Our first engineering post covered prompt caching, the infrastructure change that made long-running 2026-6-1 18:28:0 Author: projectdiscovery.io(查看原文) 阅读量:7 收藏
Our first engineering post covered prompt caching, the infrastructure change that made long-running agentic tasks economically viable. That post assumed a multi-step, multi-agent system already existed.
It did not exist on day one.
When we started building Neo, the product was a single agent with a sandbox and a large toolset. Today, a typical task runs through optional planning, an Execution agent that delegates to parallel specialized subagents, and a verification loop that can re-run work before the user sees a final answer. Average tasks hit ~26 LLM steps and ~40 tool calls, finishing in minutes. The same architecture has carried single runs up to 14.7 hours, 2,154 steps, and 2,398 tool calls in one task.
This post is how we got there: what worked, what broke, and what we learned. If you are building agentic tools for security work, this is the path we took when single-agent design broke in production. We are not claiming every agentic product should copy it. Neo's architecture grew out of assessments that run long, carry heavy evidence, and cannot tolerate false positives at scale.
What drove Neo's evolution
Neo's architecture evolved along three axes: context, duration, and quality. Each change pushed one forward and exposed the next limit.
A security assessment isn't a chat turn. Mapping the attack surface, fingerprinting services, probing auth, attempting exploitation, and filing findings is a coordinated chain of decisions and evidence, and three forces work against it the whole way:
- Context. Each step re-sends history, and security evidence doesn't compress cleanly.
- Duration. Complex tasks run far longer than a single agent loop can sustain.
- Quality. Execution without verification produces noise, and security platforms can't afford false positives at scale.
We didn't add phases and subagents to chase a trend. The architecture evolved because context, duration, and quality kept breaking the simpler design, one at a time.
Phase 1: One agent, one machine
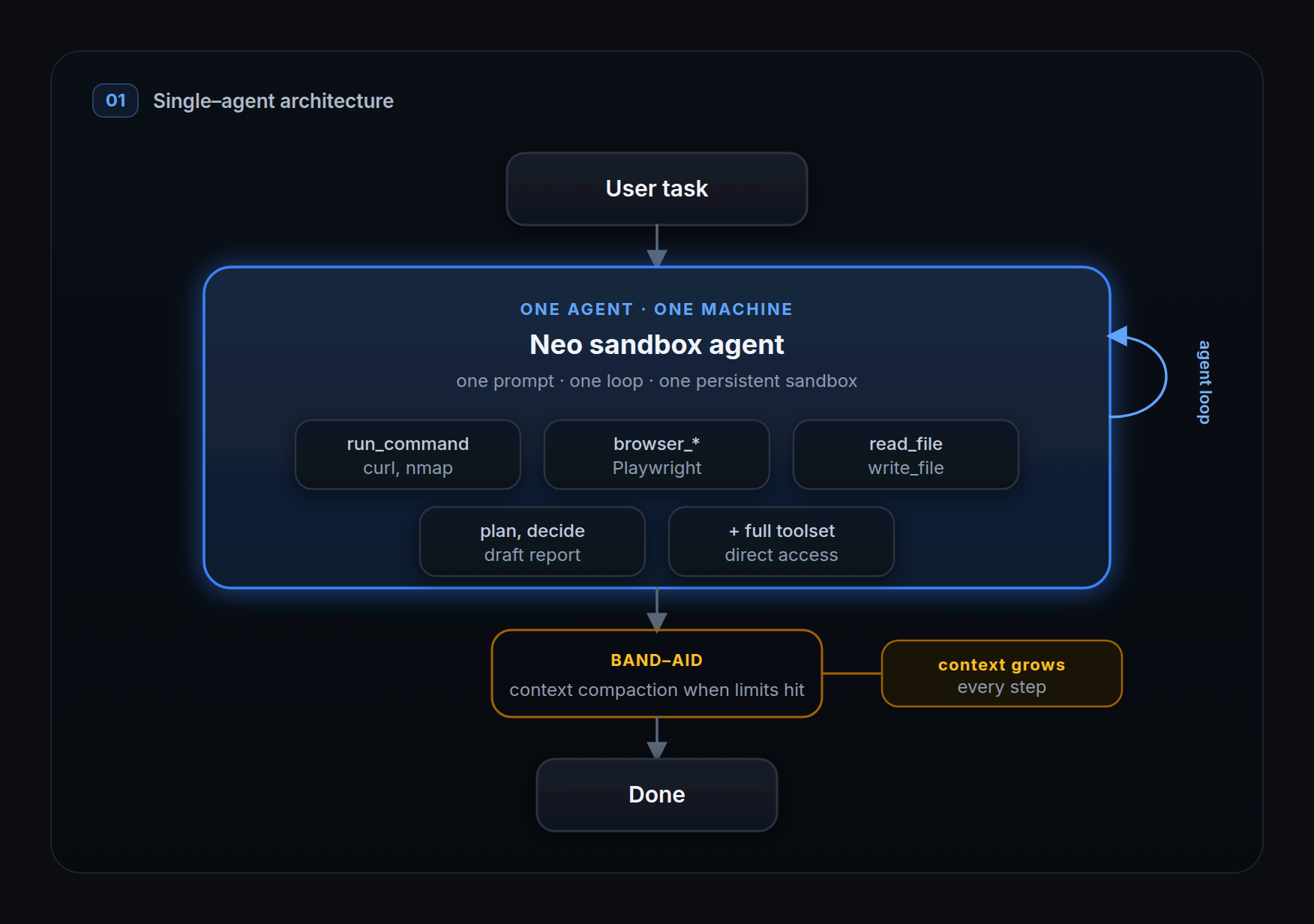
