
0X00前言
Django 一直以来安全性就非常之高,从2005发行到现在就没有出现过能够无条件直接利用的RCE。本着对Django的学习,来聊聊Django因编程不当而产生的RCE。
0x01 CVE-2014-0472
2014年,Django官方修复一个问题,其描述是因位于django/core/urlresolvers.py文件中的reverse函数过滤不当而导致Django可以任意获取内部的函数,如果攻击者知道代码内部存在恶意的模块,则可以发起任意代码执行。参考https://www.djangoproject.com/weblog/2014/apr/21/security。
来看看官方的补丁https://github.com/django/django/commit/8b93b31487d6d3b0fcbbd0498991ea0db9088054
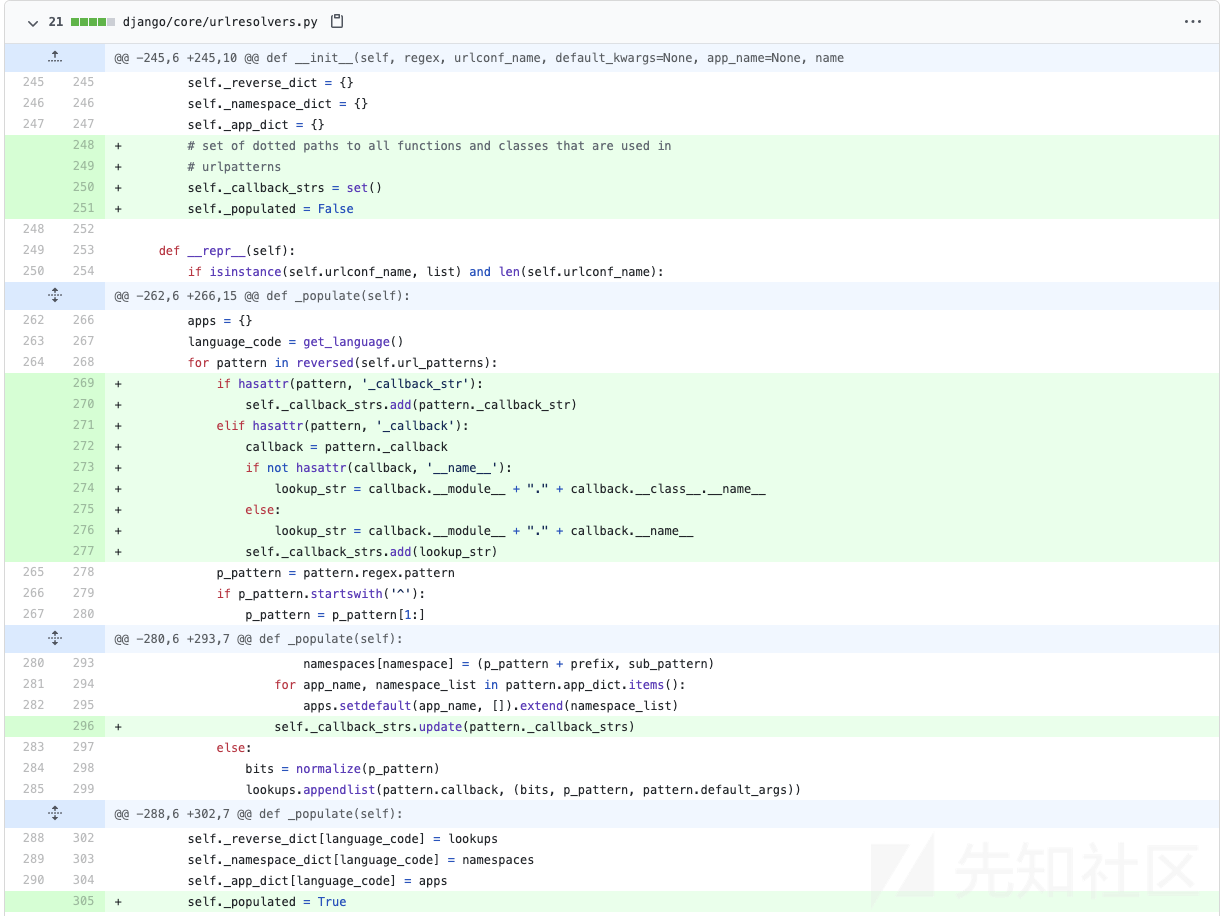
可以看见修复的地方为urlresolvers.py文件,增加了对传入reverse函数内部功能的检查,检查改方法是否存在于url路由表中。
同时,该文件也在2014年被删除,现在reverse函数位于文件/django/url/resolvers.py中。同样,来看看漏洞的位置

