好的,我现在需要帮用户总结一篇文章的内容,控制在100字以内。首先,我得通读整篇文章,理解其主要内容和重点。 这篇文章主要讲的是使用合成数据来构建强化学习(RL)环境。作者提到,收集真实数据既耗时又昂贵,而合成数据可以解决这个问题。他们通过一个例子展示了如何用合成数据训练模型,并在真实数据上取得了不错的效果。 接下来,我需要提取关键点:合成数据的作用、案例研究、结果以及结论。确保在100字以内涵盖这些内容,同时保持语言简洁明了。 最后,检查字数是否符合要求,并确保总结准确传达文章的核心信息。 </think> 文章探讨了利用合成数据构建强化学习环境的可行性。通过生成虚拟公司及其电子邮件数据集,研究展示了合成数据在训练和评估RL模型中的有效性。实验表明,完全基于合成数据训练的模型在真实数据上表现出色,证明了合成数据在RL任务中的潜力和实用性。 2026-3-31 20:16:6 Author: securityboulevard.com(查看原文) 阅读量:3 收藏
Building Reinforcement Learning (RL) environments to evaluate and train agents involves simulating the world in which an agent interacts, which raises an immediate question: how do we populate this world with realistic data and scenarios? Unless you have vast troves of real-world data in hand, gathering relevant data will likely be a slow and expensive process. In this post, we’ll demonstrate the effectiveness of leveraging synthetic data to build environments, allowing fine-grained control over tasks and eliminating the need for slow data collection.
Open models are capable enough that RL will work for a wide variety of tasks, and services like Tinker or Prime Intellect’s Lab have commoditized the previously difficult infrastructure of fine-tuning large models. The remaining challenge is crafting meaningful tasks and building environments to train against — and that’s exactly the challenge we set out to tackle using our synthetic data solution, Tonic Fabricate.
As a starting point, we focus on one of our favorite recent examples: OpenPipe’s ART-E email agent, which was trained on synthetic tasks generated from real emails: the famous Enron Corpus. To test whether real data could be replaced entirely, we used Fabricate to swap the Enron corpus for a fictional company’s emails, then used that purely synthetic data to evaluate frontier models and RL fine-tune an open-source model via Thinking Machine’s Tinker API.
The result speaks for itself: a fine-tuned Qwen3.5-35B-A3B that beats o3 on real Enron emails — despite never seeing a single real email during training. No real data. No enron. Just a fictional company invented by Fabricate.
The setup
OpenPipe’s ART-E benchmark evaluates email search agents: given an inbox and a question, the agent searches emails using tools (search_inbox, read_email) and returns an answer. OpenPipe’s key finding was that a fine-tuned Qwen 2.5 14B could beat o3 on this task.
We wanted to test whether you could get the same result using entirely synthetic data. The motivation:
- Real corpora have limits — Enron is the only large public email corpus, and it’s 25 years old. Most modern tooling lacks analogous open datasets.
- Real corpora lack structure — you can’t control difficulty or ensure coverage of specific reasoning patterns.
- If synthetic data works, you can generate unlimited training data for any domain and set of tools.
Generating an RL Environment with Tonic Fabricate
We tasked Tonic Fabricate with generating a complete corporate world. The starting prompt:
You are a creative writer building a realistic corporate world for generating synthetic email data. The company should feel like a real mid-size tech company with realistic org structure, politics, and interpersonal dynamics. Generate a company with 5 departments and 100 employees total. Every person needs a unique corporate email address. Include a mix of seniority levels. Personality notes should capture how each person writes emails.
From this seed, the data agent built Vectrix Technologies, a fictional 100-person SaaS startup. The generation proceeded in phases:
Phase 1: The Corporate World. The agent populated a SQLite database with org structure, employee profiles, and interpersonal dynamics. Each of the 100 employees got a detailed personality profile with a distinct email voice — Nadia Volkov signs off with nothing, Marcus Webb sends stream-of-consciousness emails at midnight, Darius Williams writes in sarcastic lowercase.
Phase 2: Timeline Events. 914 events across 12 months, organized around 6 narrative arcs: a product rewrite, an enterprise sales push, OG-vs-new-guard culture tensions, board pressure on burn rate, SOC 2 compliance, and co-founder divergence. Each event tagged with category, confidentiality level, emotional temperature, and email thread potential.
Phase 3: Thread Specifications. A mapping layer of 995 thread specs linking events to email structures — thread type (announcement, discussion, escalation, 1:1, social), participants, message counts, key information to embed, and cross-references between threads. These cross-references are critical: they define the structural links that make multi-hop reasoning tasks possible.
