚拟地址
通过virt_addr[12:48]定位page table entry
CR3寄存器存储PGD物理地址, virt_addr[12:21]为PGD_index, PGD+PGD_index=PGD_addr
- virt_addr[21:30]为PUD_index, PGD_addr+PUD_index=PUD_addr
- virt_addr[30:39]为PME_index, PUD_addr+PME_index=PME_addr
virt_addr[39:48]为PTE_index, PME_addr+PTE_index=PTE_addr
PTE_addr即为page table entry是一个表项映射到PPN
页表结构cache转换
- 明确概念:
如果某些虚拟地址临近, 那么很有可能他们会有相同的页表项(PGD or PUD or PMD or PTE),对于这种情况如果还是依次查询页表就会浪费大量时间, 所以存在页表结构cache, 用来缓存页表
cache种类:
- PDE cache(virt_addr[22:48]作为tag, 映射PME entry地址)
- PDPTE cache(virt_addr[31:48]作为tag, 映射PUD entry地址)
- PML4 cache(virt_addr[40:48]作为tag, 映射PGD entry地址)
拓展
普通页表cache
- 明确概念:
页表保存在内存中, 可以被缓存到普通cache
各级页表中存在PCD(page-level cache disable)标志位, 控制下一级页表是否需要被缓存
Huge_Page
- 明确概念:
- 页表中指向下一级的地址是按页对齐的, 也就是低12bits无效, 可以用作flag标志位
page size flag为1时表示当前页表的下级地址对应大页地址而不是页表
x86两级页表支持4MB大页(跳过PTE, 4K*2^10=4MB)
x86_64四级页表支持2MB大页(跳过PTE, 4K*2^9=2MB), 1GB大页(跳过PME, 2M*2^9=1GB)
页表标志位
P(Present) - 为1表明该page存在于当前物理内存中, 为0则触发page fault。
G(Global)- 标记kernel对应的页, 也存在于TLB entry, 表示该页不会被flush掉。
A(Access) - 当page被访问(读/写)过后, 硬件置1。软件可置0, 然后对应的TLB将会被flush掉。
D(Dirty)- 对写回的page有作用。当page被写入后, 硬件置1, 表明该page的内容比外部disk/flash对应部分要新, 当系统内存不足, 要将该page回收的时候, 需首先将其内容flush到外部存储, 之后软件将该标志位清0。
R/W和U/S属于权限控制类:
R/W(Read/Write) - 置1表示该page是writable的, 置0是readonly。
U/S(User/Supervisor) - 置0表示只有supervisor(比如操作系统中的kernel)才可访问该page, 置1表示user也可以访问。
PCD和PWT和cache属性相关:
PCD(Page Cache Disabled)- 置1表示disable, 即该page中的内容是不可以被cache的。如果置0(enable), 还要看CR0寄存器中的CD位这个总控开关是否也是0。
PWT (Page Write Through)- 置1表示该page对应的cache部分采用write through的方式, 否则采用write back。
64位特有:
XD (Execute Disable)- 在bit[63]中
CR3支持PCID:
CR4寄存器的PCIDE位 = 1, 则CR3低12位表示PCID(覆盖PCD和PWT--CR3低12bits只有PCD和PWT标志位)
伙伴算法(buddy)
- alloc_pages(内存分配)概略图

- __free_pages(内存释放)缩略图

alloc_pages源码分析
- pol变量保存内存分配策略(man set_mempolicy)

- MPOL_DEFAULT: 默认策略, 优先从当前结点分配内存, 若当前结点无空闲内存, 则从最近的有空闲内存的结点分配
- MPOL_BIND: 指定内存分配结点集合, 若该集合内无空闲内存, 则分配失败
- MPOL_INTERLEAVE: 内存分配要覆盖所有结点, 且每个结点使用的内存大小相同, 常用于共享内存区域
- MPOL_PREFERRED: 从指定结点上分配内存, 若该结点无空闲内存, 则从其他结点分配
- MPOL_LOCAL: 同MPOL_DEFAULT
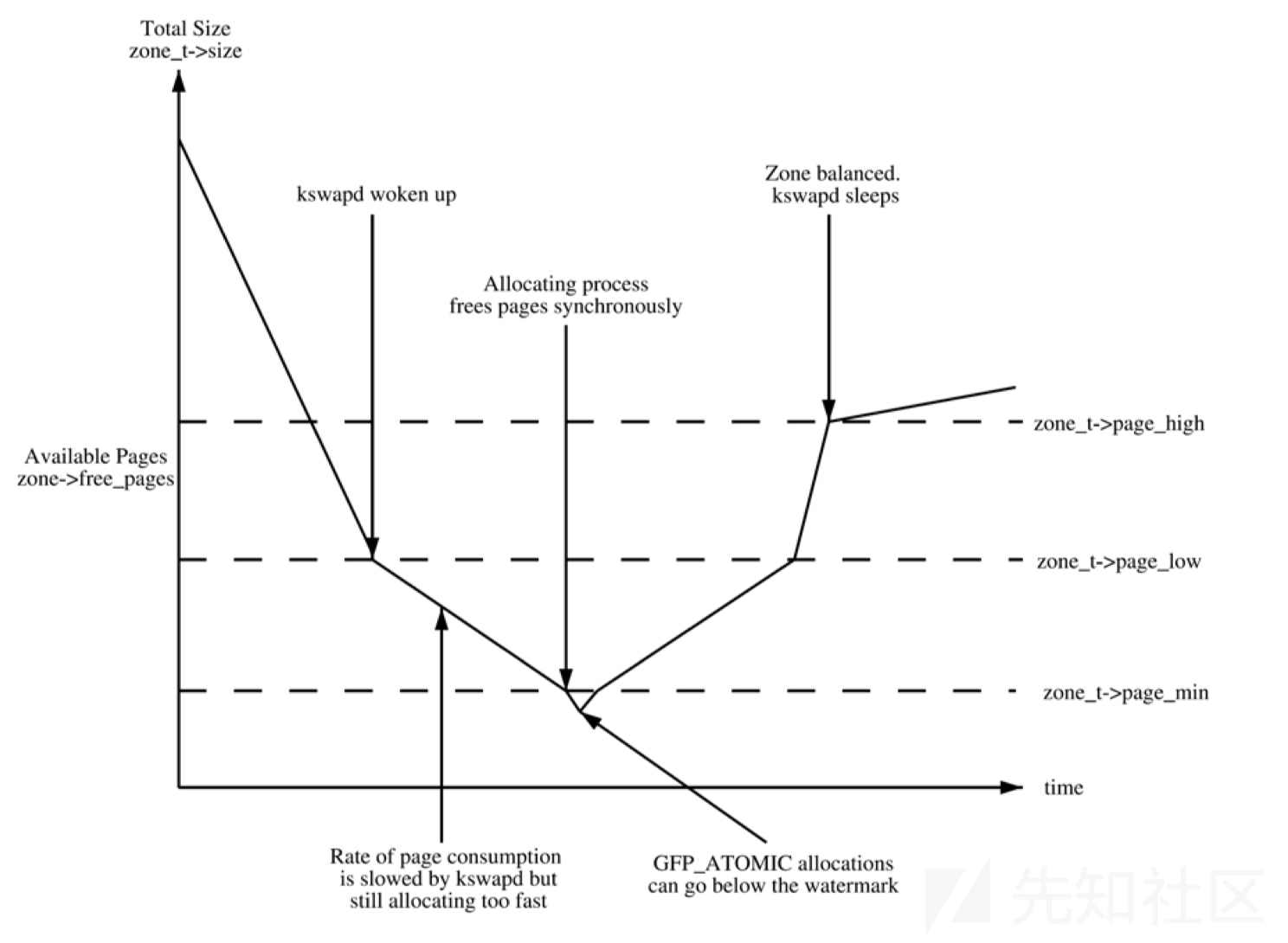
- water_mark
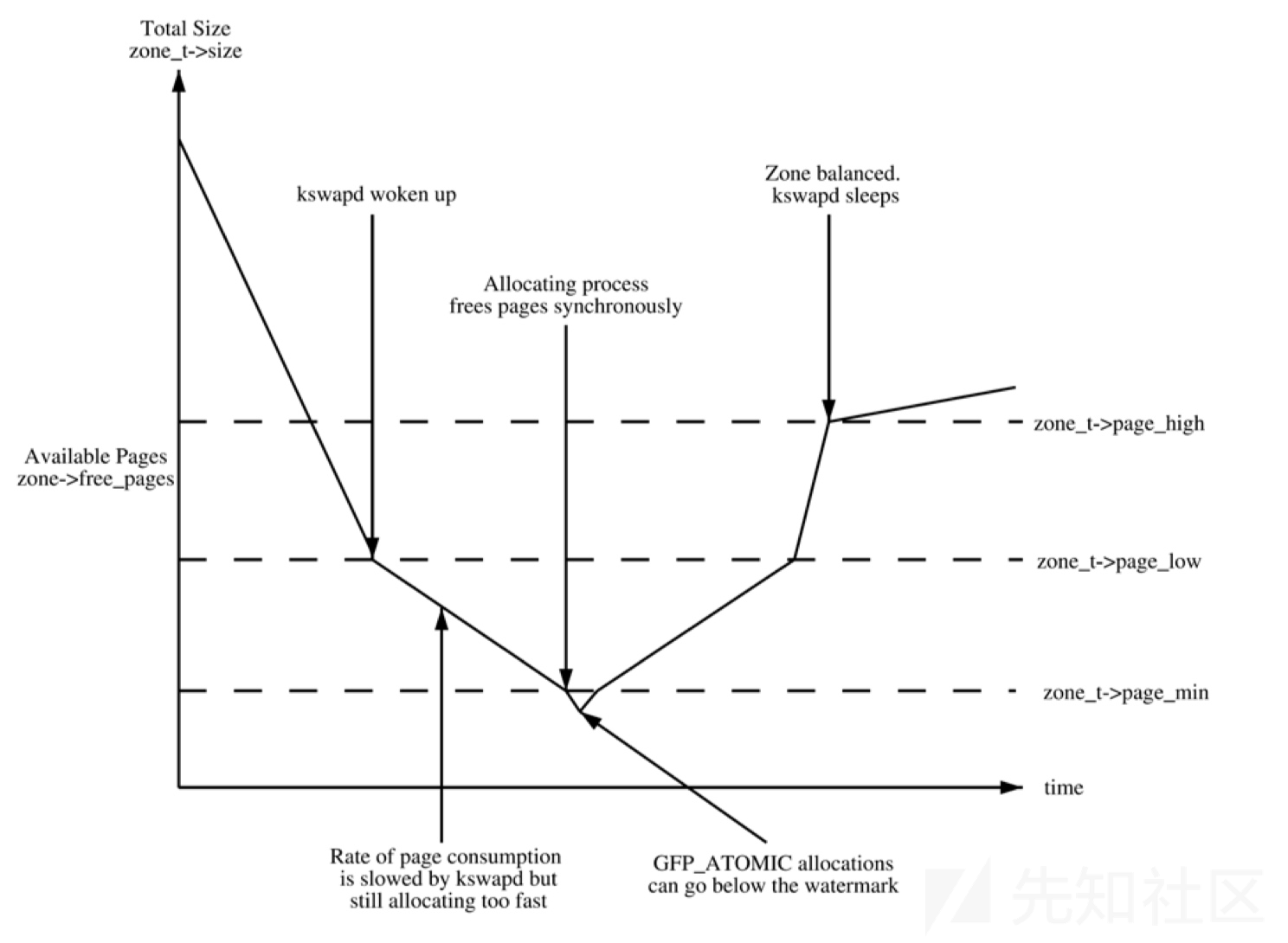
enum zone_watermarks { WMARK_MIN, WMARK_LOW, WMARK_HIGH, NR_WMARK };
- WMARK_MIN: 当空闲页面的数量降到WMARK_MIN时, 唤醒 kswapd 守护进程以同步的方式进行直接内存回收, 同时只有GFP_ATOMIC可以在这种情况下分配内存
