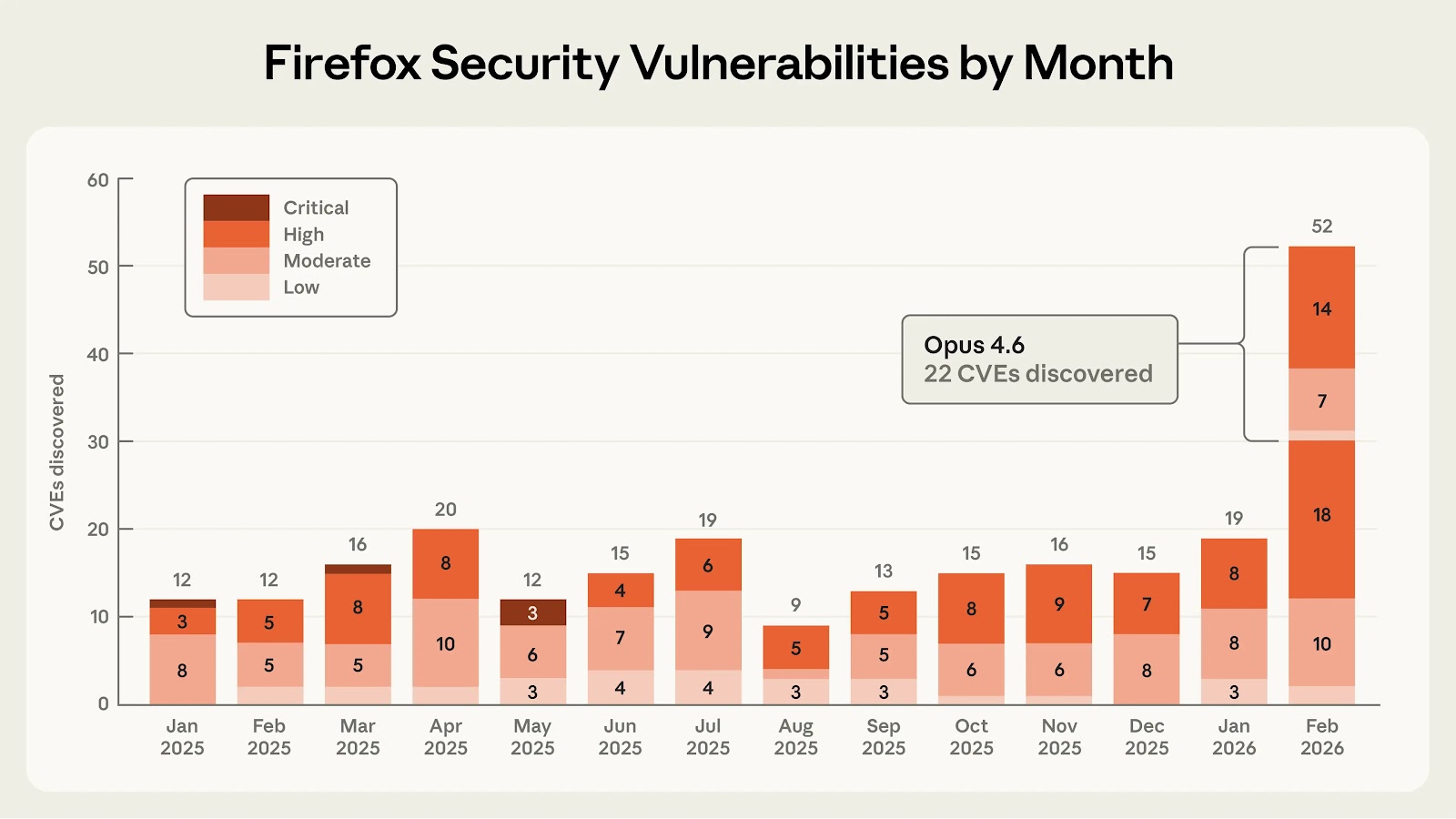

Anthropic on Friday said it discovered 22 new security vulnerabilities in the Firefox web browser as part of a security partnership with Mozilla.
Of these, 14 have been classified as high, seven have been classified as moderate, and one has been rated low in severity. The issues were addressed in Firefox 148, released late last month. The vulnerabilities were identified over a two-week period in January 2026.
The artificial intelligence (AI) company said the number of high-severity bugs identified by its Claude Opus 4.6 large language model (LLM) represents "almost a fifth" of all high-severity vulnerabilities that were patched in Firefox in 2025.
Anthropic said the LLM detected a use-after-free bug in the browser's JavaScript after "just" 20 minutes of exploration, which was then validated by a human researcher in a virtualized environment to rule out the possibility of a false positive.
"By the end of this effort, we had scanned nearly 6,000 C++ files and submitted a total of 112 unique reports, including the high- and moderate-severity vulnerabilities mentioned above," the company said. "Most issues have been fixed in Firefox 148, with the remainder to be fixed in upcoming releases."
The AI upstart said it also fed its Claude model access to the entire list of vulnerabilities submitted to Mozilla and tasked the AI tool with developing a practical exploit for them.
Despite carrying out the test several hundred times and spending about $4,000 in API credits, the company said Claude Opus 4.6 was able to turn the security defect into an exploit only in two cases.
This behavior, the company added, signaled two important aspects: the cost of identifying vulnerabilities is cheaper than creating an exploit for them, and the model is better at finding issues than at exploiting them.

"However, the fact that Claude could succeed at automatically developing a crude browser exploit, even if only in a few cases, is concerning," Anthropic emphasized, adding the exploits only worked within the confines of its testing environment, which has had some security features like sandboxing intentionally stripped off.
A crucial component incorporated into the process is a task verifier to determine if the exploit actually works, giving the tool real-time feedback as it explores the codebase in question and allowing it to iterate its results until a successful exploit is devised.
One such exploit Claude wrote was for CVE-2026-2796 (CVSS score: 9.8), which has been described as a just-in-time (JIT) miscompilation in the JavaScript WebAssembly component.
The disclosure comes weeks after the company released Claude Code Security in a limited research preview as a way to fix vulnerabilities using an AI agent.
"We can't guarantee that all agent-generated patches that pass these tests are good enough to merge immediately," Anthropic said. "But task verifiers give us increased confidence that the produced patch will fix the specific vulnerability while preserving program functionality—and therefore achieve what's considered to be the minimum requirement for a plausible patch."
Mozilla, in a coordinated announcement, said the AI-assisted approach has discovered 90 other bugs, most of which have been fixed. These consisted of assertion failures that overlapped with issues traditionally found through fuzzing and distinct classes of logic errors that the fuzzers failed to catch.
"The scale of findings reflects the power of combining rigorous engineering with new analysis tools for continuous improvement," the browser maker said. "We view this as clear evidence that large-scale, AI-assisted analysis is a powerful new addition to security engineers' toolbox."
Found this article interesting? Follow us on Google News, Twitter and LinkedIn to read more exclusive content we post.