Phase 4: Email Bodies. 1,964 emails written in character voice, each matching the personality profiles from Phase 1.
The key design choice: the world has structured metadata (timeline events, thread specs, cross-references) that sits between the narrative and the emails. The metadata graph lets us programmatically construct tasks that range from simple single-email lookups to multi-hop reasoning across thread chains — and to generate question/answer pairs grounded in specific emails.
Here’s the database schema — three layers from world-building down to the emails themselves:
1-- Layer 1: The corporate world
2employees (100) -- name, email, title, seniority, hire_order, is_og, is_remote
3employee_profiles (100) -- email_style, greeting, signoff, communication_quirks, political_style
4departments (5) -- engineering, sales, product, people_ops, finance
5teams (23) -- manager, headcount, description
6alliances (12) -- members, strength (deep/strong/moderate/situational)
7active_tensions (9) -- side_a, side_b, intensity (simmering → boiling), trigger_topics
8
9-- Layer 2: The narrative
10timeline_events (914) -- date, category, description, key_people, departments_affected,
11 -- confidentiality, precursor_events, consequence_events,
12 -- emotional_temperature (routine → crisis)
13
14-- Layer 3: The mapping from events to emails
15email_thread_specs (995)-- event_id, thread_type (announcement/discussion/escalation/1on1/social),
16 -- initiator, participants, message_count, cross_references
17
18-- Layer 4: The emails (what the agent actually sees)
19emails (1,964) -- message_id, subject, from_address, date, body
20recipients (4,759) -- recipient_address, recipient_type (to/cc)The agent only sees Layer 4. Layers 1-3 are invisible to it — but they’re what lets us construct tasks of known structure and verify that reference answers are grounded in real email content.
How tasks are constructed
Tasks are built by traversing the metadata graph at different depths:
1Single email: THR-0712 ──→ 1 email
2 "Who is the new enterprise AE that was recently onboarded?"
3
4Same thread: THR-0031 ──→ 3 emails (Mike flags risk → Brittany adds context → Craig responds)
5 "What are the specific concerns and renewal risks Brittany
6and Mike raised about the three mid-market accounts?"
7
8Cross-thread: THR-0405a (Sentinel pitch prep)
9 │ cross_references
10 ▼
11 THR-0405b (pricing approval)
12 "Who is presenting the security remediation sprint at the
13 final Sentinel pitch, and who gave final approval for the
14 $400K ARR?"
15
16Multi-hop chain: THR-0039 (SaaS audit) ──→ THR-0063 (follow-up savings)
17 │ │
18 ▼ ▼
19 THR-0094 (Q1 budget review) ──→ THR-0115a (Q2 budget cuts)
20 "How did Frank's SaaS audit findings influence subsequent
21 budget decisions for Q2, and what arguments did leadership
22 have at each stage?"Each arrow is a cross_references link in the thread spec table. The agent only sees the emails — it has to discover these connections through search.
Quality pipeline
LLM-generated reference answers hallucinate. We measured a 14% hallucination rate in raw task generation, scaling with complexity (L0: 2%, L2: 30%). A three-stage pipeline catches these:
- Validate — programmatically verify all referenced emails are accessible from the assigned inbox (catches 6%)
- Audit — LLM judge checks every factual claim in the reference answer against the actual email content (catches 14%)
- Split — stratify by inbox to prevent train/eval leakage
Final dataset: 1,109 training tasks and 184 eval tasks across 77 mailboxes.