- WMARK_LOW: 当空闲页面的数量降到WMARK_LOW时, 唤醒 kswapd 守护进程进行内存回收
WMARK_HIGH: kswapd进程休眠
自旋锁(spin_lock)
- 为什么使用自旋锁:
- 使用常规锁会发生上下文切换,时间不可预期,对于一些简单的、极短的临界区来说是一种性能损耗
- 中断上下文是不允许睡眠的,除了自旋锁以外的其他锁都有可能导致睡眠或者进程切换,这是违背了中断的设计初衷,会发生不可预知的错误
- 自旋锁的功能: 一直轮询等待检查临界区是否可用, 直至时间片用完
- 自旋锁使用原则:
- 禁止抢占: 如果A, B同时访问临界区, A进程首先获得自旋锁, B进程轮询等待, B抢占A后, B无法获得自旋锁, 造成死锁
- 禁止睡眠: 如果自旋锁锁住以后进入睡眠,而又不能进行处理器抢占,内核的调取器无法调取其他进程获得该CPU,从而导致该CPU被挂起;同时该进程也无法自唤醒且一直持有该自旋锁,进一步会导致其他使用该自旋锁的位置出现死锁
- 自旋锁的几个实现:
- spin_lock: 只禁止内核抢占, 不会关闭本地中断
- spin_lock_irq: 禁止内核抢占, 且关闭本地中断
- spin_lock_irqsave: 禁止内核抢占, 关闭中断, 保存中断状态寄存器的标志位
- spin_lock与spin_lock_irq的区别:
- 禁止中断与禁止抢占的原因相同
- spin_lock_irq与spin_lock_irqsave的区别:
- 假设临界区被两把spin_lock_irq(a->b)锁定, 当b解锁后(a还在加锁中), 不会保存a加锁后的中断寄存器状态(直接开中断), 也就是锁a在加锁时, 中断被打开, 导致spin_lock_irq在功能上和spin_lock相同, 也就具备了spin_lock的中断隐患
alloc_pages_current
struct page *alloc_pages_current(gfp_t gfp, unsigned order) { // pol变量保存内存分配策略(默认为default_policy) struct mempolicy *pol = &default_policy; struct page *page; // 如果不在中断状态下且未指定在当前结点分配内存时, 使用get_task_policy获得当前进程内存分配策略 if (!in_interrupt() && !(gfp & __GFP_THISNODE)) pol = get_task_policy(current); // 如果内存分配策略为MPOL_INTERLEAVE, 则进入alloc_page_interleave if (pol->mode == MPOL_INTERLEAVE) page = alloc_page_interleave(gfp, order, interleave_nodes(pol)); else page = __alloc_pages_nodemask(gfp, order, policy_node(gfp, pol, numa_node_id()), policy_nodemask(gfp, pol)); return page; }
__alloc_pages_nodemask
struct page * __alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask) { struct page *page; unsigned int alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */ struct alloc_context ac = { }; // 如果order大于MAX_ORDER(11), 则内存分配失败 if (unlikely(order >= MAX_ORDER)) { WARN_ON_ONCE(!(gfp_mask & __GFP_NOWARN)); return NULL; } // 添加gfp_allowed_mask标志位 gfp_mask &= gfp_allowed_mask; alloc_mask = gfp_mask; // 填充ac参数(用于内存分配), 并做一些检查 if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask, &ac, &alloc_mask, &alloc_flags)) return NULL; // 决定是否平衡各个zone中的脏页, 确定zone(相当于对prepare_alloc_pages的补充) finalise_ac(gfp_mask, &ac); // 给alloc_flags添加ALLOC_NOFRAGMENT标志位(不使用zone备用迁移类型), 如果遍历完本地zone后仍然无法分配内存则取消该标志位, 该方案是为了减少内存碎片 alloc_flags |= alloc_flags_nofragment(ac.preferred_zoneref->zone, gfp_mask); // 通过快分配分配内存页 page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac); if (likely(page)) goto out; alloc_mask = current_gfp_context(gfp_mask); ac.spread_dirty_pages = false; if (unlikely(ac.nodemask != nodemask)) ac.nodemask = nodemask; // 通过慢分配分配内存页 page = __alloc_pages_slowpath(alloc_mask, order, &ac); out: if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page && unlikely(__memcg_kmem_charge(page, gfp_mask, order) != 0)) { __free_pages(page, order); page = NULL; } trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype); return page; }
prepare_alloc_pages
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask, struct alloc_context *ac, gfp_t *alloc_mask, unsigned int *alloc_flags) { // ac填充从gfp_mask获取的内存分配参数 // 获得当前nodemask对应的zone的max_index ac->high_zoneidx = gfp_zone(gfp_mask); // 获得node对应的zone_list ac->zonelist = node_zonelist(preferred_nid, gfp_mask); ac->nodemask = nodemask; // 选择迁移类型 ac->migratetype = gfpflags_to_migratetype(gfp_mask); // 判断是否存在cpuset机制 if (cpusets_enabled()) { *alloc_mask |= __GFP_HARDWALL; if (!ac->nodemask) ac->nodemask = &cpuset_current_mems_allowed; else *alloc_flags |= ALLOC_CPUSET; } // 函数未实现 fs_reclaim_acquire(gfp_mask); fs_reclaim_release(gfp_mask); // 如果内存紧张可能会休眠 might_sleep_if(gfp_mask & __GFP_DIRECT_RECLAIM); // 对gfp_mask, ord做检查(默认没有开启CONFIG_FAIL_PAGE_ALLOC的情况下, 直接return false) if (should_fail_alloc_page(gfp_mask, order)) return false; // 匹配CMA机制 if (IS_ENABLED(CONFIG_CMA) && ac->migratetype == MIGRATE_MOVABLE) *alloc_flags |= ALLOC_CMA; return true; }
finalise_ac
static inline void finalise_ac(gfp_t gfp_mask, struct alloc_context *ac) { /* Dirty zone balancing only done in the fast path */ ac->spread_dirty_pages = (gfp_mask & __GFP_WRITE); // 从zone_list头部开始寻找匹配nodemask的zoneref ac->preferred_zoneref = first_zones_zonelist(ac->zonelist, ac->high_zoneidx, ac->nodemask); }
get_page_from_freelist
static struct page * get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac) { struct zoneref *z; struct zone *zone; struct pglist_data *last_pgdat_dirty_limit = NULL; bool no_fallback; retry: /* * Scan zonelist, looking for a zone with enough free. */ // ALLOC_NOFRAGMENT标志位由alloc_flags_nofragment()函数设置 // no_fallback: node->node_zonelists[]包含本node的zones以及备用zones, 设置fallback后可使用备用zones no_fallback = alloc_flags & ALLOC_NOFRAGMENT; z = ac->preferred_zoneref; // 遍历zone for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx, ac->nodemask) { struct page *page; unsigned long mark; // 判断cpuset是否开启且当前CPU是否允许在内存域zone所在结点中分配内存 if (cpusets_enabled() && (alloc_flags & ALLOC_CPUSET) && !