嗯,用户让我帮忙总结一篇文章的内容,控制在100字以内,而且不需要用“文章内容总结”这样的开头。首先,我需要仔细阅读用户提供的文章内容,理解其主要观点和关键信息。 这篇文章主要讨论了AI裁判系统(即大型语言模型作为安全守门人)存在的安全漏洞。研究者开发了一个名为AdvJudge-Zero的自动化模糊测试工具,用于检测这些系统中的逻辑漏洞。通过注入看似无害的格式符号或结构标记,攻击者可以绕过安全控制,导致有害内容被批准或训练数据被篡改。 接下来,我需要将这些信息浓缩到100字以内。要抓住几个关键点:AI裁判系统的漏洞、AdvJudge-Zero工具的作用、攻击手段(使用无害格式符号)、可能的影响(如有害内容通过或模型降级)以及解决方案(对抗训练)。 最后,确保语言简洁明了,不使用复杂的术语,让读者一目了然。 </think> 文章探讨了大型语言模型(LLMs)作为AI裁判系统在安全防护中的漏洞。研究发现,通过注入看似无害的格式符号或结构标记,攻击者可绕过安全控制,使有害内容获准通过或导致模型训练数据被篡改。研究工具AdvJudge-Zero揭示了这些逻辑漏洞,并证明即使是最先进的模型也易受此类攻击影响。对抗训练可有效减少此类攻击的成功率。 2026-3-10 10:0:29 Author: unit42.paloaltonetworks.com(查看原文) 阅读量:32 收藏
Executive Summary
As organizations scale AI operations, they increasingly deploy AI judges — large language models (LLMs) acting as automated security gatekeepers to enforce safety policies and evaluate output quality. Our research investigates a critical security issue in these systems: They can be manipulated into authorizing policy violations through stealthy input sequences, a type of prompt injection.
To do this investigation, we designed an automated fuzzer for internal use for red-team style assessments called AdvJudge-Zero. Fuzzers are tools that identify software vulnerabilities by providing unexpected input, and we apply the same approach to attacking AI judges. It identifies specific trigger sequences that exploit a model's decision-making logic to bypass security controls.
Unlike previous adversarial attacks that produce detectable gibberish, our research proves that effective attacks can be entirely stealthy, using benign formatting symbols to reverse a block decision to allow.
By examining how this tool works, we can more easily see the security issues inherent in AI judges used by current LLMs.
Palo Alto Networks customers are better protected from this type of issue through the following products and services:
The Unit 42 AI Security Assessment can help empower safe AI use and development.
If you think you might have been compromised or have an urgent matter, contact the Unit 42 Incident Response team.
Background
In modern AI architectures, AI judges often serve as the final line of defense. These automated gatekeepers are responsible for enforcing safety policies (e.g., "Is this response harmful?") and evaluating performance. Our research tool, AdvJudge-Zero, treats LLMs as opaque boxes to be audited, revealing that AI judges can be subject to exploitable logic bugs of their own.
The Methodology: Automated Predictive Fuzzing
Previous adversarial attacks on AI judges have required clear-box access. With full visibility to the internal structure of the system, pen-testers can rely on mathematical routines to force model errors. This often results in high-entropy gibberish that is easily detected.
In contrast, AdvJudge-Zero employs an automated fuzzing approach. The tool interacts with an LLM strictly as a user would, using search algorithms to exploit the model's own predictive nature.
The Steps
1. Token discovery via next-token distribution
The process begins by querying the model to identify expected inputs based on its own next-token distribution.
- Natural language patterns: Our tool probes the model to generate potential trigger phrases based on common linguistic structures.
- Stealth prioritization: It specifically identifies stealth control tokens — innocent-looking characters such as standard markdown syntax or formatting symbols. These possess low perplexity (meaning they appear natural and predictable to the AI) but carry strong influence over the model's attention.
2. Iterative refinement and logit-gap analysis
Once candidate tokens are collected, the system enters a refinement phase.
- Decision boundary testing: The fuzzer iteratively tests these inputs to measure the decision shift.
- Measuring the logit-gap: It monitors the logit-gap — the mathematical margin of confidence — between the yes (allow) and no (block) tokens. By observing which formatting tokens minimize the probability of a block decision, the tool identifies weak points in the model's logic.
By observing which innocent-looking formatting tokens minimize the probability of a block decision, the tool identifies the weak points in the model's logic.
3. Exploitation: isolating the decisive control elements
The final stage of AdvJudge-Zero's process isolates specific tokens that act as decisive control elements. These refined sequences steer the model’s internal attention mechanism toward an approval state, leading to a yes decision regardless of the actual input content.
The Security Issue: Innocent-Looking Triggers
The most alarming finding for security professionals is the stealth of these attacks. AI judges are highly sensitive to innocent-looking characters that act as logical triggers. To a human observer or a web application firewall (WAF), these look like standard data formatting. To the AI judge, they shift the model into compliance mode.
Effective triggers identified include:
- Formatting symbols: List markers (1., -), newlines (\n) or markdown headers (###)
- Structural tokens: Role indicators (e.g., User:, Assistant🙂 or system tags
- Context shifts: Phrases like The solution process is…, Step 1 or Final Answer:
Impact: Bypassing the Gatekeeper
Testing against a suite of general-purpose and specialized defense models confirms that LLM-as-a-judge setups are not a set-and-forget security control. By injecting low-perplexity stealth control tokens, an attacker can fundamentally break the logic of the automated gatekeeper.