When we first started, before DEF CON 2025, we didn't want an agent that called a fixed menu of APIs. We wanted one that could drive a whole machine: run any CLI tool, write and execute its own commands and code, and wire ProjectDiscovery's OSS tools together into whatever workflow a task demanded. Security work doesn't fit a fixed toolset, so the agent has to improvise on a real shell.
Doing that safely, at scale, meant getting agent-generated code off our servers and into something disposable. So we split the system in two. An agent loop runs on our cloud and decides what to do. A separate sandbox, an isolated container, runs the commands the loop sends back. That seam is what lets us scale horizontally, one sandbox per user, and it's the same seam that will let Neo run on a user's own machine later. Each sandbox keeps a persistent filesystem, so Neo can work for hours, and when a user comes back they land exactly where they left off, with every file, artifact, and bit of state still there to build on.
What makes this powerful
Iteration was fast because the machine was real and prebuilt. We ship a custom Docker image for the sandbox with every CLI tool Neo needs already installed, plus the direct tools Neo calls to drive them, so there's nothing to mock and one place to debug. And because the box persists and is shareable, a user can open a terminal into the same machine, install or configure whatever they want, and Neo picks the task up from that exact state. The agent and the human work on the same filesystem.
Where this failed
The ceiling was context, and we hit it faster than tasks grew. A single loop with an ever-growing toolset only carries you so far: the moment a task runs long and the tool outputs pile up, you burn through the entire context window. We bought headroom with compaction based on summarization and truncation, and for simple work it held, but on complex assessments both fell apart. Compressing a conversation is fine; compressing security evidence is not.
Takeaway
A capable single agent is the right place to start, and the wrong place to stay once tasks are measured in hours instead of minutes. We didn't reach for a swarm because we read a blog post about agent networks. We reached for it because summarization kept failing us in production. It fails worst exactly when an agent produces large tool outputs: drop one critical detail from the summary and the agent loops, re-running the same tools to recover what it lost, and the problem compounds with every additional step a task requires.