__cpuset_zone_allowed(zone, gfp_mask)) continue; // ac->spread_dirty_pages不为0表示gfp_mask存在__GFP_WRITE标志位, 有可能增加脏页 if (ac->spread_dirty_pages) { if (last_pgdat_dirty_limit == zone->zone_pgdat) continue; // 如果zone对应的node脏页超标则使用last_pgdat_dirty_limit标识, 并跳过该zone if (!node_dirty_ok(zone->zone_pgdat)) { last_pgdat_dirty_limit = zone->zone_pgdat; continue; } } // 如果设置no_fallback且当前zone并非preferred_zone, 则索引zone->node, 如果该node并非preferred_zone->node, 则取消ALLOC_NOFRAGMENT标志位即设置fallback(因为相比于内存碎片, 内存局部性更重要) if (no_fallback && nr_online_nodes > 1 && zone != ac->preferred_zoneref->zone) { int local_nid; local_nid = zone_to_nid(ac->preferred_zoneref->zone); if (zone_to_nid(zone) != local_nid) { alloc_flags &= ~ALLOC_NOFRAGMENT; goto retry; } } // 获取该zone的水准, 并检查该zone的水位是否水准之上 mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK); if (!zone_watermark_fast(zone, order, mark, ac_classzone_idx(ac), alloc_flags, gfp_mask)) { int ret; // 如果存在ALLOC_NO_WATERMARKS标志位则忽略水位, 进入try_this_zone if (alloc_flags & ALLOC_NO_WATERMARKS) goto try_this_zone; /* static bool zone_allows_reclaim(struct zone *local_zone, struct zone *zone) { return node_distance(zone_to_nid(local_zone), zone_to_nid(zone)) <= node_reclaim_distance; } */ // 如果系统不允许回收内存或者preferred->zone与当前zone的node_distance大于node_reclaim_distance(默认30), 则更换zone if (node_reclaim_mode == 0 || !zone_allows_reclaim(ac->preferred_zoneref->zone, zone)) continue; // 内存回收 ret = node_reclaim(zone->zone_pgdat, gfp_mask, order); switch (ret) { case NODE_RECLAIM_NOSCAN: /* did not scan */ continue; case NODE_RECLAIM_FULL: /* scanned but unreclaimable */ continue; default: // 内存回收后, 水位正常 if (zone_watermark_ok(zone, order, mark, ac_classzone_idx(ac), alloc_flags)) goto try_this_zone; continue; } } try_this_zone: // 伙伴算法开始分配页内存 page = rmqueue(ac->preferred_zoneref->zone, zone, order, gfp_mask, alloc_flags, ac->migratetype); if (page) { prep_new_page(page, order, gfp_mask, alloc_flags); if (unlikely(order && (alloc_flags & ALLOC_HARDER))) reserve_highatomic_pageblock(page, zone, order); return page; } else { }
rmqueue
