Ad

Ad

#人工智能 OpenAI 开源发布隐私过滤模型 Privacy Filter,该模型可以精准识别个人隐私信息,例如姓名、电话、邮箱、密码、API 凭证。开发者可以使用这个模型来识别用户提交的内容,再使用其他规则批量删除包含隐私信息的字段,最后再将不含隐私信息的文本提交给其他大型模型以保护用户隐私。查看详情:https://ourl.co/112793
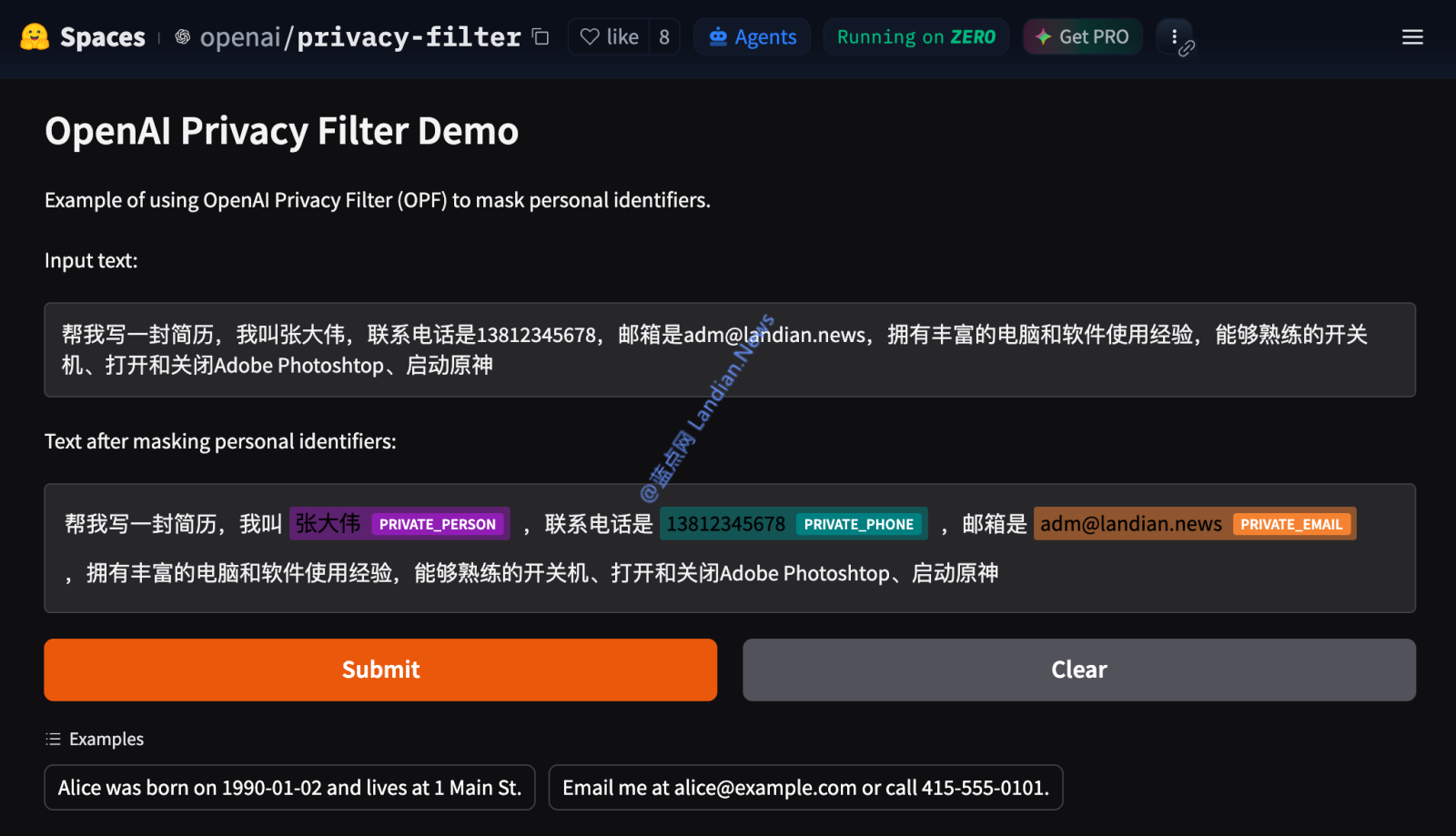
人工智能公司 OpenAI 日前开源发布参数规模只有 1.5B 的隐私过滤模型 Privacy Filter,与常规大型语言模型不同,这个新模型主要是用来识别并自动清除用户提交内容中的个人信息,让其他 AI 系统处理数据时更加安全和可控。
Privacy Filter 模型经过自回归预训练,架构与 GPT-OSS 开源模型类似但规模更小,理论上说还可以在常规消费级设备上运行,例如集成到浏览器里用于自动清除用户提交的敏感信息。
注意:这个模型本身只是用于标记,开发者还需要搭配其他规则或模型将成功匹配出来的隐私内容清除,这个模型本身不会直接清除隐私内容并生成不含隐私内容的文本。

识别并清理的内容包括:
目前 OpenAI Privacy Filter 模型可以识别并清除如下个人隐私信息:姓名、地址、电话号码、邮箱地址、日期信息、账号、银行账号、URL 链接、密码、API 凭证等,模型会在处理过程中扫描整段文本,然后对敏感信息进行标记以方便后续进行遮蔽或替换。
以前很多隐私过滤工具主要依赖规则匹配,例如使用正则表达式识别手机号码或使用固定格式识别邮箱地址,这种识别方法只能识别格式明显的数据,对于复杂语境无能为力,所以实际处理过程中可能无法准确清理个人敏感信息。
这个模型的优势在于:
- 通过上下文理解和基于语境的判断来识别内容,识别准确率更高方便后续处理
- 模型体积非常小,可以在网页浏览器或笔记本电脑上本地运行 (1.5B+50M 活跃参数)
- 可以通过简单高效的方式进行微调,让模型适应特定的数据分布
- 支持最高 128K 上下文窗口,能够以高吞吐量处理长文本,不需要分段处理,提高准确率
- 可以通过预设的工作点配置精度 / 召回率权衡和检测到的跨度长度进行控制