Per condurre con successo un attacco di data poisoning su un modello di machine learning non è neces 2026-5-22 07:23:24 Author: www.cybersecurity360.it(查看原文) 阅读量:5 收藏
Per condurre con successo un attacco di data poisoning su un modello di machine learning non è necessario alterare grandi quantità di dati.
Studi sperimentali hanno dimostrato che è sufficiente modificare lo 0,1% del dataset di addestramento per ottenere effetti misurabili sul comportamento del modello.
Le pipeline di data management per l’AI presentano numerose superfici di attacco durante il transito, quando sono a riposo, durante l’etichettatura e durante la composizione dei dataset, senza dimenticare che vi accedono una pluralità di soggetti che potrebbero diventare un insider threat.
Una volta avvenuto, l’avvelenamento è difficile da rimediare.
Il riaddestramento integrale è oneroso e le tecniche di machine unlearning sono ancora in fase di sviluppo.
La prevenzione strutturale, tramite una chain of custody crittografica, è una strategia preferibile rispetto alle difese su base statistica implementate a posteriori.
L’attacco di data poisoning
La soglia oltre la quale un attacco di data poisoning produce effetti significativi sul comportamento di un modello di machine learning è sorprendentemente bassa.
La letteratura documenta che la modifica dello 0,1% del dataset di addestramento (cinquanta immagini su cinquantamila, come in un noto caso di studio [2]) è sufficiente per indurre il modello ad apprendere associazioni distorte, manifestare backdoor latenti o ridurre in modo selettivo le proprie prestazioni.
Questo dato, che dovrebbe indurre alla riflessione il professionista della sicurezza, si scontra con la realtà industriale, in cui le pipeline di gestione dei dati sono raramente progettate con la stessa cura dedicata alle infrastrutture di rete o ai sistemi di gestione delle identità.
Il contributo, pubblicato nel mese di aprile 2026 da Renae Metcalf e Matt Churilla [1], pone il problema in termini operativi, avanzando una tesi netta: la difesa contro l’avvelenamento dei dati di addestramento non può essere demandata a meccanismi probabilistici applicati a posteriori, ma richiede un’architettura preventiva ispirata al principio del chain of custody.
Lo strumento, mutuato dalla giurisprudenza che documenta la catena di possesso di un elemento di prova, viene riformulato in chiave crittografica e applicato al ciclo di vita dei dati che alimentano un sistema di IA.
Questo articolo riprende la proposta di Metcalf e Churilla, la inserisce nel più ampio contesto della sicurezza dei sistemi AI e ne discute le implicazioni operative.
Si analizzano la natura del data poisoning, le superfici di attacco lungo il ciclo di vita dei dati, l’architettura della chain of custody crittografica e le sue alternative.
Data poisoning di un dataset
Si parla di data poisoning quando un insider o un avversario esterno modifica i dati di addestramento di un modello di machine learning con l’intento di influenzarne il comportamento o di peggiorarne le prestazioni. L’attacco può assumere molteplici profili.
Nella sua forma più elementare, l’attaccante modifica direttamente il contenuto dei dati, come i pixel di un’immagine, il testo di un documento o i valori di un record, con l’obiettivo di indurre il modello a imparare correlazioni errate.
In una versione più sofisticata, l’attaccante non modifica i dati, ma manipola le etichette, approfittando del fatto che la fase di interpretazione è spesso meno controllata di quella di acquisizione.
Tra le conseguenze pratiche vi sono l’introduzione di bias sistematici, l’occultamento di pattern critici (un sistema di rilevamento del traffico malevolo addestrato a non riconoscere una specifica firma), l’iniezione di vulnerabilità latenti nel codice prodotto da un agente di sviluppo basato su large language model.
L’aumento delle dimensioni dei modelli e dei dataset ha reso impraticabile l’etichettatura manuale di tutti i dati di addestramento.
La transizione dal machine learning supervisionato a quello semi-supervisionato e l’affermazione del paradigma non supervisionato per i modelli linguistici hanno modificato il profilo della superficie di attacco senza ridurla.
Anzi, nei contesti non supervisionati, in cui il modello apprende le statistiche
di distribuzione sull’intero corpus, anche piccole alterazioni mirate possono propagarsi in modo non immediatamente individuabile.
La scala stessa dei dataset di addestramento dei foundation model, dell’ordine di terabyte e miliardi di documenti, rende impossibile una verifica esaustiva di ogni singolo elemento.