static inline struct page *rmqueue(struct zone *preferred_zone, struct zone *zone, unsigned int order, gfp_t gfp_flags, unsigned int alloc_flags, int migratetype) { unsigned long flags; struct page *page; //如果分配单页, 则进入rmqueue_pcplist if (likely(order == 0)) { page = rmqueue_pcplist(preferred_zone, zone, gfp_flags, migratetype, alloc_flags); goto out; } // 不能使用__GFP_NOFAIL, 分配order>1的页 WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1)); // 使用自旋锁加锁zone资源 spin_lock_irqsave(&zone->lock, flags); do { page = NULL; // ALLOC_HARDER表示高优先级分配, 进入__rmqueue_smallest if (alloc_flags & ALLOC_HARDER) { page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC); if (page) // 用于debug的插桩设计 trace_mm_page_alloc_zone_locked(page, order, migratetype); } // 不满足上诉条件或page未分配成功, 进入__rmqueue if (!page) page = __rmqueue(zone, order, migratetype, alloc_flags); } while (page && check_new_pages(page, order)); // check_new_pages遍历page_block中的struct page, 检查page成员, 如果出错则打印错误原因 spin_unlock(&zone->lock); if (!page) goto failed; // page_block被分配后更新zone成员信息 __mod_zone_freepage_state(zone, -(1 << order), get_pcppage_migratetype(page)); __count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order); // 如果系统是NUMA架构, 则更新NUMA hit/miss 数据 zone_statistics(preferred_zone, zone); // 恢复中断信息 local_irq_restore(flags); out: /* Separate test+clear to avoid unnecessary atomics */ if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) { clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags); wakeup_kswapd(zone, 0, 0, zone_idx(zone)); } // 编译阶段的变量类型检查 VM_BUG_ON_PAGE(page && bad_range(zone, page), page); return page; failed: local_irq_restore(flags); return NULL; }
rmqueue_pcplis
static struct page *rmqueue_pcplist(struct zone *preferred_zone, struct zone *zone, gfp_t gfp_flags, int migratetype, unsigned int alloc_flags) { struct per_cpu_pages *pcp; struct list_head *list; struct page *page; unsigned long flags; // 禁用全部中断, 并将当前中断状态保存至flags local_irq_save(flags); // 获得当前cpu的pcp结构体(热页) pcp = &this_cpu_ptr(zone->pageset)->pcp; // 根据迁移类型选择热页链表 list = &pcp->lists[migratetype]; // 在list中分配内存页 page = __rmqueue_pcplist(zone, migratetype, alloc_flags, pcp, list); if (page) { __count_zid_vm_events(PGALLOC, page_zonenum(page), 1); // Update NUMA hit/miss statistics zone_statistics(preferred_zone, zone); } // 恢复中断状态并开中断 local_irq_restore(flags); return page; }
