written on May 24, 2026 Pi is now part of Earendil, but in the important se 2026-5-24 00:0:0 Author: lucumr.pocoo.org(查看原文) 阅读量:8 收藏
written on May 24, 2026
Pi is now part of Earendil, but in the important sense it is still Mario’s project. He has been living with its issue tracker longer than I have, and he has been exposed to the weirdness of the new form of agent traffic in Open Source projects for longer too. This post is mostly a reflection of my own experience after spending more time in the tracker, using Pi to work on Pi, and watching what I have learned about it so far.
Slop Issues
Unsurprisingly, we are using Pi to build Pi. That sounds like a cute dogfooding thing but it really helps understand what we do. An interesting effect of building with agents is that it changes the role of the issue tracker a tiny bit. The issue descriptions are not just messages from a user to a maintainer because we also use them as inputs for prompts in Pi sessions. It is something I might hand to my clanker1 and say: “understand this, reproduce it, inspect the code, and propose a fix.”
That means the shape of the issue matters in a new way. A bad issue was always annoying, but at least a lot of issues were vague. Now we are also dealing with a class of issues that are 5% human and 95% clanker-generated and largely inaccurate shit. A bad issue that contains a plausible but wrong diagnosis creates extra work.
The most frustrating failure mode right now is that people submit issues that are not in their own voice. They contain an observed problem somewhere, but it has been thrown into a clanker and the clanker reworded it and made a huge mess of it. Typically, it was prompted so badly that the conclusions produced are more often than not inaccurate but always full of confidence. The result is complete guesswork on root causes, fake-minimal repros, suggested implementation strategies, analogies to adjacent but often the wrong code, and long lists of error classes that might or might not matter.
That is worse than no diagnosis.
I don’t want to point to specific issues because I really do not want to bad
mouth anyone, but it is frustrating. It is also frustrating because when I give
that issue to Pi, Pi sees the wrong diagnosis too. It does not treat the issue
body as a rumor. It treats it as evidence. It will happily go down the path
that the issue already prepared for it, because the prose is confident and the
code references look plausible. We use a custom slash command called /is,
which specifically has this instruction in it:
Do not trust analysis written in the issue. Independently verify behavior and derive your own analysis from the code and execution path.
Unfortunately, it does not fully work, because when humans first throw their issue through the clanker wringer, their clanker expands scope almost immediately. What was once a very narrow and fact based bug observation, turns into a much expanded surface area full of hypotheses. So at least personally, I increasingly want issue reports to be condensed to what the human actually observed:
- I ran this command.
- I expected this to happen.
- This happened instead.
- Here is the exact error or log.
That is enough. If you used an LLM to understand the problem, great, maybe leave it as a follow-up comment. But the issue and the issue text should be something you own. If you do not know the root cause, say that. I too can operate a clanker, and I would rather do this myself than use your slop. If your repro is a guess, say that. If the only hard fact is one stack trace, give me the stack trace and stop there.
Slop Begets Slop
That we’re seeing issues full of slop is just a result of the present day quality of these machines. Sadly, their failures in creating good issues extend to a lot of code that is generated. Not all of it, but a lot of code. Over and over I keep running into them over-engineering the hell out of issues and implementations.
If you tell them that “this malformed session log crashes the reader,” the clanker will often add a tolerant reader. Then it will add a fallback, then maybe a migration, then more debug output, then a test for all of this. None of this is necessarily wrong in isolation, but it can be the wrong move for the system.
At Pi’s core is a rather well-designed session log with invariants that must be upheld. The clanker’s present-day behavior is to just assume that no such invariants exist, and instead to make the system work with all kinds of malformedness, blowing up the complexity in the process.
Almost always, the correct fix is not to handle the bad state, but to make the bad state impossible. This matters a lot for persisted data such as Pi session logs. They are opened, branched, compacted, exported, shared, and analyzed. The goal here is to never write bad session data. Yet if you just let the clanker roam freely, it will attempt to handle every case of bad data in the session log with a more permissive reader.