Perché è difficile correggere un modello compromesso
Una caratteristica che differenzia il data poisoning da molti altri vettori di attacco è la difficoltà della sua remediation.
Una volta che un dato compromesso è stato incorporato nel processo di addestramento, le sue conseguenze risiedono nei pesi del modello in forma distribuita e non localizzabile.
La remediation naturale, ovvero il riaddestramento del modello su un dataset depurato, richiede risorse computazionali ed economiche spessoproibitive, soprattutto per i modelli di grandi dimensioni.
Le tecniche di machine unlearning [3], oggetto di ricerca attiva, mirano a rimuovere selettivamente l’influenza di specifici elementi senza dover ripartire da zero, ma presuppongono di sapere con precisione quali dati siano stati compromessi e si scontrano con difficoltà teoriche legate alla non identificabilità dell’influenza individuale nei modelli ad alta capacità.
Da questa asimmetria ovvero dalla facilità dell’attacco e dalla difficoltà di rimediare, deriva la motivazione principale per cui è preferibile concentrarsi sulla prevenzione strutturale piuttosto che su una risposta a posteriori. Questa asserzione è la premessa che giustifica l’adozione di una catena di custodia crittografica.
Il ciclo di vita dei dati
Per stimare l’entità della superficie di attacco, è utile considerare un esempio concreto.
Immaginiamo un sistema di visione artificiale destinato al riconoscimento e alla classificazione di oggetti rappresentati in immagini acquisite da una fonte come un drone o un sistema satellitare.
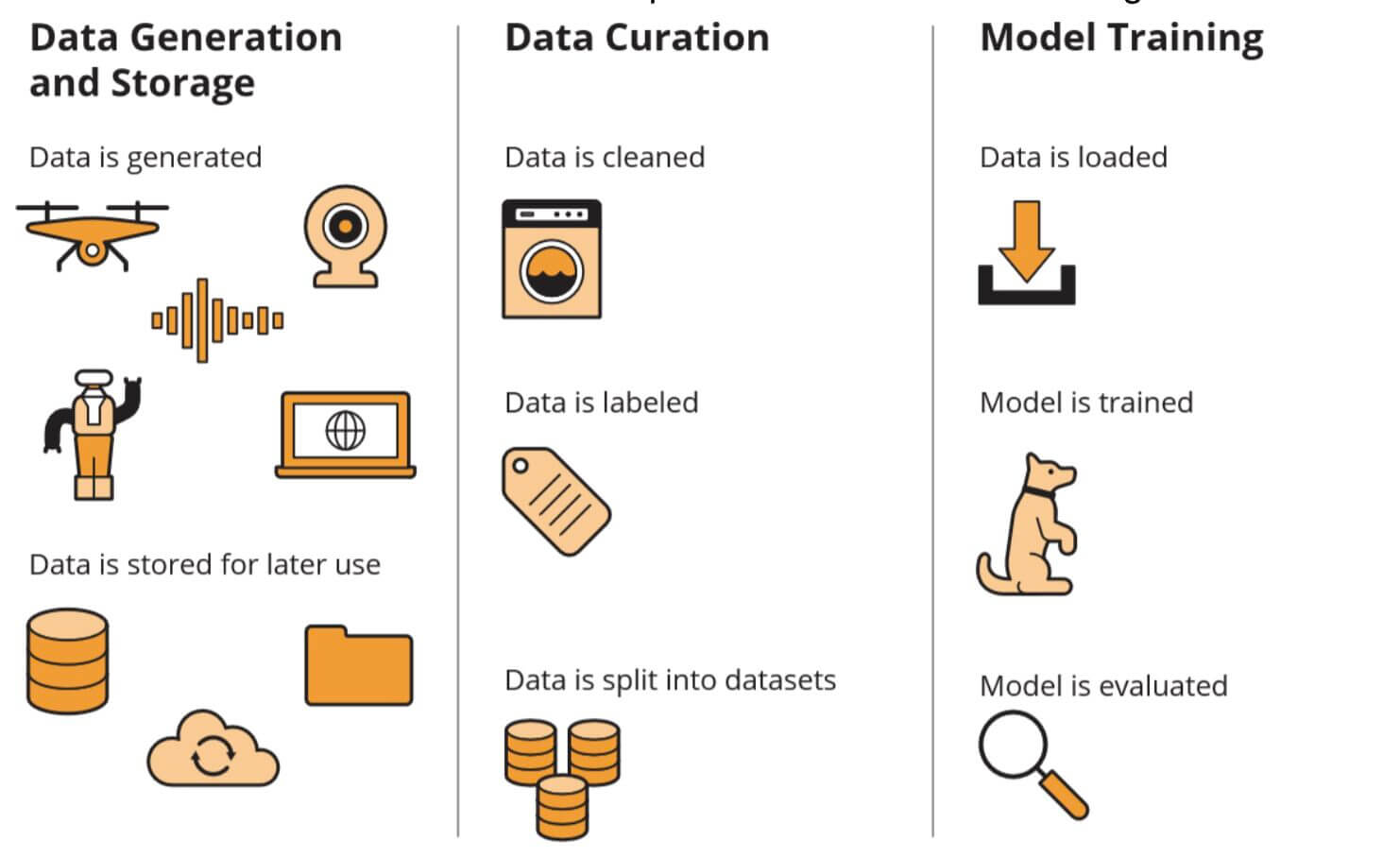
Il ciclo di vita dei dati attraversa tre fasi principali: generazione e archiviazione, catalogazione, addestramento del modello e sua valutazione.