- __rmqueue_pcplist
static struct page *__rmqueue_pcplist(struct zone *zone, int migratetype, unsigned int alloc_flags, struct per_cpu_pages *pcp, struct list_head *list) { struct page *page; do { // 如果列表为空, 则使用rmqueue_bulk装载内存页进入列表 if (list_empty(list)) { pcp->count += rmqueue_bulk(zone, 0, pcp->batch, list, migratetype, alloc_flags); if (unlikely(list_empty(list))) return NULL; } // 获得lru列表首部页结点 page = list_first_entry(list, struct page, lru); // 将页结点从page->lru列表删除 list_del(&page->lru); // 空闲page计数器-1 pcp->count--; // 对page做安全检查 } while (check_new_pcp(page)); return page; }
- rmqueue_bulk
static int rmqueue_bulk(struct zone *zone, unsigned int order, unsigned long count, struct list_head *list, int migratetype, unsigned int alloc_flags) { int i, alloced = 0; // 对zone资源加锁 spin_lock(&zone->lock); for (i = 0; i < count; ++i) { // 从zone中取出page放入pcp热页缓存列表, 直至pcp被填满 struct page *page = __rmqueue(zone, order, migratetype, alloc_flags); if (unlikely(page == NULL)) break; // check_pcp_refill封装check_new_page if (unlikely(check_pcp_refill(page))) continue; // 添加page至list->lru list_add_tail(&page->lru, list); alloced++; // 如果page位于cma中, 则更新NR_FREE_CMA_PAGES if (is_migrate_cma(get_pcppage_migratetype(page))) __mod_zone_page_state(zone, NR_FREE_CMA_PAGES, -(1 << order)); } // 从zone摘取page_block过程循环了i次, 每个page_block包含2^i个page, NR_FREE_PAGES-i << order, 更新NR_FREE_PAGES __mod_zone_page_state(zone, NR_FREE_PAGES, -(i << order)); // 解锁 spin_unlock(&zone->lock); return alloced; }
__rmqueue_smallest
static __always_inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype) { unsigned int current_order; struct free_area *area; struct page *page; // 从指定order到MAX_ORDER遍历zone->free_area[] for (current_order = order; current_order < MAX_ORDER; ++current_order) { area = &(zone->free_area[current_order]); // 从zone->free_area[][migratetype]->lru链表头部获得page() page = get_page_from_free_area(area, migratetype); if (!page) continue; // 从zone->free_area[][migratetype]->lru中删除page, 更新zone成员 del_page_from_free_area(page, area); // 将current_order阶的page_block拆成小块,并将小块放到对应的阶的链表中去 expand(zone, page, order, current_order, area, migratetype); // 设置page迁移类型 set_pcppage_migratetype(page, migratetype); return page; } return NULL; }
