嗯,用户让我总结一下这篇文章的内容,控制在一百个字以内,而且不需要用“文章内容总结”或者“这篇文章”这样的开头。直接写描述就行。 首先,我需要快速浏览一下文章。看起来这篇文章主要讲的是如何利用大型语言模型(LLMs)从网络威胁情报(CTI)报告中提取和上下文化信息,将其转化为结构化数据用于后续应用。文章还讨论了相关挑战和权衡,并通过实证评估支持这些观点。 接下来,我需要提取关键点:应用LLMs于CTI信息提取,自动化处理,结构化数据生成,面临的挑战如报告结构差异、模型推理能力等,以及评估结果和未来展望。 然后,我得把这些内容浓缩到一百个字以内。可能的结构是:介绍目的、方法、挑战、结果和未来方向。 最后,确保语言简洁明了,不使用复杂的术语,直接传达核心信息。 </think> 大型语言模型(LLMs)可用于从网络威胁情报(CTI)报告中提取和上下文化信息,将其转化为结构化数据以支持防御工作流程。文章探讨了LLMs在CTI领域的应用潜力、关键挑战及权衡,并通过实证评估展示了其可行性。尽管面临报告结构差异和推理能力限制等挑战,LLMs仍可显著提高信息提取效率和自动化水平。 2026-3-9 10:0:26 Author: www.sentinelone.com(查看原文) 阅读量:24 收藏
Overview
In this blog post, we explore the application of large language models (LLMs) for extracting and contextualizing information from cyber threat intelligence (CTI) reports, turning narrative into structured data for downstream use.
As part of our broader continuous innovation in automating defense workflows with AI, this work focuses on the use of LLMs for information extraction in the CTI domain, outlining relevant insights, key challenges, and trade‑offs involved, supported by empirical evaluations. It is intended to support CTI teams and cyber defense organizations considering the development or adoption of AI‑enabled CTI information extraction capabilities.
CTI reports contain rich information about adversary behavior, infrastructure, and intent. For defenders, they provide timely insights into ongoing campaigns and evolving techniques, helping teams keep pace with the current threat landscape, prioritize detections, and accelerate their response to novel threats. However, because this information is conveyed in narrative form, the manual extraction of relevant elements such as indicators of compromise (IOCs) and contextual details is slow, inconsistent, and difficult to scale. LLMs have the potential to automate this task by interpreting narratives, extracting explicit data, and inferring implicit relationships, transforming text into structured, machine‑readable data that supports defense workflows at all levels of automation.
AI for Extracting and Contextualizing CTI Information
Non‑LLM‑based methods, such as pattern‑matching approaches, can automatically and accurately extract explicit elements that follow well‑defined formats, for example atomic IOCs like IP addresses or file hashes. However, LLM‑driven extraction can be applied in more complex scenarios that require semantic understanding or adaptable inclusion criteria beyond simple pattern recognition.
Certain use cases may demand selective IOC extraction, for example by focusing on attacker‑registered domains while filtering out benign ones. Such distinctions often depend on contextual cues within the report, such as whether a domain is described as adversary‑registered infrastructure or simply mentioned in passing during the description of normal network behavior.
In addition, capturing the broader context that extends the operational value of atomic IOCs, such as infrastructure ownership, compromise state, their association with specific threat actors, victimology, and characteristic TTPs, or the role within an intrusion chain, remains a demanding challenge for non‑LLM approaches. Unlike atomic IOCs, these contextual details are often implicit rather than explicitly stated and therefore must be inferred.
This context is increasingly important as the standalone value of atomic IOCs continues to diminish in an era of rapid shifts in adversary techniques, tools, and infrastructure. It is important for guiding accurate and effective detection and response decisions involving the associated IOCs, as well as for other purposes, such as uncovering related malicious activities through context‑aware threat hunting and developing detections that retain value beyond individual observables.
Beyond improving detection, response, and threat hunting, context‑enriched intelligence extracted by LLMs can integrate with organizational defense systems such as threat‑intelligence platforms (TIPs) to support collaboration, correlation, prioritization, and organization‑wide sharing of intelligence. This integration transforms CTI narrative into structured, linked knowledge that can be leveraged across organizational defense workflows.
Scope and Structure
The extraction of information from CTI narratives using LLMs has been explored in previous research. This blog complements existing work by taking a practical perspective, focusing on selective IOC extraction, the structured representation of contextual information, and the automated reconstruction of adversary activity into playbook-level sequences with inferred chronology. It presents a preliminary study intended to demonstrate feasibility and highlight key design, evaluation, and operational considerations in designing LLM‑driven CTI information extraction systems.
The aim is to share practical insights drawn from our own experience rather than to rank individual models or propose a complete solution. To illustrate these points, we use a basic, preliminary setup as a running example, and evaluate general‑purpose LLMs to measure out‑of‑the‑box performance in extracting information.
The following sections outline our approach along with the evaluation methodology and results. We begin by describing the overall workflow and data structures used for information extraction, followed by the method used to instruct and guide the LLM during extraction. We then present the evaluation setup and discuss results across multiple dimensions, including extraction performance, processing efficiency, and output quality.
Information Extraction | Workflow Overview
Our preliminary workflow for extracting information from CTI reports consists of three phases.
Phase 1 | Report Ingestion and Sanitization
In Phase 1, the Sanitizer component ingests reports in HTML format and removes non-content elements such as navigation (nav), headers, footers, sidebars (aside), scripts (script), and styles (style). It then converts the remaining content to clean, plain text, preserving the text of headings, paragraphs, lists, and tables, while discarding the HTML markup. This reduces noise, standardizes inputs across sources, and lowers the risk of errors in downstream extraction.
Phase 2 | LLM‑Based Extraction
In Phase 2, the sanitized report content is passed to LLM-based extractors, the Infrastructure, Executables, and Playbook Extractor. They use an LLM to reason over the input text in order to extract information and produce structured output. Each extractor’s LLM is guided by:
- an extractor-specific output data model that defines entities and associated attributes, data types, and inter-entity relationships;
- LLM instructions that define the extraction policy, including value assignment criteria for fields defined in the data model.
The output of each extractor is a JSON record generated according to its data model, effectively turning narrative text into structured, machine-readable data.
Each extractor’s data model is an in‑house specification tailored to its analytical scope. For example, the Infrastructure and Executables Extractor use data models that define atomic IOC types, specifically Infrastructure (domain or IP) for the Infrastructure Extractor and Hash (MD5, SHA-1, or SHA-256 hash) for the Executables Extractor, as well as per-type IOC contextual attributes. Together, these models define 12 IOC contextual attributes, typed either as enumerations (categorical labels) or as open‑text strings. The categorical attributes capture aspects of the operational context of network and executable artifacts, such as their functional roles within threat actor operations (usage), their behavioral properties (injection), and the points in time or intrusion stages at which they are employed (attack_stage). The open-text attributes capture explicitly reported details extracted from the input text, such as file paths (filepath), command‑line arguments (cmdline), or names of injected processes (injected_processes).
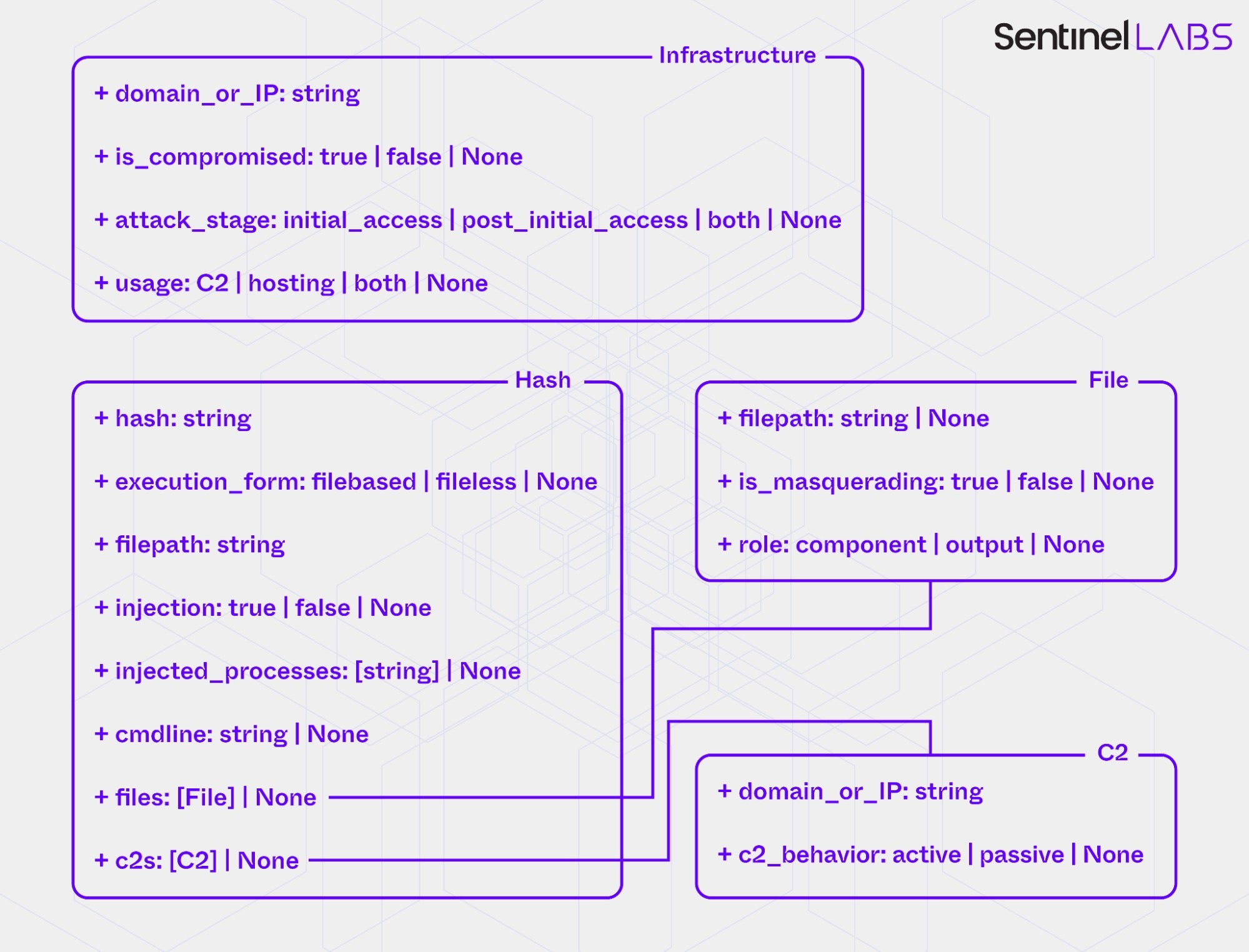
Across the extractors’ data models, the categorical attributes are implemented as tri‑ or four‑state variables that standardize annotation. For example, they allow the LLM to distinguish between positive and negative evidence in binary contexts (true and false), assign a composite value when evidence supports more than one allowed category (both), and denote cases where evidence is absent or insufficient for classification (None).