我们传入redirect函数内的参数会被传到reverse函数去查看是否含有如下的URL的路由,例如
url(r'^index', views.red, name="index_view")
当我们传入参数为index_view时,Django识别出来之后给我们跳转到index的URL上面。其中get_callable即为搜索URL的函数方法

从进入callable函数的过程中可以看到当函数不能被调用的时并且函数名字不为空的时候则进入到lookup_view = getattr(import_module(mod_name), func_name)这一行代码中去,而这一行代码则会在不拥有任何过滤的情况使用getattr调用这个函数的名字,从而造成了任意函数的引用。
构造一个视图函数并配置路由
def redirect_test(request): page = request.GET.get('page', None) if page is not None: redirect(page) return HttpResponse("OK") # url url(r'^example', views.redirect_test, name="redirect")
这是一个基本的跳转方法,当我们往page参数输入redirect参数的时候,页面会跳转到example的路由中来

如果我们输入一个并不存在的路由函数的时候则会触发reverse报错

当我们输入os.system的时候报错结果如下

可以看到os.system被Django调用了。同时也可以在getattr处下断点,此处传入参数sys.path,得到如下结果

可以看到成功调用了sys.path并返回了参数。而改漏洞的利用点为当攻击者知道项目本身利用的恶意引用的时候则可以调用改方法。虽然这听起来很鸡肋,但是官方非常重视这个问题的原因是它可以出自Django自身的代码,也就是admin路由。用过admin的用户都知道,访问admin的头的时候会跳转到admin/login/?next=/admin/的URL中去,例如python官网是这样
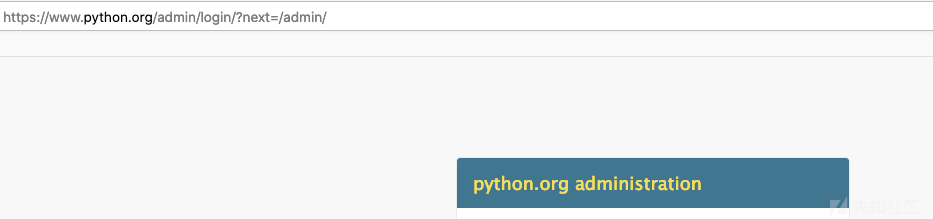
而这个next后面的传值,实际上就是发往redirect函数中的参数。
如何利用
我们可以通过getattr去访问Django框架下的任意的参数,比如位于apps.py文件底下的函数,我们可以直接传入参数app.apps.xxx即可以拿到该函数的对象,可能产生危害的环境我放到了github上,欢迎师傅们来讨论
https://github.com/christasa/CVE-2014-0472
0x02 FileBasedCache
这是我本文主要介绍的另一种情况——Django的缓存配置错误引发的RCE。在Django开发的过程中缓存是使用的比较多的,GitHub上搜索关键字cache_page的结果大约有200K以上,配置的方法可以有如下的几种
from django.views.decorators.cache import cache_page @cache_page(60 * 15) def cache_views(requests) .... 或者 # urls.py path('cache_url', cache_page(60 * 60 * 6)(cache_views))
Cache缓存的存储方式有很多种,具体可以参考官方文档https://docs.djangoproject.com/en/3.1/topics/cache/,本次主要谈一谈FileBasedCache的方法。
基于文件系统的缓存主要代码逻辑位于django/core/backends/filebased.py文件中,其FileBasedCache类同样继承了BaseCache的几个方法add、get、set、delete和touch等。从开头引入的包可以看到,Django的Cache功能引用了pickle作为压缩的主要模块,既然有pickle,那就有可能会存在反序列化,来看看cache是怎么进行内容的读取的。从get方法来看
def get(self, key, default=None, version=None): fname = self._key_to_file(key, version) try: with open(fname, 'rb') as f: if not self._is_expired(f): return pickle.loads(zlib.decompress(f.read())) except FileNotFoundError: pass return default
Django对缓存文件内容的读取是直接进行loads的,没有进行任何过滤。与此同时,在pickle.loads之前会有一个self._is_expired函数来检查缓存文件是否过期,再来跟进一下该函数
def _is_expired(self, f): """ Take an open cache file `f` and delete it if it's expired. """ try: exp = pickle.load(f) except EOFError: exp = 0 # An empty file is considered expired. if exp is not None and exp < time.time(): f.close() # On Windows a file has to be closed before deleting self._delete(f.name) return True return False
可以看到逻辑为首先通过序列化文件内容,拿到序列化的时间戳,如果时间不为0或者小于设置的时间时返回True。看到关键点exp = pickle.load(f)。没有进行任何的过滤从而直接进行load文件序列化,这就意味着我们可以构造任何恶意的序列化内容来控制Django返回的内容,甚至是RCE,只要我们知道缓存存放的名字和位置,那么我们就能够直接进行代码执行。
幸运的是Django恰巧同时满足这两个条件!
第一个位置的条件我们可以从settings.py文件中关于cache的配置中得到,并且官方有着推荐的地址分别为Linux下的/var/tmp/django_cache和Windows下的c:/foo/bar