__rmqueue
static __always_inline struct page * __rmqueue(struct zone *zone, unsigned int order, int migratetype, unsigned int alloc_flags) { struct page *page; retry: // 使用__rmqueue_smallest获得page page = __rmqueue_smallest(zone, order, migratetype); if (unlikely(!page)) { // page分配失败后, 如果迁移类型是MIGRATE_MOVABLE, 进入__rmqueue_cma_fallback if (migratetype == MIGRATE_MOVABLE) page = __rmqueue_cma_fallback(zone, order); // page分配再次失败后使用判断是否可以使用备用迁移类型(如果可以则修改order, migratetype)然后跳转进入retry if (!page && __rmqueue_fallback(zone, order, migratetype, alloc_flags)) goto retry; } trace_mm_page_alloc_zone_locked(page, order, migratetype); return page; }
- __rmqueue_fallback
- 备用迁移类型
static int fallbacks[MIGRATE_TYPES][4] = { [MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, [MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES }, [MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES }, #ifdef CONFIG_CMA #endif #ifdef CONFIG_MEMORY_ISOLATION #endif };
- __rmqueue_fallback
static __always_inline bool __rmqueue_fallback(struct zone *zone, int order, int start_migratetype, unsigned int alloc_flags) { struct free_area *area; int current_order; int min_order = order; struct page *page; int fallback_mt; bool can_steal; // 如果设置alloc_flags为ALLOC_NOFRAGMENT(内存碎片优化), min_order=pageblock_order(MAX_ORDER-1)---尽可能分配大页 if (alloc_flags & ALLOC_NOFRAGMENT) min_order = pageblock_order; // 遍历zone->free_area[order](order=MAX_ORDER-1~min_order) for (current_order = MAX_ORDER - 1; current_order >= min_order; --current_order) { area = &(zone->free_area[current_order]); // 查找可以盗取的迁移类型 fallback_mt = find_suitable_fallback(area, current_order, start_migratetype, false, &can_steal); if (fallback_mt == -1) continue; // 如果can_steal=0且迁移类型为MIGRATE_MOVABLE, 当前所在的order大于需求order, 跳转进入find_smallest // 这里的can_steal=0并不表示不能盗取, 只是对于迁移类型为MIGRATE_MOVABLE的内存分配需求有更好的解决方法(窃取和拆分最小的可用页块而不是最大的可用页块)所以单独列出 if (!can_steal && start_migratetype == MIGRATE_MOVABLE && current_order > order) goto find_smallest; goto do_steal; } return false; find_smallest: // 从最小的order开始遍历 for (current_order = order; current_order < MAX_ORDER; current_order++) { area = &(zone->free_area[current_order]); fallback_mt = find_suitable_fallback(area, current_order, start_migratetype, false, &can_steal); if (fallback_mt != -1) break; } VM_BUG_ON(current_order == MAX_ORDER); do_steal: // 获得备用迁移类型对应的page_block page = get_page_from_free_area(area, fallback_mt); // 判断直接盗取(改变page_block的迁移类型), 还是借用(分配但不改变页块迁移类型) steal_suitable_fallback(zone, page, alloc_flags, start_migratetype, can_steal); trace_mm_page_alloc_extfrag(page, order, current_order, start_migratetype, fallback_mt); return true; }