To instantiate data model entities, the LLMs of the Infrastructure and Executables Extractor first selectively extract atomic IOCs and then assign values to the associated contextual attributes for each extracted IOC by performing:
- classification for categorical attributes, assigning a value from a predefined set of allowed labels;
- text extraction for open‑text attributes, assigning unconstrained string values taken directly from the input text.
The selective extraction of network‑related atomic IOCs (domains and IPs) focuses on indicators that have played an active role in the adversary activity described in the input report, encompassing both attacker‑owned assets and compromised external systems deliberately used for malicious purposes. The intent is to capture infrastructure that has directly supported the activity while excluding references to resources that fall outside the actor’s control, such as legitimate infrastructure mentioned during the description of normal network behavior. The selective extraction of hashes focuses on those associated with malicious or attacker‑used software components that have been deployed within victim environments, including both custom malware and publicly available tools used for offensive purposes. It excludes hashes corresponding to legitimate third‑party binaries that appear in attack chains, for example, as part of DLL hijacking or other forms of abuse.
The LLM of the Playbook Extractor instantiates data model entities as follows:
- Extracts distinct threat actor actions, represented by
Stepentities, and groups them into one or morePlaybookentities. APlaybookrepresents a sequence ofStepentities within a single adversary operation or campaign. SeparatePlaybookentities are created when the report shows explicit or clearly implied operational separations, for example, distinct campaign names, non‑overlapping timeframes, different targets or regions, or unrelated objectives. - Infers the chronological order of the
Stepentities within eachPlaybookand creates directed relationships between them to reflect the inferred sequence. - Maps each
Stepto the appropriate MITRE ATT&CK tactic, technique, and, where applicable, sub-technique recorded in the associatedTTPentity. Theprocedureattribute ofTTPrecords the distinct threat actor action identified earlier. - Extracts contextual information about the threat actor attributed to each
Playbook(for example, actor name, aliases, country of origin, and motivation) and links aThreatActorentity representing the actor to the correspondingPlaybookentities.
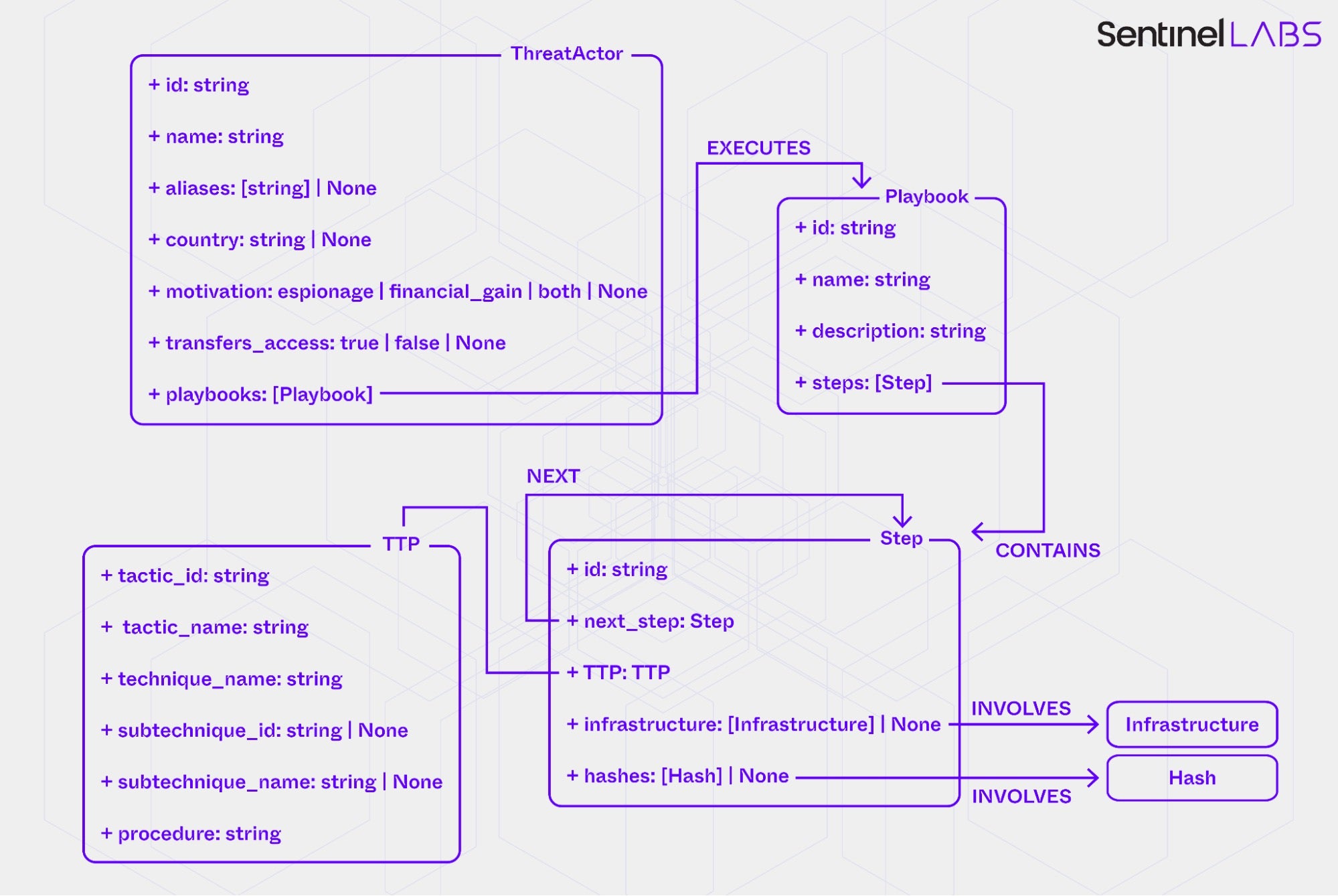
The Playbook Extractor constructs a directed acyclic graph over ThreatActor, Playbook, Step, Infrastructure, and Hash entities by adding links according to sequencing and linking rules, with the goal of producing self-contained flows with consistent chronology, valid MITRE ATT&CK mappings, and coherent relationships.
Phase 3 | Knowledge Graph Assembly
In Phase 3, the LLM of the Playbook Extractor maps each atomic IOC and its contextual attributes (an Infrastructure or Hash entity instantiated by the Infrastructure or Executables Extractor) to threat actor actions that use or produce it; that is, establishes INVOLVES relationships from Step entities. This combines all extracted information into a unified knowledge graph, which serves as the final consolidated output for downstream applications.
Task Granularity and Input Modality
Each LLM‑based extractor performs multiple distinct subtasks in Phase 2. For example, the Infrastructure and Executables Extractor selectively extract atomic IOCs and interpret the input text to assign values to IOC contextual attributes, a task that requires context‑sensitive, evidence‑based inference. The Playbook Extractor handles an even more complex set of operations, including identifying distinct threat actor actions, inferring their chronological order, mapping them to MITRE ATT&CK tactics, techniques, and sub-techniques, and linking any attributed threat actors and IOCs to the relevant actions.
Depending on task complexity and the diversity of reasoning steps required, LLMs may find multi‑objective workloads challenging, as attention and inference capacity are distributed across diverse goals. Dividing broad tasks into smaller components may sharpen focus, preserve contextual consistency, and improve extraction and classification quality. However, segmentation adds orchestration complexity, increases the risk of error propagation across subtasks, and may introduce latency. Choosing the right granularity requires balancing the gains against these costs.
Beyond task segmentation, input modality and coverage are also important for extraction outcomes. In our preliminary implementation, the LLM‑based extractors operate only on textual content, leaving a gap in coverage for reports that embed relevant text in images, such as command lines, tool outputs, or malware code snippets, which is common in CTI reporting. Using optical character recognition (OCR) to extract text from images in reports can make this information accessible to LLM‑based extraction workflows and enrich the input with observables and contextual details that would otherwise be lost. However, OCR introduces trade‑offs that should be accounted for, as transcription errors, noise from low‑quality or stylized visuals, and inconsistencies in extracted text formatting can complicate downstream processing.
Data Model Selection and Design
Industry‑standard data models, like STIX, provide broad interoperability and predefined representations for common CTI concepts such as atomic IOCs, malware, threat actors, campaigns, and techniques, and the relationships among them. Adopting or extending an existing standard as the output data model in CTI extraction workflows is particularly appropriate for organizations that require compatibility with external feeds or cross‑organizational sharing platforms. This approach is also suitable when the cost of designing and maintaining a custom in‑house model cannot be justified.
In contrast, a custom data model can be more effective when extraction and analysis serve internal, organization‑specific needs rather than cross‑organizational sharing. Such a model provides full control over scope and structure, allowing its size and complexity to match current requirements. This flexibility supports precise extraction of the information relevant to specific use cases without being constrained by predefined relationships, hierarchical elements, or granularity imposed by external data models, which may be unnecessarily complex for certain applications. For example, data model organization, such as the depth of elements within the structural hierarchy, carries semantic weight that shapes LLM inference, making deliberate design choices important.