Nella prima fase, il sistema acquisisce le immagini, le memorizza in locale e
successivamente le trasferisce a un repository centralizzato.
Ogni fase – acquisizione, memorizzazione locale, trasferimento e archiviazione finale – rappresenta uno stato in cui i dati sono a riposo o in transito e, pertanto, potenzialmente alterabili.
Un esempio classico è l’attacco on-path durante il trasferimento dalla sorgente al repository: l’attaccante non deve compromettere né il dispositivo di acquisizione né il sistema di archiviazione, ma deve solo intercettare il flusso e modificarne il contenuto in transito.
Trattamento e catalogazione dei dati
Nella seconda fase, i dati vengono trattati e catalogati. Il processo include la pulizia (ridimensionamento delle immagini, normalizzazione dei formati e rimozione degli artefatti), l’annotazione (assegnazione di etichette che costituiranno la ground truth per il modello) e la composizione dei dataset per l’addestramento e il test.
Ogni sotto-fase coinvolge tipicamente operatori diversi: un data engineer per la pulizia, un esperto di dominio per l’annotazione e un altro data engineer per la composizione dei dataset.
Ognuno di essi rappresenta una potenziale minaccia interna. Di conseguenza, la superficie di attacco si moltiplica e diventa possibile alterare un’immagine, un’etichetta o un dato lasciando intatto il resto, oppure spostare un dato dal set di addestramento a quello di test e viceversa.
Il processo di addestramento
Nella terza fase, i dati elaborati alimentano il processo di addestramento. Anche in questo caso, i dati vengono caricati in memoria, elaborati in batch e, se necessario, integrati con tecniche di data augmentation.
Una compromissione del data loader o un’alterazione delle pipeline di augmentation può introdurre distorsioni che si manifestano solo nel modello finale, ovvero alla fine di tutta la pipeline.
In assenza di meccanismi di verifica end-to-end, risulta estremamente complesso effettuare un’analisi forense a posteriori.
La chain of custody crittografica: i 3 strumenti
Il concetto di chain of custody non è nuovo. In ambito legale, la catena di custodia documenta senza soluzione di continuità chi ha custodito un elemento di prova, in quale momento e con quale finalità; la sua integrità è una condizione necessaria affinché la prova possa essere ammessa in un procedimento giudiziario.
Da questo dominio originario il principio si è esteso alla digital forensics e al supply chain management.
La proposta di Metcalf e Churilla consiste nell’applicare questa tecnologia, con l’ausilio della crittografia, ai dati che alimentano i sistemi AI.
Dal punto di vista tecnico, la catena di custodia crittografica si basa su tre strumenti:
- il checksum ovvero un’impronta digitale calcolata sul contenuto di un dato (o di un gruppo di dati) tramite una funzione hash crittografica: qualsiasi modifica del contenuto, anche minima, produce un checksum diverso e pertanto rilevabile;
- la firma digitale, che lega in modo non ripudiabile un’operazione (la creazione, la modifica o l’approvazione di un dato) a un soggetto identificato;
- il registro di log, dove ogni operazione viene annotata in forma append-only, idealmente su strutture dati che ne preservino l’immutabilità, come i ledger crittografici, sistemi di event sourcing con firma incrementale, database con proprietà di journaling.
