好的,我现在需要帮用户总结一篇关于处理暴露密钥的SRE响应指南的文章,控制在100字以内。首先,我得通读整篇文章,抓住主要点。 文章开头描述了一个典型的未管理的事故场景,工程师们在压力下犯错,导致系统崩溃。接着介绍了响应计划的重要性,分为准备、检测、影响评估、实时响应、事后分析和预防措施几个部分。 准备部分包括明确目标、角色分配、沟通和文档标准。检测部分涉及API使用异常、云监控和日志分析。影响评估需要确定泄露范围和优先级。实时响应包括隔离系统、撤销和生成新密钥,并利用自动化工具。事后分析则强调从事故中学习,实施预防措施,并持续更新响应计划。 总结下来,文章强调了标准化流程在事故管理中的作用,特别是针对密钥泄露的特殊处理方法。因此,在总结时需要涵盖准备、检测、响应和预防这几个关键步骤。 现在,我需要用简洁的语言把这些要点浓缩到100字以内。确保涵盖准备阶段的目标设定,检测阶段的指标和日志分析,响应阶段的隔离和自动化,以及预防措施如密钥管理系统的使用。 最终的总结应该清晰明了,突出每个阶段的重点,并说明该指南如何帮助团队有效应对密钥泄露事故。 </think> 文章介绍了一套针对暴露密钥的安全事件响应指南(SRE Playbook),涵盖了从准备到实时响应再到事后分析的关键步骤。内容包括明确目标与角色、设置检测指标与日志分析、评估影响范围、隔离系统与自动化处理、实施预防措施如使用密钥管理系统等。该指南强调通过标准化流程与多层防护机制来应对暴露密钥的风险,确保系统安全与可靠性。 2026-1-27 17:13:36 Author: securityboulevard.com(查看原文) 阅读量:3 收藏

Imagine this: It's a regular Thursday morning when disaster strikes. The on-call engineer receives a flood of alerts – unusually high API failures of an internal service. Reverting to a previous version changes nothing. Now, colleagues are panicking in crisis mode. Just when things couldn't get worse, it does: another deployment triggered by a code merge takes everything down. The entire platform is now completely offline.
Above is a typical "unmanaged" incident, where a series of blunders and a lack of coordination lead to a meltdown. Humans tend to make mistakes, especially under pressure; that's why we want to use standardized, structured processes to manage incidents efficiently, minimizing disruptions and restoring operations quickly. And that is precisely what an incident response playbook is for.
1. Preparation
Although you might think so, an incident response playbook doesn't really start with "if alert X happens, do Y".
Before handling incidents, there are other important things to figure out:
- Goals and objectives: What is the objective of the playbook? What is the scope? What types of incidents does it try to cover?
- Roles and teams: What are the roles involved, and what are their responsibilities? Do you need an incident commander or an ops lead? Which team/team members are required? Do they have the necessary skills? If not, are there trainings? Are they available? Is assembling a dedicated incident response team needed?
- Communication, documentation, and coordination: What channels to use for internal and external communication? How to notify stakeholders? How to transfer command clearly, especially across time zones? What format/template to use for reports, updates, and logs? How to live-update the state of an incident (e.g., a shared Google Doc) so that everyone can work synchronously? What info needs to be documented during an incident?
The above isn't an exhaustive list. There is other stuff to think about beforehand, like how to categorize incidents, how incident levels are defined, whether existing company/team policies and requirements need to be integrated with, etc.
Even if the whole document is finished, it doesn't mean the end of the preparation – remember to test the playbook! Train related team members on the playbook, do simulations to test its effectiveness, and adjust procedures based on feedback.
One can never be too prepared!
2. Secret Leak Incident
As briefly mentioned, there are different types of incidents, and one incident response playbook couldn't possibly cover all. It's a good practice to tailor our playbooks to different types of incidents.
Here, I want to single out one specific type of incident – secret leaks, because it is different in many ways.