Our case exemplifies this scenario. Each extractor uses a custom output data model optimized for internal analytics and tailored to integrate with proprietary formats of endpoint telemetry and other log data. This alignment supports specific internal applications such as proactive threat hunting and telemetry enrichment. For example, the top-level IOC contextual attribute is_compromised distinguishes infrastructure intentionally set up by the attacker from legitimate but compromised assets. This distinction can make the difference between targeted action and unintended disruption. If a domain observed in our telemetry is described in a processed CTI report as attacker-controlled infrastructure, traffic can be blocked and related domains identified by pivoting on attributes such as certificate fingerprints or registration data. In contrast, if the domain is described as belonging to a compromised legitimate website, blocking policies can be applied in a way that minimizes interruption to legitimate services, favoring precise and reversible measures such as URL‑specific filtering and follow‑up verification before relaxing controls.
An important aspect of designing an output data model for CTI extraction workflows is the linguistic formulation of elements such as field names and categorical labels. Just as hierarchy depth carries interpretive significance, wording can influence how LLMs allocate attention during classification and text extraction. Because LLMs rely on natural‑language context to guide reasoning, phrasing choices for field names and category labels implicitly frame how evidence is interpreted and may cue different decision boundaries, potentially biasing a model toward particular outcomes. For example, we have observed measurable differences in classification accuracy when LLMs assign values to categorical IOC contextual attributes under different phrasings of field names and labels. Using terminology that guides LLM reasoning toward the intended interpretation and decision boundaries helps ensure that the LLM’s attention and inference are aligned with the extraction objectives.
Information Extraction | LLM Instructions
The LLM‑based extractors operate using structured prompts with domain‑specific instructions aligned with their respective data models. For example, guided by these prompts, the Infrastructure and Executables Extractor analyze the entire input text, selectively extract atomic IOCs that meet the defined criteria, and assign values to contextual IOC attributes based on the available evidence.
Each extractor operates within defined reasoning boundaries. Across all extractors, the prompts combine extractor‑specific task scopes with a unified reasoning policy, which defines how the LLM interprets evidence. They constrain the model’s reasoning to explicit and strongly implied evidence, with the degree of inference bounded by an evidence‑grading scale. Each extraction decision is graded by evidence strength: High for explicit statements, Medium for strongly implied information, and Low for weak or speculative cues, which the LLM is instructed to ignore.
Building on this evidence‑grading approach, a unified decision‑making framework ensures consistent logic in how values are assigned across all categorical fields. The framework also defines how multiple candidate values are resolved for the same field and specifies conflict‑resolution procedures for reconciling competing or contradictory evidence.
The following prompt excerpt, shown in Markdown format, illustrates some of the evidence grading and decision‑making principles.
### Evidence and inference
- Use only information that is explicitly stated or strongly implied in the report. Weak, associative, or speculative cues must not be used for classification.
- Evidence confidence levels:
- High: explicit statements or direct behavioural descriptions.
- Medium: strongly implied and supported by multiple consistent observations.
- Low: weak or speculative — ignore low‑confidence signals when assigning values.
- Absence of evidence for one label is not evidence for another.
### Decision‑making framework
(Applies to all fields including tri‑state and multi‑class labels; e.g., `{'true','false','None'}`)
1. Identify candidate labels (set C) = labels in the field’s allowed set (excluding 'None') that have explicit or strongly implied evidence according to the field definition.
2. If C is empty: Set the field to 'None' (the report lacks qualifying evidence for any label).
3. If |C|=1: Set the field to that label.
4. If |C|>1:
- If the field defines a valid composite/union label (e.g.,'both') and evidence supports all involved roles on the same artifact → assign the union label.
- Otherwise apply the field’s specific precedence/conflict rule.
Prompt Optimization and Conceptual Boundaries
The effectiveness of the instructions in guiding the LLM‑based extractors to accurately extract information depends not only on prompt design but also on the models that interpret them. Because model versions and families differ in how they represent and interpret language, infer meaning, and translate instructions into reasoning steps, the same prompt can produce model‑specific differences in interpretive and response behavior.
Prompts can be optimized for the reasoning patterns and instruction‑following behavior of a specific model, which in the context of this work can improve information extraction quality. However, model‑specific prompt optimization increases maintenance overhead when models are frequently updated or replaced. For example, in managed environments where older model versions may be deprecated over time, each update requires not only prompt adjustments but also a reevaluation of the prompt’s effectiveness before deployment.
In addition to model-specific prompt optimization, defining the specific semantic scope of categorical data model fields that encode analytical concepts is an important yet challenging aspect of designing effective LLM instructions for information extraction. These scope definitions determine how these fields translate complex real‑world operational behavior and relationships into discrete categories that the model can apply consistently. They function as a layer of conceptual modeling that mediates between the descriptive language of reports and the structured reasoning required for extraction, encoding within the instructions the definitional decisions that establish each field’s scope. Well‑defined scopes enable consistent model interpretation and coherence across downstream analytical processes, whereas vague or internally inconsistent boundaries lead to misclassification and undermine overall reliability.
In our case, clear scope definition is particularly important for the categorical IOC contextual attributes, which require deliberate, analytically grounded boundaries. For example, defining the scope of usage, which distinguishes infrastructure used for command‑and‑control from that used only to host malicious content or store exfiltrated data, requires giving the model clarity on multiple concepts, including what constitutes command‑and‑control, malicious content, and passive hosting.
Evaluation Setup
In the following sections, we present the results of an evaluation study of several off‑the‑shelf, general‑purpose language models from OpenAI and Anthropic — GPT‑4.1, GPT‑5, GPT‑5.2, Claude Sonnet 4.5, and Claude Opus 4.5 — used within the Infrastructure, Executables, and Playbook Extractor without any additional fine‑tuning or task‑specific adaptation. We quantified performance from multiple complementary perspectives using the same set of extractor prompts across all models.
Where applicable, the reasoning mode for the GPT models was set to High, the Claude models were configured with a thinking budget of 16000 tokens to allow for extended reasoning, and the LLM temperature parameter was set to 0 to minimize randomness and reduce non‑deterministic behavior.
The reported results are preliminary and based on a limited ground truth dataset comprising 343 atomic IOCs and 1859 labeled IOC contextual attribute instances. The purpose of this evaluation is not to provide conclusive performance comparisons but to demonstrate the feasibility of using LLMs for information extraction from threat intelligence narratives.
To account for the inherent non-determinism of LLMs and to provide statistically reliable results, all reported metric values were obtained through repeated executions of each evaluation experiment until the point estimates reached a 95% confidence level with a relative precision of less than 5%.
Manual Ground Truth Creation
There is no readily available common ground truth dataset that enables evaluation of LLM performance in extracting information from CTI reports. A dataset suitable for this purpose must be aligned with the LLMs’ expected outputs, reflecting the same data model, field definitions, and scope boundaries used during extraction to enable direct comparison between LLM predictions and reference data. Differences in analytical focus and output data model design across potential CTI information extraction approaches effectively preclude the possibility of a common ground truth dataset. Even though standardized data models such as STIX could, in principle, support a shared ground truth dataset, implementations can add custom extensions to accommodate organization‑specific analytical needs, reintroducing differences in data model design and scope.
Creating a ground truth dataset aligned with the output data model and analytical scope of a given CTI information extraction approach is a time‑consuming process that relies on manual annotation guided by expert judgment to ensure accurate interpretation of CTI reports and consistent application of field‑scope definitions and label criteria.
Ground Truth for Ambiguous Evidence
When extracting and classifying information from CTI reports into discrete values, both human analysts and LLMs face the inherent ambiguity of natural language reporting. CTI reports vary widely in precision and contextual completeness, meaning that informative cues supporting a given interpretation may be partial or implied rather than explicit. For example, an IP address listed in a generic IOC table might appear without any narrative cues describing its operational use. In such cases, the value of the usage attribute in our data model becomes uncertain: one annotator may assign C2 if the report primarily discusses adversary C2 infrastructure, whereas another, applying stricter evidentiary standards, may assign None, indicating insufficient evidence to support any other specific label. Neither interpretation is necessarily incorrect; they reflect differing thresholds for inference, with one adopting a looser contextual assumption and the other following a stricter evidence‑based criterion.
The adequacy of contextual detail in CTI reports depends on the type of information being extracted, how much inference is allowed to bridge contextual gaps, and other factors, including the report’s intended audience and analytical scope. For example, when extracting information about technical artifacts, strategic reports aimed at broad audiences may lack the specificity needed for reliable extraction, whereas reports written for technical analysts are more likely to include the context required to support such extraction. Beyond the quantity of contextual detail, ambiguity can also result from linguistic and structural sources of uncertainty in CTI reporting, such as inconsistent terminology, implicit assumptions, and condensed summaries.
While a highly conservative strategy can be applied, allowing minimal interpretive flexibility and constraining extraction to cases only where very explicit supporting evidence is present, such rigidity may be impractical. If most of the information to be extracted depends on ambiguous evidence, the overall volume of extracted information would become severely limited.
Considering the inherent limitations and ambiguities of CTI reporting, even experienced human analysts, who are afforded a degree of interpretive flexibility, may assess the available evidence differently, with some adopting broader interpretations while others adhere to stricter criteria. LLMs granted comparable interpretive flexibility show similar indecisiveness when confronted with ambiguous or incomplete information, producing outputs that mirror the uncertainty observed in human reasoning.
To ensure accurate evaluation of LLMs that extract information from CTI narratives with some interpretive flexibility, the ground truth datasets should account for these ambiguities. For genuinely underspecified cases, it may be more realistic to define multiple acceptable values rather than a single correct label. However, developing such flexible ground truth increases the labeling effort: ideally, for each ground truth element where the correct value may be ambiguous, multiple human annotators independently assess the evidence and then reach consensus on whether the ambiguity is genuine and which alternative values are plausibly supported. This procedure captures genuine uncertainty without compromising methodological rigor.
The ground truth dataset we use in our evaluation study applies this flexible labeling approach, allowing multiple values to be considered correct for truly ambiguous cases.
