
AI Vulnerability Research and the Fuzzer Era Déjà Vu: Why the Numbers Are Only Half the Story
Posted by: voidsec Post Date: May 12, 2026
Reading Time: 11 minutes
TL;DR A post by Alex Albert (Anthropic) claims that with the help of Claude Mythos, Mozilla fixed more security bugs in April 2026 than in the previous 15 months combined. Mozilla published the full breakdown: 271 of those bugs were found by Mythos, of which 180 were rated sec-high and 80 sec-moderate. The findings included sandbox escapes, race conditions, and UAFs. The severity distribution looks impressive, but tells a fraction of the story: not every bug is a security bug, not every security bug is exploitable, and what we are witnessing is (IMHO) the AI-assisted equivalent of the fuzzer era. Same initial spike, same low-hanging fruits, same incoming plateau. The hard bugs still require human expertise; Mozilla says so themselves. The hard part isn’t finding bugs; it’s chaining them into a reliable full-chain against a hardened target.
The Trigger
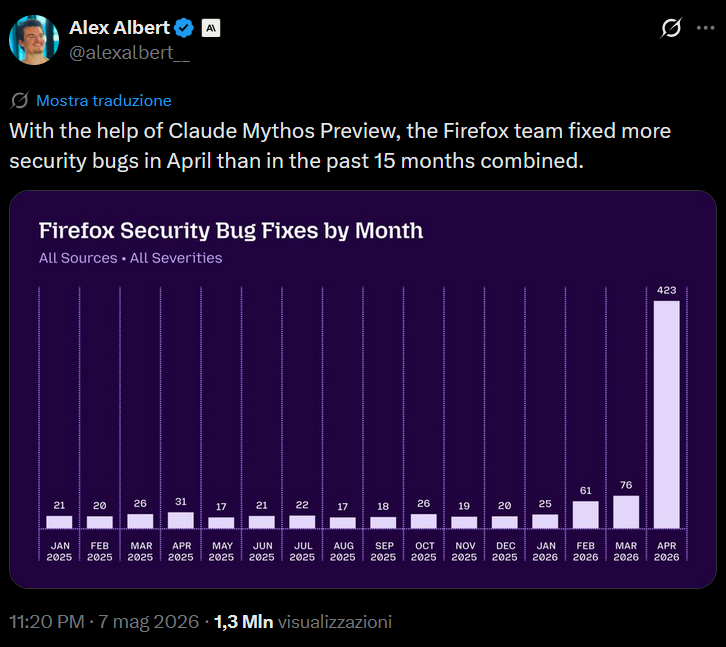
A post recently circulating on X by Alex Albert from Anthropic showed the following chart:

“With the help of Claude Mythos Preview, the Firefox team fixed more security bugs in April than in the past 15 months combined.”
The accompanying chart shows Firefox security bug fixes by month. From January 2025 through March 2026, the monthly count sits between 17 and 31. Then in April 2026, it spikes to 423, roughly 14x the previous monthly average.
Don’t get me wrong, this is genuinely impressive from an engineering throughput perspective, and Mozilla deserve credit. But the moment I saw that chart, a very specific reaction kicked in, the same one I get every time a tool, technique, or vendor promises to “finally solve” software security. I’ve been around long enough to have seen this pattern play out before, and I’d like to lay out exactly why this kind of announcement needs to be read with a fair bit of critical thinking.
Bug ≠ Security Bug
The chart is labelled “Firefox Security Bug Fixes by Month – All Sources · All Severities.”
When I first saw the chart, my immediate reaction was: where’s the severity breakdown? A spike driven overwhelmingly by low-severity hardening issues is a very different story from one driven by memory corruption bugs. Mozilla published the full breakdown in their technical blog post, and I’ll give credit where it’s due: of the 271 bugs attributed to Claude Mythos in Firefox 150, 180 were rated sec-high, and 80 were sec-moderate.
The 423 figure also deserves unpacking: 271 were Mythos findings, 41 were externally reported, and the remaining 111 were found internally through a mix of other AI models, other Mythos Preview findings shipped in other releases, and traditional fuzzing. So, the chart is not purely “AI did this”; worth knowing.
This isn’t a criticism specific to Anthropic or Mozilla; it’s a systemic problem in how “security metrics” get communicated publicly. Bug counts are just a vanity metric unless you know the exploitability, and this is where my argument actually begins.