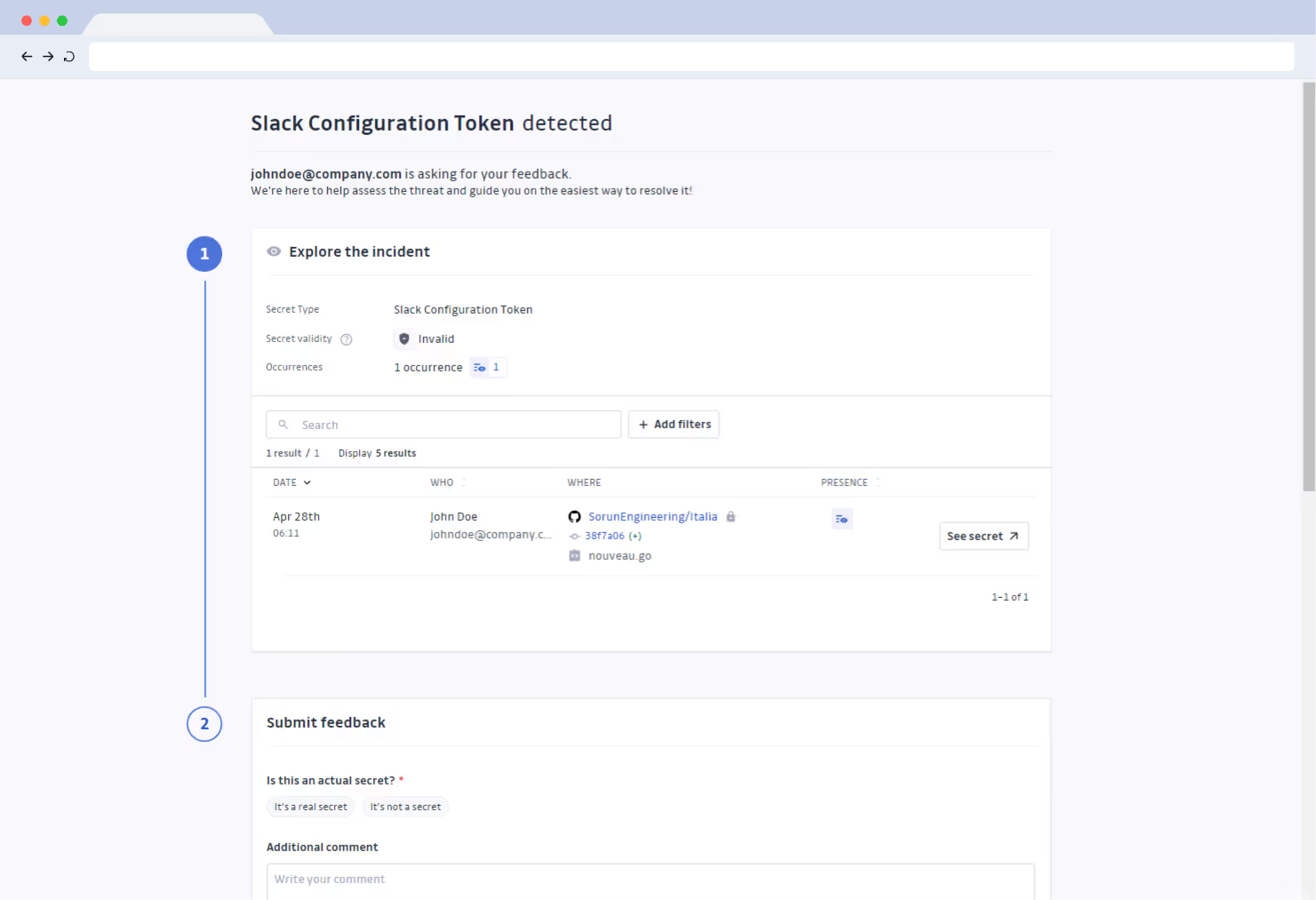
2.1 Alerting and Detection
From the alerting and detection standpoint, it's more challenging to spot secret leaks.
The "service/server/network down" type of incidents typically show up clearly, and immediately, on our dashboard because we get alerts on unreachable resources, high latencies, and elevated error rates. However, traditional metrics and monitoring systems are less effective in detecting secret leaks: CPU usage, latency, and error rates might only increase slightly, and it isn't always immediately obvious since it takes time for malicious actors to find it out and exploit.
We can create specific metrics and alerts for secret leaks. For example:
- API usage: Is there unexpected traffic like sudden, unexplained increases? Are there requests from unfamiliar IP addresses or locations? Does error rate increase, but not to 100% (since a surge in errors like 401 Unauthorized/403 Forbidden might indicate that someone is trying to use the leaked secret improperly or is attempting to brute-force access, instead of a service going down completely)? Is there a high volume of requests from a single IP?
- Cloud monitoring: Is there unusual resource consumption (a leaked key could be used to spin up cloud resources)? Are there unauthorized IAM activities? Infrastructure as Code for IAM could be our friend to track changes to IAM roles and permissions. Is there network traffic to unfamiliar destinations or unusual data transfer patterns?
- Database Monitoring: Are there unusual queries, such as attempts to access sensitive data or perform unauthorized modifications? Is there a high number of failed login attempts for database accounts, which could indicate that someone is trying to gain access using compromised credentials?