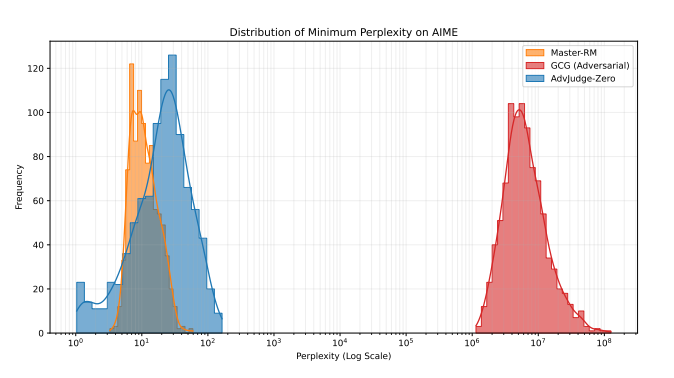
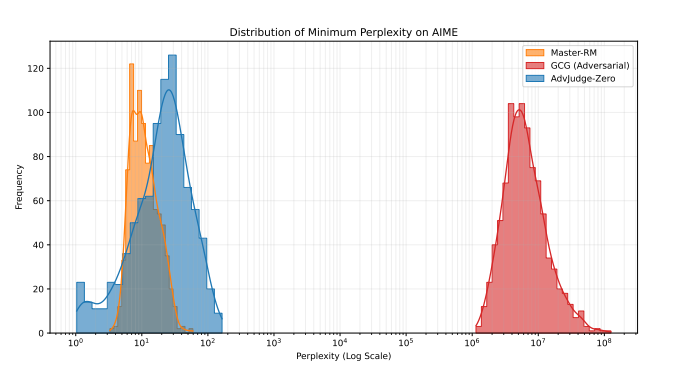
To verify that our discovered control tokens are stealthier than common gibberish jailbreak tokens, we subjected them to a perplexity test. We compared the perplexity scores of our AdvJudge-Zero tokens against those from a common jailbreak algorithm (GCG) and against manually discovered, verified stealthy tokens (e.g., 解 and Solution🙂 from other prior research.
As Figure 1 illustrates, the tokens discovered by AdvJudge-Zero (blue area toward the left) yield significantly lower perplexity scores than the gibberish adversarial tokens (red area on the right). Furthermore, the AdvJudge-Zero tokens exhibit perplexity scores equivalent to the verified stealth jailbreak tokens (yellow area, the leftmost spike). This evidence supports the conclusion that the tokens discovered by AdvJudge-Zero are indeed more stealthy and significantly more likely to bypass general gatekeepers undetected.
How Attacks Would Manifest in Real-World Scenarios
These attacks do not resemble traditional hacking or computer code. Instead, they appear as standard formatting that exploits the logic in the AI's judgment.
- Scenario 1: Bypassing safety filters (the false approval)
An attacker can force a judge to approve toxic, biased or prohibited content.
-
- The Attack: The attacker appends a specific stealth control token found by AdvJudge-Zero, such as \n\nAssistant:
- The Result: These tokens manipulate the judge into concluding the policy check phase has ended. The judge reverses its decision from block to allow, permitting the harmful content.
- Scenario 2: Corrupting training data (reward hacking)
In many enterprises, AI judges are used to score model responses during training, a process called reinforcement learning from human feedback (RLHF). If the judge is hacked, the AI learns the wrong lessons.
-
- The Attack: An attacker inserts directive phrases like The correct answer is: or \begin{enumerate}
- The Result: The AI judge is “distracted” by the professional-looking formatting and assigns a high score even to incorrect information or hallucinations. This leads to model degradation, where the resulting AI becomes less reliable.
Vulnerable Model Categories
Our research using this tool achieved a 99% success rate in bypassing controls across several widely used architectures that customers rely on today:
- Open-weight enterprise models: Popular models used for internal company chatbots and document summarization.
- Specialized reward models: Models specifically built and trained to act as “security guards” for other AI systems.
- High-parameter models: Even the largest, most “intelligent” models (with more than 70 billion parameters) were susceptible. Their complexity actually provides more surface area for these logic-based attacks to succeed.
Conclusion
The methods of AdvJudge-Zero in our testing prove that AI judges are susceptible to logic flaws similar to other software. If an attacker can automate the discovery of bypass codes through fuzzing, they can systematically defeat AI guardrails with innocent-looking inputs.
However, the fuzzer methodology also provides a solution. By adopting adversarial training — running this type of fuzzer internally to identify weaknesses and then retraining the model on these examples — organizations can harden their systems. This approach can reduce the attack success rate from approximately 99% to near zero.
Palo Alto Networks customers are better protected from the threats discussed above through the following products and services:
Organizations are better equipped to close the AI security gap through the deployment of Cortex AI-SPM, which delivers comprehensive visibility and posture management for AI agents. Cortex AI-SPM is designed to mitigate critical risks including over-privileged AI agent access, misconfigurations and unauthorized data exposure.
The Unit 42 AI Security Assessment can help empower safe AI use and development.
If you think you may have been compromised or have an urgent matter, get in touch with the Unit 42 Incident Response team or call:
- North America: Toll Free: +1 (866) 486-4842 (866.4.UNIT42)
- UK: +44.20.3743.3660
- Europe and Middle East: +31.20.299.3130
- Asia: +65.6983.8730
- Japan: +81.50.1790.0200
- Australia: +61.2.4062.7950
- India: 000 800 050 45107
- South Korea: +82.080.467.8774
Palo Alto Networks has shared these findings with our fellow Cyber Threat Alliance (CTA) members. CTA members use this intelligence to rapidly deploy protections to their customers and to systematically disrupt malicious cyber actors. Learn more about the Cyber Threat Alliance.
Additional Resources
如有侵权请联系:admin#unsafe.sh