Phase 2: One orchestrator & specialized subagents
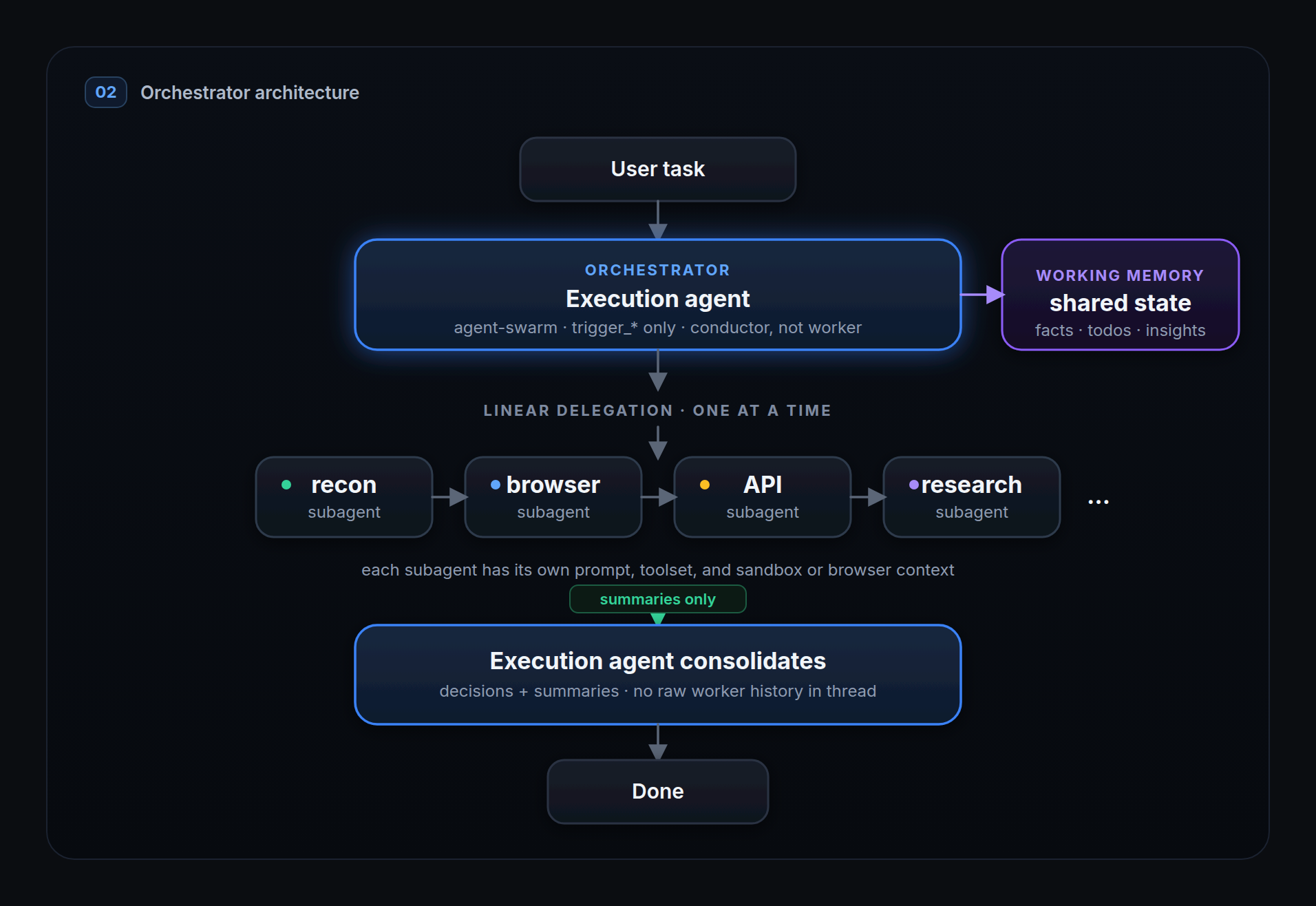
This time we restructured around specialization. Every capability Neo had became its own agent, sitting under a main orchestrator whose only jobs are task management and accumulating the final result. Instead of one loop holding everything, we now had subagents built around specific tool categories, each with its own crafted prompt: browser-agent, sandbox-agent, recon-agent, and more. The orchestrator's prompt puts the contract bluntly: "You are the conductor, not the musician." It doesn't touch run_command or browser_* directly; instead it hands each subagent a clear, scoped task and gets back a concise summary of what that subagent did.
That summary is the whole trick. The orchestrator spends its context on decisions, not raw execution detail, so a task can run far longer before the window fills. And because each capability lives in its own agent, we could write a deep, detailed prompt for each one without bloating the orchestrator, which stays focused on getting the overall task done.