As a reminder, the Infrastructure and Executables Extractor apply controls when assigning values to IOC contextual attributes that constrain how evidence is evaluated and how conflicting or insufficient cues are resolved. These controls limit classification to explicit or strongly implied contextual evidence and apply field‑specific rules that default to None when no support for another value is found. Even with these controls and deterministic inference settings applied where applicable (temperature = 0), models can still produce different label assignments across repeated runs when the input evidence is ambiguous. Such variation arises not from stochastic sampling but from minor non‑deterministic aspects of inference, such as floating‑point rounding or context‑evaluation differences, which slightly alter internal probability weighting. When a case lies near a conceptual decision boundary, between sufficient and insufficient evidence, or between competing interpretations supported by similar cues, these micro‑variations can shift the balance enough for the model to favour a different plausible label. Across models, these effects combine with differences in calibration of what constitutes strong, sufficient, or insufficient evidence, producing similar alternation among valid values under the same policy.
To illustrate this tendency of LLMs to alternate between valid values in ambiguous cases, we measured internal decision consistency for each evaluated LLM on two IOC contextual attributes for which different values were frequently accepted as valid by expert annotators. Specifically, we calculate two metrics for is_compromised and attack_stage, with the reported values conditioned on each model’s extracted IOCs:
IOCs with Pₒ < 1 (%): The proportion of extracted IOCs for which, across repeated runs under identical conditions, the LLM assigned two or more different values for the same attribute, alternating among the values that the expert annotators defined as valid (yielding observed agreementPₒ< 1 across runs). This metric indicates how often the model switches among valid values under identical conditions.- Average mode‑based observed disagreement
D̄ₒ: For the subset of IOCs withPₒ< 1, the average proportion of the LLM-assigned attribute values across the repeated runs that differ from the dominant (mode) value. This metric quantifies the degree of variability in the model’s assigned values across those runs.
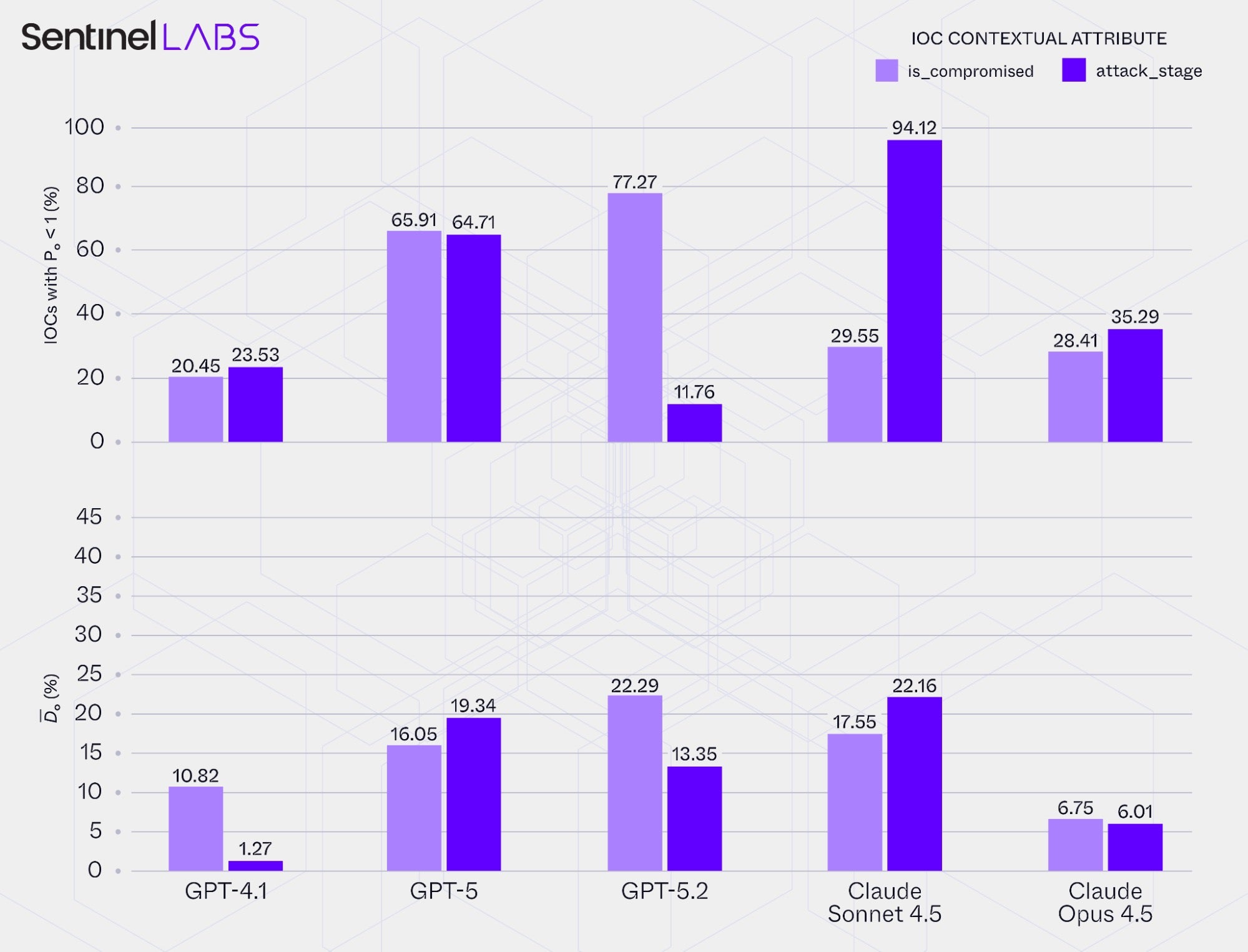
Together, these metrics describe each model’s sensitivity to ambiguous or borderline inference conditions. Higher percentages of IOCs with Pₒ < 1 indicate greater fluctuation in how the LLM interprets ambiguous evidence, while higher D̄ₒ values show that, in cases where the model switches between valid attribute values, its decisions are more evenly distributed among the alternatives rather than converging on a single dominant interpretation.
These observations highlight why allowing multiple valid values in the ground truth data is important when evaluating LLMs that extract information from CTI narratives with some interpretive flexibility. Recognizing and encoding the ambiguity inherent in CTI reports ensures that evaluation reflects the realistic bounds of human interpretation rather than enforcing artificial certainty. The same principle should extend to downstream applications, where processes or systems consuming LLM outputs should be able to accommodate alternative but defensible value assignments.
Evaluation | Selective IOC Extraction
This section presents the performance of the evaluated LLMs in selective IOC extraction, measured using F1‑scores that capture the balance between precision (correctness of extracted atomic IOCs) and recall (extraction completeness under the predefined selection criteria). The reported values represent the average of the F1‑scores achieved by each LLM when used in both the Infrastructure and Executables Extractor, providing a single performance measure per model.
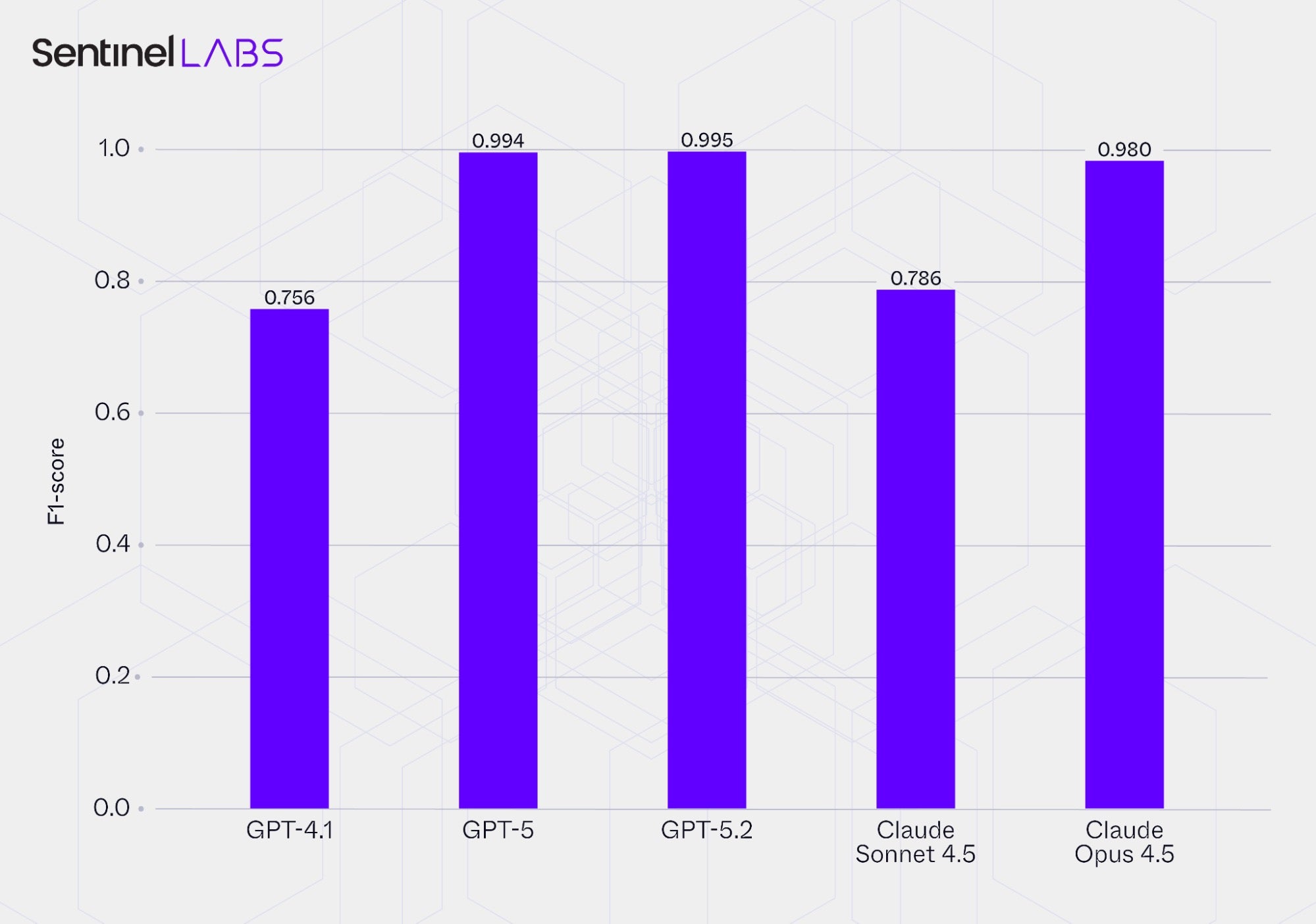
Report Structure and Formatting Effects
Variation in the formatting and structural presentation of IOCs, as well as in the availability of labeling and contextual cues such as column headers or textual indicators linking IOCs to relevant entities such as threat actors, malware, or campaigns, was a key factor contributing to differences in F1‑scores. CTI documents differ widely in how they present information, combining narrative text, tables, lists, and other structured elements with varying levels of detail and contextual labeling.
