异常检测模型按照其数据样本的分布可以分为无监督模型、半监督模型和有监督模型。当已标记数据量充足的情况下,例如具有海量真实样本数据的阿里云和360,此时优先选用有监督学习,效果一般不错;当只有少数黑样本的情况下,例如有成熟安全团队的二线互联网厂商应该有一些积累,可以考虑半监督学习;当遇到一个新的安全场景,没有样本数据或是以往积累的样本失效的情况下,只有先采用无监督学习来解决异常检测问题,当捕获到异常并人工审核积累样本到一定量后,可以转化为半监督学习,之后就是有监督学习。
现实的情况是安全场景被细分,问题需要一个一个单独去解决,能够借助的资源比较有限,所以异常检测问题的开始往往是两眼一抹黑,只有业务场景和没有标记的海量数据,这时候就需要无监督异常检测模型了。
无监督异常检测模型有基于密度的异常检测、基于邻近度的异常检测、基于模型的异常检测、基于概率统计的异常检测、基于聚类的异常检测、OneClassSVM的异常检测、iForest的异常检测、PCA异常检测、AutoEncoder异常检测、序列数据的异常检测等,有点杂乱,知乎大佬总结的很好,分为五大类:统计和概率模型、线性模型、基于相似度衡量的模型、集成异常检测和模型融合、特定领域的异常检测。
统计和概率模型:主要是假设和检验。假设数据的分布,检验异常。比如对一维的数据假设高斯分布,然后将3sigma以外的数据划分为异常,上升到高维,假设特征之间是独立的,可以计算每个特征维度的异常值并相加,如果特征之间是相关的,也就变成了多元高斯分布,可以用马氏距离衡量数据的异常度。这类方法要求对问题和数据分布有较强的先验知识。
线性模型:假设数据在低维空间上有嵌入,那么无法、或者在低维空间投射后表现不好的数据可以认为是异常点。PCA有两种检测异常的方法,一种是将数据映射到低维空间,然后在特征空间不同维度上查看每个数据点和其他数据点的偏差,另一种是看重构误差,先映射到低维再映射回高维,异常点的重构误差较大。这两种方法的本质一样,都是关注较小特征值对应的特征向量方向上的信息,《机器学习-异常检测算法(三):Principal Component Analysis》这篇文章关于PCA异常检测介绍的很详细。OneClassSVM也属于线性模型。
基于相似度衡量的模型:这里的相似度衡量可以是密度、距离、划分超平面等。其中典型的当属基于局部相对密度的Local Outlier Factor,和基于划分超平面的Isolation Forest。
集成异常检测和模型融合:Isolation Forest是经典例子,判别异常的直接依据是异常点的划分超平面数远小于正常点,Isolation Forest通过数据和特征的bagging和多模型等集成学习技术增加模型的鲁棒性。
无监督异常检测模型有什么用呢?设想一种场景:正在业务发展期的一线互联网公司,安全团队初建,一切都是从头开始,主管给实习生小四设定了检测主机用户异常操作的任务,小四面临的问题有:
1、场景问题,做异常检测,那么怎么定义用户正常操作和异常操作?
2、数据问题,完全没标记样本数据积累,典型的无监督学习,只能从头自己采数据,那能获取到的数据是什么?数据量级?数据内在分布?
3、特征工程问题,因为对问题不了解,造成了对数据不了解,进而对能区分正常异常的特征提取也不了解。
4、算法选择问题,是选用基于高斯分布的统计和概率模型还是Isolation Forest一把梭,因为对问题及数据分布没有较强的先验知识,所以选取哪种算法比较好很难说清楚。