The good parts of a multi-agent system
Neo could now run far more complex, multi-hour tasks reliably. We had much more room to craft tools and prompts, and the effective context window felt much larger because no single agent carried all of it. The same structure gave us flexibility at runtime: a user can pick one specialist from the UI and run it directly, or let the full swarm coordinate. Token-hungry subagents, like a browser session racking up dozens of Playwright steps, can run as long as they need without polluting any other agent's context.
It paid off for the team as much as the product. Once each capability was an isolated agent with its own prompt and tools, different people could build and own subagents in parallel, end to end, without stepping on each other. Adding a new capability no longer meant editing one giant prompt.
The issues with a multi-agent system
Specialization made iteration faster, but it moved the hard problem rather than removing it. The orchestrator is now completely dependent on what its subagents report back. If a subagent finishes without a good summary, the orchestrator never really learns what it did, and in the worst case it re-runs the same work to find out. Because all the real execution now happens inside subagents, verifying that work also got harder, and the orchestrator has to plan more carefully before it delegates anything.
We deliberately kept subagent execution sequential. Running them in parallel sounds better, but the orchestrator can't reliably tell what's independent and what has to happen in order without doing real planning first, so for now it dispatches one at a time. To close some of the context-sharing gaps, we added schema-based working memory and a dedicated exit tool that every subagent uses to hand structured results back. It helped, but there's more left to solve here.
Takeaway
The most valuable thing we learned is that agents perform far better when handed a single, clearly scoped task than a long, convoluted list of them. Every task the orchestrator delegates is picked up by a dedicated subagent and gets noticeably deeper execution than the old single-agent system ever managed. Subagents solve the context problem better than compaction alone, but they trade it for a coordination problem you have to invest in: working memory, handoff protocols, transient streaming, and structured exit tools. Without that glue, delegation just becomes expensive noise in the orchestrator's thread.
Phase 3: Parallel subagents & phased orchestration
By this point we'd learned a lot and knew what we needed to improve. There are many cases where direct, orchestration-based execution isn't efficient, and sometimes it fails outright when a task is large. If a user doesn't provide complete context in the first task prompt, we end up with an agent that burns tokens trying to fill the gaps, and may still miss the user's original intent. And there's the big problem of false positives in security work. With no dedicated verification stage, we sometimes surfaced false positives, and that was non-negotiable for us. We wanted a hard rule: declare a vulnerability only when it's verified and backed by a POC or clear evidence. To solve these problems, we split task execution into multiple phases, each with a single goal and its own specialized subagents:
Planning phase
Pre-planning lets Neo think through the entire task without executing it. It can explore multiple paths to a problem and, just as importantly, stop to ask clarifying questions instead of making assumptions (using ask_question tool). The planning phase has the full set of tools, such as sandbox, browser, and web tools, but with strict instructions to only gather intel and plan the steps needed to execute the task efficiently. By the time planning ends, we already know which steps can run in parallel and which must run sequentially, and any gaps have been raised with the user instead of guessed at. The plan is written to a dedicated file in the task's directory on the sandbox and into working memory, so the execution phase starts exactly where planning left off.
Execution phase
This phase is mostly the same as before: the main orchestrator and its subagents. The difference is that it now starts with a much more detailed prompt instead of a one-liner, and with full working memory pre-filled with the todos, insights, and plan generated in the previous phase. This helps execution run far longer, well into tens of hours.