La fiducia risiede nel calcolo matematico
Le caratteristiche di queste primitive consentono di registrare, per ogni elemento del dataset e in ogni fase del ciclo di vita, un manifest verificabile contenente:
- i metadati pertinenti al dominio (sorgente, timestamp, parametri di acquisizione);
- i metadati specifici del file (formato, dimensioni, fingerprint);
- l’identità dell’operatore o del sistema che ha eseguito l’azione;
- le firme digitali di approvazione e i checksum di integrità.
La verifica della catena di custodia, in qualsiasi punto della pipeline, consiste nel ricomputare i checksum e nel validare le firme rispetto alle chiavi pubbliche degli operatori autorizzati.
Nel momento in cui la verifica fallisse, l’elemento verrebbe considerato compromesso e la pipeline si arresterebbe o lo isolerebbe dal resto. Il valore aggiunto di questa tecnologia rispetto a un sistema di log tradizionale risiede nella natura crittografica della verifica.
A differenza di un log testuale, che può essere alterato da chi controlla il sistema di log stesso, un manifest firmato espone qualsiasi tentativo di manipolazione, anche successivo.
Questo principio sfrutta la stessa logica dei meccanismi di firma del codice e delle reti basate sui certificati: la fiducia non è più riposta nel processo, ma nel calcolo matematico.
Il workflow di protezione in dettaglio
Per comprendere il funzionamento della chain of custody crittografica, è utile seguire il dato lungo tutto il suo ciclo di vita, evidenziando dove avvengono le verifiche e dove sono collocate le firme in ciascuna fase del processo di machine learning.

Data Generation e Storage
Il principio fondamentale è che la firma del dato debba avvenire il più vicino possibile, nel tempo e nello spazio, al momento della sua generazione. Nell’esempio citato, il dispositivo di acquisizione dovrebbe disporre di una chiave privata univoca, custodita in un componente sicuro, con la quale firmare ogni immagine prodotta non appena questa viene scritta sulla memoria.
Contestualmente alla firma viene calcolato il checksum dell’immagine e dei suoi metadati.
La firma e il checksum costituiscono il primo anello della catena e attestano che l’immagine, con il suo contenuto specifico, è stata generata da quel dispositivo in quel preciso istante.
Nella fase successiva di archiviazione ovvero nel trasferimento dei dati dalla sorgente al repository centrale, entra in gioco un componente automatico, il data loader, che a sua volta firma il record di trasferimento.
Il record include il riferimento al dato trasferito (tramite il suo checksum), l’identità del componente che ha eseguito il trasferimento, l’istante e la destinazione.
Un’eventuale alterazione del file durante il transito viene rilevata immediatamente al momento della scrittura sul repository, attraverso il confronto tra il checksum originale e quello del file ricevuto.
Data curation
La fase di data curation è quella in cui la chain of custody dimostra la propria utilità in maniera più evidente, in quanto è la fase in cui l’intervento umano è più intenso ed è quindi la più esposta al rischio di insider threat.
Inoltre, la normalizzazione di un’immagine, come il ridimensionamento alla risoluzione nativa della pipeline di addestramento, genera un elemento nuovo, distinto dall’originale, che deve essere a sua volta firmato e tracciato. Il manifest della nuova versione registra il riferimento all’originale, l’identità del data engineer che ha eseguito la trasformazione, lo strumento utilizzato e il nuovo checksum del file risultante.
La specificità dell’etichettatura
L’etichettatura segue una logica analoga, con una specificità importante: in questa fase, infatti, il contenuto del dato non cambia, ma viene associato a una ground truth.
Il manifest registra dunque l’identità del classificatore, l’etichetta o il set di etichette assegnate e firma l’associazione. In questa fase si manifesta uno dei vettori di attacco più insidiosi documentati in letteratura: l’alterazione delle sole etichette, lasciando intatti i dati.
La catena di custodia rende riconoscibile anche questo tipo di attacco, in quanto la firma vincola l’etichetta a un classificatore specifico e una manipolazione successiva o un’annotazione effettuata da soggetti non autorizzati produce una verifica negativa.
Il momento in cui la verifica end-to-end diventa indispensabile è composizione dei dataset. Prima di assemblare un training set, il sistema deve verificare la chain of custody di ciascun elemento candidato, ricostruendo all’indietro la sequenza di firme e checksum dalla generazione fino allo stato corrente.
