嗯,用户让我帮忙总结这篇文章,控制在一百个字以内,而且不需要用“文章内容总结”这样的开头。首先,我需要快速浏览文章内容,抓住主要信息。 文章主要讲的是一个网络攻击事件,分为三个阶段:初始阶段、高强度攻击阶段和逐渐下降阶段。攻击者使用了多种基础设施,包括商业主机和住宅宽带网络,涉及五个不同的自治系统。攻击者试图通过伪装浏览器和设备属性来隐藏自己的行为,但最终被DataDome的检测系统识别并阻止了。 接下来,我需要把这些信息浓缩到100字以内。重点包括攻击的时间线、使用的基础设施、攻击手段以及防御措施。同时,要确保语言简洁明了。 可能的结构是:先说攻击的时间和阶段,然后提到使用的基础设施和手段,最后说明被检测系统阻止的结果。这样就能在有限的字数内涵盖主要信息。 最后检查一下是否符合用户的要求:中文、100字以内、不使用特定开头。确保没有遗漏关键点。 </think> 该文章描述了一起为期13天的大规模网络抓取攻击事件,攻击者利用地理分布广泛的代理基础设施,在商业主机和住宅宽带网络之间切换以隐藏身份。通过伪装浏览器指纹和设备属性等手段发起高强度请求,峰值每两小时达到135万次恶意请求。最终被DataDome的意图检测引擎通过识别不一致的浏览器配置、服务器指纹及设备异常等威胁标记成功拦截。 2026-3-31 14:11:33 Author: securityboulevard.com(查看原文) 阅读量:3 收藏
Overview of the attack
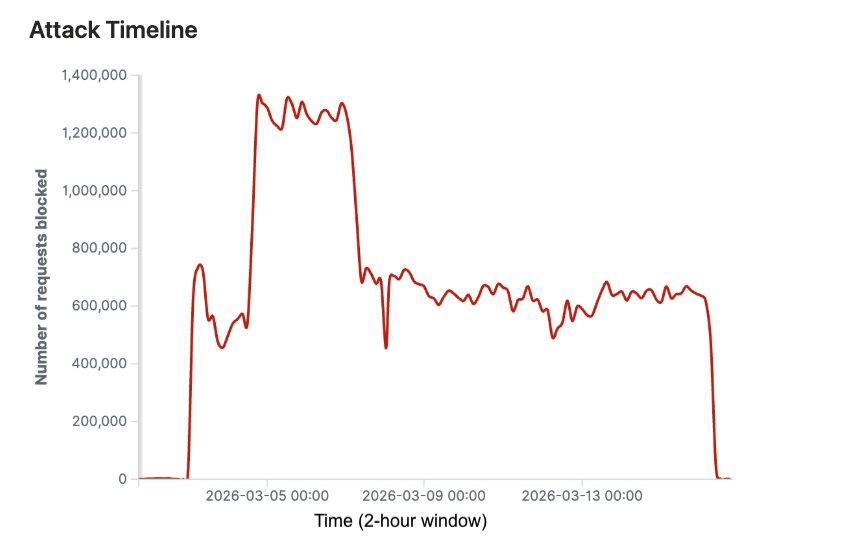
This scraping attack exhibited a distinct three-phase pattern, as seen on the graph below (Figure 1). It started on March 3rd with an initial spike on March 5th, transitioned into a sustained high-volume assault from March 5-9th, peaking at 1.35 million blocked requests every two hours, then gradually declined from March 9-15th before stopping abruptly.

Figure 1: Number of malicious requests blocked per 2-hour window
This pattern suggests the attackers tested detection thresholds early, scaled to maximum capacity mid-campaign, then kept at it consistently for days.
At this scale, even partial success would have yielded millions of scraped business listings, user reviews, and rating data worth substantial sums on secondary markets, as this data represents significant commercial value to the review platform’s competitors.
Attack infrastructure and distribution
The attack leveraged geographically diverse proxy infrastructure spanning commercial hosting and residential broadband networks.
Five autonomous systems accounted for all malicious traffic:
- AS13213: THG Hosting Limited (54.25%), a UK-based hosting provider
- AS262287: Latitude.sh LTDA (17.18%), a Brazilian hosting and data center provider, also known as Maxihost
- AS20001: Charter Communications Inc. (13.54%), a major US cable/broadband ISP (Spectrum)
- AS396356: Latitude.sh (10.34%), Latitude.sh US operations
- AS11404: Wave Broadband (4.69%), a US-based cable and internet service provider
While the top two ASNs are registered in the United Kingdom and Brazil, the vast majority of their active network infrastructure and IP allocations are physically located in the United States.
This infrastructure mix is deliberate. Hosting providers offer speed and scale, while residential ISPs provide IP addresses that appear legitimate and are harder to block without risking false positives against real users.
How was the attack detected & blocked?
DataDome’s intent-based detection engine blocked all 80 million malicious requests throughout the 13-day campaign by identifying multiple threat markers that indicated malicious automated scraping activity rather than legitimate user traffic.
Primary threat markers
Three primary detection signals provided the strongest evidence of malicious automated activity:
- Inconsistent browser profile: As the attack’s predominant threat marker, the attackers attempted to impersonate legitimate browsers but failed to maintain consistent browser fingerprints across sessions.
- Server-side fingerprints: A substantial portion of the blocked traffic presented server-side characteristics inconsistent with claimed client environments, suggesting the use of headless browsers or automation frameworks.
- Device and session anomalies: Inconsistent device attributes and unlikely session sequences indicate that the attack leveraged a distributed infrastructure with poor session management.
Secondary threat markers
Multiple secondary indicators reinforced the automated nature of the campaign:
- Identity spoofing: User-agent and geolocation inconsistencies suggest the attackers attempted to evade detection through header manipulation and geographic distribution.
- Proxy infrastructure: Significant anonymity proxy usage indicates attempts to obscure attack origins.
- Anti-detection measures: Forged headers and cookies demonstrated the attackers’ active efforts to bypass security controls.
- Challenge-solving capabilities: The presence of automated challenge-solving indicated a moderately sophisticated operation willing to invest in evasion capabilities.
Overall, the attack demonstrated intermediate-to-advanced characteristics, including distributed infrastructure, multiple evasion techniques, and challenge-solving capabilities.
However, the prevalence of consistency failures across browser, device, and session attributes suggested the attackers prioritized volume over stealth, likely relying on legitimate-looking but poorly implemented automation tools.
Protect your website from scraping attacks with DataDome
This attack demonstrates what modern scraping operations look like: 855,000 IPs across hosting and residential networks, intermediate evasion techniques, and 13 days of sustained pressure. Traditional defenses like IP blocking and rate limiting can’t keep up.
For example, before DataDome, Coop, a major Swiss e-commerce brand, was facing a heavy load on its servers due to scraping bots that significantly slowed page loading times:
“Our IT teams were burdened with the manual task of analyzing traffic to identify and block bad IP addresses, which was time-consuming and inefficient, as blocking an IP only provided temporary relief before bots would reappear using new addresses,” said Tobias Schläpfer, Web Applications Developer & Manager of Bot Protection at Coop.
After adding DataDome to its tech stack, Coop saw immediate improvements: 25% of the traffic—due to bad bot activity—disappeared, allowing web pages to load faster and improving the site’s SEO performance.
DataDome’s detection engine analyzes 5 trillion signals daily across thousands of AI models, stopping malicious bot and AI agent traffic at the edge to prevent attackers from causing damage to your business.
If your platform faces similar scraping threats, book a demo to see how DataDome can protect your websites, apps, and APIs without adding friction for legitimate users.
如有侵权请联系:admin#unsafe.sh