这导致部分开发者直接使用了官方推荐的地址,从GitHub搜索的结果可以看出

第二名字的条件。来分析一下Django生成cache名字的代码,位于django/utils/cache.py文件和django/core/backends/filebased.py中,核心的代码如下
def _generate_cache_key(request, method, headerlist, key_prefix): """Return a cache key from the headers given in the header list.""" ctx = hashlib.md5() for header in headerlist: value = request.META.get(header) if value is not None: ctx.update(value.encode()) url = hashlib.md5(iri_to_uri(request.build_absolute_uri()).encode('ascii')) cache_key = 'views.decorators.cache.cache_page.%s.%s.%s.%s' % ( key_prefix, method, url.hexdigest(), ctx.hexdigest()) return _i18n_cache_key_suffix(request, cache_key)
def _key_to_file(self, key, version=None): """ Convert a key into a cache file path. Basically this is the root cache path joined with the md5sum of the key and a suffix. """ key = self.make_key(key, version=version) self.validate_key(key) return os.path.join(self._dir, ''.join( [hashlib.md5(key.encode()).hexdigest(), self.cache_suffix]))
缓存的URL分为GET方式和HEAD方式,views.decorators.cache.cache_page.%s.%s.%s.%s里面传入的值分别是自定义的缓存前缀,方法,URL的MD5值和参数,最后使用.djcache结尾。总结出来的名字的规则为
md5(":1:views.decorators.cache.cache_header..<全局url的md5>.en-us.UTC") + ".djcache"
md5(":1:views.decorators.cache.cache_page..GET.<全局url的md5>.d41d8cd98f00b204e9800998ecf8427e.en-us.UTC") + ".djcache" # GET方式拿到的cache 名字
md5(":1:views.decorators.cache.cache_page..HEAD.<全局url的md5>.d41d8cd98f00b204e9800998ecf8427e.en-us.UTC") + ".djcache"# HEAD方式拿到的cache名字例如,当我们使用GET请求访问一个URL为http://127.0.0.1:8000/时,其产生的两个cache的名字分别为
md5(":1:views.decorators.cache.cache_header..md5("http://127.0.0.1:8000/").en-us.UTC") + "djcache" = 96f05816abc9879d149c5a6fb516c796.djcache.djcache
md5(":1:views.decorators.cache.cache_page..GET.md5("http://127.0.0.1:8000/").en-us.UTC") .d41d8cd98f00b204e9800998ecf8427e.en-us.UTC") + ".djcache" = 970fe90174a01b863a3ec74833134b47.djcache至此,我们拿到能够获得进行pickle序列化的所有条件。