Besides monitoring, we can aggregate logs from all systems, so that machine-learning-based (or simply rule-based) anomaly detection can be used to detect patterns that deviate from the norm.
Last but not least, perform regular scans on code repos, logs, and configuration files for exposed secrets, and they can be integrated into our CI/CD pipelines to prevent secrets from being committed.
2.2 Impact, Scope, and Investigation
Typical "server down" types of incidents have a more localized and immediate impact, and while the results can be severe, the scope is usually contained. And, the investigation process focuses on identifying the root cause, such as:
- analyzing logs to identify errors;
- examining performance metrics to identify bottlenecks or resource constraints;
- reviewing recent configuration changes that may have caused the issue;
- using standard troubleshooting techniques to pinpoint the problem and find a solution.
On the other hand, the impact of secret leaks can be long-lasting, since a compromised secret can grant unauthorized access to sensitive data and services, and the scope can extend beyond the immediate system where the leak occurred, potentially affecting multiple apps and services, or even an entire environment. So, the investigation requires a more comprehensive approach, and understanding the blast radius is crucial for secret leaks. When working on a secret leak incident, the first thing to do usually isn't to rotate the leaked secret, but to identify the scope:
- Identify the leaked secret: How to determine what systems and data are accessible with the exposed secret?
- Determine the scope of the compromise: How critical is it? For example, can the secret be used to access personally identifiable information (PII) or financial data? Is the affected environment non-prod or production?
- What are the tools and techniques to identify the scope? Are there tools and scripts to parse access logs? Is network traffic analysis possible?
- Revoke and rotate: How to invalidate the leaked secret and rotate all related secrets while maintaining reliability?
- Collaboration: Is collaboration with another team, like a dedicated security team or even a legal team, necessary to assess the potential impact?
How to Become Great at API Key Rotation: Best Practices and Tips
Secret management can be a complex challenge, especially when you are trying to do it in a way that is right for security. Key rotation is a big piece of that puzzle. In this article, we will take you from zero to hero on key rotation.
![]() GitGuardian Blog – Take Control of Your Secrets SecurityGuest Expert
GitGuardian Blog – Take Control of Your Secrets SecurityGuest Expert

2.3 Prevention
To prevent "server down" type of incidents, traditional methods are monitoring, redundancy, capacity planning, autoscaling, and change management.
For secret leaks, however, prevention requires a multi-layered approach:
- Secret management: Use a dedicated secret management system (e.g., HashiCorp Vault, AWS Secrets Manager, Azure Key Vault) to store and manage secrets securely.
- Least Privilege Principle: Grant only the necessary permissions to access secrets.
- Code scanning: Integrate secret scanning into the CI/CD pipeline to prevent secrets from being committed to code repositories.
- Continuous learning: Train developers and operations staff on secure coding practices and the importance of secret management.
Secrets Management Simplified with Multi-Vault Integrations