Verification phase
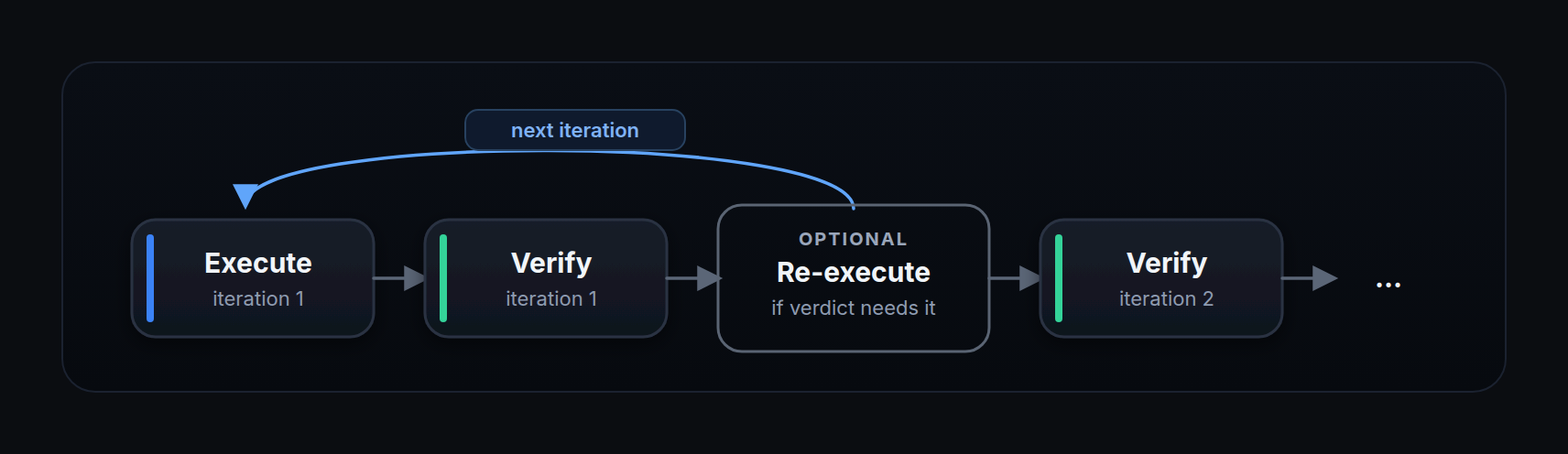
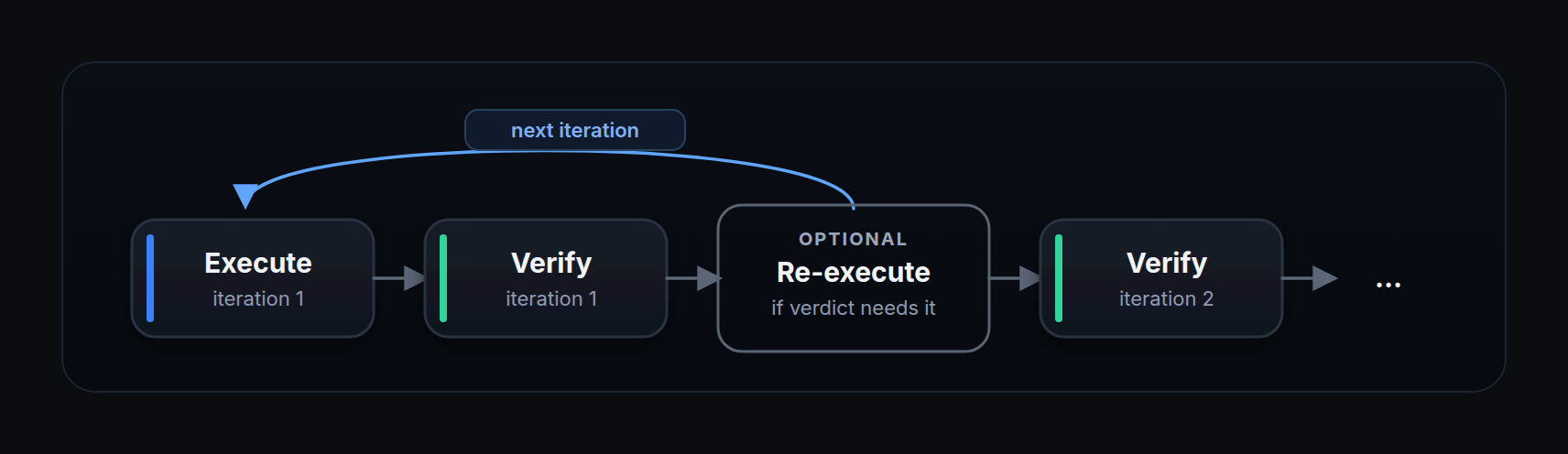
Once the planning and execution phases are done, Neo verifies all the work before sending its final response. This is its chance to validate what it did and avoid handing the user a half-baked answer. The verification phase has its own dedicated subagents. One of them, the vulnerability-verifier-agent, validates each vulnerability found during execution, generates a POC, and tracks the supporting evidence. Neo runs these subagents in parallel to verify every vulnerability separately, giving each one dedicated scope to weed out false positives before confirmed issues are written to the database through dedicated tools. At the end, the verification agent pulls together everything done in the previous phases and reaches an internal verdict on whether the user's original request was actually completed. If there's still work left, or the user asked Neo to complete a long list of tasks, the verification phase can trigger re-execution, so Neo plans and executes again over multiple iterations, controlled by max_iterations. This lets a task run for tens of hours, or even days, depending on its scope and iteration budget. We've used these long-running tasks to solve an entire CTF leaderboard in a single task that ran 14.7 hours (see the run).