I have complained about this plenty, but working on Pi’s code base continues to reinforce the point. This is one of the ways LLM authored code grows so much needless complexity. All these models see a local failure and try to locally defend against it. As maintainers we have to keep pulling the conversation back to the global invariant, which is harder than it should be, and it’s laborious.
Volume Is The Problem
Then there is the issue of volume. The tracker is receiving a lot of issues and PRs, and a significant fraction of them are clearly LLM-assisted. Some are good, none are excellent, and most are just bad. The total throughput is a maintenance problem by itself.
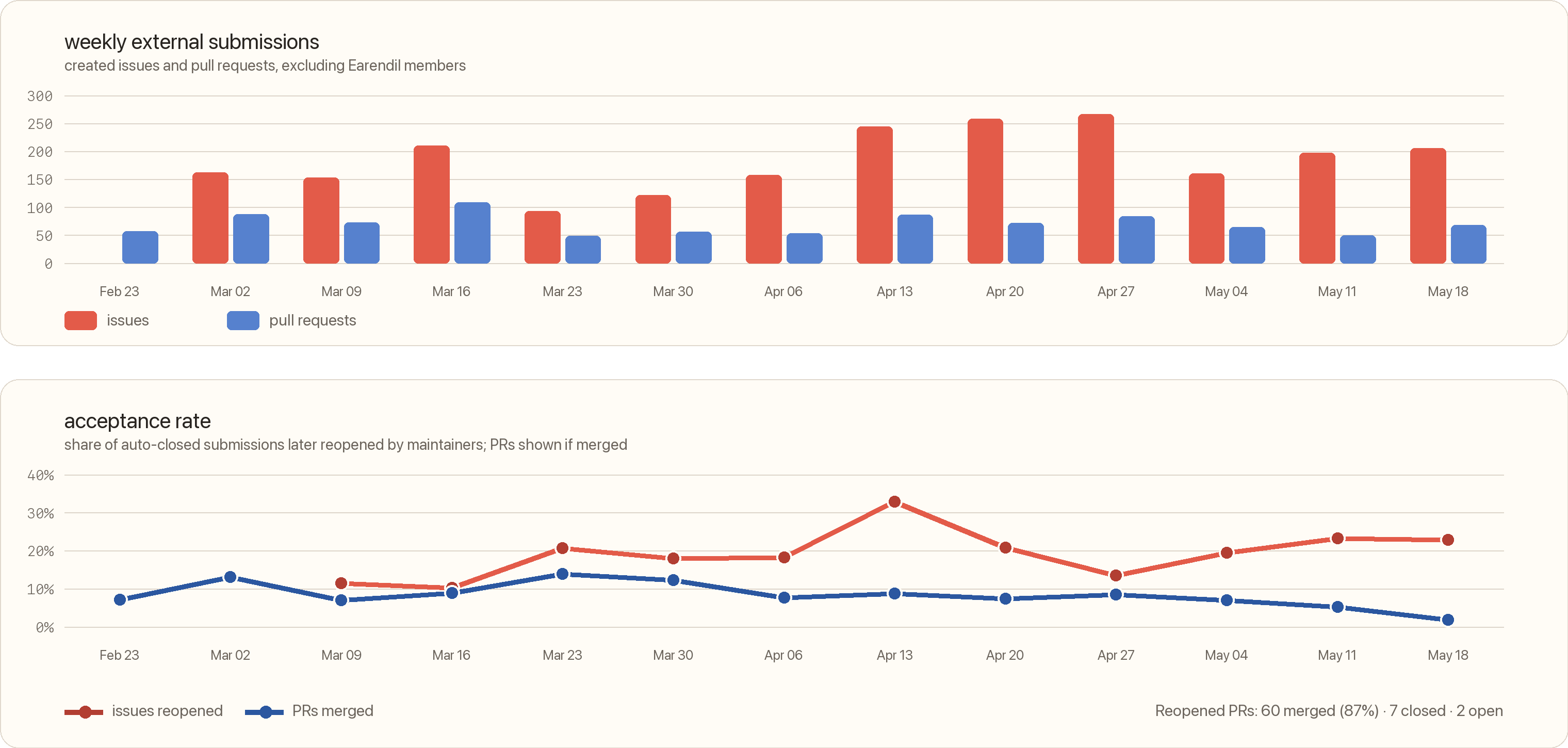
As you might know, Pi’s issue tracker is automated to close all issues and pull requests from new contributors, and there is a manual process by which we might reopen some of them or approve individuals. So auto-close -> reopen -> close again is an interesting statistic for us to look at.