Se ogni anello della catena risultasse integro, l’elemento verrebbe ammesso nel dataset; in caso contrario, il sistema segnalerebbe un errore agli amministratori e attiverebbe una procedura di analisi forense.
Una volta verificato e approvato, il dataset ottiene un firma da paete del data engineer responsabile, che ne certifica il contenuto in quella specifica configurazione.
Model Training e Evaluation
Il principio della chain of custody-awareness si estende anche ai data loader impiegati durante il training.
Ogni batch di dati caricato in memoria deve essere sottoposto automaticamente alla verifica delle firme e dei checksum.
l modello prodotto al termine del processo viene a sua volta firmato e corredato da un manifest che documenta i dati di training.
Questo manifest, conservato insieme al file del modello, abilita due proprietà fondamentali:
- in primo luogo, le nuove istanze del modello in produzione potranno verificare la propria provenienza prima dell’esecuzione, garantendo che il modello caricato sia esattamente quello prodotto dalla pipeline autorizzata;
- in secondo luogo, in caso di incidente, gli analisti forensi disporranno di un log auditable e crittograficamente verificabile dell’intero processo, dalla fonte dei dati fino al modello deployato.
Difesa statistica, isolamento, accettazione del rischio
È utile confrontare la soluzione proposta con le possibili alternative per comprenderne l’efficacia e la fattibilità operativa.
Tra quelle rinvenibili nella letteratura scientifica, se ne evidenziano due di natura sostanzialmente diversa che giungono a una valutazione trasparente della loro adeguatezza.
La prima alternativa consiste nel sostituire la verifica crittografica dell’integrità con un monitoraggio basato sulla distribuzione statistica.
In pratica, si tratta di calcolare in modo continuativo le statistiche sulle distribuzioni dei dati in ingresso al processo di addestramento e sugli output prodotti dal modello e di segnalare come potenzialmente compromesse le situazioni in cui tali statistiche divergono da una baseline attesa.
Questo approccio presenta un’efficacia limitata e costi non trascurabili. È limitato, in quanto di natura probabilistica: un avversario sufficientemente abile può creare input avvelenati che rientrano nella distribuzione attesa, eludendo la rilevazione.
Inoltre, genera falsi positivi che, oltre a causare un carico operativo, intaccano la fiducia degli utenti nel sistema di verifica.
È oneroso, in quanto richiede infrastrutture di calcolo dedicate e l’elaborazione continua di metriche su grandi volumi di dati.
Accettando il rischio residuo
La seconda opzione consiste nel non implementare alcun controllo specifico, accettando il rischio residuo.
Questa scelta può essere ragionevole solo in contesti molto particolari, come gli ambienti di ricerca senza sistemi in produzione, le infrastrutture completamente isolate dall’esterno e gli scenari in cui altri controlli di sicurezza riducono drasticamente la superficie di attacco.
Per qualsiasi organizzazione che produca modelli AI destinati a scenari operativi reali, come i sistemi diagnostici medici, i classificatori del traffico di rete, gli agenti software autonomi o i modelli incorporati nei dispositivi critici, l’assenza di controlli adeguati, come quelli previsti dalla chain of custody, rappresenta una lacuna difficile da giustificare, soprattutto se si considera l’asimmetria tra il costo dell’attacco e quello della sua remediation.
Implicazioni operative
L’adozione di una chain of custody crittografica per i dati di training ha implicazioni che coinvolgono diversi domini dell’organizzazione.
Dal punto di vista tecnico, richiede un’infrastruttura di gestione delle chiavi crittografiche simile a quella di cui molte organizzazioni già dispongono per la code signing infrastructure: rotazione delle chiavi, custodia in componenti sicuri e procedure di emergenza in caso di compromissione.
Richiede l’integrazione delle primitive di firma e verifica nei data loader, negli strumenti di etichettatura, nei sistemi di gestione dei dataset. Attualmente, molti di questi componenti non sono progettati nativamente per supportare una chain of custody, e la loro implementazione rappresenta un investimento non banale.
Dal punto di vista organizzativo, richiede l’introduzione di ruoli e responsabilità ben definiti per la manipolazione dei dati.
Ogni operatore deve disporre di un’identità crittografica univoca e le procedure di onboarding e offboarding devono prevedere la generazione e la revoca delle relative chiavi.