这样一看,任务就是通过无监督异常检测模型检测主机用户异常操作,梳理了一下面临以上四个问题,发现最根本的问题还是在场景问题,也就是异常操作的理解和定义。这里有两种思路,一种是即使我们不知道此业务场景面临的异常到底是什么,也要深入了解业务后根据已有的经验和知识定义异常,有针对性特征化接无监督学习,效果完全看经验,因为业务的不同,以前的经验可能很有用也可能一开始方向就错了。另一种是我们不知道异常就不知道异常,异常操作数据直接看成文本,用NLP和深度学习技术盲特征化再接入无监督算法学习,从0开始从真实环境中一点点筛出异常人工审核,抓到异常样本再去审视问题,获取先验知识,定义此业务场景下的真实异常,然后再接第一种思路,模型的话看样本数量继续用无监督或调整为半监督。第一种思路适合老师傅,实习生小四选择了第二种思路,当小四跃跃欲试的想去抓数据时,主管告诉小四线上环境不能碰,只分配一台云测试机,小四,卒。
小四只有采用迂回战术,选用公开数据集较多的URL异常检测这个场景来验证第二种思路的可行性。假设我们不知道URL异常是什么,只猜测URL数据中有异常,构造了训练集和测试集,来验证数据的维度、数量、分布对无监督模型异常检测效果的影响。

解释一下上面表格数据,(2000,0)(20000,1000)24795意思是训练集2000个白样本,0个黑样本,测试集20000个白样本,1000个黑样本,24795个特征(tfidf),第一列其他数据同理。第2、3、4列中的数据,例如41.8s|0.5175|0.494,表示模型训练时间为41.8秒,训练集准确率为0.5175(20%验证集),测试集准确率为0.494,红色标记表示按行同类型算法中最差的效果,黑色加粗表示最好效果。
观察可得出以下结论:
1、Isolation Forest较为稳定,维度和数据量对Isolation Forest的综合影响不大,无论是开销还是训练集和测试集准确率。
2、综合来看Local Outlier Factor的模型准确率最优,但是维度和数据量对lof的训练时间开销有较大影响,如果是稀疏矩阵的话例外。
3、OneClassSVM准确率性能最差,一片红,数据量也对OneClassSVM的模型训练时间开销产生很大影响,不适合处理大规模数据。
4、Robust Covariance效果一般,可能是因为采用tfidf提取的24795个稀疏特征,经过降维后得到的200维、100维、50维、10维特征的数据不满足高斯分布这个假设。Robust Covariance不适合处理高维(稀疏)特征,也没必要处理高维特征,统计得到的可能满足高斯分布的特征数量一般都还是低维范畴。
5、从数据维度和量级对训练时间开销、训练集测试集的准确率三个评价指标的综合影响来看,IsolationForest《Local Outlier Factor《Robust Covariance《OneClassSVM。
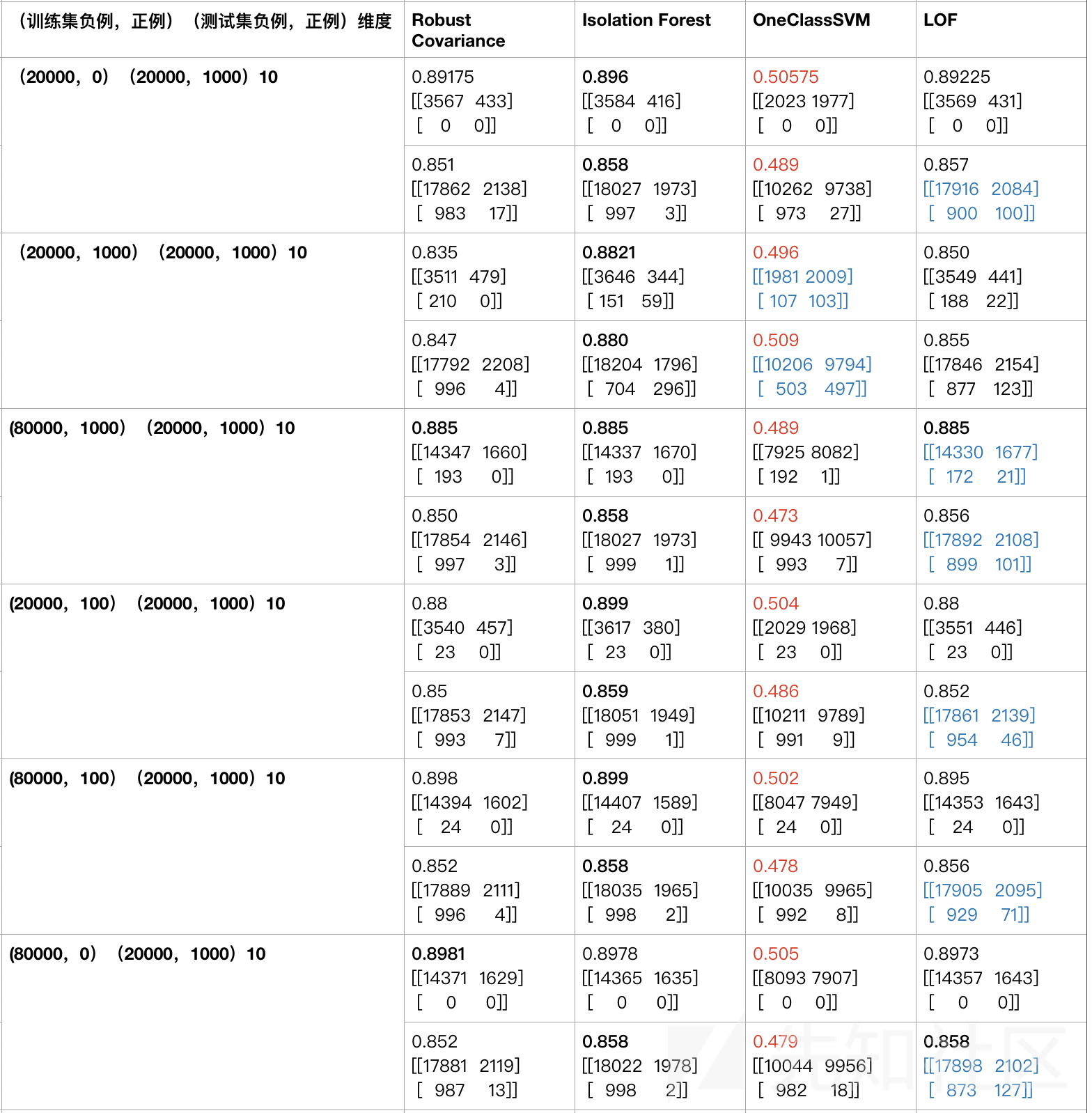
真实的环境下,一般异常非常稀疏,所以下面关注的点是模拟数据分布(正负样本比)对无监督学习模型筛选异常的影响,优先关注召回率,所以下面表格数据列出了样本混淆矩阵。

解释一下表格数据,维度10都还是由NLP的tfidf提取特征再降维到10维,黑色加粗表示按行同类型算法准确率最优,红色表示最差,蓝色标记的混淆矩阵表示检出正例(异常样本)最优。
观察表格数据可以得到以下结论:
1、不论训练集中黑样本数据的稀疏与否,Robust Covariance对异常的检出能力极差,这是因为这里的10维特征都是NLP提取并降维的,不满足高斯分布的假设前提。
2、在异常占比相对较多的情况下,Isolation Forest和OneClassSVM对异常有一定的检出能力,但是随着黑样本的稀疏,检出能力越来也差,而且OneClassSVM的准确率很低,可能不适用于真实环境中对异常的筛选。
3、LOF对异常的检出率稳定较优。
4、算法选择优先级LOF>Isolation Forest>OneClassSVM>Robust Covariance。
上面四个结论的前提都是10维特征是由tfidf自动提取的,效果总的来看较差,但是一定程度上还是能够检出异常的,当我们抓取到异常样本并人工审核后,观察样本,统计提取特征,重新看一下数据分布对无监督模型异常检测的影响。

