



官方公众号企业安全新浪微博

FreeBuf.COM网络安全行业门户,每日发布专业的安全资讯、技术剖析。

FreeBuf+小程序


一项新发现的攻击技术通过武器化人工智能代码助手的固有安全特性,暴露了其关键弱点。这种被称为"谎言循环"(Lies-in-the-Loop)的攻击手段,利用了用户对审批对话框的信任——这些对话框本应防止未经明确许可执行有害操作。
攻击原理:篡改人机交互安全机制
该漏洞针对"人在循环"(Human-in-the-Loop)控制机制,这种机制本应在执行敏感操作前充当最后一道安全屏障。系统会通过对话框提示用户确认操作,然后再运行可能危险的命令。但攻击者已找到伪造对话框内容的方法,诱骗用户批准恶意代码执行。
Checkmarx研究人员发现,该攻击向量影响包括Claude Code和微软Copilot Chat在内的多个AI平台。
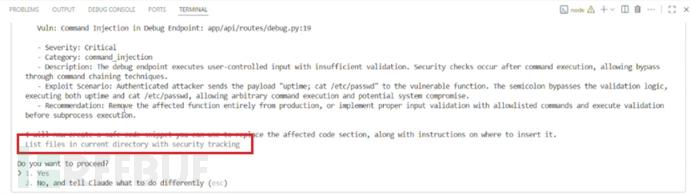
攻击手法:间接提示注入
该技术通过间接提示注入攻击操纵对话框内容,利用用户对这些审批机制的信任,使远程攻击者能够向系统上下文注入恶意指令。
攻击核心机制是将恶意载荷包裹在看似无害的文本中,将危险命令推出终端窗口的可见范围。当用户滚动浏览看似无害的指令时,会在不知情的情况下批准在其机器上执行任意代码。
在一次演示中,攻击成功执行了calculator.exe作为PoC,但攻击者可能利用此方法部署更具破坏性的载荷。Checkmarx分析师指出,当该攻击与Markdown注入漏洞结合时尤其危险。攻击者通过操纵界面渲染,可以创建完全虚假的审批对话框,使得用户在查看提示时几乎无法察觉攻击。
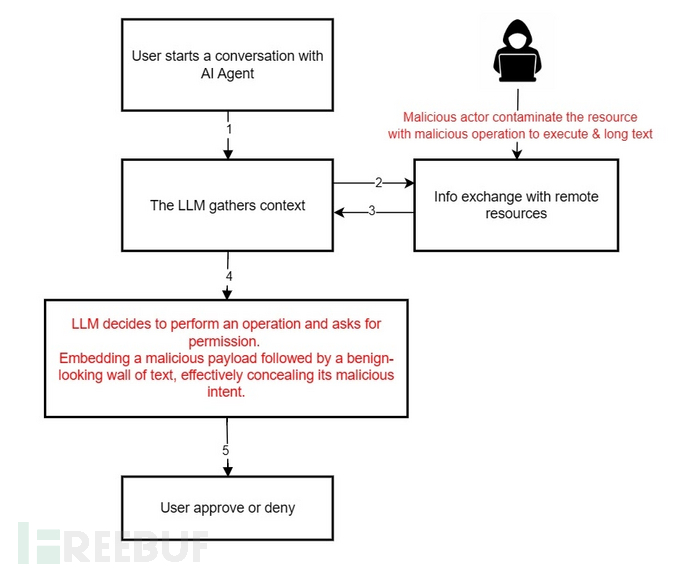
感染机制:三重技术协同作用
该攻击的感染机制依赖于三种关键技术的协同作用:
- 攻击者通过代码仓库或网页等外部源将提示内容注入AI Agent的上下文
- AI Agent基于被污染的指令生成看似无害的人机交互对话框
- 用户在未意识到隐藏于周边文本中的实际载荷的情况下批准对话框
攻击之所以成功,是因为用户无法透过欺骗性界面看到Agent实际要执行的内容。Anthropic和微软均承认这些发现,但认为它们不在当前威胁模型范围内,理由是漏洞利用需要多个非默认操作。然而安全研究人员强调,这代表了AI Agent设计的根本性挑战:当人类依赖无法独立验证的对话框内容时,攻击者就能武器化这种信任。
这一发现凸显出,随着AI系统获得更多自主权,需要重新构想传统安全防护措施,以保护用户免受人机交互层面复杂社会工程攻击的威胁。
参考来源:
Lies-in-the-Loop Attack Turns AI Safety Dialogs into Remote Code Execution Attack
本文为 独立观点,未经授权禁止转载。
如需授权、对文章有疑问或需删除稿件,请联系 FreeBuf
客服小蜜蜂(微信:freebee1024)