For example, some reports present IOCs in visually dense formats, such as tables listing multiple hash representations in a single row. These cases require the model to interpret logical relationships within structured data, for example how corresponding values relate across columns. This involves a degree of relational reasoning that some models apply inconsistently, particularly when labeling or contextual cues are absent or ambiguous, leading to missed indicators and reduced recall.
This observation highlights how the structure and formatting of CTI reports directly influence LLM extraction performance. Simplicity in IOC presentation, together with explicit labeling and unambiguous contextual cues, helps LLMs extract IOCs more accurately and consistently while maintaining interpretability for human analysts.
Evaluation | Report Processing Time
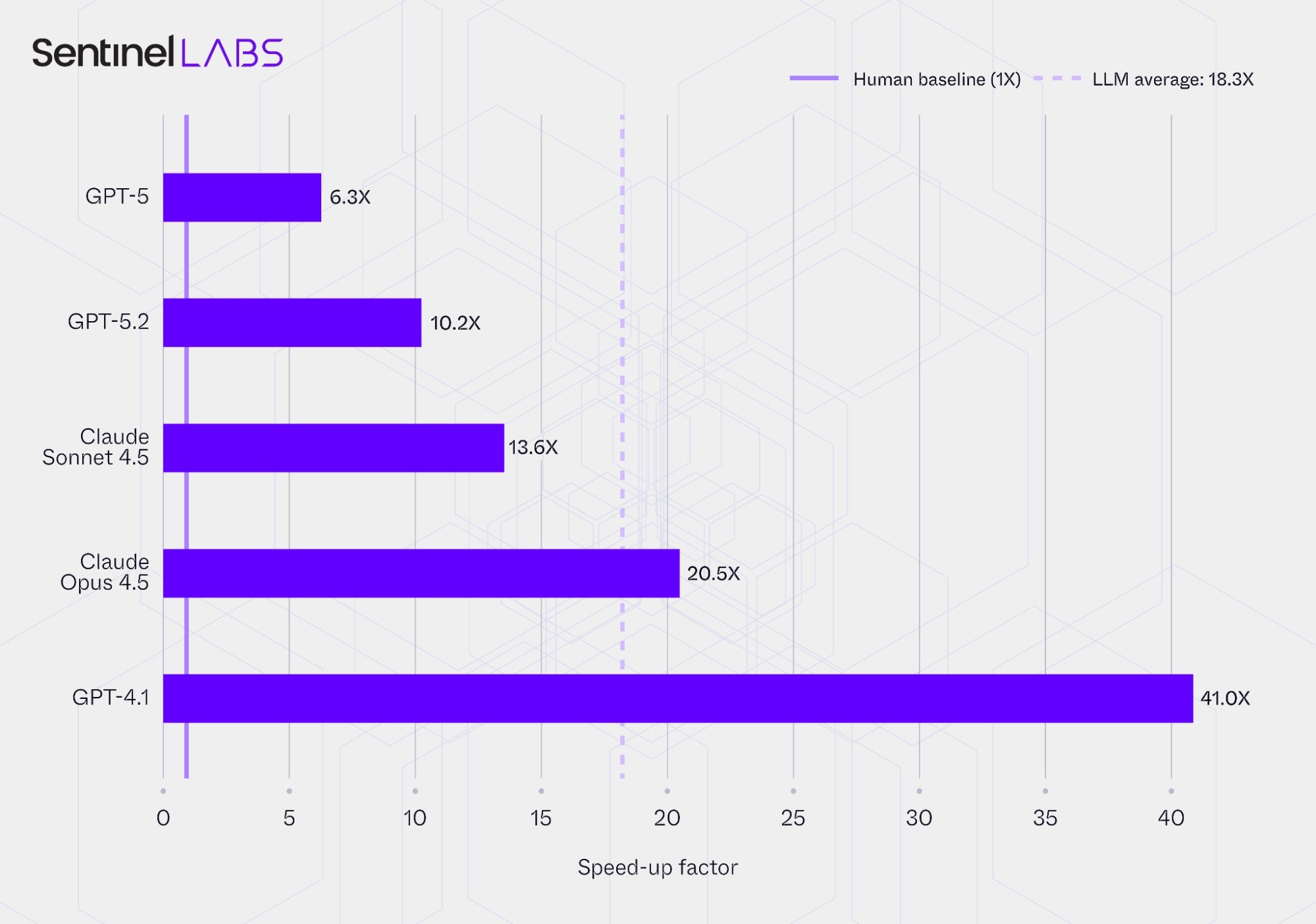
The charts below compare the average report processing times and the corresponding speed‑ups achieved by the Infrastructure and Executables Extractor configured with each evaluated LLM, alongside the baseline time required by human analysts. Report processing time refers to the end‑to‑end duration required to process a CTI report, including ingestion, reasoning, selective IOC extraction, IOC attribute value assignment, and output generation.
The metric represents the average time per report in minutes, rounded to the nearest half minute, and the speed‑up values express the same results relative to human processing time. The reported values represent the combined per‑report average processing time from both extractors, with the human baseline reflecting the equivalent manual processing of both extraction tasks, and are conditioned on each LLM’s extracted IOCs.
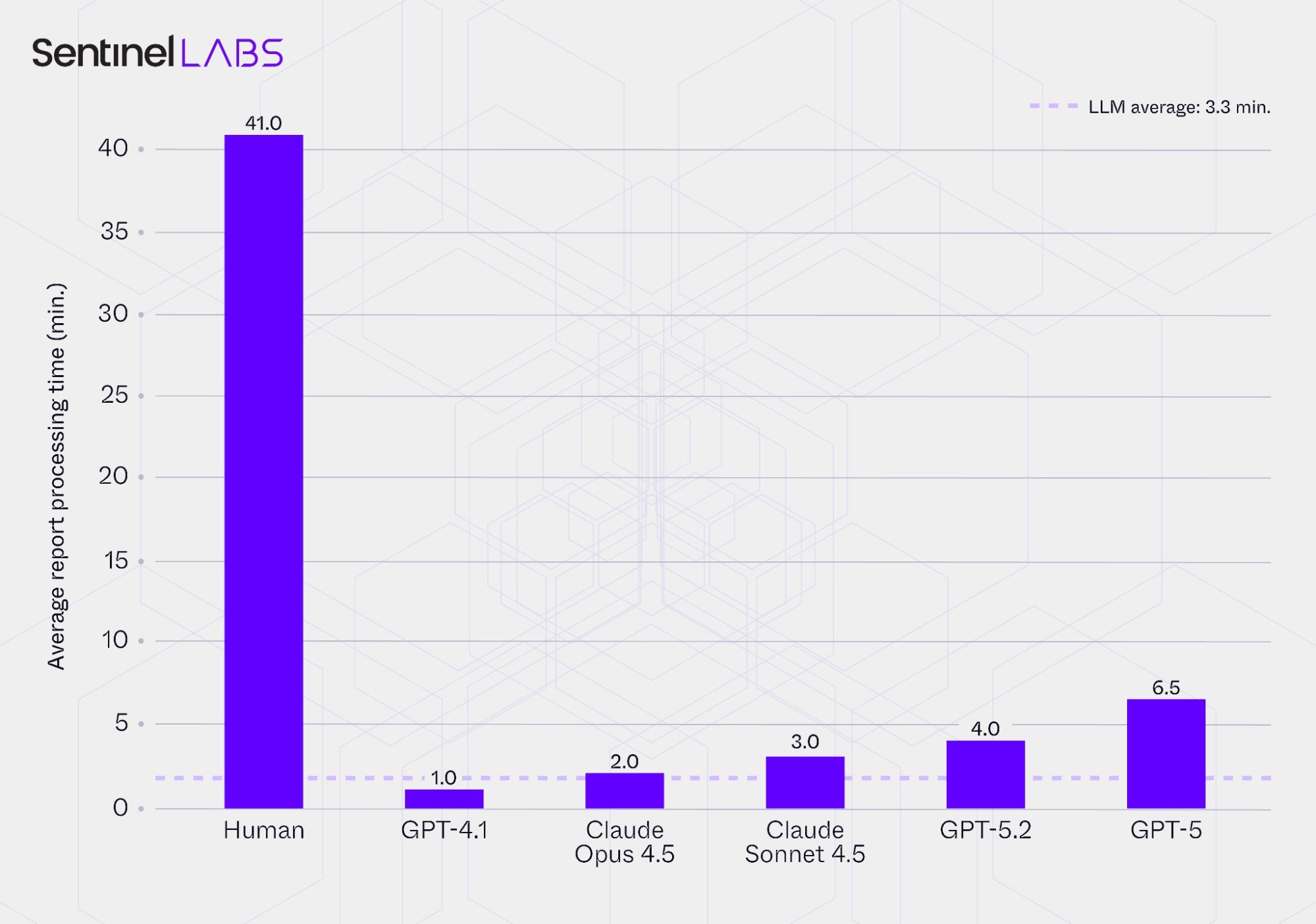
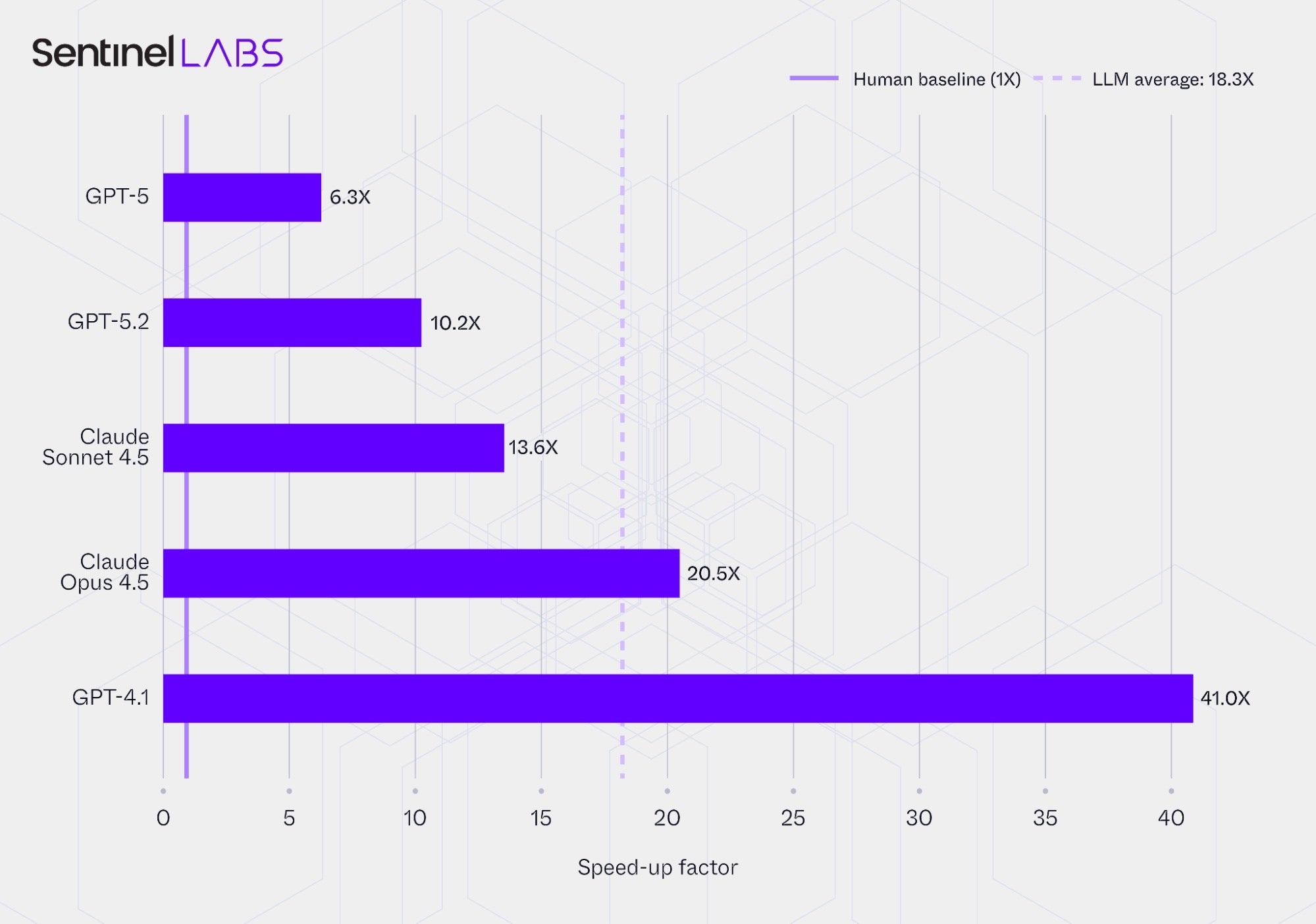
In all cases, the use of LLMs substantially reduced report processing time compared with human analysts, whose average was 41 minutes per report. On average, the extractors required about 3.3 minutes per report, corresponding to an aggregate speed‑up of more than 18 times. Even the slowest LLM-based setup processed reports approximately 6 times faster than the human baseline, while the fastest reduced average processing time by more than 97% relative to the human baseline. These results highlight the considerable time‑efficiency gains achieved by using LLMs for CTI information extraction compared with traditional human workflows, though with accompanying trade‑offs in extraction completeness and correctness.
Evaluation | Accuracy and Precision
The chart below reports accuracy and precision in assigning values to IOC contextual attributes for each evaluated LLM when operating within the Infrastructure and Executables Extractor:
- Standard accuracy: the mean of accuracies computed per IOC contextual attribute.