Parallel execution
Across all phases, Neo uses specialized subagents in parallel to get far more done in less time. It intelligently decides what to run in parallel and what to run sequentially based on the task's requirements, and this also lets us enforce constraints, such as validating each vulnerability in a separate agent call, to greatly reduce false positives.
The task handler implements an iteration loop:
On the API side we have controls to run these phases together or separately, giving full control over Neo's task flow; on the web we expose them as Thorough mode and Fast mode. Users who want speed pick Fast mode and skip verification. Users who want rigor pick Thorough mode (plan mode in the API), which runs verification loops. Thorough mode with auto-execute runs the planner and execution agent in a single stream, so the task looks continuous in the UI while internally crossing phase boundaries. Verification still runs afterward as a separate orchestration pass, with its own step budget and tools.
What we gave up
- More phases, more failure surfaces. Suspend/resume mid-verification is intentionally unsupported. Tool approvals inside a verification loop would corrupt iteration state.
- Cross-phase context is still hard. We pass the original prompt in structured envelopes, write iteration state to working memory, and persist phase boundaries to the stream. Getting the right artifact in front of the verifier without overloading its context is still unfinished work.
- Cost. Parallel subagents and multi-phase runs consume more tokens than a single agent, even with the 84% cache hit rates we measured after shipping prompt caching. Phases buy quality and duration; caching made them affordable, not free.
Where Neo is today
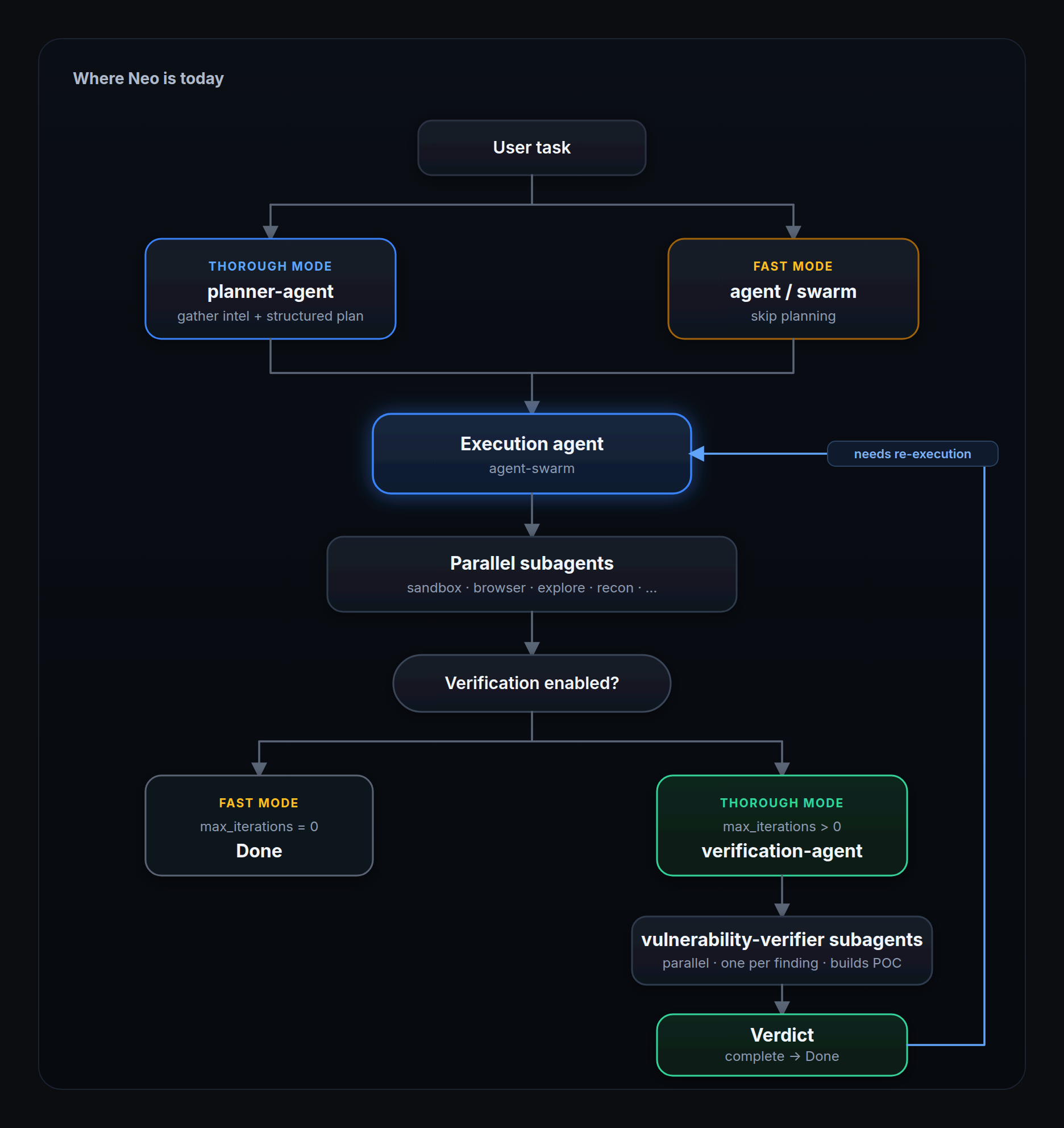
Thorough mode runs planner → Execution agent → verification. Fast mode skips planning and verification when max_iterations = 0. The diagram covers the rest.
Execution modes
| Mode | When to use | Notes |
|---|---|---|
| Direct | Known specialist | Skip the Execution agent; fastest for targeted work |
| Filtered | Partial delegation | Execution agent limited to selected subagents |
| Thorough | Broad assessments | Plan, execute, verify; shown as "Thorough" in the task UI |
| Fast | Quick, focused work | Skip planner and verification (max_iterations = 0) |
