说在前面
在渗透测试及漏洞挖掘过程中,信息搜集是一个非常重要的步骤。而在网站的JS文件中,会存在各种对测试有帮助的内容。
比如:敏感接口,子域名等。
社区内的文章也有有些关于JS文件提取信息的片段,比如Brupsuite和LinkFinder结合的方式,但还是有些问题:不能提取子域名,是相对URL,没那么方便等等。
于是我写了一个工具 - JSFinder。能够根据一个URL自动的收集JS,并在其中发现提取URL和子域名。毕竟,信息搜集的方式,自然是越多越好。
项目地址:https://github.com/Threezh1/JSFinder
JSFinder获取URL和子域名的方式:

使用方式
我们以京东为例来测试,京东的网址为:https://www.jd.com/
简单爬取:
python3 JSFinder.py -u https://www.jd.com/
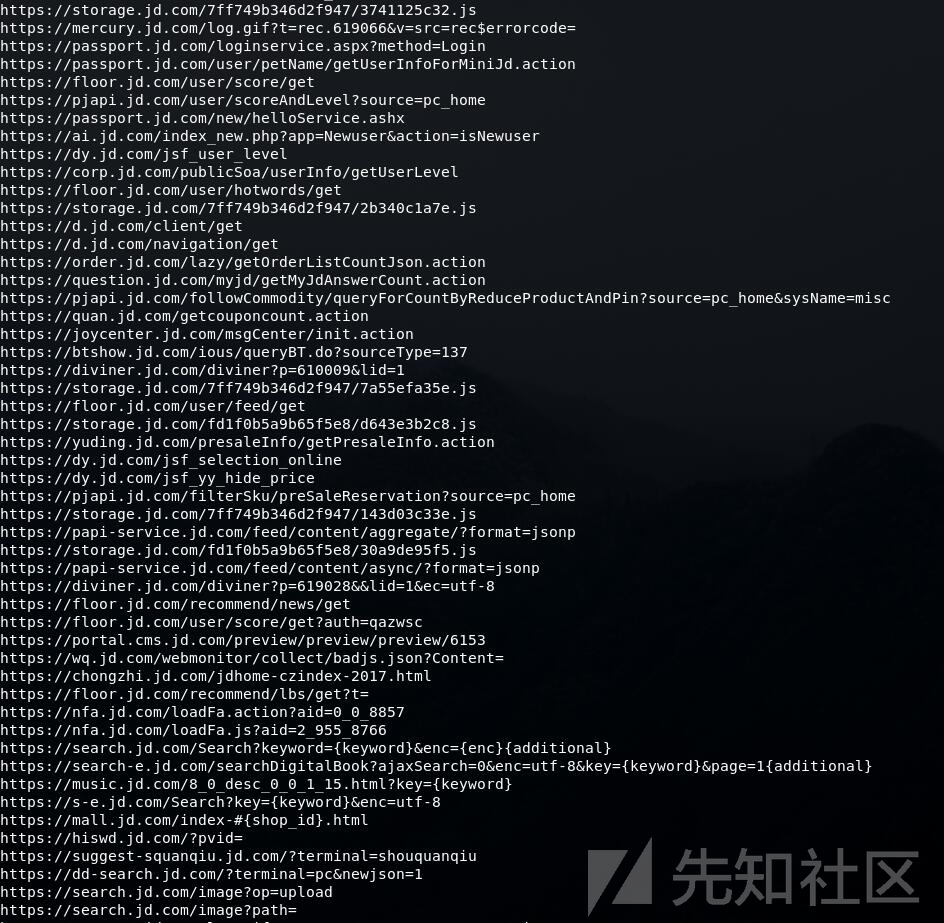
提取的URL:


提取的子域名:

打开一个像接口的URL看看

看起来是一个商品信息的接口。
只有一百多个URL和几十个子域名,远远不够。
当你想获取更多信息的时候,可以使用-d进行深度爬取来获得更多内容,并使用命令 -ou, -os来指定URL和子域名所保存的文件名。
python3 JSFinder.py -u https://www.jd.com/ -d -ou jd_url.txt -os jd_domain.txt


4019个URL,319个子域名,能够收集到的内容还是非常多的。
当然,信息的质量取决于网站,各种接口有没有用还取决于自己。
除了这两种方式以外,还可以批量指定URL和JS链接来获取里面的URL。
指定URL:
python JSFinder.py -f text.txt
指定JS:
python JSFinder.py -f text.txt -j
最后
写这个脚本的目的是为了丰富信息搜集,也是锻炼自己的编程能力。如果师傅们有更好的建议,希望能够告诉我,谢谢。
email:[email protected]
如有侵权请联系:admin#unsafe.sh