Security Bug ≠ Exploitable Bug
180 high-severity security bugs is a serious number, but there’s a catch, and Mozilla themselves say so in their FAQ: “Is a sec-high or sec-critical bug the same as a practical exploit? Not necessarily.” They classify sec-high based on crash symptoms reported by AddressSanitizer (use-after-free, out-of-bounds memory access), and their threat model conservatively assumes any of them could be exploitable with sufficient effort, but it also means the 180 count represents a ceiling on potential impact, not a measure of it.
And even if, for the sake of argument, we assume that a meaningful portion of those bugs are genuine security issues, the kind of things that end up in a CVE advisory. We’re still only at step one of a multi-step process.
Finding a vulnerability and proving that a vulnerability is exploitable are completely different disciplines. The triage phase, where you determine whether a bug has actual offensive value, requires answering a set of non-trivial questions:
- Reachability: Can the vulnerable code path actually be triggered from an attacker-controlled input, or does it require a specific internal program state that’s hard to reach?
- Primitives: What does the bug give you? An arbitrary write? A type confusion? An out-of-bounds read? Not all primitives are equal; some are trivially weaponizable, others require significant work to convert into something useful.
- Mitigation landscape: Firefox runs inside a multi-process architecture with a sandbox and a layer of exploit mitigations, ASLR, CFG, stack canaries, and JIT hardening, to name a few. Does the bug survive contact with those layers? Can it be triggered in a process with useful capabilities, or is it sandboxed to irrelevance?
- Heap state dependency: Many memory corruption vulnerabilities are only exploitable under specific heap layout conditions. Without understanding the allocator behaviour and the surrounding object lifecycle, a UAF can look terrifying on paper and be practically useless in exploitation.
- Interaction with the JavaScript engine: Firefox’s SpiderMonkey JIT introduces additional complexity. A bug in the JIT compilation pipeline or in the GC’s handling of JS objects requires a very specific kind of expertise to understand and weaponise.
Mozilla’s own pipeline does include automated triage: the agentic harness creates and runs reproducible PoC test cases, actively dismissing false positives before escalating findings. This is meaningfully more sophisticated than a static analyser dumping findings into a queue. But the pipeline still doesn’t answer the question an attacker cares about: does this bug give me a reliable primitive that survives real mitigations in the target process? That assessment still requires a human.
An attacker doesn’t care about your fix count. They care about whether any of those 423 bugs gives them a reliable primitive.
Mozilla is explicit about this: in most cases, a single sec-high bug is not enough to compromise Firefox.
The Fuzzer Era Parallel
Here’s where I’m going to offer what I suspect will be an unpopular analogy: what we are witnessing with AI-assisted vulnerability research is comparable to what happened during the initial fuzzer era. Some meaningful distinctions in entry barrier, scale, and capability ceiling, but the same fundamental dynamics.
Go back to the early-to-mid 2010s, when fuzz testing started becoming accessible. Tools like AFL and libFuzzer lowered the barrier dramatically. Suddenly, you didn’t need deep RE skills to find crashes; you needed a reasonably good harness, a corpus, and patience. The result was a surge of vulnerability discoveries across virtually every major software project. The security community celebrated. Google’s OSS-Fuzz eventually reported finding thousands of vulnerabilities in open source projects.
The pattern looked something like this:
- New technique/tooling emerges: dramatically lowering the entry barrier
- Initial spike of discoveries: a mix of quick wins and low-hanging fruit in parsing code and, later, genuinely complex bugs once tooling matured
- Mainstream adoption: more tooling, more automation, more projects covered
- Diminishing returns as the surface gets cleaned up
- Plateau: the remaining bugs require a deeper understanding of the codebase that the technique alone can’t achieve
Fuzzers are still invaluable today, and they still find interesting things. But the initial surge of “fuzzing is going to fix software security” hype gave way to a more nuanced reality: mutation-based fuzzers are not effective at finding bugs that require understanding complex program state or multi-step interaction sequences.
| Dimension | Fuzzer Era (2014–2018) | AI-Assisted Vuln Research (2025) |
| Entry barrier | Moderate: harness writing required basic reverse engineering skills | Very Low: prompt-based interaction |
| Scale of initial spike | Large: thousands of bugs across OSS | Potentially larger: faster, broader reach, more targets in parallel |
| Basis for bug discovery | Random mutation + coverage guidance | Pattern recognition on training data: bugs similar to previously seen ones. Even though agentic reasoning + dynamic PoC testing can greatly refine the results. |
| Bug complexity ceiling/Deep codebase understanding | Low-to-medium | Higher: better than pure fuzzing, but still not genuine reasoning |
| Exploitability assessment | None | Limited: Partial automated triage via PoC reproduction. Full exploitability still requires human expertise |
| Expected trajectory | Plateau after low-hanging fruits exhausted. Continued value in regression prevention | Likely similar plateau at a higher ceiling than fuzzing; possibly delayed by larger training data |
What AI Is Actually Doing
Let me be precise about the mechanism here, because I think a lot of the hype stems from mixing “AI found a bug” with “AI understood the codebase and reasoned its way to a new vulnerability class.”