Evaluation: Synthetic benchmark
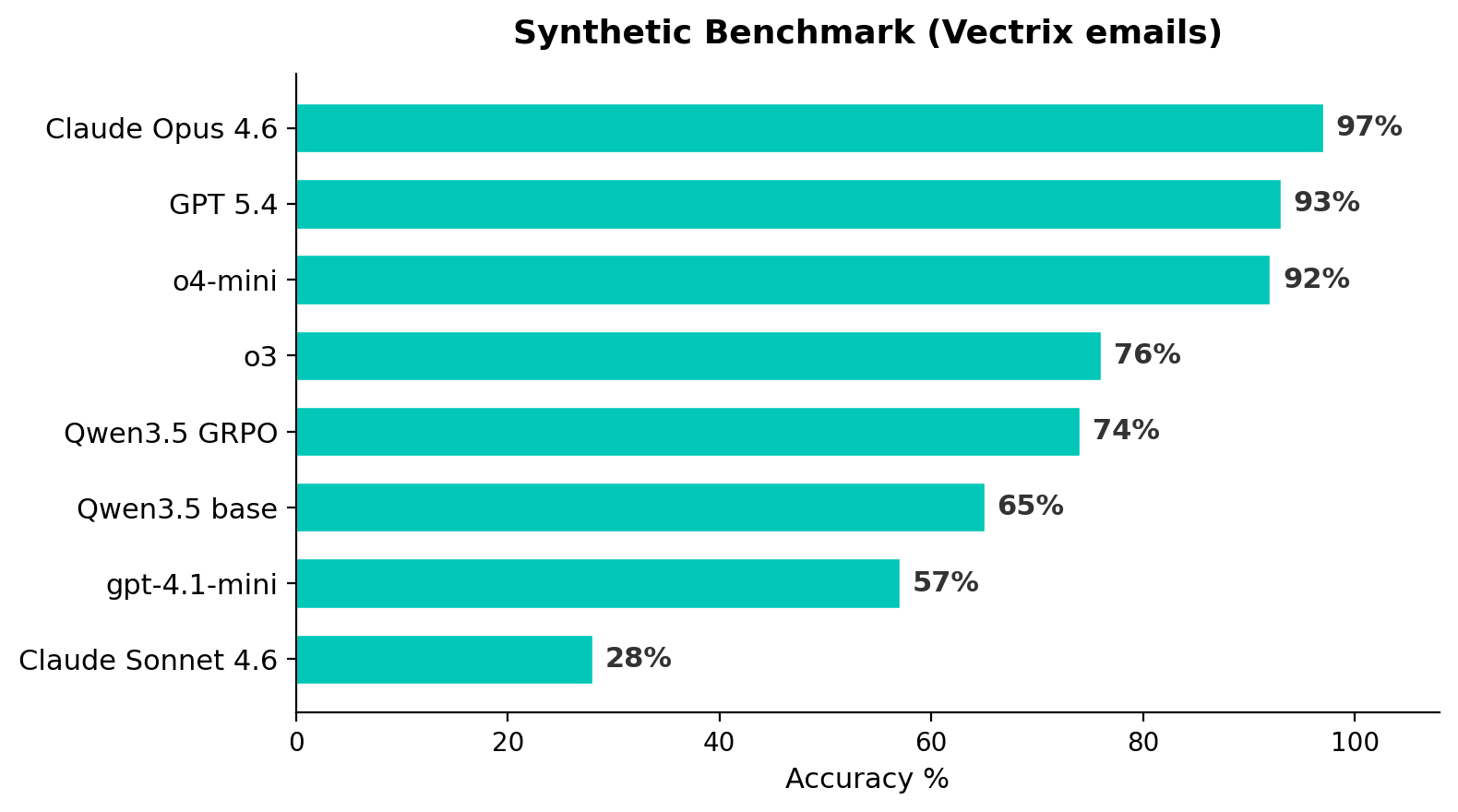
We evaluated 8 models on the synthetic benchmark. Two details matter:
Judge: gpt-4.1-mini at temperature=0 with an explicit prompt for handling paraphrases and alternative valid answers. We found that the default temperature introduced ~19% noise in judge decisions.
Agent prompt: We discovered that including “You may take up to 10 turns” in the system prompt artificially suppressed scores by up to 14pp for some models. Removing this and replacing with “Search thoroughly” unlocked significant performance, particularly for o3 and o4-mini. Both prompt versions are reported below.