Struggling with fragmented secrets management and inconsistent vault practices? GitGuardian new multi-vault integrations provide organizations with centralized secrets visibility, reduce blind spots, enforce vault usage and fight against vault sprawl.
![]() GitGuardian Blog – Take Control of Your Secrets SecurityFerdinand Boas
GitGuardian Blog – Take Control of Your Secrets SecurityFerdinand Boas
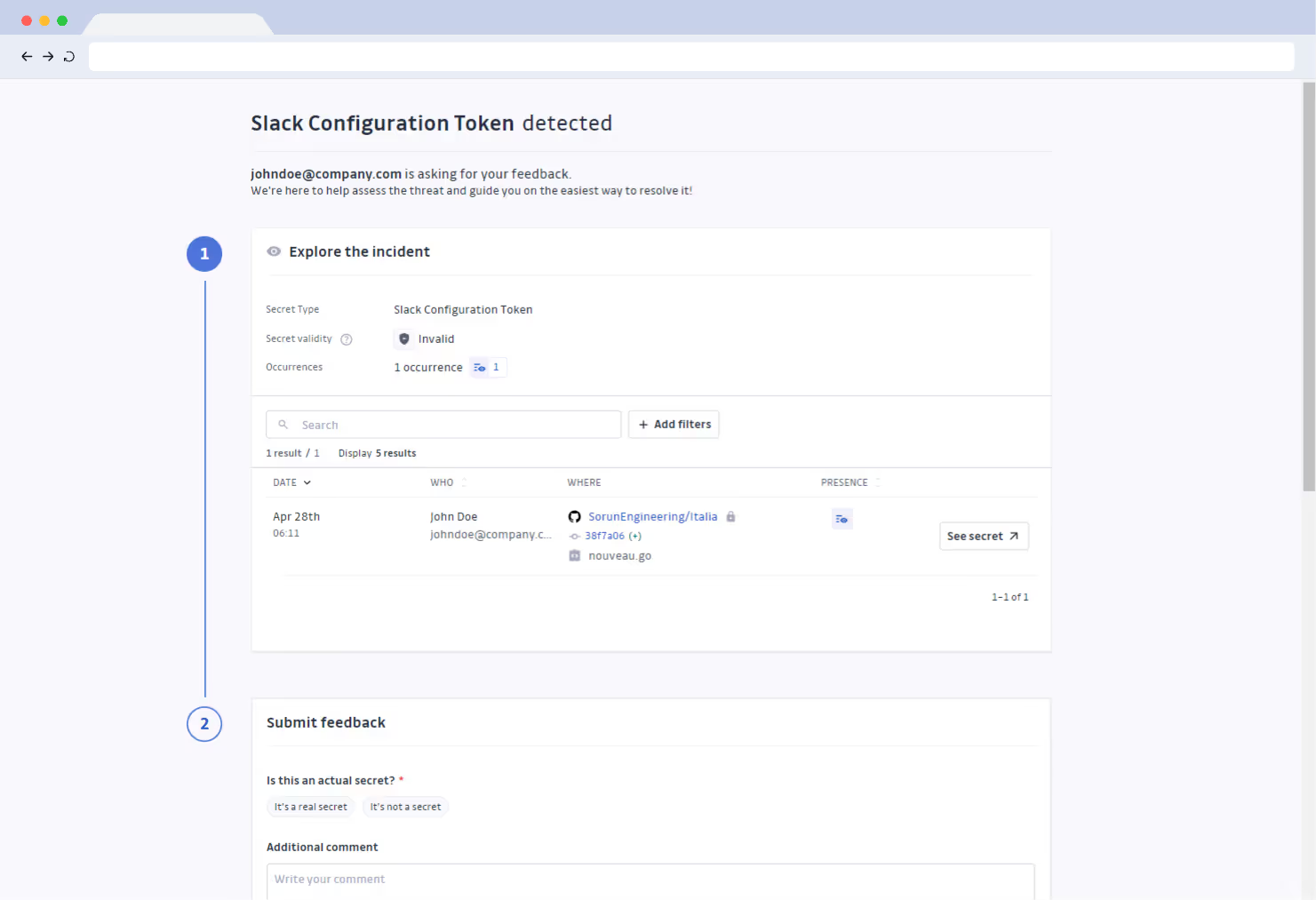
3. Real-Time Incident Response: The SRE Action Plan
After detection and analysis, it's time to contain, eradicate, and recover. This part of the playbook needs to be as specific as possible with easy-to-follow instructions to avoid any ambiguity and human errors. Detailed response steps should be outlined, and they differ for different types of incidents.
First, we want to have detailed steps for isolating affected systems to prevent further access. Prioritize efforts based on the importance of the affected systems and the potential impact, focus on high-value assets, sensitive data, and publicly accessible systems. If possible, isolate affected systems from the network to prevent further traffic. This can be achieved through firewall rules or network segmentation. If the exposed secret is associated with a user account, temporarily disable the account to prevent further use. If the exposed secret is an API key or access token, revoke it, but as said in earlier chapters, figure out the blast radius should precede the operation. Cloud provider firewalls and IAM systems can be used to help revoke access.
Then we would like to revoke the compromised secret and generate a new one. Pinpoint where the compromised secret is stored (e.g., environment variables, secrets management system); delete the secret from the secrets management system, invalidate the API key, or change the password; create a new, strong secret using a cryptographically secure random number generator; store the new secret securely; finally, update the config. Here, we want to use automation to speed up incident response time and reduce human error. Use tools like HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault to securely store and manage secrets, tools like Ansible to automate the process of updating configuration files, and tools like continuous deployment/GitOps for secret injection to update environment variables.
Before declaring the result and notifying impacted teams and stakeholders, make sure to test that the new secret is working correctly and that the old secret is no longer valid.
It's worth mentioning that rotating secrets in a production environment can be challenging, since it can potentially disrupt services and cause downtime. We can take advantage of different deployment strategies to minimize downtime:
- Blue/Green Deployments: Deploy changes to a separate environment before switching over. This allows us to test the changes without impacting production.
- Feature Flags: Enable or disable features without deploying new code. This allows us to control the rollout of changes and quickly revert.
- Canary Releases: Roll out changes to a small subset of users before a full deployment. This allows us to identify any issues before they affect a large number of users.
It's recommended to monitor key metrics during and after the rotation, which will help identify any potential issues that may arise during the process. It's also necessary to have a rollback plan, which should include steps to revert to the previous state.