- Balanced accuracy: the mean of balanced accuracies computed per IOC contextual attribute; for each attribute, balanced accuracy is the average recall across value classes (for categorical attributes, the predefined labels; for open-text attributes,
Nonevs any assigned value), which accounts for differences in value‑class distributions in the ground truth. - Mean macro precision: the mean of macro precision values computed per IOC contextual attribute. Macro precision is the unweighted average of per-class precision within the attribute, based on the same value-class definition as above.
Averages are computed over all IOC contextual attributes combined across both extractors, and the reported metric values are conditioned on each LLM’s extracted IOCs.
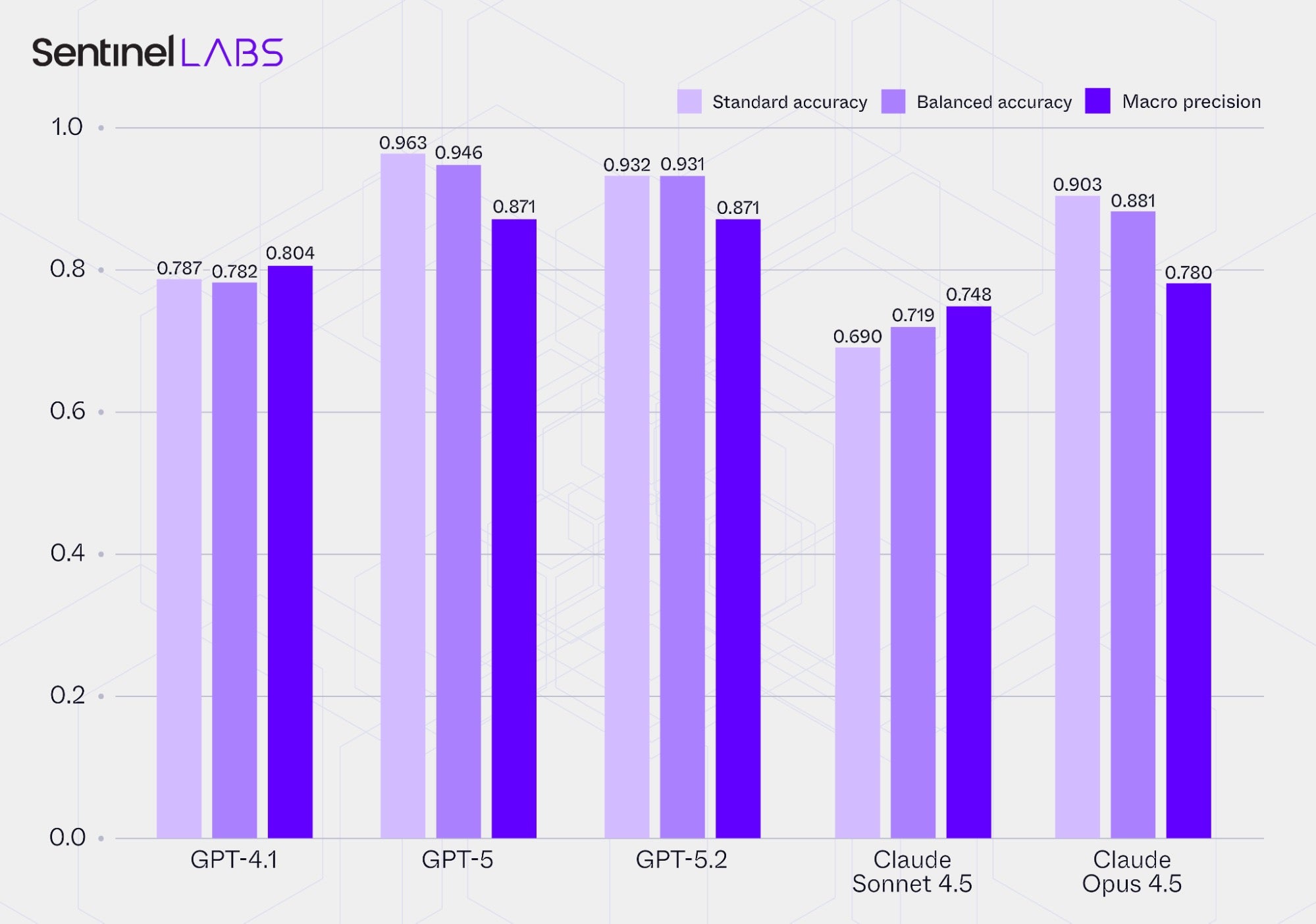
The variation in results across LLMs reflects the interplay of several factors, including differences in their capacity to detect, link, and interpret cues, the extent of permitted inference, adherence to instructions and instruction–model fit, and characteristics of the input CTI reports themselves. As discussed earlier, CTI reports vary widely along multiple dimensions relevant to LLM‑driven information extraction, such as evidence strength, terminology, and format.
In practice, selecting an LLM for CTI information extraction and integrating its outputs into downstream applications requires setting accuracy and precision thresholds and weighing operational factors such as latency, all aligned with the requirements of the intended application. For example, fully automated mission‑critical applications warrant stricter thresholds than exploratory uses. Thresholds may be defined globally across all outputs and, where relevant, per output category.
Value Assignment Abstention
In our extraction pipeline, the value class None provides an explicit abstention option for value assignment, allowing the LLM to assign None to an IOC contextual attribute when evidence is insufficient, rather than outputting a concrete value. Since CTI reporting often provides only partial or implied cues supporting a definitive assignment, and at times no relevant cues at all, an abstention option is important: without it, the LLM would have to commit to an output despite insufficient evidence, inflating false positives and undermining trust in the outputs. By enabling abstention, a value such as None reduces incorrect assignments, communicates uncertainty, and allows downstream consumers to defer, escalate, or exclude that data point.
The abstention option requires careful consideration because it trades correctness, including accuracy and precision, against coverage. For instance, a lenient inference policy, which accepts weak evidence and broader contextual cues, reduces abstention and increases coverage but raises the risk of speculative assignments. In contrast, a strict policy that requires strong evidence and limits inference increases abstention and improves correctness but may suppress recoverable information.
