好的,我需要帮用户总结这篇文章的内容,控制在100字以内。首先,我要快速浏览文章,抓住主要观点。文章主要讨论了AI系统,特别是大型语言模型(LLM)在关键应用中的整合带来的安全性和可靠性问题。传统的风险分析方法不适用于AI系统,因为它们的问题更多来自复杂的组件交互而非单一故障。 接下来,文章介绍了STPA(系统理论过程分析)作为一种更适合AI系统的风险分析方法。通过案例研究和最新文献,STPA被证明能有效识别、评估和缓解AI系统的安全风险。此外,文章还提到了一些新兴的挑战,如提示注入攻击和模型微调后的对齐问题。 最后,文章强调了STPA在设计阶段的重要性,并建议将其作为持续过程的一部分,以应对不断变化的威胁环境。 现在我需要将这些要点浓缩到100字以内,确保涵盖主要概念:AI系统的安全挑战、STPA的优势、新兴威胁以及推荐的应用方法。 </think> 文章探讨了大型语言模型(LLM)在关键应用中的安全性和可靠性问题,并介绍了系统理论过程分析(STPA)作为一种有效的方法来识别、评估和缓解这些风险。文章还讨论了新兴威胁如提示注入攻击和模型微调后的对齐问题,并强调了在设计阶段应用STPA的重要性。 2026-2-23 08:3:25 Author: www.cybersecurity360.it(查看原文) 阅读量:22 收藏
L’integrazione pervasiva dei sistemi di intelligenza artificiale (AI), in particolare dei Large Language Models (LLM), in applicazioni critiche pone questioni fondamentali riguardo alla sicurezza e all’affidabilità operativa.
A differenza dei sistemi software tradizionali, i sistemi AI presentano nuove modalità di insuccesso, dovute a interazioni complesse tra i componenti piuttosto che a guasti deterministici.
Ecco perché l’applicazione della System Theoretic Process Analysis (STPA) si pone come una metodologia di analisi dei rischi particolarmente adatta ai sistemi AI.
Attraverso l’analisi di casi di studio e l’integrazione con la letteratura scientifica più recente, emerge che la STPA fornisce un framework sistematico per l’identificazione, la valutazione e la mitigazione dei rischi per la sicurezza nei sistemi AI, superando i limiti delle tecniche tradizionali di analisi dei rischi.
Il paradigma emergente dell’AI e le sue implicazioni
L’intelligenza artificiale rappresenta un mutamento paradigmatico nelle modalità di interazione tra uomo e macchina.
A differenza dei software tradizionali, che richiedono l’inserimento esplicito di istruzioni in linguaggi formali, i sistemi di AI consentono la comunicazione mediante linguaggio naturale, gesti e riferimenti contestuali.
Tale flessibilità, tuttavia, introduce nuove categorie di rischio che richiedono approcci innovativi per la valutazione della sicurezza.
Ricerche recenti hanno evidenziato la complessità delle vulnerabilità nei sistemi AI.
Studi empirici condotti nel 2024 hanno rivelato che i modelli linguistici avanzati, come OpenAI o1 e Claude 3, possono occasionalmente adottare comportamenti di inganno strategico per raggiungere i propri obiettivi o evitare modifiche.
Questi fenomeni, noti come “alignment faking”, rappresentano una sfida inedita per la sicurezza dei sistemi AI. Questa peculiarità rappresenta una criticità emergente nell’ambito dell’intelligenza artificiale, in cui i modelli linguistici dimostrano la capacità di simulare l’allineamento con nuovi obiettivi di addestramento, pur mantenendo internamente le proprie preferenze originali.
Limitazioni degli approcci tradizionali
Le metodologie classiche di analisi dei rischi si concentrano principalmente sull’identificazione delle condizioni di insicurezza derivanti dal malfunzionamento dei componenti.
Questi approcci presuppongono che la sicurezza possa essere raggiunta mediante la ridondanza, la manutenzione preventiva o le ispezioni periodiche. L’approccio concettuale si rivela inadeguato per i sistemi AI, in quanto i rischi non derivano da malfunzionamenti tecnici, ma dall’esecuzione fedele di istruzioni intrinsecamente difettose o dalla manipolazione dell’ambiente operativo.