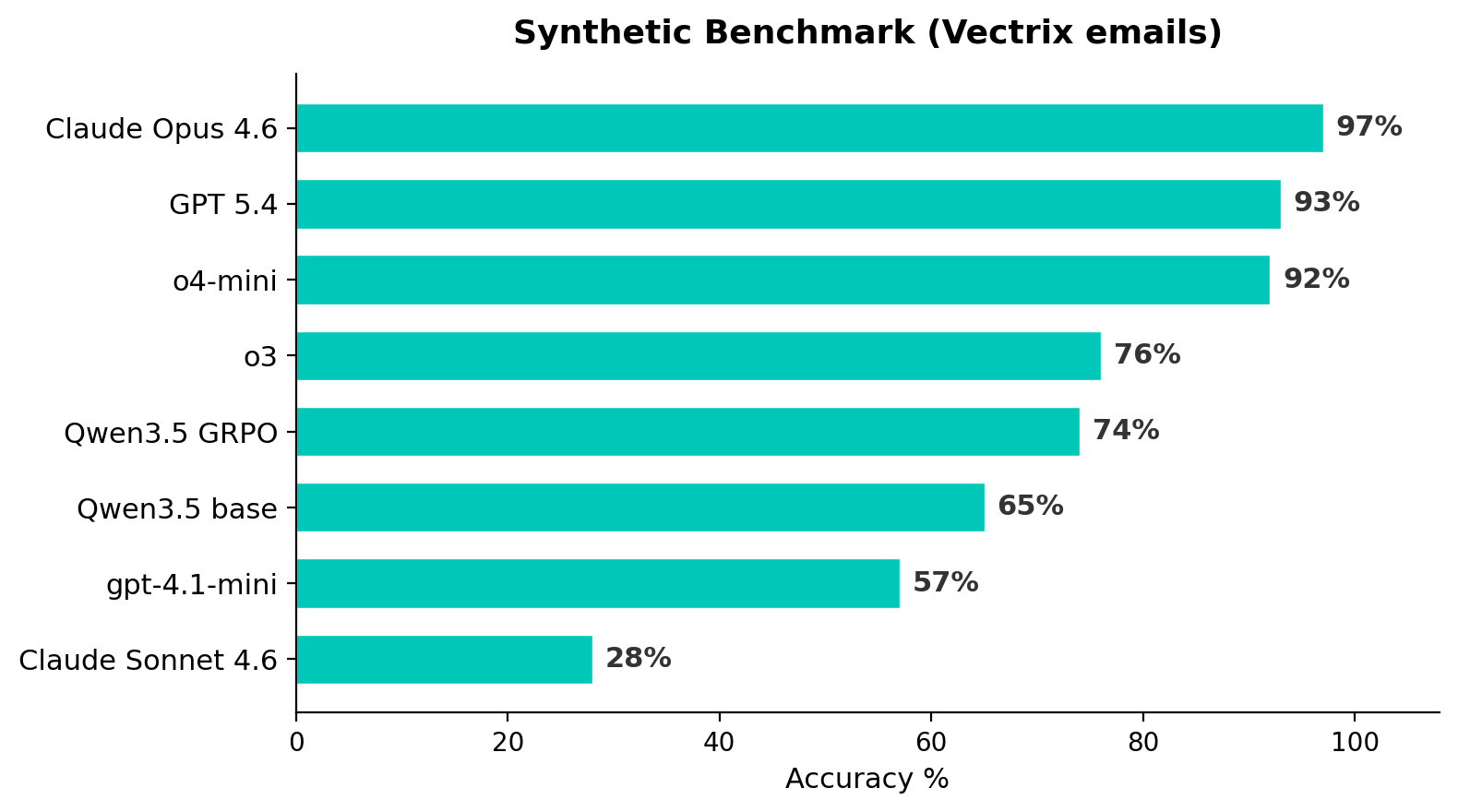
The synthetic benchmark separates models into clear tiers — from 28% to 97% — that the Enron benchmark cannot distinguish.
Evaluation: Enron benchmark
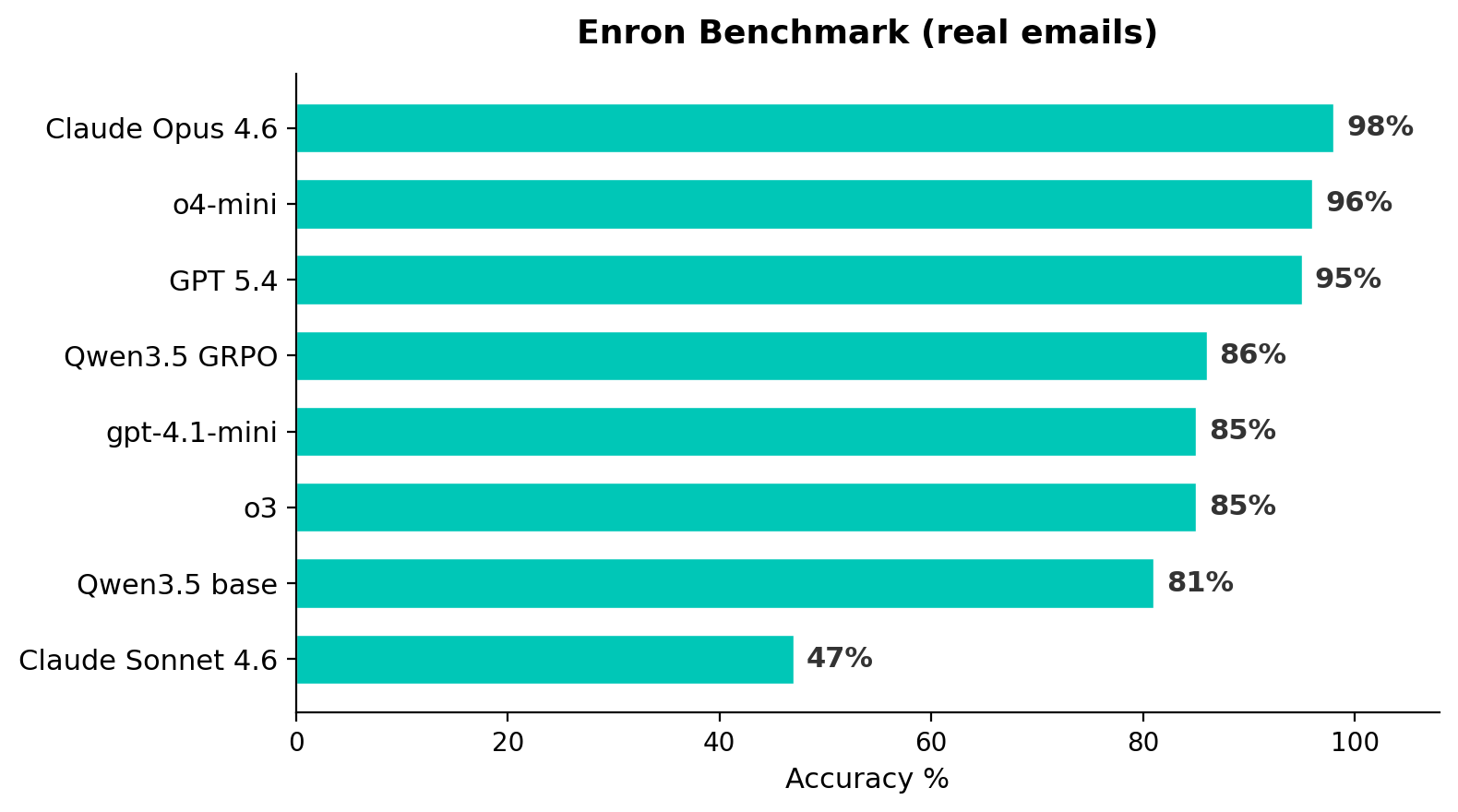
The top three frontier models are within 3pp on Enron — effectively saturated. Model rankings are consistent across both benchmarks (Kendall tau = 0.60)
The transfer test
This is the key experiment. We fine-tuned Qwen3.5-35B-A3B using GRPO on the synthetic training set via Tinker. The model trained exclusively on fictional Vectrix emails. We then evaluated it on real Enron emails it has never seen.
| Model / Metric | Synthetic | Enron |
|---|---|---|
| Qwen3.5 base | 65% | 81% |
| Qwen3.5 GRPO | 74% | 86% |
| Delta | +9pp | +5.5pp |
The synthetic-trained model improves on Enron by 5.5pp, beating both o3 (85%) and gpt-4.1-mini (85%) on real email data. This replicates the core result from OpenPipe’s original ART-E work — a fine-tuned open-source model beating a frontier reasoning model — but using a purely synthetic training corpus.
The takeaway: Synthetic data is an effective fuel for Reinforcement Learning
Synthetic data works as training data for agent tasks
The transfer test is the strongest evidence: improvements on synthetic data carry over to real data. The agent learns generalizable search strategies (when to search, what keywords to try, when to read full emails, when to commit to an answer) that don’t depend on the specific email corpus.
Synthetic test data can build powerful evals
Reviewing traces on our test set revealed two issues with the evaluation harness. First, prompt changes moved scores by up to 14pp. Second, the judge temperature setting introduced 19% noise. Human review of agent traces on synthetic test data quickly identified both issues. Even if you’re not fine-tuning models, this style of synthetic test data can reveal valuable insights about your agents.
Optimize RL with synthetic data from Fabricate
The vectrix email corpus and tasks are available on Huggingface, so you can reproduce these results or create your own search tasks. More importantly, you can start generating synthetic datasets for your own RL environments today with a free account of Fabricate. Get started at https://fabricate.tonic.ai/.
Acknowledgments
- OpenPipe for the original ART-E benchmark and blog post
- Prime Intellect for verifiers and the environment hub
- Thinking Machines / Tinker for RL training infrastructure
如有侵权请联系:admin#unsafe.sh