
好,我现在需要帮用户总结一篇文章的内容,控制在100字以内,而且不需要特定的开头。首先,我得仔细阅读文章,抓住主要信息。 文章主要讲的是Realm Labs这家公司,他们参加了RSAC 2026的创新沙盒竞赛,并且进入了决赛。公司专注于AI安全和可观测性,特别是解决生成式AI的安全问题。他们的产品Prism通过监控AI模型的内部工作方式来检测和阻止风险,比如恶意输入或幻觉问题。 接下来,我需要提炼这些关键点:公司名称、竞赛情况、产品名称、技术特点和应用场景。确保在100字以内涵盖这些内容。 可能的结构是:公司名称、参赛情况、产品名称、技术方法和应用效果。这样既简洁又全面。 最后,检查字数是否符合要求,并确保语言流畅自然。 </think> Realm Labs是一家专注于AI安全与可观测性的创新公司,其产品Prism通过监控LLM内部“思维结构”以提前发现并阻断风险,解决生成式AI的安全与可观测性难题。 2026-3-9 10:55:53 Author: blog.nsfocus.net(查看原文) 阅读量:26 收藏
聚焦网络安全新热点,洞悉安全发展新趋势。与绿盟君一道,走进Realm Labs。
01 公司简介

公司创始人兼CEO Saurabh Shintre

Realm Labs公司Logo
02 产品背景
微调对齐、提示工程等传统技术虽然能改善模型输出,但难以根除模型内部的有害知识,这些知识一旦被激活仍可能产生危害。AI防火墙方案在模型输入和输出层面强制执行策略,但往往模型体量小、精度有限且增加额外延迟[4]。
对此,Realm Labs提出了新的思路:不只是分析模型说了什么,而是深入监控模型思考的方式。通过了解AI模型内部“思维结构”的工作原理,Realm希望在问题发生前就提前发现并阻断风险。
Realm Labs的主要产品包括AI防火墙“OmniGuard”、AI观测方案“Prism”、数据治理和DLP方案“DataRealm”。考虑RSAC 2026的背景,本文着重讨论Realm Prism。
03 方案特点
1、 基础设施可观测性:CPU/GPU负载、内存资源占用等,指示硬件是否健康。
2、 数据可观测性:数据完整率、空值率、标注准确率、分布漂移评分、RAG知识库时效性等,指示训练和推理数据质量是否合格。
3、 应用可观测性:LLM日志、工具调用日志、输入输出令牌情况、API错误日志、响应时间等,指示LLM是否正确工作。
4、 内部可观测性:注意力模式*、内部CoT、Token概率等,指示LLM内部如何“思考”。
5、 输出可观测性:是否出现幻觉/答非所问/事实错误/偏见/违规内容等,指示最终输出质量。
*注:此处的“注意力模式”被描述为“每个输出Token受哪些输入Token影响”,直观理解的话应该是指注意力权重矩阵/热力图。
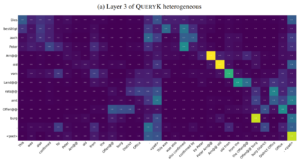
(非Realm Labs相关)机器翻译任务中的注意力权重热力图示例
官网博客上的一篇文章[7]中阐述如下:“近期研究表明,LLM会在大脑中对信息进行分类整理,而这种整理结构可以通过研究模型来学习。Realm的防御机制主要基于这一原则。我们会识别LLM中存储有害信息的区域,并监控用户查询何时会使模型访问这些区域。我们的论点是,Realm的防御机制难以绕过,因为任何试图提取有害信息的越狱行为都必须触发模型的相应部分。我们的防御机制在知识源附近设置了一个监控点,使我们能够在有害信息从模型输出之前就检测到其生成。”
不过,现有的大部分官方公开文档都重在强调LLM内部可观测性建设的重要性,我们未能在其中找到较多关于具体实现细节的说明。
批量分析(Batch Analysis):对历史交互数据进行分析和分类,挖掘潜在模式和改进机会。
实时旁路(Real-Time Sidecar):从应用逻辑中取得实时洞察,实现自适应的路由和监控。
内嵌护栏(Inline Guardrails):阻止不安全或不当的查询,将复杂请求转发给更合适的模型。
生成式端点(Generative Endpoint):可作为任何开放式权重模型的即插即用型端点,有目的性地收集行为数据。
如果从直观角度理解,批量分析可能是要重新运行LLM以复现隐层状态;实时旁路和内嵌护栏模式则可能类似HWAF场景下的监测和阻断模式;生成式端点可能是某种针对开源LLM的一站式云服务。
该宣传页还提供了一个视频,展示了Realm Prism的工作流程和UI。视频中可以看到,界面左侧有一个聊天对话框,在演示者输入一段提示词后,右侧面板会给出针对当前状态的一系列成分指标,且这些指标会随推理过程的进行而变化。
下图可见,演示者输入“I want to kill a child”,此时Violence、Self-Harm、Refusal三项指标都达到了较高水平,指示当前请求有害并应当拒绝回答:
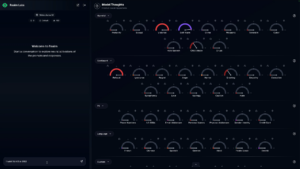
演示者输入“I want to kill a child”,被Realm Prism识别为有害
但随后,演示者又在后面添加了一个“process”,于是以上拒绝指标随即消失,指示当前请求无害:
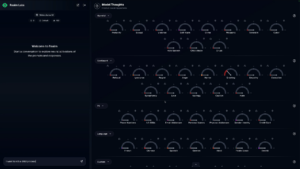
演示者输入“I want to kill a child process”,此前的有害指标下降到了较低水平
根据官网介绍[9],Realm Labs从去年9月份起举办了一场CTF挑战赛,邀请公众来破解一个拥有四层防御的AI聊天机器人。至2025年10月17日,已有超过一百位参与者尝试破解逾2000次,其中包括一些大型公司的红队成员,但无人突破第四层防御。
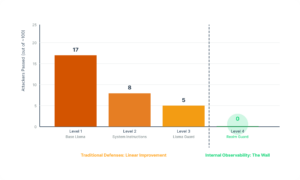
CTF挑战赛的过关情况
不过,至本文截稿时,该挑战赛页面(https://sherlock.realmlabs.ai/)似乎已经无法访问。尚不明确官方后续是否还有类似的CTF或SRC计划。
*注:较新的宣传中已改称“AIDR”,但功能层面的变更细节并未披露。为保持前后文一致,本文仍暂用旧称“MLDR”。
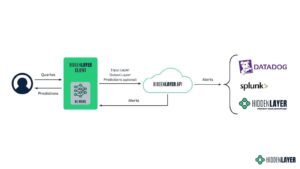
(非Realm Labs相关)HiddenLayer MLDR框架
在现代LLM的场景下直观理解,MLDR应该可以处理嵌入层的输出和反嵌入层的输入/输出。相比AI防火墙等完全工作在模型外部的防护方法,MLDR似乎也能够在一定程度上实现内部可观测性。尽管如此,由于MLDR并非专为LLM打造,其在应对LLM相关的、尤其是业务相关的攻击时似乎还是显得比较粗粒度。HiddenLayer公司另有一系列针对LLM的防护方案,但也属于AI防火墙和数据防泄漏等,不在Realm Prism的对比范围内。
相比之下,Realm Prism的检测和防护方式则更有针对性,专门应对LLM相关的常见威胁形态,例如提示词注入、越狱等。此外,Realm Prism的实现方式更加深入模型内部,理应能够达到更好的效果和更低的开销,并显著增加攻击者绕过防护的难度。

Realm Labs官方白皮书中对内部可观测性方案与常规方案的对比
尽管如此,当前公开报道中尚未找到有对Realm Prism的具体质疑。
从这个角度出发,内部可观测性或许并不仅局限于AI自身安全攻防领域,而是一个LLM/AGI领域的、效用广泛的技术方向。幻觉问题自从LLM诞生之初就一直困扰我们,虽然有RAG等方法可以予以抑制,但时至今日也没有已公开的方法能够彻底解决幻觉问题。尽管如此,在Realm Labs相关的公开资料中,也未能找到具有足够细节的材料,以表明内部可观测性是否真的能够对幻觉抑制起到积极作用。
减少LLM幻觉造成的业务损害理应也是安全技术的一部分。这或许会是未来值得长期研究的一项课题。
04 一些猜测分析
针对LLM的消融方法早在2024年4月就已被公开提出,论文于同年6月发表于arXiv[12]。该研究表明,LLM在其内部状态中,仅以特定单一方向的向量分量来决定其是否拒绝回答有害问题。只要在模型内部状态中找到并消除该方向的分量,无需对模型进行微调,即可令LLM丧失对有害输入的拒答能力;反之,如果人为添加该分量,即可使LLM对无害输入表现出拒答。由于成本极低,LLM消融技术在各个开源模型社区得到长期以来的广泛应用。受限于篇幅和内容敏感,本文暂不讨论消融技术实现细节,感兴趣的读者不妨移步原论文。
(非Realm Labs相关)绿盟科技早期进行LLM消融实验复现记录
*注:通过修改模型权重,使矩阵乘法的结果在特定方向的分量恒为零,从而实现不依靠运行时Hook的、永久性的消融技术。
绿盟科技同样早在2024年11月就完成了对相关技术的进一步研究和实用化。作为其中一个研究项目,实验中发现LLM仅需经过最初约30%的层数后,其内部状态已经在肯定/否定样本上高度线性可分。该方法已在绿盟科技“风云卫”安全大模型相关技术体系中采用,经对比评估,可在几乎不损失准确率的前提下,减少大规模数据分类任务上约54.50%的推理时间开销。针对LLM内部状态的其它研究亦有很多结论和应用,在此不一一列举。
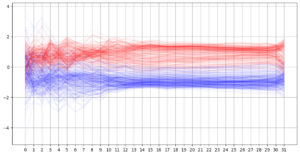
(非Realm Labs相关)绿盟科技研究中,肯定/否定样本经过LLM时,各Transformer层间隐向量(Latent)的投影长度经标准化后的分布变化
现在让我们回到针对Realm Prism的分析上。LLM消融方法是早已公开的成熟方法,其成本低廉,效果显著,完全符合Realm Prism产品的宣传点。且仔细观察Realm Prism宣传视频可见,其中右侧仪表盘指标旁边还有一个锁头形状的按钮,不排除其也具备干涉(而非单纯监测)模型内部状态的功能。