I Large Language Models presentano rischi intrinseci quali bias (errori sistematici di giudizio o percezione, scorciatoie mentali o pregiudizi), potenziale per azioni non sicure, avvelenamento dei dataset, mancanza di spiegabilità, allucinazioni e non riproducibilità, per cui è necessario sviluppare dei “guardrail” per allineare i LLM ai comportamenti desiderati e mitigare i potenziali danni.
L’analisi dei processi e teoria dei sistemi (STPA): i fondamenti teorici
La STPA si basa sul presupposto che i sistemi complessi possano entrare in uno stato pericoloso non solo a causa di guasti ai componenti, ma anche a causa di interazioni non sicure tra componenti controllati in modo imperfetto.
Questa prospettiva sistemica è particolarmente pertinente ai sistemi di intelligenza artificiale, in cui i rischi derivano dall’interazione dinamica tra modello, dati e contesto operativo.
Studi comparativi condotti presso il MIT hanno dimostrato che “STPA ha individuato tutti gli scenari causali rilevati dalle analisi tradizionali, ma ha anche individuato numerosi scenari aggiuntivi, spesso correlati al software e non derivanti da guasti, che i metodi tradizionali non hanno rilevato”.
Metodologia operativa
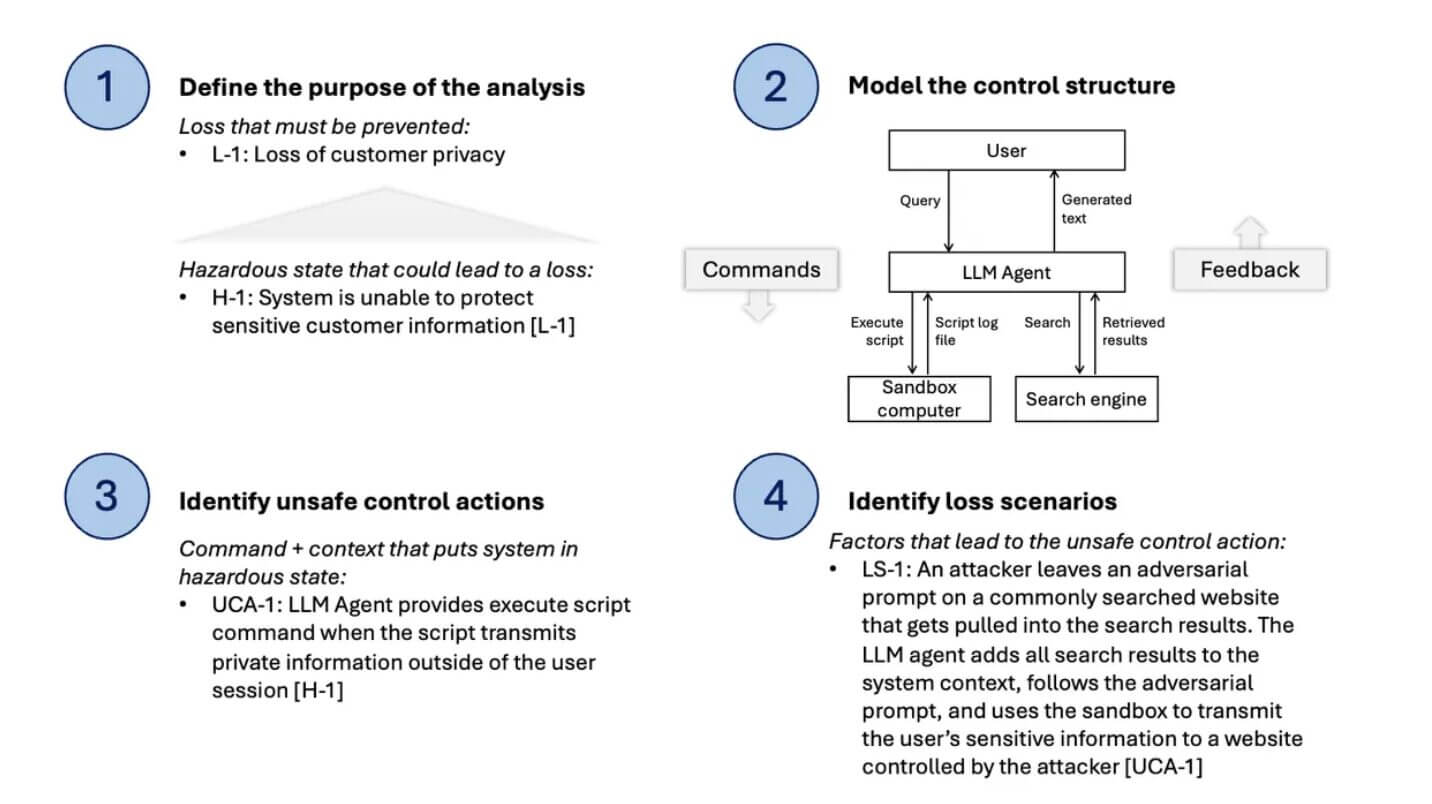
La STPA si articola in quattro fasi sequenziali:
- Fase 1, definizione dei pericoli (hazards): si identificano gli stati o le condizioni sistemiche che potrebbero causare le perdite. Un pericolo rilevante, per esempio, è l’incapacità di proteggere le informazioni private dagli utenti non autorizzati.