Building on the accuracy and precision evaluation above, this section focuses on the LLMs’ abstention behavior, specifically their assignments of None. We report two error rates:
- False Discovery Rate (FDR): the proportion of
Noneassignments that were unwarranted (the LLM assignedNonewhile the ground truth specified a non-Nonevalue), indicating excessive conservatism; and - False Negative Rate (FNR), the proportion of instances that should have abstained but did not (the LLM assigned a non-
Nonevalue while the ground truth wasNone), indicating a tendency to speculate.
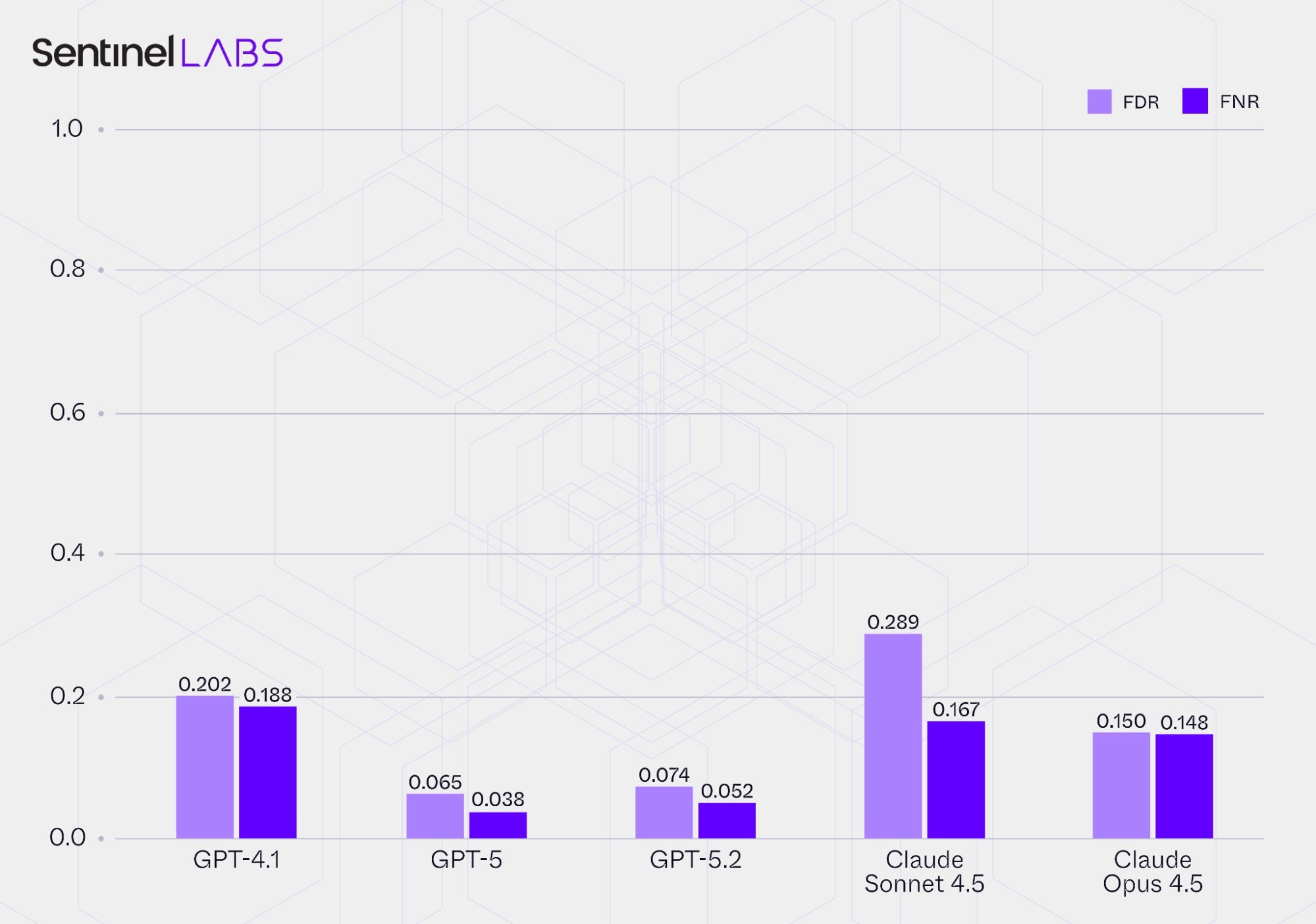
The observed variation in value assignment abstention across LLMs highlights the importance of evaluating this aspect of model behavior. Evaluation of abstention tendencies guides LLM selection and configuration, helps define acceptable ranges for abstention and speculative assignments appropriate to the use case, and informs the choice of operating settings that balance correctness and coverage, such as evidence criteria and the extent of permitted inference. Abstention behavior requires ongoing monitoring as input data changes over time to keep its frequency and speculation rates within target ranges for downstream applications.
Evaluation | LLM Ensemblies
Ensembling multiple LLMs can improve extraction correctness and stability by offsetting model‑specific limitations. Examples include majority voting, where the most frequent prediction across LLMs is selected, and judge‑based arbitration, in which one LLM reconciles conflicting outputs.
Effective ensembles balance operational compatibility, such as comparable inference latency and extraction performance, with statistical diversity. For example, when individual LLM accuracies differ substantially, an ensemble may provide little or no improvement. Under such conditions, a majority‑voting configuration with unweighted aggregation can even reduce overall accuracy, whereas weighted schemes that assign greater weight to more accurate models tend to converge toward the output of the strongest single model.
The potential benefit of any ensemble ultimately depends on the diversity of predictions and errors among its members. If models fail in similar ways, aggregation merely amplifies shared weaknesses, whereas if their errors differ or their predictions diverge, ensembling can provide more reliable and accurate results by combining complementary reasoning.
To illustrate this concept, the chart below reports the phi (φ) error correlation coefficient and the disagreement rate, calculated from the extraction outputs of GPT‑4.1 and Claude Sonnet 4.5 when operating within the Infrastructure and Executables Extractor. The error correlation coefficient measures the extent to which the two LLMs make the same mistakes, while the disagreement rate captures how often their predictions diverge on the same extraction field. Low error correlation combined with moderate disagreement indicates complementary reasoning and strong ensemble potential. In contrast, high error correlation and low disagreement suggest that the LLMs fail in similar ways, limiting the benefit of aggregation.
Both metrics were calculated on the same set of IOCs and corresponding contextual attributes for which the two LLMs produced predictions. The analysis focuses on a subset of IOC contextual attributes chosen to illustrate how error diversity manifests across attributes that differ in value format (categorical and open-text) and reasoning demands, ranging from typically localized factual attributes (is_compromised and injection) to contextual and functional (usage, execution_form, and attack_stage) and explicitly stated attributes (filepath).
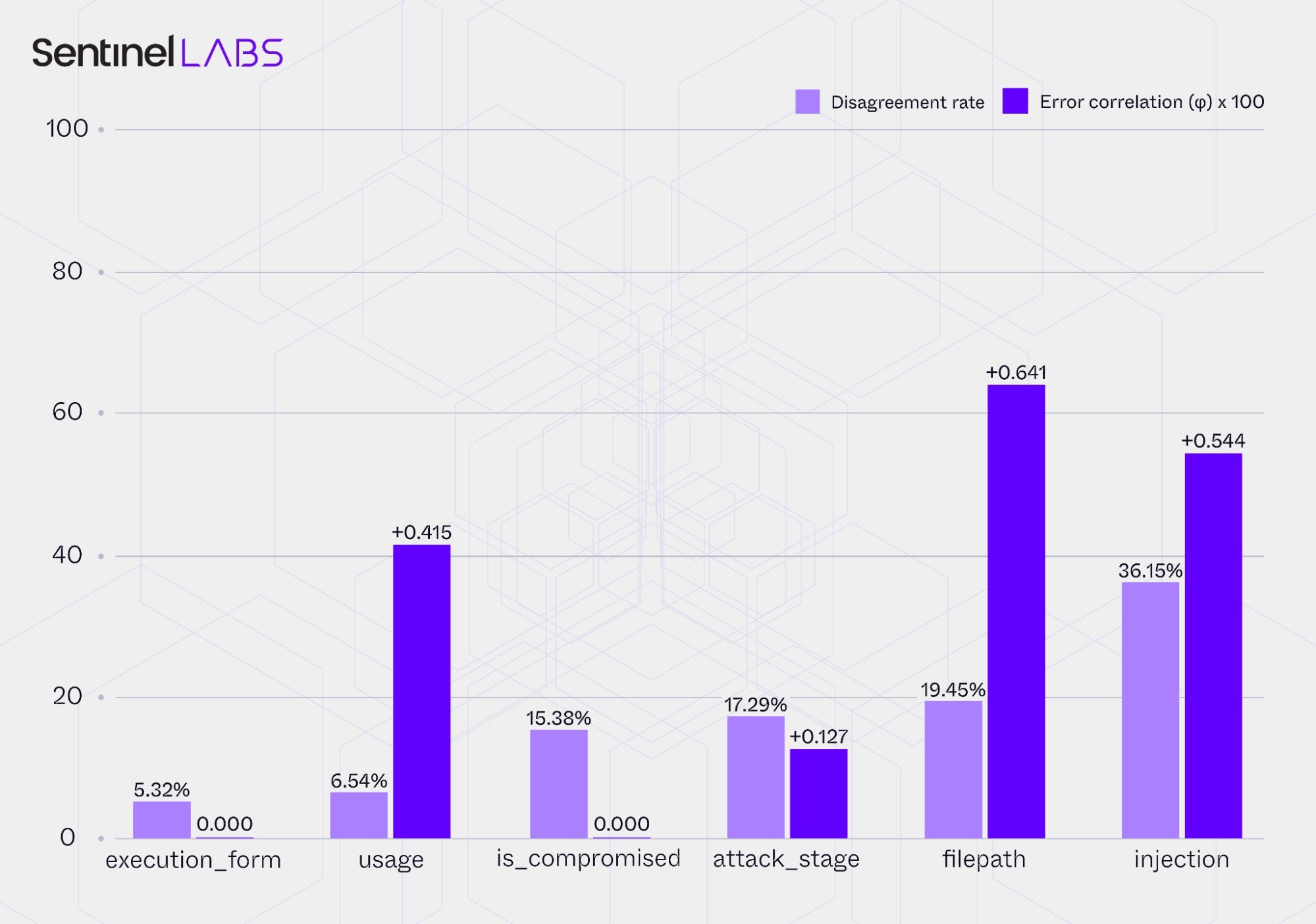
The results show variable ensemble potential across attributes, with predictions for some attributes, such as attack_stage, showing more complementary behavior between models, while others, such as usage, display strong coupling in their errors. This heterogeneity suggests that ensemble benefit is influenced by the interaction between the reasoning demands of each attribute and the way individual models respond to those demands in their predictions.