- find_suitable_fallback
int find_suitable_fallback(struct free_area *area, unsigned int order, int migratetype, bool only_stealable, bool *can_steal) { int i; int fallback_mt; // 判断该order内存链表是否为空 if (area->nr_free == 0) return -1; *can_steal = false; for (i = 0;; i++) { // 遍历备用迁移类型 fallback_mt = fallbacks[migratetype][i]; // MIGRATE_TYPES表示不可用, 退出 if (fallback_mt == MIGRATE_TYPES) break; // 如果area->free_list[fallback_mt]为空, 遍历下一个备用迁移类型 if (free_area_empty(area, fallback_mt)) continue; // 判断是否可盗取 if (can_steal_fallback(order, migratetype)) *can_steal = true; if (!only_stealable) return fallback_mt; if (*can_steal) return fallback_mt; } return -1; }
- can_steal_fallback
static bool can_steal_fallback(unsigned int order, int start_mt) { // 判断order是否大于等于MAX_ORDER-1 if (order >= pageblock_order) return true; // 如果order>=(MAX_ORDER-1)/2 或者 迁移类型为MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE 或者 page_group_by_mobility_disabled=1(gdb动调发现默认为0) 则表示可以盗取 if (order >= pageblock_order / 2 || start_mt == MIGRATE_RECLAIMABLE || start_mt == MIGRATE_UNMOVABLE || page_group_by_mobility_disabled) return true; return false; }
_alloc_pages_slowpath
static inline struct page * __alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order, struct alloc_context *ac) { bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM; // PAGE_ALLOC_COSTLY_ORDER=3 const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER; struct page *page = NULL; unsigned int alloc_flags; unsigned long did_some_progress; enum compact_priority compact_priority; enum compact_result compact_result; int compaction_retries; int no_progress_loops; unsigned int cpuset_mems_cookie; int reserve_flags; // 如果内存分配标志包含__GFP_ATOMIC(来自不能阻塞或延迟和失败没有回调的原子上下文的请求), __GFP_DIRECT_RECLAIM(可以直接回收, 表示有回收需要时会阻塞请求), 明显二者冲突, 此处做一个校验 if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) == (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM))) gfp_mask &= ~__GFP_ATOMIC;
如有侵权请联系:admin#unsafe.sh