What large language models are remarkably good at, and what makes them genuinely useful for vulnerability research and bug hunting, is pattern recognition on their training data. A model that has been trained on millions of lines of C/C++, on CVE descriptions, on bug bounty writeups, on exploit code, and on security advisories has an extremely good internal map of what buggy code tends to look like. It can recognise signatures of use-after-free conditions, integer overflow patterns, format string vulnerabilities, and similar well-documented bug classes.
This is quite powerful, particularly for codebases that are large and where human reviewers might miss a familiar-looking pattern buried in a sea of code. It also explains the initial spike: there is a lot of code out there that contains well-known bug class signatures that no human has gotten around to reviewing carefully. AI can cover that ground efficiently.
The key innovation is not the model itself but the agentic harness: a pipeline that instructs the model not only to hypothesise about bugs but to actively write and execute PoC test cases against a live build, dynamically verify whether the crash is reproducible, and dismiss false positives before escalating.
LLMs are still, at their core, operating on learned representations of code, and there are categories of bugs where I still expect them to struggle without significant additional scaffolding:
- Understanding a complex data structure and reasoning about how it can be violated under a specific sequence of operations.
- Tracing multi-component interactions. e.g. how does a value set by a JavaScript callback in SpiderMonkey interact with the GC’s object lifecycle assumptions five call frames later?
- Reasoning about concurrency and timing-dependent race conditions that only manifest under specific OS behaviour or hardware conditions.
- Understanding how a chain of individually benign operations accumulates into a security-relevant state. Vulnerability chains where no individual component is obviously buggy, and the security issue only emerges from the combination.
- Bugs that require understanding proprietary, undocumented internals with no analogues in public training data.
None of this is straightforwardly pattern-matchable against prior bugs. These are the bugs that require you to understand the specific system in front of you, its history, its design decisions, and its failure modes.
The Entry Barrier Difference
One dimension where AI-assisted vulnerability research genuinely diverges from the fuzzer era, and where I’d argue the implications are underappreciated, is the entry barrier reduction.
Fuzzing required you to write a harness. That harness required you to understand, at least partially, the structure of the target, the input format, the parsing pipeline, and the code paths worth reaching. Someone with no security background would have struggled to produce a meaningful fuzzing setup for SpiderMonkey in a reasonable amount of time.
An LLM-based code review tool requires none of that. You point it at code and ask it questions in natural language. This means that the population of people capable of finding and reporting bugs has expanded dramatically. That’s broadly positive: faster coverage of known bug patterns across more projects.
But it also means that false positive rates will likely be higher, the triage burden on engineering teams is higher, and the discoverability of the low-hanging fruit will be exhausted faster. When everyone can run the same AI tool against the same codebase, the initial wave will be large and rapid and then the well will dry faster than it did with fuzzing.
Where This Leaves Us
I don’t want to be misread as being dismissive of what was clearly a significant engineering effort by Mozilla. 423 bug fixes in a month is real work, and reducing the attack surface is unambiguously good. If AI tooling accelerates that process, that’s a net positive; the pipeline Mozilla built to get there is worth studying.
What I’m pushing back on is the narrative and its implied conclusion: that we are witnessing a solved problem, a step change that fundamentally shifts the security posture of software against capable attackers. I’ve seen that claim made about fuzzing, static analysis, etc. Each technique has genuinely raised the bar in specific domains, and each has hit a ceiling when the available surface ran out, or the remaining bugs exceeded what the technique could reach.
The chart showing 423 fixes in April 2026 looks dramatic. Come back in 12 months and look at the trend line. My prediction is that the monthly count will settle back toward baseline, with a permanent improvement reflecting what the pipeline continues to catch on newly landed code (regression prevention rather than discovery of latent bugs). The hardest latent bugs, the ones an attacker actually needs to build a reliable full-chain exploit against a target, will still require the same combination of deep target technical expertise, creative thinking, and painstaking manual analysis.
Not all bugs are created equal, not all security bugs are exploitable, and not all impressive-looking charts tell the full story.
If you’ve read this far and want to disagree, I’m genuinely open to it. Come find me on Twitter/X and at conferences, I’m curious to hear your opinion.