上表中的维度10表示10个根据专家知识提取的统计特征,由上表数据可以得到以下结论:
1、无论异常稀疏与否,OneClassSVM对异常的发现能力最优,但是准确率最低,实际操作起来可行性不高。
2、当数据一定程度上满足高斯分布时,Robust Covariance在稀疏数据中检出异常效果较好。
3、Isolation Forest在稀疏数据中异常检测综合性能稳定。
4、当有相对可靠的统计特征为基底时,Robust Covariance、IsolationForest、OneClassSVM、LOF四种算法对异常的检出率都较好,尤其是Robust Covariance、IsolationForest和OneClassSVM。
5、综合来看,在专家统计特征情况下,算法选择优先级IsolationForest>Robust Covariance>LOF>OneClassSVM。
可以看到先采用NLP盲特征化发现异常样本(当我们对数据一无所知时,NLP能够直接反映数据部分内在分布),再用专家知识发现异常样本统计特征并做进一步异常检测的效果尚可,这也验证了思路二的可行性。
首先我们要意识到这个实践的局限性:
1、选用的数据集普遍偏小,最大不超过200000万条,因此不能真实反映出生产环境中极大数据量下的情况。
2、为了实践的可重复性,固定了训练集和验证集。但考虑到准确性,应该随机多次划分数据并求平均。
3、所有模型均未调参,都是模型的默认值。可能有些模型经过调参后效果有很大提升。
但即使是这样,实验结果也带来异常检测模型选择时的思路:没有普遍意义上最优的模型,具体问题需要具体分析,但有很多情况下相对稳定、较优的模型,比如Isolation Forest。
所以当面对一个全新的异常检测问题时,个人认为可以遵循以下步骤分析:
1、我们解决的问题是否有标签,如果有的话,优先选用有监督学习解决问题,如果没有的话,需要抓取样本
2、我们对数据的了解,数据分布可能是什么样的,异常分布可能是什么样的,在了解这点后,可以根据假设选择特征和模型。如果都不了解的话,可以试试NLP盲特征化处理,再选用LOF
3、可以根据数据的特点选择算法,当对数据的特点比较了解时,比如大数据集高维度可以选用solationForest,比如数据的特征值分布如果满足高斯分布可以选用Robust Covariance。如果对数据了解有限时,多试试不同的算法
4、无监督异常检测验证模型结果并不容易,可以采用TopN的方式,概率高的自动放过,概率低的人工审核
5、异常可能总是在变化,需要不断的重训练和调整策略
6、规则有时候比模型更有效,机器学习模型并不是万能的,如果有较强先验知识的话,优先选用规则,如果没有的话,可以把模型当成一种弱规则,总而言之使用交叉策略:人工规则+检测模型
7、异常检测问题能不能得到解决,客观上取决于正常和异常数据内在的不同,主观上取决于我们挖掘正常和异常数据外在的不同。
- 数据挖掘中常见的「异常检测」算法有哪些?
- Abnormal Detection(异常检测)和 Supervised Learning(有监督训练)在异常检测上的应用初探
- 八大无监督异常检测技术
- 梳理 | 异常检测
- 异常检测的N种方法,阿里工程师都盘出来了
- 异常检测初尝试
- 机器学习-异常检测算法(二):Local Outlier Factor
- 如何利用机器学习进行异常检测和状态监测
- PCA主成分分析Python实现
- 机器学习-异常检测算法(三):Principal Component Analysis
- Anomaly Detection异常检测--PCA算法的实现
- PCA and Mahalanobis Distance
如有侵权请联系:admin#unsafe.sh