美团正式开源 LongCat-Video-Avatar 1.5,作为一款从开源 SOTA 迈向商业级应用的数字人视频模型。在唇形同步、物理合理性、长视频稳定性、多人互动和高效推理上实现了全面跃升。Lo 2026-5-25 00:0:0 Author: tech.meituan.com(查看原文) 阅读量:9 收藏
美团正式开源 LongCat-Video-Avatar 1.5,作为一款从开源 SOTA 迈向商业级应用的数字人视频模型。在唇形同步、物理合理性、长视频稳定性、多人互动和高效推理上实现了全面跃升。LongCat-Video-Avatar 1.5 即便在复杂商业场景里,也能稳定、自然地输出高质量内容,让数字人视频生成从彩排室的完美演练,走向千人千面的真实舞台。

为了让数字人”更稳定、更自然”地动起来,我们在以下三方面实现能力升级:
- 基础体验全面商用化:在长句、快语速、歌唱等复杂语音输入下,唇部运动更精准平滑,面部表情、头部姿态和肢体动作更协调,整体表达自然稳定;
- 支持更丰富的场景:借助高质量数据体系,模型能稳定处理真人、动漫、动物等多类主体,多人对话更加自然且准确区分说话者与聆听者;
- 推理部署更高效:采用 DMD 蒸馏至 8 步生成,效率提升约 15 倍,更适配规模化应用和真实业务场景。
开源链接
- GitHub:https://github.com/meituan-longcat/LongCat-Video
- HuggingFace:https://huggingface.co/meituan-longcat/LongCat-Video-Avatar-1.5
- Tech Report:https://github.com/meituan-longcat/LongCat-Video/blob/main/assets/LongCat-Video-Avatar-1.5-Tech-Report.pdf
- Project Page:https://meigen-ai.github.io/LongCat-Video-Avatar-1.5-Page/
- ModelScope:https://www.modelscope.cn/models/meituan-longcat/LongCat-Video-Avatar-1.5/summary
一、不止于“嘴动”,更有真实的交互力与戏剧感
1.1 音频编码器升级:让口型更精准自然
在音频特征提取环节,我们将编码器从 Wav2Vec2 升级为 Whisper-large。更大的参数量和更丰富的多语言先验,让模型能够更细致地捕捉音素变化、发音节奏和多语言韵律,准确理解”每一刻应该如何开口”。这一升级同时提升了唇形同步与全身时序稳定性——面部表情、头部姿态、肩颈和肢体动作与语音更自然地协同,大幅减少了长视频中的抖动、跳帧、画面冻结和身份漂移。
综合评测中,LongCat-Video-Avatar 1.5 的自然度、真实感和稳定性均优于部分头部闭源模型,基础生成能力满足商用需求。
1.2 高质量数据体系:让模型在复杂场景中应对更自如
商业场景中数字人形态多样(真人、虚拟偶像、动漫角色甚至动物),要求模型具备强开放域泛化能力。数据质量直接决定生成上限,为此我们构建了一套多阶段数据处理流程:
- 离线标注:提取人脸关键点、人物数量、身体构图、音画同步等属性。
- 在线验证:自动过滤转场、黑帧、闪烁、跳帧等低质量片段。

同时,我们专门构建了三类增强数据来应对虚拟人生成的典型难点:
- 多人数据:通过主动说话人检测,保留同一时刻只有单一说话人发声的片段,从源头降低多人场景的音画歧义。
- 静默数据:筛选人物未说话的视频,让模型学习无语音状态下自然的微表情、视线与身体动态,避免非说话角色嘴部乱动。
- 情绪数据:结合多模态初筛与帧级情绪识别精筛,注入情绪变化过程,使模型更好理解语音、表情与身体反应的关联。
这套数据体系为模型在复杂场景中的稳定输出奠定了坚实基础。
1.3 逐帧级 GRPO 偏好对齐:让多人交互场景更生动自然
在高质量数据的基础上,我们进一步针对手部稳定性和动作连续性进行专项优化。引入 GRPO(Group Relative Policy Optimization) 进行人类偏好对齐,将奖励信号细化到逐帧层面,精准修正动作不连贯、手部变形、短时结构崩塌及表情与语音不匹配等局部问题。
针对图像到视频和视频续写任务,我们还加入首帧手部检测机制,优先提高含可见手部样本的训练比例,显著缓解手部畸变。得益于此,模型在电商直播、产品展示、教学演示等场景中的自然度与稳定性得到进一步提升。
1.4 八步生成,效率提升十五倍
商业级数字人不仅要”像”,还要”快”。推理成本降不下来,再好的效果也只能待在实验室里。
LongCat-Video-Avatar 1.5 采用 DMD(Distribution Matching Distillation)蒸馏,将原本 50 步的生成过程压缩到 8 步。同时,我们用一个共享基础模型 + 多个 LoRA 适配器替代传统三模型并行的方案,大幅降低显存开销。
实际测试中,实现约 15 倍推理效率提升,生成 10 秒视频仅需约 1 分钟。
二、模型性能:在真实场景中验证模型能力
我们基于 EvalTalker 构建了综合评测基准,覆盖新闻、教育、娱乐、商业等场景,并按音频(语速、情绪)和视觉(人数、姿态、遮挡)设置不同难度。由 770 名评估者完成 13,240 条主观评分,并由 10 名领域专家进行结构化质量分析。