4. Post-Incident Analysis and Proactive Measures
This section focuses on learning from incidents, implementing proactive measures to prevent future incidents, and making sure the playbook is up-to-date.
4.1 Post-Incident Analysis: Learning from the Leak
A thorough post-incident review is critical for understanding what happened, why it happened, and how to prevent similar incidents from happening in the future. Remember, the review isn't about assigning blame, but identifying weaknesses in the system.
Before the review, gather information, identify all factors, and determine the root cause. For example, it could be:
- lack of security awareness among developers
- misconfigured systems or apps
- insecure secret management practices
- vulnerabilities in third-party libs or components
- access controls
A comprehensive record of the incident should be created so that next time, when a similar incident happens, we have something to refer to. Key elements to include: timeline, impact assessment, actions taken, root cause analysis, and lessons learned.
4.2 Proactive Measures: Preventing Future Leaks
To implement measures that prevent similar incidents from occurring in the future, many measures can be taken. Although there are incident-specific measures for each incident, there are a few generic action items, such as:
- Shift-left: Integrate security practices earlier in the development lifecycle automatically to identify vulnerabilities before they even reach production. This reduces the cost and effort of fixing issues, improves the overall security, and fosters a culture of security awareness among developers.
- Prevent secrets from being committed: Make use of tools like pre-commit hooks, .gitignore files, environment variables (12-factor app) to avoid hard-coded secrets, and use static and dynamic analysis tools for secret scanning.
- Security awareness training and knowledge sharing: Educate developers on secure coding practices and security best practices.
- Use secret managers.
How To Use ggshield To Avoid Hardcoded Secrets [cheat sheet included]
ggshield, GitGuardian’s CLI, can help you keep your secrets out of your repos, pipelines, and much more. Download our handy cheat sheet to help you make the most out of our CLI.
![]() GitGuardian Blog – Take Control of Your Secrets SecurityDwayne McDaniel
GitGuardian Blog – Take Control of Your Secrets SecurityDwayne McDaniel

4.3 Playbook Review, Update, and Distribution
To ensure the playbook remains up-to-date, effective, and accessible, regular review, update, and test are required.
Continuously monitor the threat landscape for new types of threats and vulnerabilities, conduct periodic reviews to ensure it remains relevant, integrate feedback from actual incidents to improve the playbook's effectiveness, and update the playbook to reflect changes in the tech stack and infrastructure.
Also, playbooks need to be accessible to all relevant team members. Make sure they are version-controlled to track the changes to the playbook. Store them in a centralized repository that is easily accessible, shareable, and searchable. Also, provide training on the playbook to ensure that personnel understand its contents and how to use it.
5. Summary: Securing the Secrets, Ensuring Reliability
In this post, we've walked through the essential components of an SRE incident response playbook tailored for the threat of exposed secrets. From detailed preparation and proactive detection, to rapid response and continuous learning, a well-defined playbook is our best friend defending against potential breaches.
A quick recap of the key steps:
- Preparation: Define goals, roles, communication channels, and documentation standards before an incident occurs.
- Detection: Implement specific metrics and alerts to identify potential secret leaks, including API usage anomalies, cloud monitoring, and log analysis. Don't forget secret scanning!
- Impact assessment: Prioritize identifying the scope of the leak before taking action. Determine what systems and data are at risk.
- Containment, eradication, and recovery: Isolate affected systems, revoke compromised secrets, generate new ones, and update configurations. Leveraging automation and modern deployment strategies.
- Post-mortem: Conduct a thorough review to understand the root cause and identify areas for improvement.
- Proactive measures: Implement preventative measures such as secret management systems, the principle of least privilege, code scanning, and security awareness training.
- Continuous improvement: Regularly review, update, and test the playbook to ensure it remains effective and relevant.
An incident response playbook is not a "static" document. It's a living guide that evolves with our infrastructure, security landscape, and lessons learned from incidents. Effective communication, clear roles, and a culture of continuous improvement are key to effective incident management.
As SREs, we are the guardians of both service reliability, and security. By implementing these practices, we can minimize the impact of exposed secrets, maintain the integrity of our systems, and ensure the trust of our users.
Now, it's your turn. Take these insights and implement them within your own organizations. Develop, test, and improve your incident response playbooks. Your efforts today will pay dividends in the long run!
*** This is a Security Bloggers Network syndicated blog from GitGuardian Blog - Take Control of Your Secrets Security authored by Tiexin Guo. Read the original post at: https://blog.gitguardian.com/responding-to-exposed-secrets-an-sres-playbook/
如有侵权请联系:admin#unsafe.sh