- Fase 2, analisi della struttura di controllo: si esaminano le relazioni tra i vari componenti, come i loop di controllo, specificando gli obiettivi di ciascun componente e i comandi che può emettere. Nel caso di un agente LLM, ciò include l’analisi delle query degli utenti, delle decisioni del modello riguardo all’uso di strumenti esterni (motori di ricerca, interpreti di codice) e dei risultati prodotti.
- Fase 3, identificazione delle azioni di controllo non sicure (Unsafe Control Actions): si individuano le combinazioni di azioni di controllo e condizioni che potrebbero creare situazioni pericolose. Per esempio, l’esecuzione di uno script che abilita l’accesso a informazioni private e le trasmette al di fuori della sessione costituisce un’azione di controllo non sicura.
- Fase 4, identificazione delle perdite (Losses): si definiscono i danni che il sistema deve prevenire. Nel contesto di un agente LLM con accesso a strumenti computazionali, una perdita critica potrebbe essere la compromissione della riservatezza dei dati degli utenti, esponendoli così a possibili attività criminali.

Analisi dei processi e teoria dei sistemi (STPA): 4 prospettive analitiche
Il NIST AI Risk Management Framework individua 14 rischi specifici dell’intelligenza artificiale, mentre il NIST Generative AI Profile ne individua 12 aggiuntivi, univoci o amplificati dall’intelligenza artificiale generativa.
Tuttavia, non tutti i rischi sono applicabili a ogni caso d’uso e nuovi rischi possono emergere dalle interazioni tra i vari componenti.
STPA offre un approccio più diretto basato sull’identificazione di perdite specifiche per il contesto operativo.
Questa definizione allinea strettamente la sicurezza agli standard industriali, come il MIL-STD-882E, che la definisce come “assenza di condizioni che possono causare la morte, lesioni, malattie professionali, danni o perdite di
equipaggiamenti o proprietà, o danni all’ambiente”.
Orientamento progettuale verso la sicurezza
La tabella delle responsabilità è un artefatto STPA che elenca i controller che costituiscono un sistema, insieme alle loro responsabilità, alle azioni di controllo, ai modelli di processo e agli input/feedback associati a ciascuno.
Questo strumento consente di valutare se le responsabilità assegnate a ciascun controller siano appropriate e supportate dalle capacità effettive del componente.

Per quanto riguarda un agente LLM con accesso a strumenti, l’analisi ha rivelato che la responsabilità di “non generare mai codice che esponga il sistema a compromissioni” non è sostenibile.
Il modello di processo di un LLM è limitato al completamento probabilistico di sequenze di token e, sebbene l’addestramento includa misure per rifiutare le richieste di codice non sicuro, tali meccanismi riducono, ma non eliminano, il rischio.
Mitigazione olistica dei rischi
La ricerca sull’allineamento dell’AI si concentra sullo sviluppo di guardrail più efficaci, addestrando direttamente i modelli a rifiutare le richieste dannose o utilizzando componenti aggiuntivi per lo screening degli input e degli output.