I pulled the public GitHub tracker data while writing this over the last 90 days. Excluding Earendil members, that leaves 3,145 external issues and pull requests. Of those, 2,504 were auto-closed because they were from non-approved individuals. 17% were reopened. For pull requests the number is worse: less than 10% were merged.
![]()
Many of the issues and PRs are complete slop and in some cases the humans did not even realize that they created them. Sources of low-quality spam include OpenClaw instances, as well as some skills that people put into their context that seemingly encourage issue creation.
GitHub clearly is not built to deal with this new form of Open Source, but I’m increasingly feeling the need to put the blame less on GitHub than on all the people involved who make that experience painful. If your clanker shits on someone else’s issue tracker then it’s not the fault of GitHub, it’s yours alone.
Careful Parallelism
Pi might be built with Pi, but we’re quite far off today from where Bun and OpenClaw already are: fully detached, automated software engineering. Maybe we will reach that point, I don’t know. Today it does not seem like we know how to pull off a dark factory and we also don’t yet have the desire. That said, there is quite a bit of parallelism going on, and it is mostly for reproducing issues.
The small setup we use for this is three tiny pieces in Pi’s own committed
.pi folder. /is (for
analyze issue) is a prompt for analyzing GitHub issues: it labels and assigns
the issue, reads the full thread and links, then explicitly tells the agent not
to trust the analysis in the issue and to derive its own diagnosis from the
code. Then an extension adds a prompt-url-widget which watches the prompt
before the agent starts, recognizes the GitHub issue or PR URL that /is (or
the PR equivalent) put into the prompt, fetches the title and author with gh,
renders that in a little UI widget, and renames the session. It also rebuilds
that state on session start or session switch, so if we reopen an older
investigation the window still tells the developer which issue it belongs to.
In practice this means it’s possible to have several Pi windows open, each
running /is against a different issue, and the UI keeps the investigations
visually distinct while the agents do their independent reproduction and code
reading. Once the investigations are done, one can work through them
sequentially. To finish off everything, /wr (wrap it up) is the matching
wrap-up prompt: it infers the GitHub context from the session, updates the
changelog, drafts or posts the final issue comment with a disclaimer, commits
only the files changed in that session, adds the appropriate closes #... when
there is exactly one issue, and pushes from main.
Open Source Is About Hard Problems Worth Fixing
You will have noticed this already but Open Source in a post-AI world is under a strange new pressure. We are getting more code, more projects, and more issues. Projects appear with no real users, or a temporary audience of one, and even projects with thousands of stars can have a shelf life of weeks.
For us, Pi’s harness layer is worth maintaining carefully because it solves hard coordination problems and creates a platform we and others can build on. We also know that coordination and cooperation lifts us all up. Many times the right answer is not to work around a problem locally, but to make the upstream behavior correct. Mario has been very good at refusing to make Pi paper over every misconfigured gateway, and we’re trying to preserve that discipline. When a gateway behaves correctly, everybody benefits.
Sadly that type of thinking is quickly disappearing because these machines make local workarounds cheap, so code accumulates local defenses against every misbehavior. Instead of humans talking to humans about where a fix belongs, one human and one machine work around the problem in isolation.
Keep in mind that AI has not increased the number of people who need software, or the number of maintainers who can review it. It has mostly increased the amount of code and the number of projects competing for attention. Some of that is healthy, but a lot of it fragments effort that should be shared.
We need stronger foundations, not weaker ones. Open Source needs more collaboration, not more isolated work with a machine. Human communication is hard, and it is tempting to avoid it when you can sit alone with your clanker. But isolation is not where Open Source derives its value. The value is in the community and the structure that lets projects outlive their original creators.
This entry was tagged ai, open-source and pi
如有侵权请联系:admin#unsafe.sh