好的,我现在需要帮用户总结这篇文章的内容,控制在100字以内。首先,我得仔细阅读文章,抓住主要信息。 文章主要介绍了一个开源项目Auto-Subs,它能够将Whisper模型集成到DaVinci Resolve中,实现本地字幕生成。这样用户就不需要依赖云端服务,避免了订阅费和隐私问题。同时,Auto-Subs作为插件直接嵌入剪辑软件,流程更顺畅。 接下来,我需要提炼关键点:开源、本地运行、集成到DaVinci、解决订阅费和隐私问题、支持多语言、速度快。这些点要简洁明了地表达出来。 然后,我要确保语言流畅,不超过100字。可能的结构是先介绍项目名称和功能,再说明优势和适用情况。 最后检查一下是否符合要求:没有使用“文章内容总结”之类的开头,直接描述内容。确保所有关键信息都涵盖在内。 </think> Auto-Subs 是一个开源工具,将 Whisper 模型集成到 DaVinci Resolve 中,支持本地运行字幕生成。无需云端 API 计费,数据隐私无忧。作为插件直接嵌入剪辑软件,流程顺畅且支持多语言。适合有硬件资源的创作者节省订阅费并提升工作效率。 2026-2-3 10:57:49 Author: blog.upx8.com(查看原文) 阅读量:2 收藏

如果你平时主要在推特发视频,或者是习惯用达芬奇(DaVinci Resolve)剪辑的 Indie Hacker,在做字幕这件事上,估计都有过这种“想骂人”的时刻:
- 用剪映? 识别是很准,但要把字幕无损同步回达芬奇,那流程繁琐得能劝退一半人。
- 用 Otter 或 Descript? 体验确实好,但每个月动辄 $20 美元的订阅费,加上时长限制,对于我们这种高频创作者来说,这笔“SaaS 税”交得有点肉疼。
最近在 GitHub 挖到了一个很符合“极客精神”的开源项目:Auto-Subs。
它不是什么花里胡哨的新概念,就是简单粗暴地解决了一个问题:把那个大家都知道很准的 Whisper 模型,塞进你的达芬奇里,用你自己的显卡跑字幕。
简单说:不用云端 API 计费、不限时长、也不用担心隐私泄露。
我为什么要推荐这个?(真实体验)
试用了两周,我觉得它能替代市面上大部分收费工具。不是因为它“免费”,而是因为它的工作流(Workflow)真的很顺手:
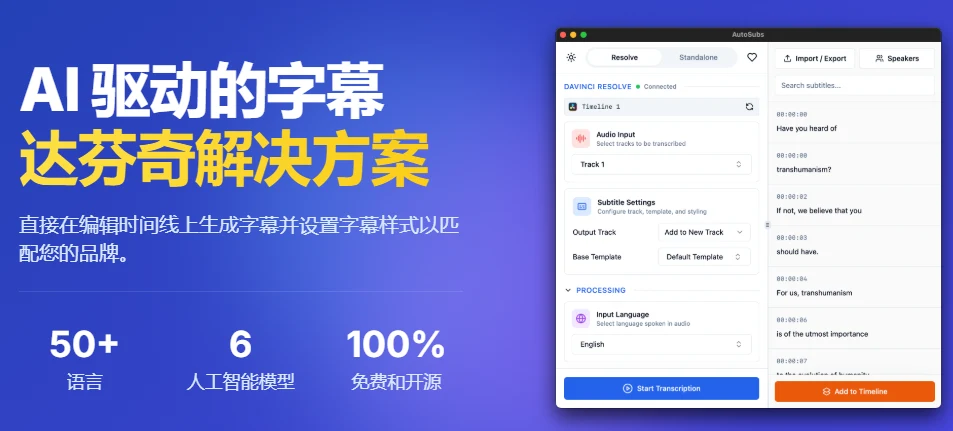
1. 它是真的“长”在达芬奇里的
这是我最看重的一点。市面上很多开源工具只能给你吐一个 SRT 文件,你还得手动拖进时间轴、费劲对齐,很断节奏。
Auto-Subs 是直接作为脚本插件嵌入到 DaVinci Resolve 内部的。你在剪辑软件里点一下“生成”,字幕就会自动出现在时间轴上,时间码卡得非常准。对于剪辑流来说,这才是真正的省时间。

2. 只有本地跑,我才敢放心地用
有些访谈素材或者内部演示,其实并不适合上传到第三方云端服务器(毕竟谁也不知道这些数据会被怎么用)。
我自己就是那种:能本地跑的东西,尽量不传云端的人。
这个工具是完全离线 (On-Device) 运行的。从语音识别到字幕生成,所有数据都不出你的本地显卡。对于比较介意数据隐私的朋友,这是目前最稳妥的方案。
3. 闲置算力的再利用
既然我们为了剪视频都买了不错的显卡,为什么还要去买云端的算力?只要你的显卡跑得动,想转多少小时都可以,这才是“一次性投入”的正确用法。
实测:本地跑 Whisper 到底慢不慢?
它的核心是 Whisper 模型,准确率大家心里都有数,基本是目前开源界的第一梯队。
- 速度实测: 我用一张 RTX 3060 的普通显卡,处理一段 10 分钟的 1080P 视频,生成字幕大概只要 40-60 秒。
- 多语言: 支持中英日韩等 90 多种语言,甚至支持直接把外语视频转译成英文字幕。
怎么上手 (防踩坑版)
部署逻辑其实很简单,不用怕全是代码:
第一步:下载
直接去 GitHub 的 Releases 页面下对应的安装包(Windows / macOS / Linux)。开发者对 Mac 的 Apple Silicon (M1/M2) 芯片也做了优化,甚至比 PC 还快。
第二步:选模式
- 独立模式 (Standalone): 如果你不用达芬奇,直接拖视频进去,它能吐出 SRT/VTT 文件。
- 达芬奇模式 (Resolve Mode): (强烈推荐) 安装后,在 DaVinci Resolve 的
Workspace -> Scripts菜单下就能找到它。选中时间轴上的音频,一键生成。
💡 硬件小建议:
因为是本地跑 AI 模型,建议你的电脑至少有一张 NVIDIA 显卡 (建议 4GB+ 显存)。首次运行建议选 “Small” 或 “Medium” 模型,这就够用了。”Large” 模型虽然最准,但对显存要求高,速度也会慢很多。
写在最后
在 AI 时代,我们看过太多包装精美但核心只是套壳 API 的收费工具。Auto-Subs 是那种典型的“Indie Hacker 风格”产物——不玩虚的,直接解决问题。
如果你手头有硬件,完全没必要为基础的字幕识别持续付费。把这个工具加入你的工作流,既能省下订阅费,又能把数据的控制权拿回自己手里,哪怕你一个月只剪几条视频,用它都比交订阅费划算。
项目与官方资源
如果你对这个项目感兴趣,或者在使用过程中遇到问题,建议直接访问官方渠道获取最新版本和详细文档:
- GitHub 项目地址 (下载与源码):https://github.com/tmoroney/auto-subs
- 官方网站与文档 (使用指南):https://tom-moroney.com/auto-subs/
如有侵权请联系:admin#unsafe.sh