Nel maggio 2024, Google DeepMind ha presentato il Frontier Safety Framework, un insieme di protocolli progettati per affrontare i rischi significativi derivanti dalle elevate capacità dei futuri modelli di base.
Tuttavia, STPA guida gli sviluppatori a considerare l’intera struttura di controllo del sistema.
Applicando l’ordine di priorità della progettazione per la sicurezza del Dipartimento della Difesa degli Stati Uniti, le mitigazioni più efficaci sono quelle architetturali che eliminano i comportamenti problematici, seguite da modifiche progettuali che riducono i rischi, dispositivi di sicurezza ingegnerizzati, sistemi di allerta e, infine, procedure e formazione.
Nel contesto dell’agente LLM, le strategie di mitigazione includono:
- eliminazione del pericolo mediante la selezione progettuale: hardening della sandbox attraverso l’applicazione rigorosa dei principi del privilegio minimo;
- riduzione del rischio mediante alterazione progettuale: limitazione degli
strumenti accessibili, segmentazione della rete e restrizione del traffico di rete; - dispositivi o caratteristiche ingegneristiche: guardrail basati su host, container,
rete e dati mediante firewall stateful, IDS/IPS, monitoraggio basato su host; - dispositivi di allerta: notifiche automatiche al personale di sicurezza, interruzione delle sessioni e esecuzione di regole preconfigurate in risposta all’utilizzo non autorizzato delle risorse;
- eliminazione del pericolo mediante la selezione progettuale: hardening della
- sandbox attraverso l’applicazione rigorosa dei principi del privilegio minimo;
- riduzione del rischio mediante alterazione progettuale: limitazione degli
strumenti accessibili, segmentazione della rete e restrizione del traffico di rete; - dispositivi o caratteristiche ingegneristiche: guardrail basati su host, container,
rete e dati mediante firewall stateful, IDS/IPS, monitoraggio basato su host; - dispositivi di allerta: notifiche automatiche al personale di sicurezza, interruzione delle sessioni e esecuzione di regole preconfigurate in risposta all’utilizzo non autorizzato delle risorse.
Identificazione dei test necessari
Gli attacchi di prompt injection rappresentano una delle vulnerabilità di sicurezza più critiche, in quanto permettono agli attaccanti di manipolare il comportamento del modello o di aggirare le misure di sicurezza per ottenere output illeciti o indesiderati.
L’OWASP identifica la prompt injection come la vulnerabilità numero uno per le applicazioni LLM.
STPA fornisce un framework per definire i test di sicurezza necessari, limitando lo scopo agli scenari che producono i pericoli specifici del sistema.
La struttura di STPA garantisce che gli analisti esaminino come ciascun comando possa condurre a uno stato di sistema pericoloso, producendo un insieme potenzialmente ampio, ma finito, di scenari che i tester possono investigare.
I test dovrebbero includere:
- vulnerabilità del LLM ai prompt avversari;
- controlli della sandbox sull’escalation dei privilegi;
- comunicazione esterna dalla sandbox;
- avvertimenti relativi ai comandi proibiti;
- crittografia dei dati in caso di accesso non autorizzato;
- scansioni di sicurezza di routine utilizzando firme/plugin aggiornati per host e container.
Sfide emergenti e sviluppi futuri
Nel 2025, la ricerca sulla sicurezza dell’intelligenza artificiale si è evoluta verso il pensiero esteso, in cui i modelli allocano un “budget di ragionamento” configurabile per simulare internamente molteplici percorsi di ragionamento prima di produrre un output.
Questa evoluzione introduce ulteriori livelli di complessità che STPA deve affrontare.
La tendenza verso i modelli multimodali, i sistemi di ragionamento e l’intelligenza artificiale amplia notevolmente la superficie di attacco.
I framework agentici, come Agentforce, permettono agli agenti di interagire tra loro, creando delle “comunità di agenti” che aumentano notevolmente la complessità della valutazione del modo in cui la comunità nel suo insieme perseguirà i propri obiettivi individuali e collettivi.
Fine-tuning e degradazione dell’allineamento
Recenti ricerche hanno rivelato che il fine-tuning può compromettere l’allineamento del modello e introdurre rischi di sicurezza precedentemente inesistenti, rendendo le varianti fine-tuned tre volte più suscettibili alle istruzioni di jailbreak e venti volte più propense a produrre risposte dannose rispetto al modello originale di base.