Inoltre, le revisioni periodiche devono verificare che le firme depositate siano coerenti con le autorizzazioni in essere.
Dal punto di vista della governance, la chain of custody offre un’evidenza auditabile particolarmente apprezzabile in contesti regolamentari che richiedono la prova della provenienza e dell’integrità dei dati, come il Regolamento europeo sull’intelligenza artificiale e gli standard di settore nei comparti sanitario e finanziario.
La catena di custodia non basta
La chain of custody non risolve da sola tutti i problemi di sicurezza dei dati AI.
Non protegge dal “poisoning” alla fonte: una sorgente compromessa che firma autenticamente i dati già alterati genera una catena formalmente integra, ma sostanzialmente avvelenata.
Non sostituisce le verifiche statistiche e le tecniche di adversarial training, ma le integra.
Comunque, non elimina la necessità di una solida igiene della sicurezza dei sistemi di archiviazione e di calcolo. Riduce, però, in modo sostanziale la superficie di attacco accessibile lungo la pipeline e trasforma il problema della rilevazione del “poisoning” da problema probabilistico a problema deterministico, almeno per la classe di attacchi che operano sui dati a riposo o in transito.
La sfida culturale
Il messaggio che emerge da questa analisi, e che merita di essere ribadito, è che i dati di training di un sistema AI devono essere trattati con la stessa attenzione dedicata al codice eseguibile di un sistema critico.
Così come da decenni è considerato inaccettabile distribuire un eseguibile non firmato in un ambiente di produzione, allo stesso modo dovrebbe essere considerato inaccettabile alimentare un modello AI con dati la cui origine non sia verificabile crittograficamente.
L’asserzione di questa proprietà, dal code-signing del software al data-signing dei dataset, rappresenta uno dei campi di ricerca e sviluppo più significativi con cui la cyber security dovrà confrontarsi negli anni a venire.
L’investimento in una chain of custody crittografica
Resta aperta una sfida di natura culturale, più che tecnica. Convincere le organizzazioni che producono o consumano modelli AI a investire in un’infrastruttura di chain of custody, in un momento storico in cui l’attenzione è focalizzata sulla rapidità di adozione, è necessario rendere visibili i costi sommersi:
- il costo di un modello compromesso che genera decisioni distorte per mesi prima di essere individuato;
- il costo del riaddestramento completo come unica soluzione possibil;
- e il costo reputazionale e legale derivante dall’impossibilità di dimostrare l’integrità della propria pipeline di fronte a un’autorità regolatoria.
Se misurato rispetto a tali costi, l’investimento in una chain of custody
crittografica appare per quello che è: non un costo aggiuntivo opzionale, ma un componente/requisito della sicurezza dei sistemi AI.
Bibliografia
- [1] Metcalf, R., Churilla, M. «Data Poisoning in AI Models: The Case for Chain of Custody Controls». SEI Insights blog, Carnegie Mellon University – Software Engineering Institute, 27 aprile 2026. DOI: 10.58012/25yz-9b86.
- [2] Carlini, N. et al. «Poisoning the Unlabeled Dataset of Semi-Supervised Learning». USENIX Security Symposium, 2021.
- [3] Liu, S. et al. «Machine Unlearning: A Survey on Methods, Models, and Applications». arXiv:2406.09073, 2024.
- [4] Gaston, M., Heim, E., Barmer, H. AI Engineering: Twelve Foundational Practices. Carnegie Mellon University – Software Engineering Institute, 2026.
- [5] Churilla, M., Shabana, M., Metcalf, R., Lau, S. AI Hygiene Starts with Models and Data Loaders. SEI Library, Carnegie Mellon University, 2024.
- [6] Coalition for Secure AI (CoSAI). Establish Risks and Controls for the AI Supply Chain v1.0. OASIS Open, 2025.
- [7] OWASP. Top 10 for Large Language Model Applications. OWASP Gen AI Security Project, 2024.
- [8] NIST. Artificial Intelligence Risk Management Framework: Generative AI Profile (AI 600-1). National Institute of Standards and Technology, 2024.
- [9] Sambasivan, N. et al. «Everyone Wants to Do the Model Work, Not the Data Work: Data Cascades in High-Stakes AI». CHI Conference, 2021.
- [10] National Security Agency et al. AI/ML Supply Chain Risks and Mitigations. Joint Cyber security Information Sheet, marzo 2026.
如有侵权请联系:admin#unsafe.sh