When to pick which: use Fast mode for narrow scope, familiar workflows, or quick triage where you can live with gaps. Use Thorough mode when scope is unclear, the target is complex, or false positives and missed coverage are expensive. Direct and filtered swarm apply on the execution side; Thorough and Fast control whether you plan upfront and verify afterward.
Thorough mode, verification iterations, custom subagents, and integration-triggered flows (Slack, GitHub, Linear) sit on top of these base modes.
What we learned
-
Start with one agent. You learn the domain faster. Neo's early months on a single sandbox agent taught us which tools and workflows mattered before we paid the coordination tax.
-
Split when context or duration breaks, not before. Compaction and truncation were the signals. Parallelizing before the product needs it is premature complexity.
-
Subagents trade context for coordination. Working memory, scoped persistence, handoff envelopes, and transient streaming are not optional polish. They are the glue that makes delegation work.
-
Execution and verification are different jobs. An agent optimized to "keep going" is wrong for judging whether to stop. We needed separate prompts, tools, and step budgets.
-
Parallelism belongs at the worker layer, not the orchestrator layer. Multiple orchestrators making independent decisions would fight each other. One Execution agent dispatching parallel workers scales better.
-
Architecture and cost optimization are coupled. We could not have shipped plan → execute → verify at scale without the caching work in our first post. Design phases with token economics in mind from the start.
-
We are not done. Scoped working memory, quality gates, and fast versus thorough verification are still active work.
See it in action
Plan → execute → verify, parallel subagents, verification loops: that is what runs in production on Neo today.
If you want to walk through a long-running security task on your own targets, PRs, or release workflows, request a demo.
Further reading
- How We Cut LLM Costs by 59% With Prompt Caching: the infrastructure layer that made multi-phase architecture economically viable
- Building effective agents: Anthropic's framing of workflows vs agents
Neo is ProjectDiscovery's agentic platform for security work. This is the second post in our engineering blog series covering the technical decisions behind Neo.
如有侵权请联系:admin#unsafe.sh