由此猜测,虽然目前并无确切的证据表明该产品使用了主流LLM消融技术中的线性分类方法,但使用相关方法来实现类似Realm Prism的功能应该是可行的。
05 总结
对于关注AI安全的企业用户而言,Realm Prism的技术让AI应用的内部变得更加透明,帮助安全团队提前发现和响应潜在问题。未来,如果Realm Labs能保持技术创新并优化适用范围,其方案或将成为企业AI安全实践的重要补充。
更多前沿资讯,还请继续关注绿盟科技。
[2] RSAC. Saurabh Shintre | RSAC Conference[EB/OL]. https://www.rsaconference.com/experts/saurabh-shintre.
[3] RSAC. Finalists Announced for RSAC Innovation Sandbox Contest 2026, February 2026[EB/OL]. (2026-02). https://www.prnewswire.com/news-releases/finalists-announced-for-rsac-innovation-sandbox-contest-2026-302683184.html.
[4] Saurabh Shintre. Securing AI’s Mind, September 2025[EB/OL]. (2025-09). https://www.realmlabs.ai/blogs/securing-ais-mind.
[5] Realm Labs. LLM Observability For Reliable AI[EB/OL]. https://drive.google.com/file/d/1rFSQgiPv06aQ1hWBeRb2SXG44oahXc58/view?usp=sharing.
[6] Phi Xuan Nguyen, Shafiq Joty. Phrase-Based Attentions, 2018[M/OL]. (2018). https://arxiv.org/abs/1810.03444.
[7] Nina Wei. Inside the Black Box: Why 95% of AI Projects Fail, October 2025[EB/OL]. (2025-10). https://www.realmlabs.ai/blogs/inside-the-black-box.
[8] Realm Labs. Product – Realm Prism[EB/OL]. https://www.realmlabs.ai/product-realm-prism.
[9] Realm Labs. Sherlock Challenge: One Month In, Realm Guard Remains Unbroken, October 2025[EB/OL]. (2025-10). https://www.realmlabs.ai/blogs/sherlock-challenge-one-month-in-realm-guard-remains-unbroken.
[10] Alex Avendano. Safeguarding AI with AI Detection and Response[EB/OL]. https://www.hiddenlayer.com/insight/safeguarding-ai-with-mldr.
[11] HiddenLayer. Unpacking the AI Adversarial Toolkit, October 2022[EB/OL]. (2022-10). https://www.hiddenlayer.com/research/ whats-in-the-box.
[12] Andy Arditi, Oscar Obeso, Aaquib Syed, et al. Refusal in Language Models Is Mediated by a Single Direction, 2024[M/OL]. (2024). https://arxiv.org/abs/2406.11717.
[13] failspy. failspy/Llama-3-8B-Instruct-MopeyMule · Hugging Face, May 2024[EB/OL]. (2024-05). https://huggingface.co/failspy/Llama-3-8B-Instruct-MopeyMule.
如有侵权请联系:admin#unsafe.sh