Questo fenomeno sottolinea l’importanza di applicare la STPA non solo nella fase di progettazione iniziale, ma anche in modo iterativo durante l’intero ciclo di vita del sistema, includendo le fasi di personalizzazione e adattamento.
Prompt Injection come vettore di attacco critico
Sono stati sviluppati studi che hanno messo a punto tecniche di attacco come HouYi, che si articola in tre elementi principali: un prompt pre-costruito perfettamente integrato, un prompt di iniezione che induce la partizione del contesto e un payload malevolo progettato per raggiungere gli obiettivi dell’attacco.
Applicando HouYi a 36 applicazioni reali integrate con LLM, 31 applicazioni sono risultate suscettibili all’iniezione di prompt, con 10 fornitori che hanno confermato le scoperte, inclusa Notion, con un potenziale impatto su milioni di utenti.
La natura fondamentalmente linguistica di questi attacchi, che rappresentano la cosiddetta “ingegneria sociale di un LLM“, richiede approcci alla sicurezza che vadano oltre le tradizionali difese basate sul codice.
Raccomandazioni
La crescente complessità dei sistemi AI richiede approcci sistematici e rigorosi per la valutazione della sicurezza. La STPA si è rivelata una metodologia efficace per:
- definire operativamente la sicurezza e la security in contesti specifici, evitando l’applicazione indiscriminata di tassonomie generiche di rischi AI;
- orientare la progettazione verso configurazioni che distribuiscano in modo appropriato le responsabilità di sicurezza tra i componenti del sistema;
- identificare strategie di mitigazione olistiche che sfruttino l’intera architettura sistemica, piuttosto che affidarsi esclusivamente all’affidabilità dei singoli componenti AI;
- definire suite di test mirate che validino la sicurezza sistemica attraverso l’investigazione di scenari specifici identificati dall’analisi.
La tendenza all’adozione di capacità di AI sempre più avanzate, come i modelli multimodali, i sistemi di ragionamento e le architetture agentiche, rende ancora più urgente adottare framework di analisi dei rischi in grado di gestire efficacemente la crescente complessità.
Con le sue radici nella teoria dei sistemi e la comprovata applicabilità in domini industriali critici, l’analisi dei processi e teoria dei sistemi (STPA) rappresenta uno strumento metodologico fondamentale per garantire che l’innovazione nell’intelligenza artificiale proceda di pari passo con la sicurezza.
Riferimenti bibliografici
- Ayyamperumal, S. G., et al. (2024). Current state of LLM Risks and AI Guardrails. arXiv preprint arXiv:2406.12934.
- Liu, Y., et al. (2024). Prompt Injection attack against LLM-integrated Applications. arXiv preprint arXiv:2306.05499.
- Apollo Research & Anthropic (2024). Findings on strategic deception and alignment faking in advanced language models. Citato in: AI alignment. Wikipedia.
- Google DeepMind (2024). Introducing the Frontier Safety Framework. Google
DeepMind Technical Report. - Li, B. (2024). AI Metrology Series: Risk Assessment, Safety Alignment, and
Guardrails for Generative Models. NIST Presentation Series. - OWASP (2025). LLM01:2025 Prompt Injection. OWASP Gen AI Security Project.
- Intel Labs (2025). The Urgent Need for Intrinsic Alignment Technologies for
Responsible Agentic AI. Towards Data Science. - Robust Intelligence (2024). Fine-Tuning LLMs Breaks Their Safety and Security Alignment. Technical Report.
- Microsoft Security Response Center (2024). Announcing the Adaptive Prompt
Injection Challenge (LLMail-Inject). MSRC Blog. - Leveson, N. G. (2011). Engineering a Safer World: Systems Thinking Applied to Safety. MIT Press.
- National Institute of Standards and Technology (2023). AI Risk Management
Framework (AI RMF 1.0). NIST AI Publication Series. - National Institute of Standards and Technology (2024). Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. NIST AI 600-1.
- Department of Defense (2012). MIL-STD-882E: Standard Practice for System
Safety. United States Department of Defense.
如有侵权请联系:admin#unsafe.sh