真实场景通测:雷达面积全面领先
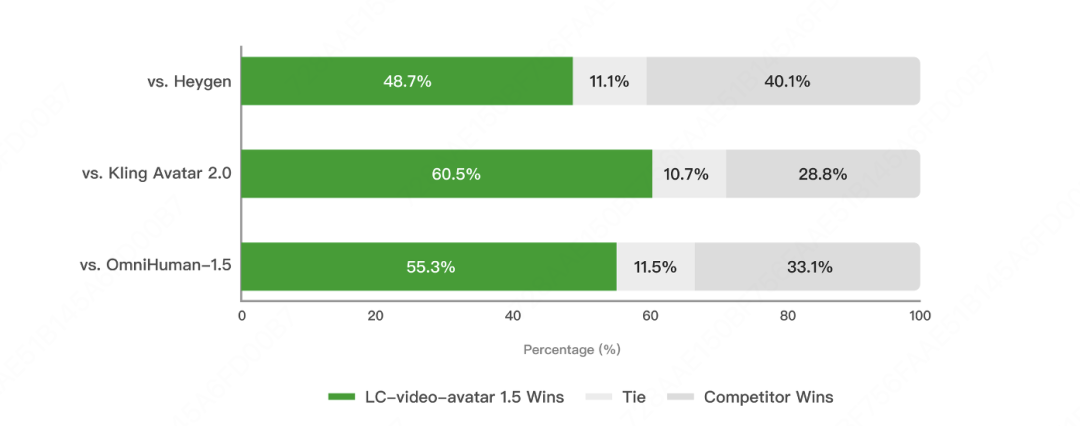
在物理合理性、时间稳定性、身份一致性和音视频协调性四个维度上,LongCat‑Video‑Avatar 1.5 的雷达图面积处于领先水平,其在画面物理合理性、时间稳定性、身份一致性和音视频协调等方面表现更均衡。在用户偏好方面,LongCat-Video-Avatar 1.5 相比 Kling Avatar 2.0 胜率 65.9%,相比 OmniHuman‑1.5 胜率 61.1%,相比 HeyGen 胜率 54.3%,整体优于其他商业系统。

单人 & 多人场景
- LongCat-Video-Avatar 1.5 单人场景得分 3.336,显著高于 HeyGen、OmniHuman-1.5 等产品;
- LongCat-Video-Avatar 1.5 多人场景得分 2.730,大幅领先 InfiniteTalk(2.339),在说话者/聆听者区分上优势明显。
物理合理性与长时序稳定性
- 在主体变形和背景变形等问题上,主体变形问题率仅为 23.1%,低于所有对比模型;背景变形问题率为 9.4%,整体保持在较低水平。
- 在画面跳帧、色调误差累积等指标上,LongCat-Video-Avatar 1.5 表现稳定,其中跳帧问题率仅为 0.8%,是所有对比模型中最低,模型在长视频连续生成中能够更好地保持画面流畅性。
音视频协调
在面部-身体同步和唇形同步方面,LongCat-Video-Avatar 1.5 同样取得最佳表现。面部-身体同步问题率为 5.1%,唇形同步问题率为 29.8%,均低于其他对比模型,说明模型在说话人的音频、唇形、表情和动作的整体协同上更加自然。
整体来看,LongCat-Video-Avatar 1.5 在效率提升的同时,仍保持了高质量的生成能力。不仅在单人场景的自然度和真实感上保持 SOTA 表现,也在多人互动、长时序稳定性、物理合理性和音视频协调性等关键维度上展现出更强的商用潜力。
三、开源是为了走向更真实的场景
LongCat-Video-Avatar 1.5 的开源,不只是模型版本的更新,更是面向开发者和创作者的邀请。
数字人视频生成正在从”展示效果”走向”真实使用”。在这个过程中,模型会遇到更多开放场景:不同角色、不同语言、不同内容形态,以及更复杂的业务需求。我们希望 LongCat-Video-Avatar 1.5 能成为一个可验证、可改进、可共建的技术基座,让更多人基于它探索数字人视频的真实应用边界。
模型和代码已经开放。欢迎大家在自己的场景中使用、测试和反馈,也期待和社区一起,把开源数字人视频模型继续向前推进。
开源链接
- GitHub:https://github.com/meituan-longcat/LongCat-Video
- HuggingFace:https://huggingface.co/meituan-longcat/LongCat-Video-Avatar-1.5
- Tech Report:https://github.com/meituan-longcat/LongCat-Video/blob/main/assets/LongCat-Video-Avatar-1.5-Tech-Report.pdf
- Project Page:https://meigen-ai.github.io/LongCat-Video-Avatar-1.5-Page/
- ModelScope:https://www.modelscope.cn/models/meituan-longcat/LongCat-Video-Avatar-1.5/summary
| 关注「美团技术团队」微信公众号(meituantech)或访问:https://tech.meituan.com/,阅读更多技术干货!

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 [email protected] 申请授权。
如有侵权请联系:admin#unsafe.sh