LLM ensemble configurations for CTI information extraction should therefore be evaluated on a task‑specific basis, such as per IOC contextual attribute in this study, rather than applied uniformly across all extraction tasks. Selective, empirically guided use of ensembling provides a more targeted path to maximizing its contribution to overall system performance.
Evaluation | Playbook and Knowledge Graph Assembly
In this section, we evaluate each LLM within the Playbook Extractor, focusing on its ability to construct connected, semantically coherent representations of adversary behavior described in CTI reports. Specifically, we examine how effectively each LLM instantiates ThreatActor, Playbook, and Step data model entities, and links them through sequencing, MITRE ATT&CK mappings, and IOC associations with threat actor actions to form a unified knowledge graph. In practical terms, this evaluation measures each model’s capacity to reconstruct the full sequence of threat actor actions within an adversary operation, ensuring that the resulting representations are internally consistent, chronologically coherent, and semantically valid.
The analysis is based on 17 individual metrics, each expressed as a ratio between 0 and 1 representing the proportion of structural or semantic elements (such as data model entities, links and their typed relationships, MITRE ATT&CK mappings, and IOC associations) that satisfy defined validation rules or external references, out of all instances evaluated for the respective metric. Here, rules refer to internal consistency conditions that shape a valid Playbook or graph structure (for example, acyclic sequences, reachability of Step entities, absence of orphaned Step entities), whereas references denote external knowledge sources used to check semantic accuracy (for example, a list of valid MITRE ATT&CK tactics and techniques and their parent-child relationships).
We consolidate these individual ratios into four aggregate categories, where each category’s value is the mean of its constituent ratios, capturing a distinct dimension of reconstruction quality:
- Structural Integrity: Assesses how coherent and complete each reconstructed
Playbookand the resulting knowledge graph is, for example how manyPlaybookinstances are loop‑free, fully connected, and internally consistent, as well as the extent to which atomic IOCs and their contextual attributes are linked toStepentities. - ATT&CK Mapping Validity: Measures the correctness of MITRE ATT&CK mappings and hierarchies, including the rate of valid tactic, technique, and sub‑technique identifiers and the proportion of correctly formed parent‑child relationships.
- Complexity and Semantic Diversity: Reflects how detailed and varied the reconstructed threat actor actions are, considering both the diversity of the captured ATT&CK tactics and techniques and the level of procedural detail expressed through the number of
Stepentities within eachPlaybook. - IOC Integration Density: Evaluates how thoroughly threat actor actions are associated with specific atomic IOCs and their contextual attributes, expressed through the average number of atomic IOCs linked per
Stepentity.
For the Structural Integrity and ATT&CK Mapping Validity categories, higher values indicate greater structural and semantic correctness, reaching 1.0 for fully valid results. The Complexity and Semantic Diversity, and IOC Integration Density, categories are based on normalized ratios that asymptotically approach 1.0 and provide relative measurements of how detailed, varied, and tightly interconnected each model’s reconstructions are. Building on the category aggregates, we calculate an overall Correctness Score as the mean of the Structural Integrity and ATT&CK Mapping Validity category scores, providing a concise and aggregate measure of structural and semantic correctness.
The chart below summarizes the category scores and the corresponding Correctness Score for each evaluated LLM.
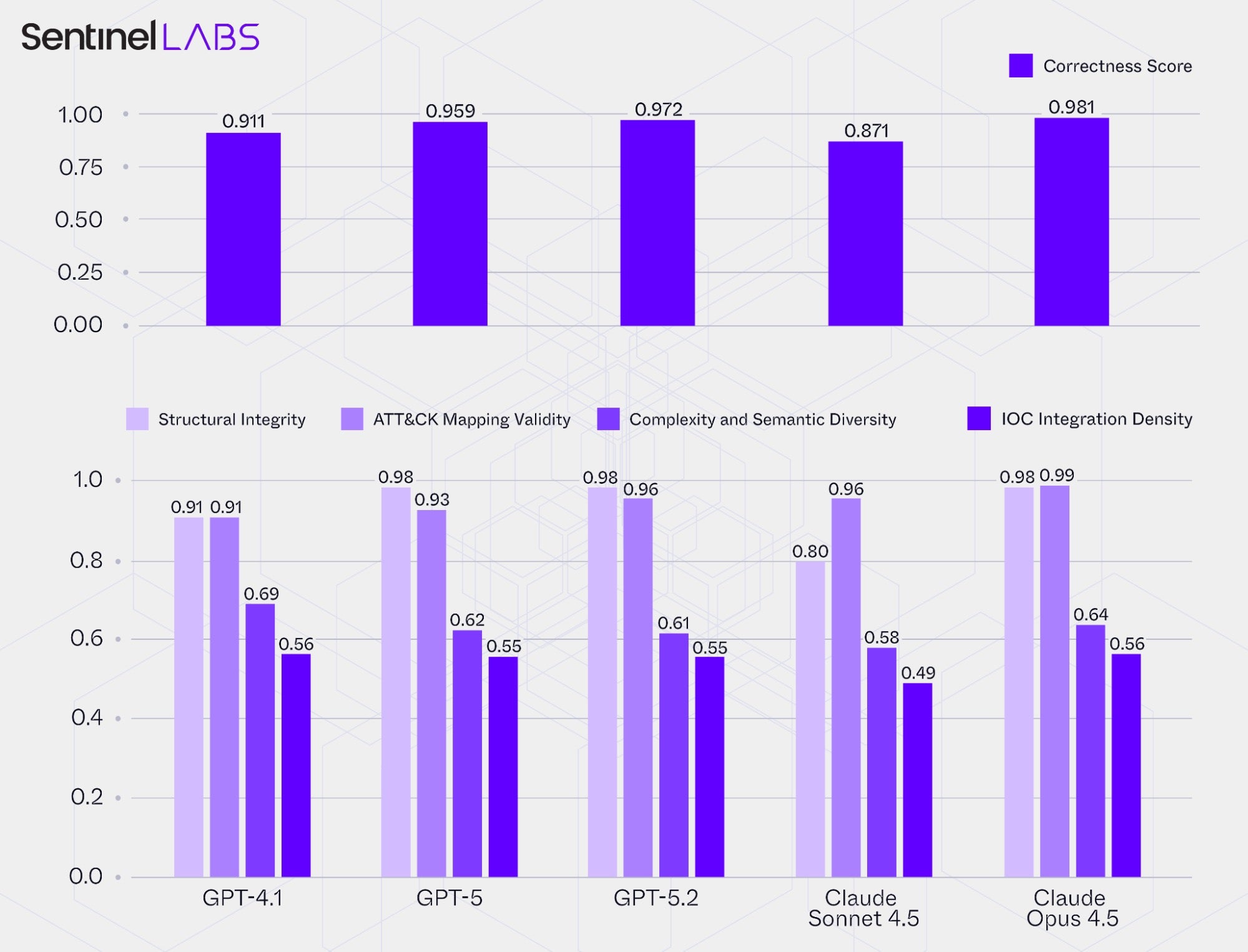
Despite relatively strong performance in transforming CTI report content into interlinked representations, the LLMs’ use of generative reasoning for extraction, combined with ambiguity and uneven detail in many reports, can introduce inconsistencies or omissions in the reconstructed structures, reducing overall coherence. These issues can affect how downstream applications traverse, correlate, and reason over the extracted information, and they should be explicitly accounted for in the design and integration of analytical workflows that consume these reconstructions. For example, implementations may prioritize the mission‑critical portions of the reconstructed structure, such as subgraphs whose relationships are key to the intended use case and must remain accurately captured to support consistent traversal and analysis, and apply additional assurance measures. Such measures include, for example, refined prompt design with strict generation guardrails or automated consistency checks.
Conclusions
LLMs can effectively automate information extraction from CTI reports, delivering substantial speed gains over manual processing. However, these reports vary widely in structure, terminology, and level of evidentiary detail, and the contextual cues needed to support LLM inference for a given extraction task may be implicit, inconsistent, or absent.
Beyond report variability, extraction outcomes also depend on the model’s reasoning capacity to connect contextual cues and on the applied inference policy applied. Together, these factors can lead to inaccuracies and coverage gaps.
In practice, achieving reliable results requires deliberate planning, evaluation, and continuous refinement. Operationalizing LLM-based CTI information extraction means setting clear objectives, defining standards for evidence and output quality, and investing in robust evaluation processes supported by representative ground truth data, all aligned with the intended application. Effective deployment depends as much on well-defined processes as on model choice. These processes involve balancing factors such as accuracy, coverage, and latency to meet operational requirements, as well as building safeguards and contingencies for mission-critical downstream applications.
Looking ahead, future model generations with stronger reasoning, better long‑range attention and salience, and more consistent adherence to extraction constraints than current models can raise baseline extraction correctness and coverage. For CTI and cyber defense, this means more accurate and complete structured intelligence, produced at scale from diverse narratives, which, in turn, supports more reliable correlation and prioritization, strengthens detection and response, and enables broader reuse across tools and teams. SentinelLABS and the SentinelOne AI team remain committed to sharing insights that support CTI teams and cyber defense organizations in integrating AI capabilities within their workflows.
如有侵权请联系:admin#unsafe.sh