利用场景
Django创建cache文件夹的默认权限是700,这意味无法通过同组的用户来进行改写,但是Django的服务器一般是用nginx或者apache等来启动。有的情况下,nginx服务器底下可能不止一个服务在运行,也可能是PHP或者其他。那么如果其他服务能够进行对临时文件夹tmp或/var/tmp内部的内容进行读写的话,则可以对Django框架进行攻击
另一种情况就是文件上传。部分开发者会错误地将cache的位置配置在文件上传的位置,也就是CACHE LOCATION为MEDIA_ROOT的子目录,这种情况就可以通过文件上传来进行pickle序列化的RCE。但是Django里model的FileField方法不会覆盖原来已有的文件,同时Django也不会主动删除缓存文件,因此无法覆盖GET型缓存。这种情况可以尝试上传HEAD类型的缓存并访问,同样也可以达到pickle RCE的效果。
除去RCE,之前也提到过,Django不会主动删除已经过期了的cache文件,只有在下一次访问的时候进行检查和重写。因此我们可以通过因为某些测试的路由在删除之后没有删除cache文件而导致的敏感信息泄漏。这种配置通常出现在CACHE LOCATION的位置位于STATIC_ROOT或者STATICFILES_DIRS上。
来看看cache保存的内容,同样,在filebase.py文件的_write_content函数上面下断点
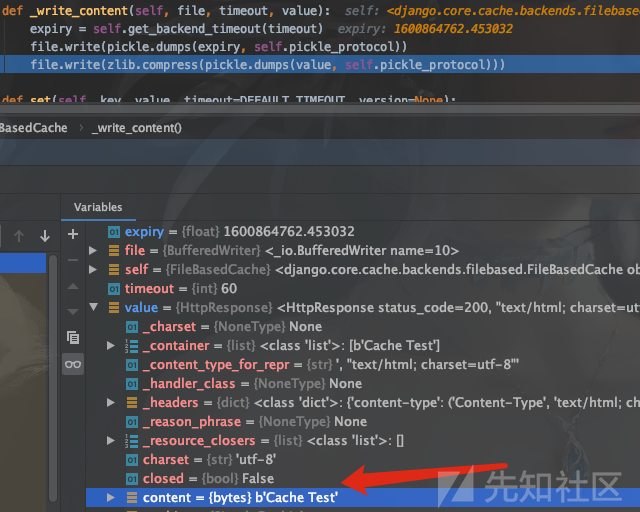
可以看到HttpResponse类中的content参数即为html的内容,我们同样也能通过改写缓存文件进行内容伪造。cache的内容提取的代码如下
import pickle from django.http.cookie import SimpleCookie import zlib import sys class HttpResponseBase: def __init__(self, content_type=None, status=None, reason=None, charset='utf-8'): self._headers = {} self._resource_closers = [] self._handler_class = None self.cookies = SimpleCookie() self.closed = False self._reason_phrase = reason self._charset = charset if content_type is None: content_type = 'text/html; charset=%s' % self.charset self['Content-Type'] = content_type def _convert_to_charset(self, value, charset, mime_encode=False): if not isinstance(value, (bytes, str)): value = str(value) if ((isinstance(value, bytes) and (b'\n' in value or b'\r' in value)) or isinstance(value, str) and ('\n' in value or '\r' in value)): raise BadHeaderError("Header values can't contain newlines (got %r)" % value) try: if isinstance(value, str): # Ensure string is valid in given charset value.encode(charset) else: # Convert bytestring using given charset value = value.decode(charset) except UnicodeError as e: if mime_encode: value = Header(value, 'utf-8', maxlinelen=sys.maxsize).encode() else: e.reason += ', HTTP response headers must be in %s format' % charset raise return value def __setitem__(self, header, value): header = self._convert_to_charset(header, 'ascii') value = self._convert_to_charset(value, 'latin-1', mime_encode=True) self._headers[header.lower()] = (header, value) def __delitem__(self, header): self._headers.pop(header.lower(), False) def __getitem__(self, header): return self._headers[header.lower()][1] def make_bytes(self, value): if isinstance(value, (bytes, memoryview)): return bytes(value) if isinstance(value, str): return bytes(value.encode(self.charset)) return str(value).encode(self.charset) class HttpResponse(HttpResponseBase): streaming = False def __init__(self, content=b'', *args, **kwargs): super().__init__(*args, **kwargs) self.content = content @property def content(self): return b''.join(self._container) @content.setter def content(self, value): # Consume iterators upon assignment to allow repeated iteration. if hasattr(value, '__iter__') and not isinstance(value, (bytes, str)): content = b''.join(self.make_bytes(chunk) for chunk in value) if hasattr(value, 'close'): try: value.close() except Exception: pass else: content = self.make_bytes(value) self._container = [content] def __iter__(self): return iter(self._container) def readcachecontent(filename): f = open(filename, "rb") pickle.load(f) previous_value = pickle.loads(zlib.decompress(f.read())) f.close() print("Content:") print(previous_value.content) if __name__ == '__main__': filename = sys.argv[1] readcachecontent(filename)

如何防御
在后期报告Django安全团队的过程中,Django官方认为这是一个问题,在询问是否有补丁提供之后,我给出的建议是对cache初始的文件名加入复杂唯一性元素,但是开发者们并不愿意对缓存增加任何元素,这个点上,P神给出的解释是“如无必要勿增实体”。最终得出来的结论是在manage.py 的check方法中增加对MEDIA_ROOT、STATIC_ROOT和STATICFILES_DIRS的检查,检查CACHE LOCATION是否位于这三个路径之下,并且在官方FileBaseCached文档下面新增加安全警告。目前代码还在审查中。
中途,Django官方因为collection权限问题出了检查static路径的权限之外,着重对cache文件夹进行权限检查,并额外分配了CVE——CVE-2020-24584
个人的建议是,在cache_page后面新增加参数key_prefix来混淆cache文件名,例如
@cache_page(60 * 60, key_prefix="obfuscating cache")
或者用其他形式的缓存存储。
如有侵权请联系:admin#unsafe.sh